
Immune-Based Prediction of COVID-19 Severity and Chronicity Decoded Using Machine Learning
www.ncbi.nlm.nih.gov/pmc/articles/PMC8273732/
オンラインで2021年6月28日に公開
Bruce K. Patterson, 1 , * Jose Guevara-Coto, 2 Ram Yogendra, 3 Edgar B. Francisco, 1 Emily Long, 1 Amruta Pise, 1 Hallison Rodrigues, 1 Purvi Parikh, 4 Javier Mora, 3 and Rodrigo A. Mora-Rodríguez 3
概要
COVID-19の発症にはCCR5とそのリガンドの発現が関与していることが示唆されており,CCR5に対する治療法が検討されている。我々は、COVID-19の免疫学的スペクトラムにおけるCCR5とそのリガンドの役割を検討した。また、バイオインフォマティクスの手法を用いて、COVIDの免疫学的局面を予測・モデル化し、効果的な治療戦略の立案とモニタリングを行った。本研究では、健康な対照群とCOVID-19疾患の連続する患者を含む224名を対象とした。健常対照者29人、軽度のCOVID-19患者26人、重度のCOVID-19患者48人、COVID-19の急性後遺症(PASC)症状を持つ121人の血漿および末梢血単核細胞(PBMC)を評価した。各グループの全患者を対象に、免疫サブセットプロファイリングと14プレックスサイトカインパネルを実施した。CD14+、CD16+、CCR5+の単球サブセット(P<0.001)と同様に、B細胞は健常者と比較して有意に増加した(P<0.001)。PD-1を発現しているCD4およびCD8陽性T細胞、ならびにT調節細胞は、健常対照者に比べて有意に低かった(それぞれP<0.001,P=0.01)。CCL5/RANTES、IL-2,IL-4,CCL3,IL-6,IL-10,IFN-γ、VEGFはいずれも健常者と比較して有意に上昇した(いずれもP<0.001)。逆に、GM-CSFとCCL4は健常者と比べて有意に低かった(P=0.01)。さらにデータを分析し、SMOTEを用いてクラスのバランスを取った。バランスのとれたデータセットを用いて、3つのランダムフォレスト分類法を構築した。マルチクラス予測法、重症グループのバイナリ分類法、PASCのバイナリ分類法である。また、疾患スコアを生成するために関連するサイトカインを特定するために、モデルの特徴の重要性を分析した。マルチクラスモデルは、PASC患者に特有のスコアを生成し、S1 = (IFN-γ + IL-2)/CCL4-MIP-1βと定義した。次に、S2 = (IL-6+sCD40L/1000 + VEGF/10 + 10*IL-10)/(IL-2 + IL-8)として、Severe COVID-19患者のスコアを定義した。Severe COVID-19患者の特徴は、過剰な炎症とT細胞の活性化・動員・対抗作用の調節不全である。一方、PASC患者は、炎症促進特性を持つエフェクターT細胞の活性化を誘導できるプロファイルを持ち、ウイルスを排除するための効果的な免疫反応を生成する能力を持っているが、活性化されたT細胞を引き付けるための適切なリクルートシグナルを持たないことが特徴である。
キーワード COVID-19,PASC、サイトカイン、ケモカイン、CCR5
はじめに
COVID-19の急性期後遺症(PASC)とは、過去に感染したことのある人が、急性疾患から回復して数週間から数ヶ月後、おそらくウイルスが排除されてから数ヶ月後に、多数の症状を経験するグループである。PASCの有病率は、SARS-CoV-2に感染した人の10%から30%とされている(1)。SARS-CoV-2に感染すると、関節痛、筋肉痛、倦怠感、ブレインフォグなどの症状が現れる。これらの症状は、関節リウマチなどのリウマチ性疾患、自己免疫疾患、線維筋痛症や慢性疲労症候群などのその他の疾患によく似ている(2)。これらの一般的な疾患の多くは、炎症、過敏症および/または自己免疫によって引き起こされ、慢性疲労のように、エプスタインバールウイルス(EBV)やヒトサイトメガロウイルス(CMV)などの病原体による急性感染後のウイルス持続に関連するものもある(3)。これまでの研究では、急性COVID-19では、CCL5/RANTES、IL-6,およびTNF-αが上昇していることが示されていた(4)。CCR5アンタゴニストを使用して患者は改善したが、これらのサイトカインのレベルは低下したが、正常なレベルには至らず、退院後もサイトカイン血症が持続していることが示唆された。また、我々の研究室を含む研究では、PASCはSARS-CoV-2自体の持続性が原因である可能性が示唆されている(5)。ここでは、COVID-19の重症度を示す可能性のある免疫学的サインを特定し、PASCが軽度から中等度(MM)重度のCOVID-19とは異なる免疫学的状態を示しているかどうかを判断することを目的とした。さらに、この免疫学的プロファイルが、長期的または慢性的な抗原曝露を示す免疫反応であるかどうかという問題にも取り組みた。機械学習を用いて、PASCとSevere COVIDの免疫型を正確に決定できるアルゴリズムを特定した。最後に、治療を受ける患者を層別化したり、治療に対する反応を非主観的に測定したりするために使用できる、定量的な免疫学的スコアを発表する。
材料と方法
被験者
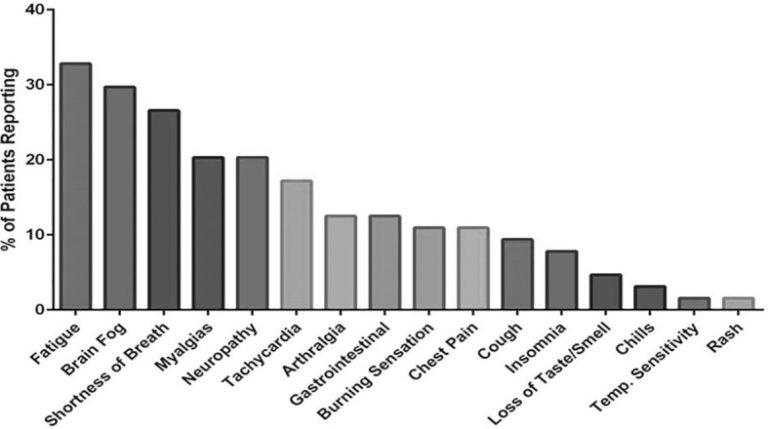
インフォームドコンセント後、全血を10 mLのEDTAチューブと10 mLの血漿調製管(PPT)に採取した。本研究には、健常対照者 29 名(SARS-CoV-2 RNA および SARS-CoV-2 IgM/IgG の両方が陰性)軽度 COVID-19 患者 26 名、重度 COVID-19 患者 48 名、慢性 COVID(PASC)患者 121 名(インフォームドコンセント後、慢性 COVID 治療センターを通じて登録、プロトコル CCTC 20-001)の合計 224 名が登録された。PASCの症状を図1に示する。研究対象者は、以下の基準で層別」
図1 本研究に登録されたPASC患者が報告した症状
軽度
発熱、咳、喉の痛み、倦怠感、頭痛、筋肉痛、吐き気、下痢、味覚・嗅覚の低下
胸部画像(CXRまたは胸部CT)で肺炎の兆候がない
息切れや呼吸困難がないこと
中等度
肺炎の発熱と呼吸器症状の放射線学的所見
海面上の室内空気での酸素飽和度(SpO2)94%以上
重度
酸素飽和度(SpO2)94%未満(海面上の室内空気)
動脈血中酸素分圧(PaO2)/吸入酸素分圧(FiO2)<300mmHG
24~48時間以内に肺浸潤が50%以上
心拍数≧125bpm
呼吸数≧30回/分
PASC
最初の症状の発現から 12週間を超えていること
High Parameter Immune Profiling/Flow Cytometry
Lymphoprep density gradient (STEMCELL Technologies, Vancouver, Canada)を用いて、末梢血単核細胞(PBMC)を末梢血から分離した。90%ウシ胎児血清(HyClone, Logan, UT)および10%ジメチルスルホキシド(Sigma-Aldrich, St. 細胞(5×105)を、14色の抗体カクテルを用いて、記載されている容量(補足表1)で、前述(4)の方法で染色し、分析した。サンプルは,Kaluza Analysis Software(Beckman-Coulter, Miami, FL)を用いて,Beckman Coulter CytoFlex LX 6-laser flow cytometerで分析した。すべての統計解析は、Mann-Whitney検定を用いて行い、P値≦0.05を統計的に有意とした。
多重サイトカインの定量
新鮮な血漿を、CytoFlexフローサイトメーター上で、カスタマイズされた14プレックスビーズベースのフローサイトメトリーアッセイ(IncellKINE, IncellDx, Inc)を用いて、以下の分析物を用いて、前述のようにサイトカインの定量化を行った。TNF-α、IL-4,IL-13,IL-2,GM-CSF、sCD40L、CCL5(RANTES)CCL3(MIP-1α)IL-6,IL-10,IFN-γ、VEGF、IL-8,およびCCL4(MIP-1β)(4)。各患者サンプルには、96ウェルプレートの各ウェルに25μLの血漿を使用した。サンプルは,Kaluza Analysis Software(Beckman-Coulter, Miami, FL)を用いて,Beckman Coulter CytoFlex LX 3-laser flow cytometerで解析した。すべての統計解析は,Mann-Whitney検定を用いて行い,P値≦0.05を統計的に有意とした。
データ処理
これまで、健常者、Mild、Moderate、Severe、PASCの各患者を定義してきたが、ダウンストリーム解析のために、患者を4つのクラスに分けた。健常対照(健康な患者)Mild-Moderate(MildとModerateの患者を含む)Severe、PASCの4つのクラスに分けた。データは,Python 3.8.3を用いて,pandasライブラリ(バージョン1.1.0)(7)とnumeric pythonモジュール,numpyバージョン1.18.5(8)を用いてインポートし,処理した。データは,4つのクラス(健常対照,軽度-中度,重度,PASC)を表す224のインスタンスで構成されている。データセットは16列で構成されており、そのうち14列はサイトカイン/ケモカインの分析項目を表し、1列は患者の識別子、1列はラベル、つまり患者の属するクラス(healthy control, Mild-Moderate, Severe, PASC)を表している。
今回のデータセットでは、クラスラベルのバランスが悪いことが判明したため、データセットのバランス調整を行うことにした。データバランシングを適切に行うためには,データをトレーニングセット,検証セット,テストセットに分ける必要があった。我々は60/20/20スキーマを使用し、トレーニング後のモデルのオーバーフィッティングを評価するために20%の検証パーティションと、クラスラベル予測のために20%のデータを使用した。データの分割は,生成されたサンプルがトレーニングセットにのみ存在することを保証するために実施する必要がある.生成されたサンプルが検証セットとテストセットのどちらかに存在すると,オーバーフィッティングやスプリアスな結果を引き起こす可能性があるため,これらのセットには生成されたサンプルを入れないようにする必要がある.
少数派クラスの合成オーバーサンプリングによるデータバランシング
データセットに含まれる4つのクラスは,それぞれ異なる数のインスタンスで構成されている.クラスの数のばらつきが大きいと、クラスの不均衡と呼ばれる現象が発生する。今回のデータセットでは、データセットの50%にあたる121人がPASCであったのに対し、軽度・中等度と健常対照者はそれぞれ26人と29人しかおらず、残りの48人はSevereクラスであったことから、クラスの不均衡が存在する可能性があることがわかった。例えば、PASCとSevereの間には2.5倍の比率、PASCとMild-ModerateおよびControlの両方との間には4倍の比率が確認された。このような比率の違いは、予測に偏りを生じさせる可能性があり、モデルの性能評価や一般化に反映されることがよくある(6, 9, 10)。このような問題を回避するために,ランダムアンダーサンプリング法やオーバーサンプリング法などのバランス調整法が提案されている。しかし、ランダムなアンダーサンプリングは情報の損失につながり(11)、一方、基本的な/ランダムなオーバーサンプリングはモデルのオーバーフィットにつながることが報告されている。
Chawlaら(11)は、少数派のクラスの合成オーバーサンプリングにおける解決策を提案した。SMOTEと呼ばれるこの手法は、少数派クラスのインスタンス間の補間を用いて、データセットのバランスをとるための新しいデータポイントを生成する。SMOTEは、生物学的文脈のものを含むインバランスにおいて、機械学習モデルと組み合わせて使用されている(12)。pythonライブラリimbalanced-learn(13)からSMOTEをパイプライン化して、トレーニングセットのバランスを取り、ランダムフォレスト分類器の構築に使用した。
ランダムフォレスト分類器
ランダムフォレスト(RF)分類器は,複数の決定木をグループ化するアンサンブル手法です.ランダムフォレストは,2001年に開発されたように,分類と回帰の両方の問題に使用することができる(14).この手法は,生物学的データセットの解析や,生物学的文脈における知識発見に用いられている(11, 15, 16).ランダムフォレスト分類法には,特徴の重要性を評価するオプションが含まれている.これは,特徴の生物学的重要性の評価,免疫反応などの特定の生物学的プロセスにおける関連性の理解,バイオマーカーとしての潜在的な役割など,下流の分析を行う際に非常に重要となる(17).
予測と関連性のある特徴の識別の両方が可能であることから、ランダムフォレストは選択手法として組み込まれている。ランダムフォレスト分類器の構築には,Pythonの機械学習ライブラリであるscikit learn 0.24.1を使用した(18)。さらに,モデルのハイパーパラメータ(特徴数,木の深さ,木の数)を調整するために,10倍のクロスバリデーション(CV)を用いて,網羅的なグリッド検索を行った。なお、重要度変数は、有意な特徴を特定するためにのみ実装されており、次元削減のためには実装されていないことに注意してほしい。
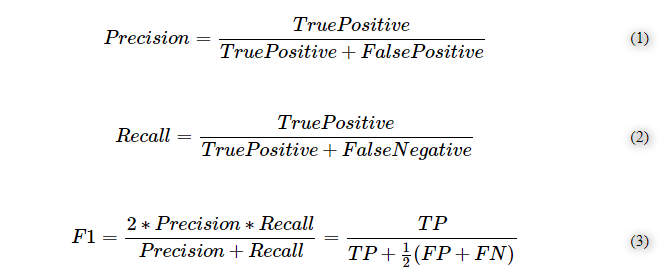
モデル性能を表すPrecision、Recall、F1スコアの定義
ランダムフォレスト分類器の性能を推定するために、3つの異なる指標を選択した。すなわち、関連性のある結果の割合を示す精度(式1)予測器によって正しく分類された関連性のある結果の合計を示すリコール(式2)およびこれら、2つの指標の調和平均であり,0から 1の範囲であるF1スコア(式3)である。 F1スコアが1に近い場合、モデルの性能が高いことを意味する。F1スコアは,偽陽性(FP)と偽陰性(FN)の両方,および真陽性(TP)の場合にも適用される。
結果
免疫プロファイリング
PASCに免疫学的な異常が残っているかどうかを調べるために、PBMCが保存されている人のサブセットで、パラメータの高い免疫細胞の定量と特性評価を行った(表1A)。サブセットを含むB細胞、T細胞、単球の定量化を行い、CD4/CD8の活性化とT細胞の枯渇についても調べた。すべてのT細胞の決定は、CD3の発現で初期化され、すべての単球サブセットは、CD45で初期化された ( 補足図1 ) 。急性COVID-19(4)とは異なり、PASCのCD4およびCD8 T細胞集団は健康なコントロールの範囲内であり、T細胞の疲弊を示す証拠はなかった。実際、PD-1を発現しているCD4およびCD8陽性T細胞は、健常対照よりも有意に少なかった(それぞれP<0.001,P=0.01)。さらに、T調節細胞の総数は健常対照者と比較して有意に減少しており(P<0.001)PASCの高免疫状態を悪化させている可能性がある。B細胞は健常者と比較して有意に増加し(P<0.001)CD14+、CD16+、CCR5+の単球サブセットも増加した(P<0.001)(Table 1A)。興味深いことに、これら、2つの免疫細胞集団は、異なるウイルスに慢性的に感染していることが示されている。B細胞はEpstein-Barrに、CD14+, CD16+, CCR5+の単球サブセットはHIV-1とHCVに感染している(19)。
表1A T細胞、B細胞、および単球の免疫表現型。
| Average | CD3+% | CD4% | CD8+% | CD4+PD1% | CD4+LAG3% | CD4+CTLA4% | CD4+FoxP3% | CD8+PD1% | CD8+LAG3% | CD8 CTLA4% | CD8+ FoxP3% | CD19% | CD14+CD16-% | CD16+CD14+% | CD16+CD14-% |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Healthy Controls |
64.40 | 53.80 | 33.83 | 35.62 | 0.94 | 1.51 | 6.21 | 43.75 | 4.35 | 1.38 | 0.67 | 6.04 | 42.79 | 9.00 | 32.67 |
| Lower CI | 54.39 | 43.21 | 27.20 | 28.36 | 0.49 | 0.75 | 4.54 | 33.50 | 2.71 | 0.74 | 0.37 | 5.04 | 34.41 | 4.60 | 25.49 |
| Upper CI | 74.50 | 64.57 | 40.46 | 42.89 | 1.39 | 2.26 | 7.87 | 54.01 | 5.99 | 2.03 | 0.97 | 7.04 | 51.16 | 13.41 | 39.86 |
| PASC | 48.98 | 56.18 | 35.36 | 17.78 | 0.72 | 4.06 | 2.58 | 31.99 | 0.71 | 3.11 | 1.01 | 13.14 | 19.01 | 29.3 | 33.86 |
| Lower CI | 44.78 | 52.44 | 32.56 | 15.73 | 0.36 | 2.32 | 2.01 | 29.46 | 0.55 | 2.04 | 0.80 | 11.72 | 15.65 | 25.65 | 30.28 |
| Upper CI | 53.18 | 59.92 | 38.70 | 19.83 | 1.08 | 5.80 | 3.15 | 35.52 | 0.87 | 4.18 | 1.22 | 14.56 | 22.37 | 32.95 | 37.44 |
PASCの免疫反応の特徴をさらに明らかにするために、29名の健常対照者を対象に定量的なマルチプレックスサイトカイン/ケモカインパネルを実施し、アッセイの健常対照範囲を設定した。その後、軽度、重度、およびPASCの血漿サンプルを分析し、サイトカイン/ケモカインのプロファイルを比較した(表1B)。CCL5/RANTES、IL-2,IL-4,CCL3,IL-6,IL-10,IFN-γ、VEGFは、いずれも健常者と比較して有意に上昇した(いずれもP<0.001)。逆に、GM-CSFとCCL4は健常者と比較して有意に低いレベルであった P=0.005
表1B サイトカインおよびその他の可溶性因子の定量化。
| Average (pg/ml) | TFN-α | IL-4 | IL-13 | IL-2 | GM-CSF | sCD40L | CCL5 (RANTE S) | CCL3 (MIP-1α) | IL-6 | IL-10 | IFN-γ | VEGF | IL-8 | CCL4 (MIP-1β) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Healthy Controls | 9.09 | 4.18 | 3.94 | 6.17 | 51.27 | 7192.39 | 10781.84 | 22.82 | 2.21 | 0.67 | 1.94 | 9.32 | 16.87 | 76.84 |
| Lower Cl | 7.37 | 2.17 | 1.79 | 5.53 | 25.72 | 5148.85 | 9764.99 | 13.05 | 1.65 | 0.42 | 0.63 | 6.36 | 13.03 | 61.00 |
| Upper Cl | 10.81 | 6.18 | 6.09 | 6.82 | 76.82 | 9235.92 | 11798.68 | 32.60 | 2.77 | 0.92 | 3.26 | 12.28 | 20.72 | 92.67 |
| PASC | 7.72 | 17.03 | 4.21 | 16.16 | 12.46 | 18302.41 | 12505.06 | 97.81 | 20.47 | 12.23 | 86.60 | 41.03 | 35.98 | 35.10 |
| Mild-Mod | 6.82 | 2.33 | 2.40 | 5.90 | 56.13 | 10673.72 | 11627.70 | 18.75 | 8.74 | 0.63 | 1.15 | 17.39 | 17.37 | 94.40 |
| Severe | 5.39 | 2.39 | 2.26 | 5.43 | 20.31 | 12306.39 | 11581.47 | 16.54 | 144.15 | 3.10 | 2.06 | 25.52 | 10.87 | 64.84 |
データセット内の分析グループを区別するためのマルチクラス・ランダムフォレスト予測器の構築
我々は、多クラスのランダムフォレスト分類器を構築することで、データセットの分析グループ(または疾患グループ)を区別することを提案した。探索的データ解析の段階で、現在のデータセットは、PASCクラスが過剰に含まれており、アンバランスであるという特徴があることがわかった。また、このデータセットは、インスタンスの数が多いため、中規模のデータと考えられる。このような潜在的な問題に対処し、モデルのオーバーフィッティングを回避するために、上述のようなバランシング技術を導入した。このように、SMOTEの実装は、オーバーフィッティングに対抗し、代表性の低いクラスや少数派クラスの補間から新しいサンプルを生成するのに有効である。SMOTEを使って少数派のクラスをPASCクラスの100%にバランスさせることで、各クラスが76のインスタンスを学習セットに持つことになった。これは、健康な対照群と軽度・中程度のクラスでは4倍、重度のクラスでは2.5倍の増加となる。
このバランスのとれたデータセットを用いてマルチクラスRF予測器を構築し,グリッドサーチとクロスバリデーションの手法を用いて微調整を行った。このグリッドサーチと10倍のCVの実施は,このモデルとその後に構築されたすべての分類器の微調整アプローチとして使用された。次に,検証セットを用いてマルチクラスモデルのオーバーフィットを分析した(表2).この分析では,健常対照者と軽度者を識別する際に,モデルの予測性能がわずかに低下していることに気づいたが,検証セットでの全体的な性能は,リコール(感度)とf1スコアに見られるように高いものであった。しかし、テストセットのパフォーマンス指標では、これらの違いが大きく強調されていた(表2)。このことは,マルチクラス分類器の混同行列(図2)からもうかがい知ることができる。この混同行列によると,テストセットでは,SevereクラスとPASCクラスは適切に識別されたが,Healthy ControlクラスとMild-Moderateクラスでは複数の誤分類が発生した。さらに、データセットの特徴の重要度(サイトカイン)を分析したところ、変数間の差は小さく、軸のスケールによってのみ増幅されることがわかった(図2)。しかし、IFN-ˠとCCL5(RANTES)の差を除けば、差はそれほど明らかではないかもしれない。これらの結果から、SevereクラスとPASCクラスに焦点を当てたバイナリRF分類器の構築を進めることにした。
表2 検証およびテストパーティションにおけるランダムフォレスト分類器の予測性能
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Multi-class-Val | 0.97 | 0.97 | 0.92 | 0.93 |
| PASC-Val | 1.00 | 1.00 | 1.00 | 1.00 |
| Severe-Val | 0.94 | 0.95 | 0.94 | 0.94 |
| Multi-class-Test | 0.8 | 0.62 | 0.65 | 0.63 |
| PASC-Test | 0.96 | 0.95 | 0.96 | 0.95 |
| Severe-Test | 0.95 | 0.97 | 0.93 | 0.94 |
パーティションはモデルの横に表示されており、Valは検証用、Testはテスト用となっている。表示された性能指標は、sci-kit learn (18) の分類レポートと混同行列を用いて計算されている。
図2 ランダムフォレスト予測器を用いたマルチクラス分類器の混同行列(A)と特徴重要度(B)
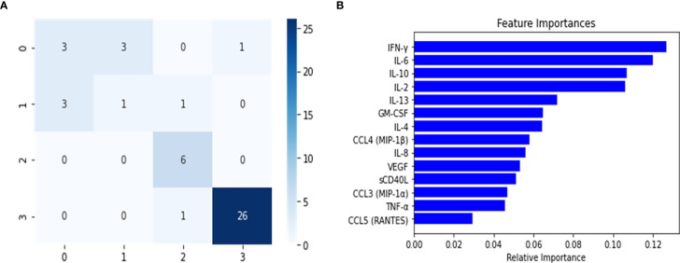
混同行列は、テストセットに対するランダムフォレスト分類器の予測値から計算された。クラスは以下の方法で割り当てられた。(0)健康なコントロール、(1)軽度-中程度、(2)重度、(3)PASC。
PASC患者を識別するためのヒューリスティックスコアを開発するために、二値のPASCランダムフォレスト分類器を構築することで、関連する特徴を識別することが可能になった。
マルチクラスの予測因子を構築した後、PASC疾患群の理解を深めるために、バイナリ分類器の開発を進めた。PASCクラスは長期疾患キャリアーで構成されているため、ランダムフォレスト分類器は、長期疾患キャリアーとこのクラスに属さないインスタンスを分離し、疾患グループの識別に関連するサイトカインや特徴を特定することを課題とした。これを実現するために、データを大きく2つに分けた。1つは、非長期疾患キャリアグループを表すすべてのクラス(健常対照、軽度、重度)で構成され、もう1つはPASCで構成されている。この新しいデータセットを60/20/20(トレーニング/バリデーション/テスト)に分割し、SMOTEを用いてトレーニングセットのバランスを取った。学習された分類器は,最適なハイパーパラメータの組み合わせ(木の深さ,特徴数,木の数)を決定するために,網羅的なグリッド探索を用いて微調整された。その後,モデルのオーバーフィットを検出するために検証セットでモデルを使用したが,モデルのオーバーフィットの兆候は確認されなかった(表2).このモデルをテストセットに導入し,このパーティション内のインスタンスのクラスを予測した。混同行列(図3)を分析すると、モデルの予測能力は非常に高く、誤って分類されたインスタンスは2つしかなかった。これは、予測指標(表2)でも裏付けられており、精度と再現率のバランスであるF1スコアは0.95であった。さらに、変数の重要度分析(図3)を見ると、最も関連性の高い上位5つのサイトカインは(順に)以下の通りであることがわかった。IFN-ˠ、IL-2,IL-4,IL-10,GM-CSFである。また、その他の関連サイトカインとして IL-8,CCL4(MIP-1β)CCL3(MIP-1α)。
図3 PASC患者を識別するためのスコアの特徴工学を可能にするPASCバイナリランダムフォレスト分類器のConfusion Matrix(A)とfeature importance(B)
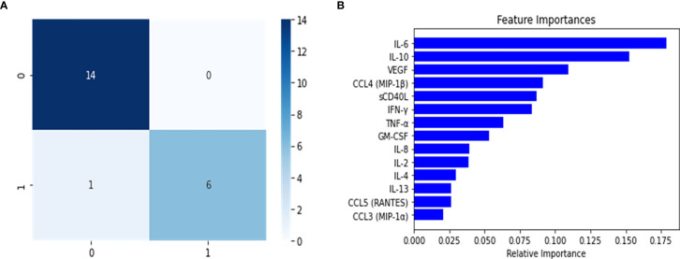
正のクラス(1)はPASC、負のクラス(0)は非PASC(健康なコントロール、Mild-Moderate-Severe)である。
変数重要度分析から得られた特徴は、特徴工学を用いて構築された新しいヒューリスティックの開発の基礎となった。このヒューリスティックから得られたスコアを用いることで、モデルを単純化し、PASCの表現型に関する生物学的な知見を得ることを目的とした。その結果、S1 = (IFN-γ + IL-2)/CCL4-MIP-1βと定義される「PASCスコア」が得られた(図4)。感度と特異度のトレードオフとして最適な閾値をS1=0.5に設定したところ、PASCの大部分(S1>0.5の118/121)をPASCに分類することができ、感度は97.5%となった。健常対照例およびMILD-Moderate例では、PASCに分類されたものはなかった(健常対照例およびMILD-Moderate例の特異度は100%)。一方、Severe症例の7/48がPASCに分類され(S1>0.5)特異度は85%であった。このことは、「誤分類」されたSevere症例が実際にPASCになる可能性を示唆している。
図4 PASC患者(S1)の識別に対するLong haulerスコアの識別能力で、Random Forest分類器を用いて識別された特徴量が減少したもの、または最も重要な特徴量が増加したもの
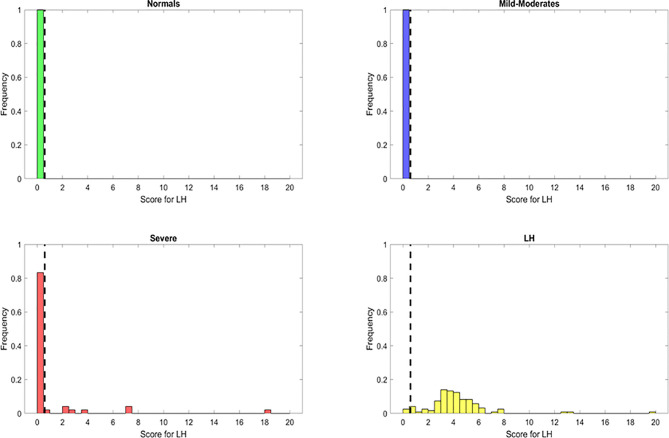
点はデータポイントを表し、黄色はPASC、赤はSevere、紺はMild-Moderate、緑はHealthy Controlである。
二値のランダムフォレスト分類器の構築と変数の重要性により、重症患者を識別するスコアの特徴工学が可能になる
重症患者と非重症患者を識別するためのランダムフォレスト分類器は,バランスのとれた健常対照群とMild-Moderate群を,非重症とラベル付けされた1つの群にグループ化することによって構築された。このデータセットでは、重症グループと非重症グループを分けるサイトカインを特定できる可能性があることから、PASCクラスを除外した。しかし、これらの非重症者は、長期保有者グループには属していない。また、重要な変数を用いて作成した疾患スコアの結果から、PASCを識別することができた。
モデルの構築と微調整は、マルチクラスモデルとバイナリーモデルで実施したのと同じ方法で行った。検証セットでは、モデルのオーバーフィッティングを確認するために、最適なパラメータを持つモデルを選択した。その結果,オーバーフィッティングの兆候は見られず,このモデルを使ってテストセットの予測を行った。このSevereバイナリ分類器のコンフュージョンマトリクス(図5)が示すように、Severeと非Severeのインスタンスを識別することができた。誤って分類されたインスタンスの数は、非SevereをSevereに誤って分類した1件であった(図5)。このモデルは,テストセットでの測定値が示すように,非常に高い性能を示した(表2).精度とリコールはともに高い値を示した(それぞれ0.97と0.93,F1スコアは0.94)。さらに、これから報告するように、このモデルは、疾患群を識別するのに関連する重要な特徴(サイトカイン)も特定した。この情報は、Severe疾患群のヒューリスティックスコアを開発するのに役立つであろう。また、変数の重要度分析(図5)を行ったところ、最も関連性の高い特徴が特定された。その結果、IL-6,IL-10,VEGFが最も関連性が高く、IFN-γ、CCL4-MIP-1β、sCD40Lの関連性はそれほど高くなかった。
図5 ランダムフォレスト分類器を用いて構築したSevereバイナリ分類器の混同行列(A)と変数の重要度(B)
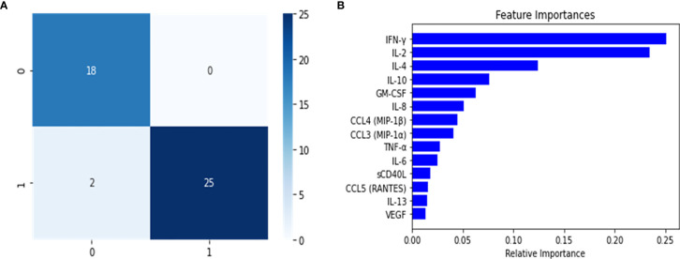
混同行列に示された結果は、テスト分割について計算されたもので,0はグループ化されたMild-Moderateと健康なコントロールのインスタンス、1はSevereのケースを表している。Bについては、Severe患者の疾患グ全身性エリテマトーデスコアを算出するための最も重要な変数であった。
これらの重要な特徴を用いて、患者を識別するためのスコアを開発した。同じ原理に基づいて、Severeランダムフォレストバイナリ分類器の関連する特徴を用いて、Severe症例を識別するためのスコアを作成した。この新しいスコアはS2と呼ばれ、以下のように計算された。S2 = (IL-6+sCD40L/1000+VEGF/10+10*IL-10)/(IL-2+IL8)。感度と特異度のトレードオフとして、S2=1.5という最適な閾値を設定したところ、ヒューリスティックを適用して、大多数のSevereをSevereと分類することができた(S2>1.5の46/48)感度は95.8%であった。Severeに分類されたのは、健常対照者では2/29,MILD-Moderateでは5/26のみであった(特異度は健常対照者で93%、MILD-Moderateで81%であり、病状の誤分類の可能性がある)(図6)。しかし、このスコアだけでは、ほとんどのPASCがSevereに分類されてしまうため、本来のPASCを分離することはできない。
図6 ランダムフォレスト分類器を用いて識別された、重要度の低い特徴または最も重要な特徴を持つSevere患者(S1)を識別するためのSevereスコアの識別能力
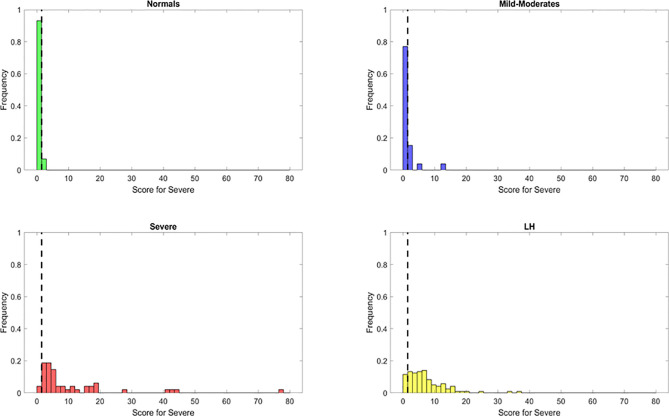
点はデータポイントを表しており、黄色はPASC、赤はSevere、紺はMild-Moderate、緑はHealthy Controlである。
PASCとCOVID-19の重症例の最適な分類を可能にする複合ヒューリスティック法
PASCとSevereの識別を統合するために、我々は両方のスコアと上記で定義した最適化されたしきい値を用いて、複合的なヒューリスティックを開発することを目指した。このヒューリスティックは、まず「PASCスコア」を用いてPASC症例を特定し、次に残りのデータポイントからSevere症例を特定する。図7のグラフでは、PASCとSevereのケースが、健康なコントロールとMild-Moderateのケースから非常によく分離されている。すべてのPASC(121)がPASC(118)またはSevere(3)に分類され、病理を特定する感度は100%であった。一方、SevereのうちMild-Moderateに分類されたのは1例のみであり、ほとんどのSevere症例がSevere(n=40)またはPASC(n=7)に分類されたことから、病変の検出感度は97.9%であった。また、Severeに分類された7件がPASCに分類されたということは、Severeの中にもPASCに分類される可能性があることを示唆している。
図7 Long Hauler(S1)とSevere(S2)の両方のスコアを持つヒューリスティックの識別能力
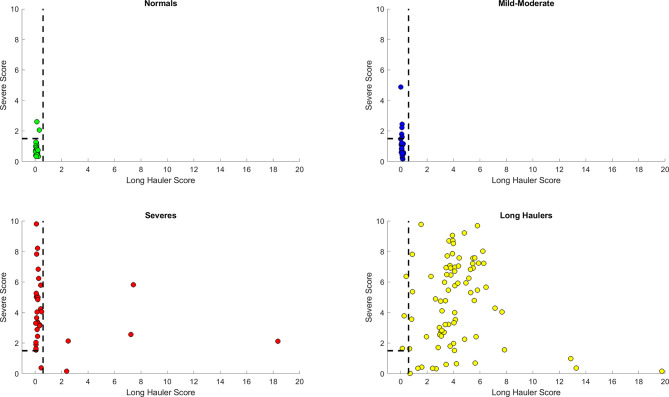
まず、S1>1.5のPASC患者が特定される。残った患者から、S2>1.5のSevereケースが特定される。点はデータポイントを表しており、黄色はPASC、赤はSevere、紺はMild-Moderate、緑はNormalである。
最後に、情報量の多い特徴に基づく2つの分類スコアの特徴工学によって、予測モデルを単純化した。まず、「PASCスコア」は、S1 = (IFN-γ + IL-2)/CCL4-MIP-1βと定義した。次に、「Severe Score」は、S2 = (IL-6+sCD40L/1000+VEGF/10+10*IL-10)/(IL-2+IL8)と定義した。複合的なヒューリスティックを用いて、まずPASC(S1>0.4)を分類し、次にSevere COVID-19患者(S2>0)を分類したところ、PASCでは感度97%、特異度100%、Severe患者では感度88%、特異度96%という結果が得られた(図7)。
考察
SARS-CoV-2に感染した患者は、異なる重症度のパターンを示し、それは異なる免疫活性化プロファイルと関連していた。興味深いことに、完全に回復するまでに長い時間を必要とするケースがあり、これは最近、long-COVIDまたはPASCと呼ばれている特定の病的タイプを表している。
この数ヶ月間に得られた科学的証拠は、COVID-19患者の異なる転帰が、ウイルス感染に反応して活性化された免疫メカニズムによって決定されることを強く裏付けている(20)。
SARS-CoV-2に対する免疫反応は、インターロイキンを含むサイトカインやケモカインなど、炎症作用を持つさまざまな分子の放出を誘導する。この現象はサイトカイン・ストーム(20)と呼ばれ、COVID-19の免疫病理学的特徴であり、病気の重症度と関連している。COVID-19患者では、IL-6,IL-8,IL-10,TNF-α、IL-1β、IL-2,IP-10,MCP-1,CCL3,CCL4,CCL5などのインターロイキンやケモカインなど、さまざまなサイトカインの血中濃度が上昇することが報告されている(4)。これらの分子のいくつかは、COVID-19患者の臨床経過をモニターし、治療法の選択を決定するためのバイオマーカーとして提案されている(21-23)。しかし、これらの分子の中には、状況に依存して機能するものもあり、単一のサイトカインの変化を分析することの臨床的意義は限定的であることを考慮することが重要だ。
パンデミック時の最も重要な課題の一つは、医療システムの飽和状態を回避することであり、そのためには患者の層別化を可能にする予測バイオマーカーを決定することが最重要である。IL-6やIL-8などのサイトカインは、病気の重症度の指標として提案されており、いくつかの研究では患者の生存率を強力かつ独立して予測していたが(24)、単独で分析した場合の予測値については議論の余地がある(24)。免疫機能の異なるインターロイキンやケモカインなどのサイトカインの血中濃度を考慮してスコアを作成することは、これらの分子の文脈依存的な機能の重要性を反映している。
重症度を予測するために、IL-10,IL-6,IL-2,IL-8などの炎症関連因子や、血管の恒常性に関連するsCD40L、VEGFの血中濃度を考慮したスコアを作成した(25,26)。この分類では、Severe症例はIL-6とIL-10が高いことを特徴としている。これらのサイトカインは、これまでCOVID-19の免疫病原性を高めるとされており、Severe症例の予測値となっている(22, 23)。様々な背景から、IL-6は酸化ストレス、炎症、内皮機能障害、血栓形成と関連しており(25-28)、これらは骨髄系細胞の過剰な活性化によって引き起こされるCOVID-19重症例に特徴的な特徴である(29)。同様に、IL-10レベルの上昇は、適切なT細胞応答を妨げ、T細胞の疲弊と制御性T細胞の偏りを誘発し、抗ウイルス免疫応答の回避につながる(30)。さらに、IL-10はT細胞に対する抗炎症機能に加えて、いくつかの背景では、IL-10はSTAT1の活性化を誘導し、タイプIFNでプライミングされたミエロイド細胞に炎症反応を起こさせる(30, 31)。したがって、IL-6とIL-10の上昇は、骨髄系細胞の活性化、酸化ストレス、内皮の損傷を促進し、抗ウイルスT細胞の十分な活性化に影響を及ぼす可能性がある(26-30)。
さらに、重症患者では、血管炎や血管リモデリングに関連するsCD40LやVEGFが高値を示している。sCD40Lは血小板活性化マーカーであり、COVID-19患者の重症度上昇と関連している(32-34)。さらに、sCD40Lの値は女性よりも男性の方が高く、これは病気の重症度に性差があることを意味している(33)。SARS-CoV-2感染に伴うもう一つの血管の変化は、内皮の活性化である。提案された重症度スコアによると、入院中のCOVID-19患者ではVEGFレベルが軽度-中等度の症例と比較して有意に上昇していた。さらに、今回発表した分類を強化するために、このスコアでは、適切なT細胞の活性化(IL-2)およびリクルート(IL-8)に関連するサイトカインであるIL-2およびIL-8を分母としてSevere症例を区別している(35,36)。
PASCを区別するために作成されたスコアによると、これらの患者はIFN-γとIL-2が増加し、CCL4の産生が減少していることが特徴である。ウイルス感染の状況下では、IFN-γとIL-2の組み合わせは、炎症性の特性を持つエフェクターT細胞の活性化を誘発し、ウイルスを排除するための効果的な免疫反応を生成する能力を持っている。しかし、PASCでは、疲労や肺の損傷などの臨床症状が長く続くのが特徴である。これは、T細胞の活性化につながるこれらのサイトカインが作り出す炎症の状況は、活性化したT細胞を引き付ける適切なリクルートシグナルがなければ、十分な抗ウイルス反応を生み出すのに十分ではないことを示唆している。CCL4は、受容体CCR5を介してT細胞を炎症部位に惹きつけるシグナルを発し、免疫状況に応じて、この分子は異なる活性化T細胞をリクルートする(37, 38)。さらに、軽度および重度のCOVID-19患者では、末梢の骨髄細胞でCCL4の発現が抑制されていることが、シングルセル解析により最近明らかになった(39)。PASCでは、IFN-γとIL-2がTh1極性に有利な免疫状況を作り出しているが、CCL4のレベルが低いと、これらの細胞のリクルートに影響を与え、SARS-CoV-2のRNAやタンパク質が残存した場合の抗ウイルス反応が損なわれてしまう。IFN-γとIL-2の増加がT細胞の活性化に及ぼす影響は、健康なドナーと比較して、疲弊したT細胞(CD4+PD1+/CD8+PD1+)と総制御性T細胞(FoxP3+)の頻度が減少したことからも明らかである。したがって、適切なT細胞の活性化(高いIFN-γ+IL-2)と効果的でないT細胞のリクルート(低いCCL4)は、PASCグループで観察された失敗した抗ウイルス反応の特徴であり、ウイルスの持続を支えている。
PASC群におけるB細胞の有意な増加は、B細胞の増殖と分化を促進するIL-2レベルの高さと関連している(40)。興味深いことに、IFN-γの増加は、B細胞のリンパ節へのホーミングに影響を与え(41)、総IgG産生を低下させ、前活性化B細胞を阻害する(42)。CCL4は、B細胞受容体経路活性化のバイオマーカーとして提唱されていることから(43)、このことが、PASC群で観察されたCCL4レベルの低さに裏付けられ、ウイルスの持続性と関連している可能性がある。
さらに、IFN-γの増加は骨髄系細胞の活性化を促進し、健常人と比較してPASC群では炎症性のCD14+、CD16+、CCR5+単球の頻度が増加していることから、これらの患者におけるリンパ球減少とウイルスの持続性を裏付けていると考えられる。このことは、軽度および重度のCOVID-19患者のIFN-γに応答して、末梢の骨髄細胞で遺伝子発現が増加することを記述した最近の知見(39)や、COVID-19患者で記述された単球サブセットの拡大による単球集団のバランスの乱れ(39)と一致している。最後に、我々は、PASCで観察される長期にわたる肺障害は、以下のような複合的な要因によって引き起こされると提案する。ウイルスの持続は、IFN-γとIL-2の高いレベルを特徴とするPASCの免疫プロファイルに影響され、Th1極性を誘導するが、CCL4によるT細胞のリクルートが少ないために効果がなく、炎症性骨髄系細胞の活性化につながる。PASC免疫プロファイルの免疫病理学的影響については、マウスモデルを用いて、IFN-γレベルが高いと、炎症による肺損傷の解消や血栓の解消の速度に影響を与えることが示されており(44-46)、これが肺の凝固障害や免疫介在性の組織損傷に関連するPASCの長期的な症状に関係している可能性がある。
興味深いことに、COVID-19の患者(PASC、軽度、重度を含む)は、CCL4と同様にCCR5を介してシグナルを送るケモカインであるCCL5の濃度が高い。実際、CCL5-CCR5経路を遮断すると、重篤なCOVID-19患者の免疫バランスが回復する(4)。PASCに限って言えば、CCL5が健常者と比較して統計的に有意に上昇しているにもかかわらず、CCL4を介した活性化T細胞のリクルートが減少していることが提案されている。これにはさまざまな要因が考えられる。
- CCL4濃度が低いPASCでは、リクルートシグナルの総数が減少する。
- CCR5遺伝子の多型に対するCCL4とCCL5の機能的反応の違い。CCR5遺伝子の変異体では、結合性、受容体の内在化、Ca++の流入、走化性などの機能的特徴が異なることが報告されている(47)。しかし、HIV/AIDSにおけるCCR5の多型に関する知識を考慮しても、CCR4とCCL5のCCR5との相互作用の明確なメカニズムの違いは不明である(48)。
- CCL5の代替受容体を介したシグナル伝達 CCL5は、CCR5以外にも、CCR1やCCR3という受容体を介してシグナルを伝達することができる(49)一方、CCL4の作用はCCR5に限定される。CCL4はCCR1に結合できるが、化学誘引刺激の活性化に必要な細胞内経路を誘導できないことが示されている(49)。そのため、CCL4はCCR1のアンタゴニストとして提案されている(50)が、これについてはさらなる分析が必要である。興味深いことに、CCR1は単球や好中球などの血液中の骨髄系細胞に発現しており、COVID-19患者では発現量が増加している(51)。さらに、PASCの特徴であるIFN-γの高濃度投与は、ヒト好中球上のCCR1発現の増加と関連している(52)。したがって、PASCでは、高レベルのCCL5(潜在的なCCR1アンタゴニストであるCCL4の低レベルとの組み合わせ)が、CCR1を発現している骨髄系細胞の高いリクルートをもたらす。
結論
結論として、我々は、機械学習法を用いてCOVID-19の免疫学的ランドスケープのサイトカインを分析し、PASCとSevereの個人を他のクラスから識別するバイオインフォマティクス・パイプラインを開発した。ランダムフォレスト分類法を導入することで、この判別に重要なサイトカインを特定することができ、それを用いてPASCとSevereの個体に対する高感度なヒューリスティックを算出することができた。これらのモデルは、臨床検査情報システムに組み込むことができ、COVID-19の重症感染者とPASCの免疫学的な分類を高精度に行うことができた。このワークフローは、感染者のトリアージ、治療、予後を大きく改善する可能性がある。PASC分類の特異性に影響を与える興味深い注意点として、7人の重症COVID-19患者がPASCに分類されたことが挙げられる。これは、PASC分類の特異性に影響を与える一方で、PASCに罹患する運命にある急性COVID-19患者のサブセットを表している可能性がある。
また、これらのデータは、サイトカインプロファイルに基づいて重症患者およびPASC患者を効果的に分類することで、機械学習の出力結果に導かれた精密治療により、重症度およびPASCスコアが低下し、より良好な臨床結果が得られる可能性を示している。CCR5アンタゴニズムは、重症度スコアの分子であるIL-6やVEGF(4,53)を減少させ、PASCスコアの分子であるIFN-γを減少させることがすでに実証されている(54)。