
Emergent Abilities of Large Language Models
要旨
言語モデルをスケールアップすることで、下流のさまざまなタスクで性能とサンプル効率が予測可能に向上することが示されている。本論文では、その代わりに、大規模言語モデルの創発的能力と呼ばれる予測不可能な現象について議論する。私たちは、ある能力が、小さなモデルには存在せず、大きなモデルには存在する場合、その能力は創発的であると考える。このように、創発的な能力は、小さなモデルの性能を外挿するだけでは予測することができない。このような創発の存在は、さらなるスケーリングによって言語モデルの能力の範囲をさらに拡大できる可能性があるかどうかという問題を提起している。
1 はじめに
言語モデルは、近年、自然言語処理(NLP)に革命をもたらしている。言語モデルの規模(例えば、トレーニング計算、モデルパラメータなど)を大きくすることで、下流の様々なNLPタスクの性能とサンプル効率が向上することは、今やよく知られている(Devlin et al., 2019;Brown et al., 2020、など)。多くの場合、性能に対する規模の影響は、スケーリング法則によって方法論的に予測できることが多い-例えば、クロスエントロピー損失のスケーリング曲線は、経験的に7桁以上に及ぶことが示されている(Kaplan et al., 2020;Hoffmann et al., 2022)。一方、ある種の下流タスクのパフォーマンスは、逆にスケールの関数として連続的に向上するようには見えず、そのようなタスクを事前に予測することはできない(Ganguli et al., 2022)。
創発とは、システムの量的な変化が、挙動の質的変化をもたらすことである。
ここでは、学習量とモデルパラメータ数で測定されるモデル規模に関する創発を探求する。具体的には、大規模言語モデルの創発的能力を、小規模モデルには存在しないが大規模モデルには存在する能力と定義し、小規模モデルでの性能向上を外挿するだけでは予測できない能力とする(§2)1。創発は、なぜそのような能力が獲得されるのか、より多くのスケーリングがさらなる創発能力をもたらすのか、といった今後の研究の動機付けとなり、この分野の重要な課題として取り上げる(§5)。
2 創発的能力の定義
広い概念として、創発はしばしば非公式に使用され、合理的に様々な方法で解釈することができる。本稿では、大規模な言語モデルの創発的な能力について、焦点を絞った定義を検討する:
ある能力は、より小さなモデルには存在しないが、より大きなモデルには存在する場合、創発的である。
創発的な能力は、小規模なモデルからスケーリング法則(すなわち一貫した性能向上)を外挿することによって直接予測されることはないだろう。スケーリングカーブ(X軸:モデル規模、Y軸:性能)で可視化すると、創発的な能力は明確なパターンを示す。この質的な変化は、相転移とも呼ばれ、小規模なシステムの検討では予測できなかった全体的な動作の劇的な変化である(Huberman & Hogg, 1987)。
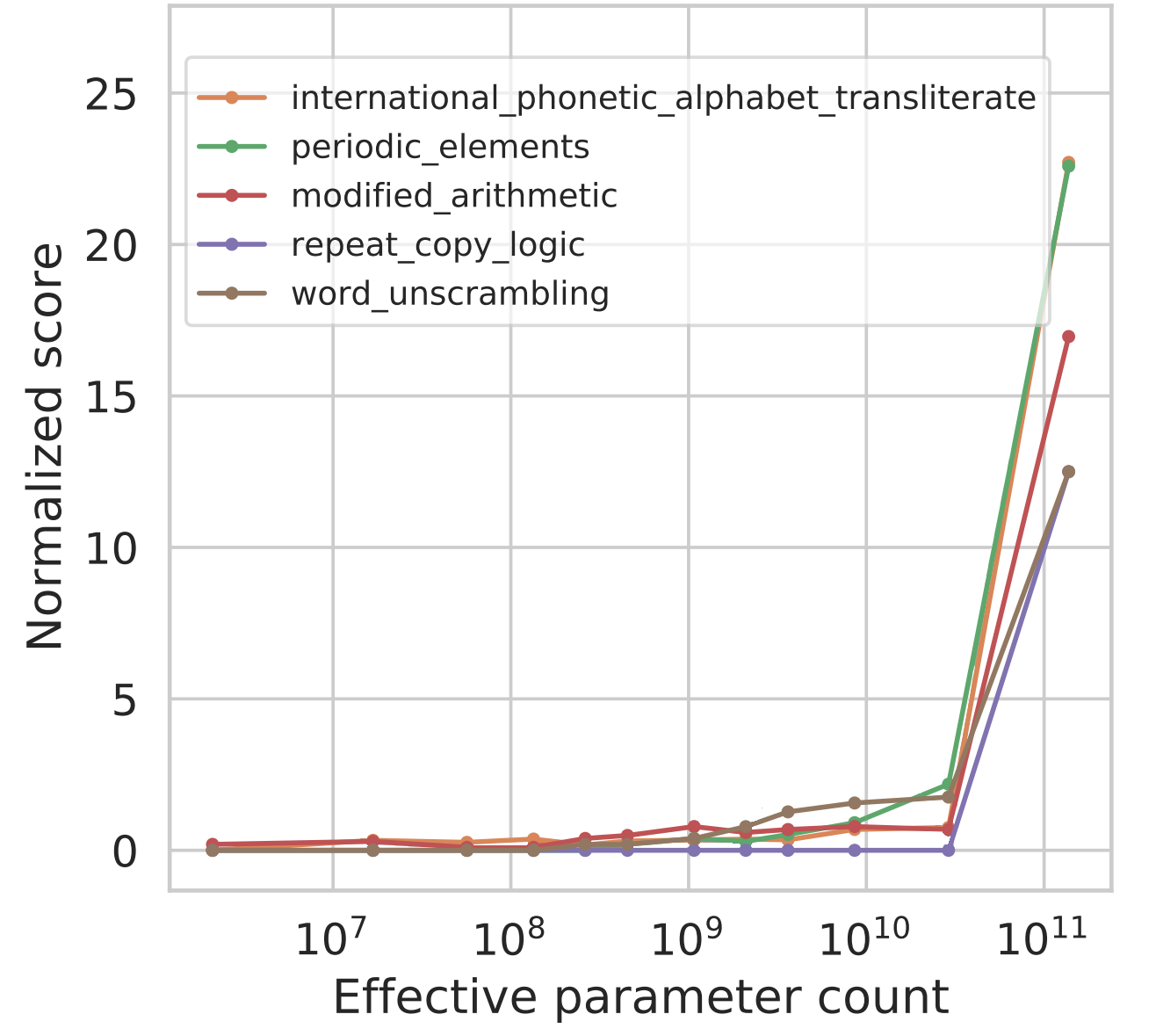
今日の言語モデルは、主に計算量、モデルパラメータ数、学習データセットサイズの3つの要素に沿ってスケーリングされている(Kaplan et al., 2020; Hoffmann et al., 2022). 本稿では、各モデルの学習計算量をX軸のFLOPsで測定し、異なるモデルの性能をプロットすることでスケーリングカーブを分析する(Hoffmann et al., 2022)。より多くの計算量で訓練された言語モデルは、より多くのパラメータを持つ傾向があるため、付録Dでは、さらにモデルパラメータの数をx軸にしたプロットを示している(図11と図12、図4と図10を参照)。訓練FLOPsまたはモデルパラメータをx軸として使用すると、ほとんどの高密度Transformer言語モデルファミリーがモデルパラメータにほぼ比例して訓練計算をスケールしている(Kaplan et al., 2020)ため、同様の形状の曲線が得られる。
訓練データセットサイズも重要な要素だが、多くの言語モデルファミリーがすべてのモデルサイズに対して固定数の訓練例を使用しているため、能力に対するプロットは行っていない(Brown et al., 2020; Rae et al., 2021; Chowdhery et al., 2022)。ここでは訓練計算とモデルサイズに焦点を当てているが、スケールのすべての側面を適切に捉える単一のプロキシは存在しない。例えば、Chinchilla(Hoffmann et al., 2022)はGopher(Rae et al., 2021)の4分の1のパラメータ数だが、同様のトレーニング計算を行う。また、スパース混合専門家モデルは、緻密モデルよりもトレーニング/推測計算あたりのパラメータ数が多い(Feds et al.) 全体として、創発を多くの相関する変数の関数として捉えることが賢明かもしれない。例えば、図4の後半では、WikiText103 perplexity (Merity et al., 2016)の関数としてemergenceもプロットするが、これはたまたまGopher/ Chinchillaのトレーニング計算と密接に相関している(ただし、長期的にはこの相関は保持されないかもしれない)。
能力の出現が最初に観察される規模は、多くの要因に依存し、能力の不変的な特性ではないことに注意してほしい。例えば、より質の高いデータで学習したモデルでは、より少ない学習量や少ないモデルパラメータで出現することがある。逆に言えば、データの量や質、モデルのパラメータ数などに制限されないことも、創発的な能力の重要な要素である。今日の言語モデルは最適に訓練されていない可能性が高く(Hoffmann et al., 2022)、モデルの最適な訓練方法に関する私たちの理解は、時間とともに進化していくだろう。本稿の目的は、創発的な能力を観察するために特定の尺度が必要であると特徴付けたり主張したりすることではなく、先行研究における創発的な動作の例について議論することである。
私たちは、数発のプロンプトの設定など、さまざまな能力が、十分に大きな言語モデルで評価された場合にのみ観察されることを見てきた。そのため、小規模なモデルでのパフォーマンスを外挿するだけでは、その出現を予測することはできない。また、プリトレーニングに含まれるタスクが明示されていないため、言語モデルが実行可能なプロンプトタスクの全容を把握できていない可能性がある。このことは、さらなるスケーリングによって、より大きな言語モデルに新たな能力が付与される可能性があるのではないかという疑問を投げかける。例えば、BIG-Benchには、最大のGPT-3やPaLMモデルでさえ、ランダム以上の性能を達成できないタスクが何十個もある(付録E.4参照)。
スケールが予測不可能に新しい技術を可能にする能力は、理論的なものだけではない。歴史的な例として、図2Hに示すWord in Context(WiC)ベンチマーク(Pilehvar & Camacho-Collados, 2019)を考えてみよう。この否定的な結果について、Brownら(2020)は、GPT-3のモデルアーキテクチャ、または(ノイズ除去訓練目的ではなく)自己回帰言語モデリング目的の使用を潜在的な理由として挙げ、救済策として双方向アーキテクチャの同規模のモデルを訓練することを示唆した。しかし、その後の研究により、デコーダのみの言語モデルをさらにスケーリングすることで、このタスクでランダム性を超える性能を実現できることがわかった。図2Hに示すように、PaLM (Chowdhery et al., 2022)を3 – 1023トレーニングFLOPs (62B parameters) から3 – 1024トレーニングにスケーリングすることで
3GPT-3は、ワンショットのプロンプトではなく、数ショットのプロンプトを使用した場合(55%)、開発セットでランダムをわずかに上回る性能を達成しているが、このランダムを上回る性能は規模の結果ではないようで、テストセットのサーバーでは保持されなかった。
FLOP(540Bパラメータ)は、Brownら(2020)が示唆するようなアーキテクチャの大幅な変更なしに、性能の大幅なジャンプにつながった。
【中略】
5.1 創発の潜在的な説明
創発的な能力の例は何十とあるが、なぜそのような能力がそのような方法で出現するのかについては、現在のところ説得力のある説明はほとんどない。ある種のタスクでは、なぜ創発が特定の閾値スケールよりも大きなモデルを必要とするのか、自然な直感があるかもしれない。例えば、多段階推論タスクがl段階の連続計算を必要とする場合、少なくともO(l)層の深さを持つモデルが必要となるかもしれない。また、より多くのパラメータとより多くの訓練により、世界知識を必要とするタスクに役立つ、より優れた記憶力が得られると考えることも妥当である4。例として、閉架式質問応答で優れた成績を収めるには、圧縮された知識ベース自体を捕らえるのに十分なパラメータを持つモデルが必要かもしれない(ただし、言語モデルベースの圧縮機は従来の圧縮機よりも圧縮率を高くできる(Bellard、2021)。
また、創発的な能力を測定するために使用される評価指標を考慮することも重要である(BIG-Bench, 2022)。例えば、長鎖目標の評価指標として文字列の完全一致を用いると、複合的な漸進的改善を創発と偽る可能性がある。同様のロジックは、多段階や算数の推論問題にも当てはまり、モデルでは、多段階の問題の最終的な答えが正しいかどうかだけが採点され、部分的に正しい解答は一切評価されないということがある。しかし、最終解答の精度が跳ね上がるだけでは、中間ステップの品質が突然ランダムを超えるようになる理由を説明できない。また、多くの分類タスク(例えば、図2D-Hのタスク)で出現した能力がまだ観察されるため、部分的に信用しない評価指標を使うことは、せいぜい不完全な説明にしかならない。
代替評価として、付録Aに詳述されているように、6つの創発的BIG-Benchタスクについて、事前学習のスケーリング則に用いられるクロスエントロピー損失を測定した。この分析は、BIG-Bench (2022)と同じ実験セットアップを踏襲し、私たちが考慮する6つの創発タスクについて彼らの結論を肯定するものである。すなわち、下流のメトリクス(完全一致、BLEU、精度)がランダムに近く、改善しない小さなモデルスケールでもクロスエントロピー損失は改善し、これは、ターゲット配列の対数尤度の改善が、そのような下流のメトリクスによってマスクされ得ることを示している。しかし、この分析では、下流のメトリクスがなぜ出現するのかを説明することはできず、出現が起こる規模を予測することもできない。全体として、スケールによって創発的な能力が発揮される要因を明らかにするためには、さらなる研究が必要である。
5.2 スケーリングを超えて
あるスケールで発生した創発的な能力を観察しても、その後、その能力がより小さなスケールで達成される可能性もある。大規模な言語モデルを学習する科学が進歩すれば、新しいアーキテクチャ、より質の高いデータ、または学習方法の改善によって、より小さなモデルでも特定の能力が解放されるかもしれない。例えば、14のBIG-Benchタスク5では、LaMDA 137BとGPT-3 175Bのモデルはランダムに近い性能を発揮するが、PaLM 62Bはモデルパラメータと学習FLOP数が少ないにもかかわらず、実際にはランダム以上の性能を発揮している。PaLM 62Bと先行モデルの違いをすべて明らかにした実証研究はないが(計算コストがかかりすぎる)、PaLMの性能が優れている理由として、高品質の訓練データ(例えば、LaMDAよりも多言語とコードのデータが多い)、アーキテクチャの違い(例えば、分割桁エンコード;Chowdheryら(2022)のセクション2参照)などが考えられるだろう。Tayら(2022c)では、Mixed-of-Denoisers目的(Tay et al., 2022a)の計算効率の良い継続的な事前学習段階により、いくつかのBIG-Benchタスクで創発的なパフォーマンスが得られることが示されている。
さらに、ある能力が発見されると、さらなる研究により、その能力がより小規模なモデルで利用できるようになるかもしれない。タスクを記述する自然言語の指示に言語モデルが従えるようにするという、新しい方向性を考えてみよう(Wei et al., 2022a; Sanh et al., 2022; Ouyang et al., 2022、特に)。Weiら(2022a)は当初、命令ベースの微調整が68Bパラメータまたはモデルに対してのみ機能することを発見したが、Sanhら(2022)は、エンコーダ-デコーダアーキテクチャを有する11Bモデルにおいて同様の動作を誘発し、これは一般的にデコーダのみのアーキテクチャよりも微調整後に高い性能を有する(Wangら, 2022a)。別の例として、Ouyangら(2022)は、InstructGPTモデルに対して、人間のフィードバックからの微調整と強化学習アプローチを提案し、これにより1.3Bモデルが、幅広いユースケースにおける人間の評価において、はるかに大きなモデルを上回ることができた。
また、言語モデルの一般的な数発プロンプト能力の向上に関する研究も行われている(Gao et al, 2021; Schick & Schütze, 2021, 特に)。言語モデリングの目的がなぜ特定の下流動作を促進するのかについての理論的および解釈可能性の研究(Wei et al., 2021a;Saunshi et al., 2021)は、今度は、単にスケーリングを超えた創発を可能にする方法について示唆することができる。例えば、事前学習データの特定の特徴(長距離コヒーレンス、多くのレアクラスを持つなど)は、創発的な数発プロンプトと相関することが示されており、より小さなモデルでそれを可能にする可能性がある(Xie et al., 2022; Chan et al., 2022)。計算言語学の研究では、モデルパラメータとトレーニングFLOPを一定に保った場合、トレーニングデータの閾値頻度が創発的な構文ルール学習を活性化することがさらに示されており(Wei et al., 2021b)、心理言語学の文献に見られるような印象深い「アハ」な瞬間があることさえ示されている(Abend et al, 2017; Zhang et al., 2021)。言語モデルのトレーニングを続ける中で、創発能力のスケール閾値を下げることは、そのような能力に関する研究をより広くコミュニティに提供するために、より重要になるだろう(Bommasani et al., 2021; Ganguli et al., 2022; Liang et al., 2022)。
当然ながら、スケール(トレーニング計算量、モデルパラメータ、データセットサイズ)の増加のみで構成されるプログラムには限界がある。例えば、スケーリングは最終的にハードウェアの制約によってボトルネックになる可能性があり、この時点ではいくつかの能力は出現していないかもしれない。例えば、非常に大きなトレーニングデータセットでも、その分布から大きく外れたタスクは、大きな性能を達成できないかもしれない。言い換えれば、スケーリングによって能力が望ましいレベルに達するという保証はない。
5.3 創発の別の見方
これまでのところ、スケール(学習FLOPsやモデルパラメータなど)は、多くのダウンストリームメトリクスにおける言語モデル性能と高い相関があるが、スケールが創発能力を見る唯一のレンズとなる必要はない。例えば、WikiText103(Merity et al., 2016)のような一般的なテキストコーパスにおける言語モデルの当惑度の関数として、タスク固有の能力の出現を分析することができる。図4は、X軸に言語モデルのWikiText103のパープレキシティ、Y軸にMMLUベンチマークのパフォーマンスを、X軸に学習FLOPsとモデルパラメータのプロットと並べて、そのようなプロットを示している。
今回検討したモデル(GopherとChinchilla)では、WikiText103の当惑度と学習FLOPsが偶然にも高い相関を持つため、出現能力のプロットは両者で類似しているように見える。しかし、バニラ密なTransformerモデル以外の新しい技術が開発されれば、WikiText103 perplexityと規模の間のこの相関は将来的に保たれないかもしれない(例えば、検索を強化したモデルは、より少ない訓練計算とより少ないモデルパラメータで強いWikiText103 perplexityを持っているかもしれない(Borgeaud他、2021)。また、モデルファミリー間の比較にWikiText103 perplexityを使用すると、訓練データの構成の違いなどの要因で複雑になる可能性があることに注意してほしい。全体として、創発的な能力は、おそらく多くの相関する変数の関数として見るべきだ。
5.4 顕在化するリスク
重要なことは、事前訓練に明示的に含まれなくても、数発のプロンプト設定で顕在化する能力が観察されたのと同様に、リスクも顕在化しうることである(Bommasani et al, 2021; Steinhardt, 2021; Ganguli et al, 2022)。例えば、真実性、偏り、毒性といった大規模言語モデルの社会的リスクは、研究分野が拡大している(Weidinger et al., 2021)。このようなリスクは、§2の定義に基づき「創発的」として正確に特徴づけられるかどうかに関わらず重要な検討事項であり、シナリオによっては、モデル規模に応じて増加する(Inverse Scaling Prize6を参照)。創発的な能力に関する研究は、言語モデルのスケーリングにインセンティブを与えるので、創発的でなくても、モデルのスケールに伴って増大するリスクに注意することが重要である。
ここでは、特定の社会的リスクとモデル規模との関係について、いくつかの先行研究結果を要約する。「看護師」や「電気技師」などの職業におけるジェンダーバイアスを測定するWinoGender(Rudinger et al., 2017)では、スケーリングによってこれまでのところ性能が向上しているが(Du et al., 2021; Chowdhery et al., 2022)、BBQバイアスベンチマーク(Parrish et al., 2022)で、曖昧な文脈ではスケーリングによりバイアスが増加することがあるとBIG-Benchが発見した。毒性に関しては、Askellら(2021)は、RealToxicityPromptsデータセット(Gehman et al., 2020)から、より大きな言語モデルがより毒性の強い応答を生成できる一方で、「役に立つ、無害、正直」という例をモデルに促すことでこの挙動が緩和されることを発見した。言語モデルからの学習データの抽出については、大規模なモデルほど学習データを記憶しやすいことが判明したが(Carlini et al., 2021; 2022)、重複排除法が提案されており、性能を向上させながら同時に記憶量を減らすことができる(Kandpal et al., 2022; Lee et al., 2022a)。TruthfulQAベンチマーク(Lin et al., 2021)は、GPT-3モデルが大きくなると人間の虚偽を模倣しやすくなることを示したが、Raeら(2021)は後に、Gopherを280Bにスケーリングするとランダムよりも大幅に優れた創発性能が得られることを複数選択式バージョンで示している。
上記以外にも、創発的リスクには、将来の言語モデルにのみ存在するかもしれない現象や、現在の言語モデルではまだ特徴付けされていない現象が含まれる。Hendrycksら(2021b)で詳細に議論されているように、そのような動作の中には、バックドア脆弱性、不注意な欺瞞、または有害なコンテンツ合成があり得る。出現したリスクを発見し緩和するために、データのフィルタリング、予測、ガバナンス、有害な行動の自動発見を含むアプローチが提案されている(Bender et al., 2021; Weidinger et al., 2021; Steinhardt, 2021; Ganguli et al., 2022; Perez et al., 2022、とりわけ)。大規模言語モデルのリスクについては、創発的なリスクも含めて、Benderら(2021);Steinhardt(2021);Bommasaniら(2021);Ganguliら(2022)を参照してほしい。
5.5 社会学的変化
最後に、ここで取り上げた創発的能力はモデル動作に焦点を当て、NLPにおけるいくつかのタイプの創発の一つに過ぎない(Manning他、2020;Teehan他、2022)。質的変化のもう一つの注目すべきタイプは社会学的なもので、規模の拡大がコミュニティの言語モデルの見方や使い方を変化させている。例えば、NLPは歴史的にタスクに特化したモデルに焦点を当ててきた(Jurafsky & Martin, 2009)。最近では、スケーリングによって、学習データに明示的にコード化されていないさまざまなタスクを実行することを目的とした単一モデル(GPT-3、Chinchilla、PaLMなど)である「汎用」モデルの研究と開発が爆発的に増加している(Manning、2022)。
汎用モデルへの社会学的なシフトが出現したときの重要な結果の1つは、スケーリングによって、数発のプロンプトを出した汎用モデルが、細かいタスクに特化したモデルによって保持されていた以前の技術状態を凌駕するときである。いくつかの例として、GPT-3 175BはTriviaQAとPiQAの質問応答ベンチマークで新たな最先端技術を達成し(Brown et al., 2020)、PaLM 540Bは3つの算術推論ベンチマークで新たな最先端技術を達成し(Chowdhery et al., 2022)、マルチモーダルフラミンゴ80Bモデルは6の視覚質問応答ベンチマークで新しい最先端を達成している(Alayrac et al.) これらすべてのケースで、前例のない規模の言語モデルを数発プロンプトすることで最先端の性能が達成された(これらの例のスケーリングカーブは付録図13に示されている)。これらの能力は、滑らかで予測可能なスケーリングカーブを持つため、必ずしも創発的なものではないが、NLPコミュニティにおける汎用モデルへの社会的なシフトが現れていることを裏付けている。
また、汎用モデルがわずかな例で未知のタスクを実行できるようになったことで、NLP研究コミュニティの外でも言語モデルの新しい用途が多数生まれている。例えば、言語モデルはプロンプトを介して、自然言語の指示をロボットで実行可能なアクションに変換したり(Ahn et al., 2022; Huang et al., 2022)、ユーザーと対話したり(Coenen et al., 2021; Wu et al., 2021; 2022a; Lee et al., 2022b)、マルチモーダル推論(Zeng et al., 2022; Alayrac et al., 2022)したりして使われている。大規模な言語モデルは、GitHub CoPilotのような製品7や、OpenAIのGPT-3 APIのようなサービスそのものとして直接、実世界に導入されている8。
5.6 今後の方向性
創発的能力に関する今後の研究には、より能力の高い言語モデルの訓練や、言語モデルにタスクを実行させるためのより良い方法が含まれる可能性がある。可能性のある方向性としては、以下のようなものがあるが、これらに限定されるものではない。
モデルのさらなるスケールアップ。これまでのところ、モデルをさらにスケールアップすることで言語モデルの能力を向上させることができると考えられており、今後の研究の方向性として真っ当なものである。しかし、言語モデルを単純にスケールアップすることは計算コストが高く、ハードウェアの課題を解決する必要があるため、大規模言語モデルの創発的な能力の将来において、他のアプローチが重要な役割を果たすと考えられる。
モデルアーキテクチャとトレーニングの改善モデルのアーキテクチャとトレーニング方法を改善することで、計算コストを抑えながら、高品質な創発能力を持つモデルを容易に作成できる可能性がある。一つの方向性は、入力の計算コストを一定に保ちながらモデルのパラメータ数をスケールアップする、スパースmixture-of-expertsアーキテクチャ(Lepikhin et al., 2021;Fedus et al., 2021;Artetxe et al., 2021;Zoph et al., 2022)の使用である。計算効率を向上させる他の方向性としては、異なる入力に対して計算量を可変にする(Graves, 2016; Dehghani et al., 2018)、ニューラルネットワークのすべての重みを通じたバックプロパゲーションよりも局所的な学習戦略を用いる(Jaderberg et al., 2017)、外部メモリでモデルを拡張する(Guu et al., 2020; Borgeaud et al., 2021; Wu et al., 2022b、など)などが考えられる。これらの新進的な方向性は、すでに多くの場面で有望視されているが、まだ広く採用されるには至っておらず、さらなる研究が必要であろう。
データのスケーリング。言語モデルが構文、意味、およびその他の世界の知識を獲得する能力には、十分な大きさのデータセットで十分に長い時間訓練することが重要であることが示されている(Zhang et al., 2021; Wei et al., 2021b; Razeghi et al., 2022)。最近、Hoffmannら(2022)は、先行研究(Kaplan et al., 2020)が計算機最適モデルの訓練に必要な訓練データの量を過小評価していると主張し、訓練データの重要性を強調した。大規模なデータセットを収集し、モデルをより長く訓練できるようにすることで、固定されたモデルサイズの制約のもとで、より幅広い能力の出現を可能にすることができる。
プロンプティングの技術向上と理解数発のプロンプト(Brown et al., 2020)はシンプルで効果的だが、プロンプトの一般的な改善により、言語モデルの能力をさらに拡大できる可能性がある。例えば、出力確率の較正(Zhao et al., 2021; Holtzman et al., 2021)やノイズチャンネルの使用(Min et al., 2022a)といった単純な改良は、様々なタスクでパフォーマンスを向上させている。また、数発の模範例を中間ステップで補強すること(Reynolds & McDonell, 2021; Nye et al., 2021; Wei et al., 2022b)で、ブラウンら(2020)の標準プロンプティング定式では不可能な多段階推論タスクをモデルが実行することが可能となった。さらに、プロンプトを成功させる要因(Wei et al., 2021a; Xie et al., 2022; Min et al., 2022b; Olsson et al., 2022)をよりよく探求することで、より小さなモデルスケールで創発能力を引き出す方法に関する洞察を得ることができる。一般に、モデルが機能する理由についての十分な理解は、数発プロンプトのような技法の開発と普及に遅れる。また、より強力なモデルが時間をかけて開発されるにつれて、プロンプトのベストプラクティスが変化する可能性もある。
フロンティアタスク。言語モデルは様々なタスクをこなすことができるが、現在までの最大規模の言語モデルでも、ランダム以上の精度でこなすことができないタスクもまだ多く存在する。BIG-Benchの数十のタスクが付録E.4に列挙されている。これらのタスクは、しばしば抽象的な推論(例えば、チェスのプレイ、数学への挑戦など)を含む。今後の研究では、なぜこのような能力がまだ現れていないのか、どうすればモデルがこのようなタスクを実行できるようになるのかを調査できる可能性がある。多言語BIG-Benchタスクの結果は、モデルのスケールとトレーニングデータの両方が出現に役割を果たすことを示している(例えば、図2Dは、ペルシア語の質問応答には、PaLMのトレーニングデータセットを使用することと62Bパラメータへのスケーリングの両方が必要なことを示している)。他のフロンティアタスクには、複数のモダリティでのプロンプトが含まれる可能性がある(Alayrac et al., 2022; Ramesh et al.)
創発を理解する。さらなる創発を解き明かす研究を超えて、今後の研究のためのオープンな疑問は、大規模な言語モデルでどのように、そしてなぜ創発能力が発生するかということである。本論文では、BIG-Benchにおけるクロスエントロピー損失のスケーリング(付録A.1)、生成タスクの異なるメトリクス(付録A.2)、どのようなタスクで創発が発生するか(付録A.3および付録B)に関する初期分析を行った。これらの分析は、なぜ創発が起こるのか、どのように予測するのかについて、完全な答えを提供するものではなかった。今後の研究では、新たな方法で創発を分析できる可能性がある(例えば、創発タスクとトレーニングの類似データとの関係を分析する、複数の構成的なサブタスクを必要とする合成タスクを作成し、それらのサブタスクのそれぞれが規模に応じてどのように改善し、組み合わせたときに創発を解除するかを評価するなど)。全体として、創発を理解することは、将来のモデルがどのような能力を持つかを予測できる可能性があり、また、より能力の高い言語モデルの訓練方法について新しい洞察を提供することができるため、重要な方向である。
6 まとめ
ここまで、言語モデルの創発的な能力について述べてきたが、意味のある性能は、ある計算量においてのみ観察されている。創発的な能力は、様々な言語モデル、タスクタイプ、実験シナリオにまたがることができる。このような能力は、言語モデルのスケールアップによって最近発見されたものであり、どのように出現するのか、スケールアップによってさらなる出現能力が可能になるのかという疑問は、NLP分野にとって重要な将来の研究方向であると思われる。