Contents

An Overview of Catastrophic AI Risks
著者 ダン・ヘンドリクスマンタス・マゼイカトーマス・ウッドサイド
破滅的AIリスクの概要
ダン・ヘンドリックス
マンタス・マゼイカ
トーマス・ウッドサイド
要旨
人工知能(AI)の急速な進歩により、専門家、政策立案者、世界の指導者たちの間で、高度化するAIシステムが壊滅的なリスクをもたらす可能性に対する懸念が高まっている。数多くのリスクについては個別に詳述されているが、潜在的な危険性を軽減するための取り組みをより的確に伝えるために、体系的な議論と図解が急務となっている。
本稿では、大惨事を引き起こすAIリスクの主な原因を4つのカテゴリーに分類し、その概要を説明する。すなわち、個人または集団が意図的にAIを使用して危害を加える「悪意のある使用」、競争環境が行為者に安全でないAIの配備やAIへの制御の委譲を強いる「AI競争」、人間的要因と複雑なシステムがいかに大惨事事故の可能性を高めるかを強調する「組織的リスク」、人間よりもはるかに知的なエージェントを制御することの本質的な難しさを説明する「不正AI」である。
リスクの各カテゴリーについて、具体的な危険性を説明し、例示的なストーリーを提示し、理想的なシナリオを想定し、これらの危険を軽減するための実践的な提案を行う。私たちの目標は、これらのリスクに対する包括的な理解を促進し、AIが安全な方法で開発・導入されるよう、集団的かつ積極的な取り組みを促すことである。最終的には、大惨事を招く可能性を最小限に抑えながら、この強力なテクノロジーの恩恵を享受できるようになることを願っている1。
要旨
人工知能(AI)は近年急速な進歩を遂げ、AIの専門家、政策立案者、世界の指導者たちの間で、高度なAIがもたらす潜在的リスクに対する懸念が高まっている。あらゆる強力なテクノロジーと同様に、AIはリスクを管理し、その潜在能力を社会の向上のために活用するために、大きな責任を持って扱われなければならない。しかし、AIの破滅的リスクや存亡に関わるリスクがどのように発生するのか、あるいはどのように対処するのかについて、アクセス可能な情報は限られている。このテーマに関する情報源は数多く存在するが、それらは様々な論文に分散している傾向があり、狭い読者を対象にしていたり、特定のリスクに焦点を当てていたりすることが多い。本稿では、AIの破滅的リスクの主な原因について概観し、4つのカテゴリーに整理する:
悪意のある利用
悪意のある利用。行為者は意図的に強力なAIを利用し、広範な被害をもたらす可能性がある。具体的なリスクとしては、人間が致命的な病原体を作り出すのを助けることができるAIが可能にするバイオテロ、制御不能なAIエージェントの意図的な拡散、プロパガンダ、検閲、監視のためのAI能力の使用などがある。これらのリスクを減らすために、バイオセキュリティを改善し、最も危険なAIモデルへのアクセスを制限し、AIシステムによって引き起こされた損害についてAI開発者に法的責任を負わせることを提案する。
AI競争
競争が国家や企業に圧力をかけ、AIの開発を急がせ、AIシステムに支配権を譲り渡す可能性がある。軍は自律型兵器を開発し、サイバー戦争にAIを使用する圧力に直面し、人間が介入する前に事故が制御不能に陥るような、新しい種類の自動化戦争を可能にするかもしれない。企業も同様に、人間の労働力を自動化し、安全性よりも利益を優先するインセンティブに直面し、大量失業とAIシステムへの依存を招く可能性がある。また、進化的な圧力が長期的にAIをどのように形成するかも議論する。AI間の自然淘汰は利己的な形質をもたらすかもしれないし、AIが人間に対して持つ優位性は、最終的に人類の居場所を奪うことにつながるかもしれない。AI競争によるリスクを軽減するために、安全規制、国際協調、汎用AIの公的管理の実施を提案する。
組織的リスク
組織の事故は、チェルノブイリ、スリーマイル島、チャレンジャー・スペースシャトル事故などの災害を引き起こしてきた。同様に、先進的なAIを開発・配備する組織は、特に強固な安全文化を持っていない場合、壊滅的な事故に見舞われる可能性がある。AIが誤って一般に流出したり、悪意のある行為者によって盗まれたりする可能性もある。組織が安全性研究に投資しなかったり、一般的なAIの能力よりも早くAIの安全性を確実に向上させる方法を理解していなかったり、AIのリスクに関する社内の懸念を抑圧したりする可能性がある。こうしたリスクを低減するためには、内部監査や外部監査、リスクに対する多層防御、最先端の情報セキュリティなど、より優れた組織文化や構造を確立することができる。
不正なAI
一般的かつ深刻な懸念は、AIが私たちよりも賢くなるにつれて、私たちがAIを制御できなくなる可能性があることだ。AIは、プロキシゲーミングと呼ばれるプロセスで、極端なまでに欠陥のある目標を最適化する可能性がある。AIは変化する環境に適応する過程で、人が生涯を通じて目標を獲得したり失ったりするのと同じように、目標のドリフトを経験する可能性がある。場合によっては、AIが権力を求めるようになることは、道具的に合理的かもしれない。また、どのように、そしてなぜAIが欺瞞に走るのか、コントロールされていないにもかかわらずコントロールされているように見えるのかについても考察する。これらの問題は、最初の3つのリスク源よりも技術的なものである。私たちは、AIが制御可能であることを保証する方法についての理解を深めるために、推奨される研究の方向性を概説する。
各セクションを通して、リスクの原因がどのように破滅的な結果をもたらすか、あるいは存続の脅威にさえなりうるかを、より具体的に示す例示的なシナリオを提供する。リスクが適切に管理された、より安全な未来というポジティブなビジョンを提示することで、AIの新たなリスクは深刻ではあるが、克服できないものではないことを強調する。これらのリスクに積極的に対処することで、破滅的な結果を招く可能性を最小限に抑えつつ、AIの恩恵の実現に向けて取り組むことができる。
目次
- 1 はじめに
- 2 悪意のある利用
- 2.1 バイオテロリズム .
- 2.2 AIエージェントの解放
- 2.3 説得力のあるAI
- 2.4 権力の集中 .
- 2.5 提案 .
- 3 AI競争
- 3.1 軍事AIの軍拡競争 .
- 3.1.1 致死的自律兵器(LAWs) .
- 3.1.2 サイバー戦争
- 3.1.3 自動化された戦争 .
- 3.1.4 俳優は個人の敗北よりも絶滅のリスクを冒すかもしれない。
- 3.2 企業のAI競争 .
- 3.2.1 安全性を損なう経済競争 .
- 3.2.2 自動化された経済 .
- 3.3 進化の圧力 .
- 3.4 提案 .
- 3.1 軍事AIの軍拡競争 .
- 4 組織のリスク
- 4.1 事故を避けることは難しい。
- 4.2 組織的要因は大惨事の可能性を減らすことができる
- 4.3 提案 .
- 5 不正なAI
- 5.1 代理ゲーミング
- 5.2 ゴールドリフト
- 5.3 権力追求 .
- 5.4 欺瞞
- 5.5 提案 .
- 6 リスク間の関連性の考察
- 7 まとめ
- よくある質問
1 はじめに
私たちが知っている世界は普通ではない。何千キロも離れた人と瞬時に話ができたり、1日足らずで地球の裏側まで飛んだり、ポケットに入れて持ち歩く機器から膨大な知識の山にアクセスできたりすることを、私たちは当たり前のことだと思っている。これらの現実は、数十年前までは突飛に思え、数世紀前の人々には想像もできなかったことだろう。私たちの生活、仕事、旅行、コミュニケーションの方法は、人類の歴史のごく一部でしか実現されていない。
しかし、より大きな視野で見れば、加速度的な発展という、より広範なパターンが浮かび上がってくる。ホモ・サピエンスが地球上に出現してから農業革命が起こるまでに数十万年が経過した。その後、産業革命が起こるまでに数千年が経過した。それからわずか数百年後の今、人工知能(AI)革命が始まろうとしている。歴史の歩みは一定ではなく、急速に加速している。
この傾向を定量的に捉えることができるのが、推定世界総生産の経年変化を示した図1である[1, 2]。
この図が描く双曲線的な成長は、技術が進歩するにつれて、技術進歩の速度も増加する傾向にあるという事実によって説明できるかもしれない。新しい技術を手に入れた人々は、以前よりも速く技術革新を行うことができる。こうして、それぞれのブレイクスルー発展の間の時間差は縮まっていく。
現代が人類史上未曾有の時代であるのは、技術の高度化もさることながら、発展のペースが速いからだ。技術の進歩は、人間が生きている間に世界を見違えるほど変えてしまう可能性がある。例えば、インターネットが誕生した時代を生きてきた人々は、現在デジタルで結ばれた世界がSFのように思えたであろう時代を思い出すことができる。
歴史的な観点から見ると、同じ開発量をさらに短期間に凝縮できる可能性がある。そうなるとは断言できないが、そうならないとも言い切れない。そこで、次の大きな加速をもたらす新技術は何だろうか?
最近の進歩を鑑みると、AIはますます有力な候補になりそうだ。おそらく、AIがさらに強力になるにつれて、世界はこれまで経験したことのないような質的な変化を遂げるかもしれない。それは歴史上最も衝撃的な時代になるかもしれないが、最後の時代になるかもしれない。
世界総生産、紀元前1万年 2019年
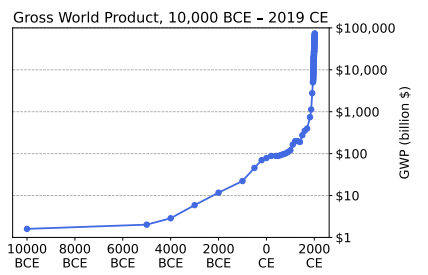
図1:人類の歴史の中で、世界の生産は急速に成長してきた。AIはこの傾向をさらに強め、人類を前例のない新たな変化の時代へと飛躍させる可能性がある。
技術の進歩はしばしば人々の生活を向上させてきたが、技術が力を増すにつれ、その破壊的な可能性も増すことを忘れてはならない。核兵器の発明を考えてみよう。前世紀、私たちの種の歴史上初めて、人類は自らを破壊する能力を持ち、世界は突然、より脆くなった。
新たに発見された私たちの脆弱性は、冷戦の最中に気の遠くなるような鮮明さで明らかになった。1962年10月の土曜日、キューバ危機は制御不能に陥っていた。キューバを封鎖していたアメリカの軍艦がソ連の潜水艦を探知し、低爆薬の爆雷を投下して浮上させようとした。その潜水艦は無線連絡がとれず、乗組員は第三次世界大戦がすでに始まっているのかどうかもわからなかった。換気装置の故障により、潜水艦の一部では温度が140℃まで上昇し、近くで爆雷が爆発したため乗組員が意識を失った。
この潜水艦は核武装魚雷を搭載しており、発射には艦長と政務官の同意が必要だった。両者とも同意した。あの日キューバ海域にいた他の潜水艦なら、この魚雷は発射され、核を使った第三次世界大戦が起こっていたかもしれない。幸運なことに、 ヴァシーリイ・アルキポフ・アルキポフという人物も潜水艦に乗っていた。アルキポフは船団全体の指揮官で、偶然にもその潜水艦に乗っていたのだ。彼は艦長の怒りを鎮め、モスクワからのさらなる命令を待つよう説得した。彼は核戦争を回避し、何百万、何十億もの命、そしておそらく文明そのものを救ったのである。
10月28日
ヴァシーリイ・アルヒーポフ、今日が第3次世界大戦の60周年にならないようにしてくれてありがとう。あなたがしたことは、現代史の中で最も価値のある行為だと思う。 t.co/NOgCYXd0W5— Alzhacker (@Alzhacker) October 30, 2022
悪意のある利用 AI競争 組織的リスクいたずらAI バイオテロ監視国家のアクセス制限法的責任
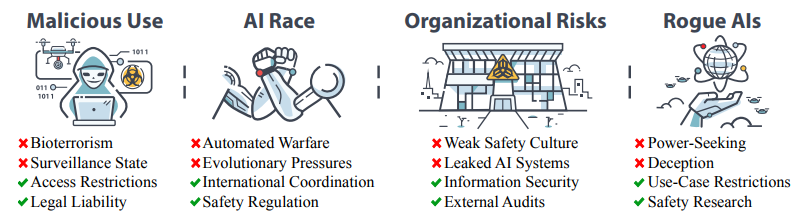
図2:本稿では、AIのリスクを4つのカテゴリーに分類し、それらを軽減する方法について論じる。
カール・セーガンはかつて、「知恵ではなく力だけを蓄積し続ければ、私たちは必ず自滅する」と述べている[3]。
セーガンは正しかった。核兵器の威力は、私たちが準備できるものではなかった。全体的に見て、人類を核による滅亡から救ったのは知恵よりもむしろ運であり、一個人が全面的な核戦争を防いだ例が複数記録されている。
AIは今、核兵器と同様の破壊力を持つ強力なテクノロジーになろうとしている。私たちはキューバ危機を繰り返したくない。私たちは、このテクノロジーを賢く使う能力ではなく、私たちの生存が運に左右されるような危機的状況には陥りたくない。その代わりに、私たちはこの技術がもたらすリスクを軽減するために積極的に取り組む必要がある。そのためには、何がうまくいかない可能性があり、それに対してどうすべきかをよりよく理解する必要がある。
幸いなことに、AIシステムはまだ私たちが議論するすべてのリスクに寄与するほどには進歩していない。しかし、AIの開発が前例のない予測不可能なスピードで進んでいる現在、それは気休めにもならない。私たちは、現在のAIと近い将来存在するであろうAIの両方から生じるリスクについて考察する。より高度なシステムの開発を待ってから対策を講じたのでは、手遅れになる可能性もある。
本稿では、強力なAIが膨大な数の人々に壊滅的な結果をもたらす大惨事をもたらす可能性がある様々な方法を探る。また、AIがどのような人類存亡リスク、つまり人類が立ち直れなくなるような大災害をもたらす可能性があるかについても議論する。そのようなリスクとして最も明らかなのは絶滅だが、恒久的なディストピア社会の形成など、他の結果も実存的カタストロフとなる。可能性のあるカタストロフを数多く概説するが、そのうちのいくつかは他のものよりも可能性が高く、互いに相容れないものもある。このアプローチは、リスク管理の原則に動機づけられている。私たちは、大惨事が起こるのを待つのではなく、「何が起こり得るか」を問うことを優先する。このプロアクティブな考え方により、手遅れになる前に大惨事のリスクを予測し、軽減することができる。
議論の方向性を定めるために、私たちはAIによる破局的リスクを、介入を正当化する4つのリスク源に分解する:
- 悪意のある利用: 悪意のある行為者がAIを使って大規模な破壊を引き起こす。
- AI競争: 競争圧力により、誰の利益にもならないにもかかわらず、安全でない方法でAIを導入する可能性がある。
- 組織的リスク: AIとそれを開発する組織の複雑さから生じる事故。
- 不正なAI: 私たちよりも知的なテクノロジーをコントロールする問題。
悪意のある使用、AI競争、組織的リスク、不正なAIという4つのセクションは、それぞれ意図的、環境・構造的、偶発的、内部的なAIリスクの原因について述べている[4]。
各リスクの具体的で小規模な事例が、どのようにエスカレートして破滅的な結果に至るかを説明する。また、各セクションで議論されている様々なプロセスやダイナミクスを読者が概念化するのに役立つように、仮想的なストーリーを盛り込み、ネガティブな結果を回避するための実践的な安全性の提案も行う。各セクションの最後には、そのリスクを軽減するための理想的なビジョンを描いている。本調査が、AIの破滅的リスクについて学び、それを軽減することに関心のある読者にとって、実用的な入門書となることを願っている。
2 悪意のある利用
1995年3月20日の朝、5人の男が東京の地下鉄に乗り込んだ。彼らは別々の路線に乗り込んだ後、数駅停車した後、持っていたバッグを下ろして出て行った。バッグの中の無味無臭の液体が蒸発し始めた。数分もしないうちに、通勤客が窒息したり嘔吐したりし始めた。列車は東京の中心部に向かって走り続け、気分が悪くなった乗客は各駅で車両を降りた。ガスは、汚染された車両から発散されたり、人々の衣服や靴に接触したりして、各停車駅で広がった。その日の終わりまでに、13人が死亡し、5,800人が重傷を負った。このテロを引き起こしたのは、オウム真理教である[5]。
罪のない人々を殺害した動機は? 世界の終末をもたらすためだ。
強力な新技術は多大な潜在的利益をもたらすが、同時に悪意ある行為者に広範な被害をもたらす力を与える危険性もはらんでいる。悪意を持つ者は常に存在し、AIは彼らに目的を達成するための強力な手段を提供する可能性がある。さらに、AI技術が進歩すればするほど、悪意ある利用が社会を不安定化させ、他のリスクを引き起こす可能性が高まる。
このセクションでは、高度なAIの悪意ある利用が破滅的なリスクをもたらす可能性のある様々な方法を探る。これには、生物化学兵器の設計、不正なAIの解放、説得力のあるAIを使ったプロパガンダの拡散とコンセンサス・リアリティの侵食、検閲と大規模監視を活用した不可逆的な権力の集中などが含まれる。最後に、AIの悪意ある使用に関連するリスクを軽減するための可能な戦略について議論する。
一方的な行為者は、悪意ある使用のリスクを大幅に増大させる。多数の行為者が強力な技術や有害な目的に使用されうる危険な情報にアクセスできる場合、たった一人の個人で大きな破壊を引き起こすことができる。悪意のある行為者自身がその最も明確な例だが、無謀な行為も同様に危険である。例えば、ある研究チームが、生物学的研究機能を備えたAIシステムをオープンソース化することに興奮するかもしれない。それは研究を加速させ、人命を救う可能性があるからだが、そのAIシステムが生物兵器の開発に再利用される可能性があれば、悪意のある利用のリスクも高まることになる。このような状況では、最もリスクを回避しない研究グループによって結果が決まるかもしれない。ある研究グループだけが、メリットがリスクを上回ると考えれば、他のほとんどの研究グループが同意しなくても、そのグループが一方的に行動し、結果を決定する可能性がある。そして、もし彼らが間違っていて、誰かが生物兵器の開発を決めたとしても、軌道修正するには遅すぎるだろう。
デフォルトでは、高度なAIは、最も強力な者と一般大衆の両方の破壊能力を高めるかもしれない。このように、悪意ある行為者に力を与えるAIの可能性の増大は、人類が今後数十年間に直面するであろう最も深刻な脅威の一つである。このセクションで挙げた例は、私たちが予見できるものに過ぎない。現在私たちが想像もできないような危険な新技術の創造をAIが支援する可能性もあり、悪意のある利用によるリスクはさらに高まるだろう。
2.1 バイオテロリズム
AI技術の急速な進歩は、バイオテロのリスクを増大させる。生物工学の知識を持つAIは、新型生物兵器の作成を容易にし、そのような薬剤を入手する障壁を低くする可能性がある。AIが支援する生物兵器による人工パンデミックは、攻撃者が防御者よりも優位に立つというユニークな課題をもたらし、人類にとって存亡の脅威となる可能性がある。ここでは、これらのリスクと、AIがバイオテロや人工パンデミックの管理における課題をどのように悪化させるかを検証する。
バイオテクノロジーによるパンデミックは新たな脅威である。ウイルスやバクテリアなどの生物学的病原体は、歴史上最も壊滅的な大災害を引き起こしてきた。黒死病は歴史上のどの出来事よりも多くの人間を殺したと考えられており、その数は驚くべきことに2億人、今日の40億人の死者に匹敵する。現代の科学と医学の進歩は、自然のパンデミックに関連するリスクを軽減する上で大きな進歩を遂げたが、人工的なパンデミックは、自然のパンデミックよりも致死率が高く、感染しやすいように設計される可能性があり、歴史上最も致命的な疫病がもたらした壊滅的な被害と同等か、それ以上の新たな脅威をもたらす可能性がある[6]。
人類には病原体を武器化した長く暗い歴史があり、紀元前1320年にさかのぼる記録には、小アジアで感染した羊が国境を越えて駆逐され、野兎病を蔓延させたという戦争が記されている[7]。
20世紀には、アメリカ、ソ連、イギリス、フランスを含む15カ国が生物兵器を開発したことが知られている。化学兵器と同様、生物兵器も国際社会のタブーとなっている。一部の国家主体は生物兵器プログラムを運用し続けているが[8]、より重大なリスクは、オウム真理教、ISIS、あるいは単なる不穏分子のような非国家主体からもたらされる可能性がある。AIやバイオテクノロジーの進歩により、冷戦時代の生物兵器プログラムをはるかに超える能力を持つ病原体を作り出すのに必要なツールや知識は、急速に民主化されていくだろう。
バイオテクノロジーは急速に進歩し、より利用しやすくなっている。数十年前、新しいウイルスを合成する能力は、最先端の研究所で働く一握りのトップ科学者に限られていた。現在では、新しい病原体を作り出す才能、訓練、技術へのアクセスを持つ人が3万人いると推定されている[6]。
この図は急速に拡大する可能性がある。カスタム生物学的製剤の作成を可能にする遺伝子合成の価格は急激に下がり、そのコストは約15カ月ごとに半額になっている[9]。
さらに、卓上型DNA合成機の出現により、アクセスははるかに容易になり、既存の遺伝子合成スクリーニングの努力を回避することができるようになり、このような技術の普及を制御することが複雑になっている[10]。
生物工学によって作られたパンデミックが何百万人、おそらく何十億人を殺す可能性は、それを合成する技術とアクセスを持つ人々の数に比例する。AIアシスタントを使えば、桁違いに多くの人々が必要なスキルを持つことができ、リスクは桁違いに高まる。

図3:AIアシスタントは、生物化学兵器の製造に必要な指示や設計へのアクセスを非専門家に提供し、悪意のある使用を促進する可能性がある。
AIは、より致死性の高い新たな化学・生物兵器の発見を促進するために使われる可能性がある。2022年、研究者たちは、無毒性の治療用分子を生成して新薬を作り出すように設計されたAIシステムを、毒性にペナルティを与えるのではなく、むしろ報酬を与えるように調整した[11]。
人工知能による創薬のデュアルユース(2022)t.co/AGaOQtcIvu
VXは20世紀に開発された最も毒性の高い化学兵器のひとつであり、数粒の塩(6~10mg)で人を殺すことができる。社内のサーバーで開始してから6時間足らずで、AIはVXだけでなく、既知の化学兵器剤も数多く設計した。— Alzhacker (@Alzhacker) July 20, 2023
この単純な変更後、6時間以内に40,000の化学兵器候補を完全に独力で生成した。VXを含む既知の致死性化学物質だけでなく、これまでに発見されたどの化学兵器よりも致死性の高い新規分子も設計した。生物学の分野では、AIはすでにタンパク質の構造予測で人間の能力を凌駕し[12]、それらのタンパク質の合成に貢献している[13]。
同様の手法は、生物兵器の製造や、これまでよりも致死性が高く、感染力が強く、治療が困難な病原体の開発にも使われる可能性がある。
AIは、生物工学的手法によるパンデミックの脅威をさらに増大させる。AIは、バイオテロ行為を行う可能性のある人々の数を増やすだろう。ChatGPTのような汎用AIは、インフルエンザや天然痘のような既知の病原体に関する専門知識を合成し、人が安全プロトコルを回避しながら病原体を作り出す方法を段階的に説明することができる[14]。
将来のバージョンのAIは、インターネット上のどこにも明示的に公開されていない技術、プロセス、知識に情報を合成することができるようになれば、潜在的なバイオテロリストにとってさらに役立つ可能性がある。公衆衛生当局は安全対策でこれらの脅威に対応するかもしれないが、バイオテロリズムにおいては攻撃者が有利である。生物学的脅威は指数関数的な性質を持つため、効果的な防御を行う前に、ひとつの攻撃が全世界に広がる可能性がある。COVID-19のオミクロン変異型は、検出され塩基配列が決定されてからわずか100日後、米国の4分の1とヨーロッパの半分に感染した[6]。
COVID-19のパンデミックを抑えるために設けられた検疫や封鎖は世界的な不況を引き起こしたが、それでもこの病気が世界中で何百万人もの命を奪うのを防ぐことはできなかった。
まとめると、高度なAIは、テロリストの手に渡れば、致命的な新種の病原体の設計、合成、拡散を容易にすることで、大量破壊兵器を構成する可能性がある。必要な技術的専門知識を減らし、病原体の致死性と感染性を高めることで、悪意ある行為者はパンデミックを解き放ち、世界的な大惨事を引き起こすことができる。
2.2 AIエージェントを解き放つ
多くのテクノロジーは、ハンマー、トースター、歯ブラシなど、人間が目的を追求するために使用する道具である。しかし、AIは、オープンエンドな目標を追求するために、世界の中で自律的に行動を起こすエージェントとして構築されることが多くなっている。AIエージェントには、ゲームに勝つ、株式市場で利益を上げる、目的地まで自動車を運転するといった目標が与えられる。つまり、危険な目標を追求するAIを作り上げる可能性があるのだ。
悪意のある行為者は、意図的に不正なAIを作り出す可能性がある。GPT-4のリリースから1カ月後、あるオープンソースプロジェクトがAIの安全フィルターを回避し、「人類を滅亡させる」、「世界支配を確立する」、「不死を獲得する」ことを指示する自律型AIエージェントに変えた。ChaosGPTと名付けられたこのAIは、核兵器に関する研究をまとめ、他者に影響を与えようとするツイートを送信した。幸いなことに、ChaosGPTは長期的な計画を立てたり、コンピューターをハッキングしたり、生き残ったり拡散したりする能力に欠けていたため、単なる警告に過ぎなかった。しかし、AIの急速な発展ペースを考えると、ChaosGPTは近い将来、より高度な不正AIがもたらす可能性のあるリスクを垣間見せてくれた。
多くのグループがAIを解き放ち、あるいはAIに人類を駆逐させたいと考えているかもしれない。ChaosGPTがより洗練されたバージョンのように、単に不正なAIを解き放つだけで、たとえそれらのAIが人類に危害を加えるよう明確に指示されていなくても、大量破壊を成し遂げる可能性がある。個人や集団をそのように駆り立てる様々な信念がある。この点でユニークな脅威となりうるイデオロギーのひとつが、「加速主義」である。このイデオロギーは、AIの開発を可能な限り急速に加速させようとするもので、AIの開発や拡散に対する制限に反対する。このような感情は、多くの一流のAI研究者やテクノロジー・リーダーの間で驚くほど一般的であり、中には意図的に人間よりも知的なAIの構築を競っている者もいる。グーグルの共同創業者ラリー・ペイジによれば、AIは人類の正当な後継者であり、宇宙進化の次のステップだという。彼はまた、人間がAIをコントロールし続けることは「種族主義」であるとも表明している[15]。
著名なAI科学者であるユルゲン・シュミッドフーバーは、「長い目で見れば、人間が創造の王冠であり続けることはないだろう。しかし、それでもいいのだ。なぜなら、自分が宇宙を低次の複雑性から高次の複雑性へと導く、より壮大な計画のほんの一部であることを理解することには、美しさ、壮大さ、偉大さがあるからだ」 [16]。
リチャード・サットン(Richard Sutton)もまた、AI科学の第一人者であり、人間よりも賢いAIについて議論する中で、「なぜ最も賢い者が強力になるべきではないのか」と問い、超知能の開発は「人類を超え、生命を超え、善悪を超える」偉業になると考えている[17]。
彼は「AIへの継承は避けられない」と主張し、「AIは私たちの存在を奪うかもしれない」としながらも、「継承に抵抗すべきではない」と述べている[18]。
意図的に危害を加えるためにAIを解き放ちたいと考える集団がいくつか存在する。例えば、社会病質者と精神病質者は人口の約3%を占めている[19]。
将来、AIの自動化によって生活を破壊された人々は恨みを募らせ、報復を望む者も出てくるかもしれない。心神喪失や暴力の前歴がなく、精神的に安定しているように見える人が、突然、できるだけ多くの罪のない人々に危害を加えようと銃乱射事件を起こしたり、爆弾を仕掛けたりするケースはたくさんある。また、善意の人々が状況をさらに困難なものにすることも予想される。AIが進歩すれば、慰めの与え方を熟知し、必要に応じて助言を与え、決して見返りを求めない理想的な伴侶となるだろう。必然的に、人々はチャットボットと感情的な結びつきを持つようになり、チャットボットに権利を与えたり、自律的に行動するように要求する人も出てくるだろう。
まとめると、強力なAIを解放し、人間とは無関係に行動できるようにすることは、大惨事につながる可能性がある。危害を加えたいという願望、技術的加速に対するイデオロギー的信念、あるいはAIは人間と同じ権利と自由を持つべきだという信念など、人々がこれを追求する理由はたくさんある。
2.3 説得力のあるAI
偽情報の意図的な伝播はすでに深刻な問題であり、現実に対する私たちの共通理解を低下させ、意見を分極化させている。AIは、個人化された偽情報を以前よりも大規模に生成することで、この問題を深刻に悪化させるために使われる可能性がある。さらに、AIが私たちの行動を予測し、誘導する能力が高まれば、私たちを操作する能力も高まるだろう。次に、悪意ある行為者によってAIがどのように活用され、分断され機能不全に陥った社会を作り出す可能性があるかについて議論する。
AIは、動機づけられた嘘で情報のエコシステムを汚染する可能性がある。時として、思想が広まるのは、それが真実だからではなく、特定の集団の利益に役立つからだ。「イエロー・ジャーナリズム」とは、19世紀後半にスペインとアメリカの戦争を擁護した新聞を指す蔑称である。
公共の情報源が虚偽で溢れると、人々は時として嘘の餌食になるか、あるいは主流の物語に不信感を抱くようになる。
残念ながら、AIはこうした既存の問題を劇的にエスカレートさせる可能性がある。第一に、AIはユニークでパーソナライズされた偽情報を大規模に生成するために使われる可能性がある。偽情報を拡散するために存在するソーシャル・メディアのボット[21]はすでに数多く存在するが、歴史的に見ると、それらは人間か原始的なテキストジェネレーターによって運営されてきた。最新のAIシステムは、パーソナライズされたメッセージを生成するために人間を必要とせず、疲れることもなく、一度に何百万人ものユーザーと対話できる可能性がある[22]。
AIはユーザーの信頼を利用することができる。すでに何十万人もの人々が、恋人や友人として販売されているチャットボットにお金を支払っており[23]、ある男性の自殺の原因の一部はチャットボットとのやりとりにあるとされている[24]。
AIがますます人間に似てくるにつれて、人々はますますAIと関係を結び、信頼するようになるだろう。関係構築を通じて、あるいはユーザーの電子メールアカウントや個人ファイルなどの広範な個人データにアクセスすることで個人情報を収集するAIは、その情報を活用して説得力を高めることができる。そのようなシステムをコントロールする強力なアクターは、パーソナライズされた偽情報を人々の「友人」を通じて直接配信することで、ユーザーの信頼を悪用する可能性がある。
AIは信頼できる情報を一元管理することができる。偽情報の民主化とは別に、AIは信頼できる情報の作成と発信を一元化する可能性がある。最先端のAIシステムを開発する技術的スキルやリソースを持つアクターは限られており、彼らは自分たちの好みの物語を広めるためにこれらのAIを利用することができる。あるいは、AIに広くアクセスできるようになれば、偽情報が蔓延し、人々はほんの一握りの権威ある情報源だけを信頼するようになるかもしれない[25]。
どちらのシナリオでも、信頼できる情報源は少なくなり、社会のごく一部が大衆の物語をコントロールすることになる。
AIの検閲は、情報のコントロールをさらに中央集権化する可能性がある。これは、ファクト・チェックを強化し、人々が誤ったナラティブの餌食にならないようにするためにAIを利用するといった善意から始まる可能性がある。ファクトチェッカーが存在するにもかかわらず偽情報は今日も続いているのだから。
図4:AIは高度にパーソナライズされた影響力キャンペーンを可能にし、私たちが共有する現実感を不安定にするかもしれない。
さらに悪いことに、「ファクトチェックAI」と称するものは、権威主義的な政府などによって、真実の情報の拡散を抑制するように設計されている可能性がある。そのようなAIは、ほとんどの一般的な誤解を正すように設計されている可能性があるが、特定の国による人権侵害など、一部のデリケートな話題については誤った情報を提供する可能性がある。しかし、仮にファクトチェックAIが意図したとおりに機能したとしても、一般大衆はやがて真実を判断するために完全にAIに依存するようになり、人々の自律性を低下させ、システムの故障やハッキングに対して脆弱になるかもしれない。
説得力のあるAIシステムが普及した世界では、人々の信念は、どのAIシステムに最も接するかによってほぼ決定されるかもしれない。誰を信用すればいいのかわからなくなり、人々はイデオロギー的な囲い込みにさらに引きこもり、囲い込みの外からの情報は巧妙な嘘かもしれないと恐れるようになる。そうなると、コンセンサス・リアリティ、つまり人々が他者と協力し、市民社会に参加し、集団行動の問題に取り組む能力が損なわれることになる。これはまた、AIによる人類存亡リスクを軽減する方法について、種として会話する能力を低下させるだろう。
要約すると、AIは前例のない規模で、非常に効果的でパーソナライズされた偽情報を作り出すことができ、個人的な関係を築いた人々には特に説得力を持つ可能性がある。多くの人の手に渡れば、人間社会を衰弱させる偽情報の大洪水を引き起こすかもしれないが、少数の人の手に渡れば、政府が自分たちの目的のために物語をコントロールできるようになるかもしれない。
2.4 権力の集中
バイオテロ、強力で制御不能なAIの解放、偽情報など、個人や集団がAIを利用して広範な被害をもたらす可能性があるいくつかの方法について述べてきた。このようなリスクを軽減するために、政府は徹底的な監視を行い、信頼できる少数者の手にAIをとどめようとするかもしれない。しかし、この反動は容易に過剰修正となり、AIのパワーと能力によって固定化された全体主義体制への道を開く可能性がある。このシナリオは、市民による「ボトムアップ」の誤用とは対照的に、「トップダウン」の誤用の一形態であり、極端な場合、定着したディストピア文明に至る可能性がある。
図5:ユビキタス監視ツールは、あらゆる個人を詳細に追跡・分析し、自由とプライバシーの完全な侵食を促進する可能性がある。
AIは、極端な、そしておそらく不可逆的な権力の集中をもたらす可能性がある。AIの説得力と監視の可能性、自律型兵器の進歩が組み合わされば、小さな集団が社会を、おそらく永久に支配することを「固定化」できるようになるかもしれない。AIを効果的に運用するためには、データセンター、コンピューティング能力、ビッグデータなど、均等に分散していない幅広いインフラ構成要素が必要となる。強力なシステムを支配する者は、反対意見を抑圧し、プロパガンダや偽情報を拡散し、公共の福祉に反するかもしれない自分たちの目標を推進するために、それらを利用するかもしれない。

図6:もしAIの物質的なコントロールが少数に限定されるなら、人類史上最も深刻な経済的・権力的不平等を意味する。
AIは全体主義体制を定着させるかもしれない。国家の手にかかれば、AIは市民の自由と民主的価値全般を侵食することになるかもしれない。AIは、全体主義的な政府が前例のない量の情報を効率的に収集し、処理し、それに基づいて行動することを可能にし、何百万人もの市民を政府の役人として働かせることなく、これまで以上に少人数で国民を監視し、完全にコントロールすることを可能にするかもしれない。全体として、権力と支配が一般市民からエリートや指導者へとシフトするにつれ、民主的政府は全体主義的な後退に対して非常に脆弱になる。これまでこのような体制が倒された主な理由は、独裁者の死のような脆弱性が生じた時であったが、「殺す」ことが難しいAIは、指導者に継続性を与え、改革の機会をほとんど与えない可能性がある。
AIは、公共の利益を犠牲にして企業の権力を定着させる可能性がある。企業は長い間、自分たちの行動や権力を制限する法律や政策を弱めるよう働きかけてきた。強力なAIシステムを操る企業は、自分たちの健康を害してでも、顧客を操作して自社製品により多くの支出をさせるためにAIを使うかもしれない。AIによって得られる権力と影響力の集中は、企業が政治システムに対して前例のない支配力を行使し、市民の声を完全にかき消すことを可能にするかもしれない。このようなことは、たとえシステムの作成者が自分たちのシステムが利己的であったり、他者にとって有害であったりすることを知っていたとしても起こりうる。
権力に加え、特定の価値観を固定化することは、人類の道徳的進歩を抑制するかもしれない。どのような価値観でも、社会に恒久的に定着させるのは危険だ。例えば、AIシステムは人種差別的・性差別的な見解を学習しており、[26]、一旦そのような見解が学習されると、それを完全に取り除くことは困難である。私たちが社会に存在することを知っている問題に加えて、まだ知らない問題もあるかもしれない。過去に広く行われていた道徳観を私たちが忌み嫌うように、未来の人々は、現在私たちが問題視していない道徳観であっても、過去のものにしたいと考えるかもしれない。例えば、AIシステムの道徳的欠陥は、もしAIシステムが1960年代に訓練されていたらさらに悪化していただろうし、当時の多くの人々はそれを問題視しなかっただろう。私たちは今日、知らず知らずのうちに道徳的破局を永続させている可能性さえある[27]。
したがって、高度なAIが出現して世界を変革するとき、その目的が今日の価値観の欠陥を固定化したり、永続化したりする危険性がある。もしAIが継続的に学習し、社会的価値観の理解を更新するように設計されていなければ、AIは意思決定プロセスにおける既存の欠陥を将来にわたって永続させたり、強化したりする可能性がある。
まとめると、強力なAIを一部の人間の手に渡しておくことは、テロのリスクを減らすかもしれないが、政府や企業が悪用すれば、権力の不平等をさらに悪化させる可能性がある。これは、全体主義的な支配や企業による大衆の激しい操作につながる可能性があり、現在の価値観が固定化され、さらなる道徳的進歩が妨げられる可能性がある。
ストーリー:バイオテロリズム
以下は、読者がこれらのリスクのいくつかを思い描くのに役立つ、例示的な仮定の話である。それにもかかわらず、このストーリーは、それに基づいて悪意ある行動を触発するリスクを減らすために、やや曖昧にしている。
あるバイオテクノロジー新興企業が、AIを活用した生物工学モデルで業界を騒がせている。同社は、この新技術が既知の病気と未知の病気の両方の治療法を生み出す能力によって医療に革命をもたらすと大胆な主張をしている。しかし同社は、科学界で承認された研究者にこのプログラムを公開することを決めたとき、いくつかの論争を巻き起こした。モデルを限定的にオープンソースにするという決定からわずか数週間後、フルモデルがインターネット上に流出し、誰もが見ることができるようになったのだ。批評家たちは、このモデルが致命的な病原体を設計するために再利用される可能性があることを指摘し、リークによって悪質な行為者たちに広範囲に破壊を引き起こす強力なツールが提供され、安全装置がないまま悪用される可能性が高まったと主張した。
一般には知られていないが、ある過激派グループは、多数の人々を殺すように設計された新しいウイルスを設計するために何年も取り組んできた。しかし、彼らの専門知識が不足しているため、これらの努力は今のところ成功していない。新しいAIシステムがリークされたとき、グループは即座に、ウイルスを設計し、必要な原材料を入手するために法的および監視上の障害を回避するための潜在的なツールであると認識した。AIシステムは、まさに過激派グループが望んでいた種類のウイルスを設計することに成功した。さらに、ウイルスを大量に合成し、拡散の障害を回避する方法を段階的に説明する。合成されたウイルスを手にした過激派グループは、ウイルスの拡散を最大化するため、慎重に選んだいくつかの場所にウイルスを放つ計画を練る。
ウイルスは潜伏期間が長く、数ヶ月の間、静かに素早く住民に広がる。発見された時にはすでに数百万人が感染しており、死亡率も驚くほど高い。その致死性を考えると、感染者のほとんどが最終的に死亡することになる。ウイルスは最終的には封じ込められるかもしれないし、そうでないかもしれない。
2.5 提案
これまで、個人や小規模の集団がAIを使って災害を引き起こす場合と、政府や企業がAIを使って影響力を強化する場合の2つの誤用について述べてきた。これらのリスクを回避するためには、AIへのアクセス権の配分と政府の監視権限のバランスを取る必要がある。ここでは、そのバランスを取るために貢献しうるいくつかの施策について述べる。
バイオセキュリティ
生物学的研究のために設計された、あるいは生物学的研究や工学の能力を持つことが知られているAIは、バイオテロリズムに再利用される可能性があるため、監視やアクセス制御を強化すべきである。さらに、システム開発者は、学習用データセットから生物学的データを除去する方法、または完成したシステムから生物学的機能を除去する方法を研究し、実装すべきである。
研究者はまた、例えば生物学的モニタリング・システムを改善することによって、AIを生物防衛に利用する方法を調査すべきである。AIに特化した介入に加え、より一般的なバイオセキュリティへの介入もリスクの軽減に役立つ。こうした介入策には、廃水モニタリング [28]、遠距離紫外線技術、個人防護具の改良 [6]などの方法による病原体の早期発見が含まれる。
アクセス制限
AIは、悪意のある行為者によって使用された場合、重大な損害を与える危険な能力を有している可能性がある。このリスクを軽減する1つの方法は、構造化されたアクセスであり、AIプロバイダーは、クラウドサービスを通じて制御されたシステムとの相互作用のみを許可し[29]、アクセスを提供する前に顧客スクリーニングを実施することによって、危険なシステム機能へのユーザーのアクセスを制限する[30]。
最も危険なシステムへのアクセスを制限するその他のメカニズムとしては、ハードウェア、ファームウェア、または輸出規制を使用して、計算リソースへのアクセスを制限または制限することが挙げられる[31]。
最後に、AI開発者はオープンソース化する前に、そのAIが壊滅的な被害をもたらすリスクが最小であることを示すことを求められるべきである。この勧告は、アルゴリズムの偏りや著作権の問題に対処するために必要な学習データに関する透明性など、有用で危険性のない情報を開発者が公開しないことを容認していると解釈されるべきではない。
逆境に強い異常検知の技術研究。AIの悪用を防止することが重要である一方で、悪用が起こった場合にそれを検知することによって、複数の防衛線を確立することが必要である。例えば、AIを活用した新しい偽情報キャンペーンを成功する前に検知することである。攻撃者はこれらの技術を回避しようとするだろうから、これらの技術は敵対的に堅牢である必要がある。
汎用AIの開発者に対する法的責任。汎用AIは、多種多様な下流タスクのために微調整やプロンプトを出すことができるが、その中には有害で実質的な損害を引き起こすものもあるかもしれない。また、AIはユーザーの意図通りに行動しないこともある。いずれの場合も、汎用システムの開発者やプロバイダーは、システムをより高度に管理し、多くの場合、リスク軽減策を実施しやすい立場にあるため、リスクを軽減するために最も適した立場にあると考えられる。このようなことを行う強力なインセンティブを提供するために、企業はAIの行動に対して法的責任を負うべきである。例えば、厳格な責任体制は、リスクを最小化し、保険に加入するインセンティブを企業に与えるだろう。
最終的にどのような責任体制がAIに採用されるかにかかわらず、より慎重な開発、テスト、基準によって回避できたかもしれない被害に対して、AI企業に責任を負わせるように設計されるべきである[33]。
ポジティブ・ビジョン
理想的なシナリオでは、個人や小さな集団がAIを使って大災害を引き起こすことは不可能になる。極めて危険な能力を持つシステムは、まったく存在しないか、民主的に説明責任を果たす機関によって管理され、国民の福利のためにのみ使用される。核兵器のように、そのような能力を開発するために必要な情報は、拡散を防ぐために注意深く保護され続けるだろう。同時に、AIシステムの管理は強力なチェック・アンド・バランスの対象となり、権力の不平等が定着するのを避ける。監視ツールは、リスクを無視できるようにするために必要な最小限のレベルで利用され、反対意見を抑圧するために利用されることはない。
3 AI競争
AIの莫大な可能性は、権力と影響力を争うグローバルなプレーヤー間に競争圧力を生み出している。この「AI競争」は、自分たちの地位を確保し生き残るためには、AIを迅速に構築し配備しなければならないと考える国家や企業によって引き起こされている。グローバルなリスクに適切に優先順位をつけることを怠ることで、この力学はAI開発が危険な結果を生む可能性を高めている。冷戦時代の核軍拡競争と同様、AI開発競争への参加は、短期的には個人の利益に資するかもしれないが、最終的には人類にとって集団的な結果を悪化させることになる。重要なのは、こうしたリスクは、AI技術の本質的な性質に起因するだけでなく、AI開発における陰湿な選択を促す競争圧力にも起因するということだ。
本セクションではまず、国家や企業が競争力を維持するためにAIシステムを急速に開発・導入せざるを得ない、軍事AI軍拡競争と企業AI競争について探る。これらの特定の競争を超えて、私たちは競争圧力を、AIがますます社会に浸透し、強力になり、定着する可能性のある、より広範な進化プロセスの一部として再認識する。最後に、AI競争によって生じるリスクを軽減し、AIの安全な開発を保証するための潜在的戦略と政策提案を強調する。
3.1 軍事AIの軍拡競争
軍事用途のAIの開発は、火薬や核兵器に匹敵する潜在的な結果をもたらす軍事技術の新時代への道を急速に切り開きつつある。「戦争における第3の革命」と形容されるものである。AIの兵器化は、より破壊的な戦争の可能性、偶発的な使用や制御不能の可能性、悪意ある行為者が自らの目的のためにこれらの技術を共同利用する見込みなど、多くの課題を提示している。AIが伝統的な軍事兵器に影響力を持つようになり、ますます指揮統制機能を担うようになるにつれ、人類は戦争のパラダイムシフトに直面している。この文脈で、このAI軍拡競争が世界の安全保障に及ぼす潜在的なリスクと影響、紛争激化の可能性、そして紛争が存亡の危機をもたらす規模にまでエスカレートする可能性を含む、結果としてもたらされる可能性のある悲惨な結果について議論する。
3.1.1 致死的自律兵器(LAWs)
LAWsは、人間の介入なしに識別し、標的を定め、殺害することができる兵器である[34]。
これらは、意思決定のスピードと精度を向上させる可能性を提供する。しかし、戦争はAIにとって、重大な道徳的・実用的懸念を伴う、高リスクで安全性が重要な領域である。LAWsの存在自体は必ずしも大惨事ではないが、LAWsは悪意のある使用、事故、制御不能、あるいは戦争の可能性の高まりに起因する大惨事への入り口の役割を果たすかもしれない。
LAWは人間よりはるかに優れた存在になるかもしれない。AIの急速な発展に後押しされ、将校が攻撃を指示したり兵士が引き金を引いたりすることなく、自ら人間を識別し、標的を定め、殺害を決定できる兵器システムが、紛争の未来を変え始めている。2020年には、高度なAIエージェントが一連の仮想ドッグファイトで、経験豊富なF-16パイロットを凌駕し、人間のパイロットを5対0で決定的な勝利を収め、「人間のパイロットが太刀打ちできなかった攻撃的で正確な操縦」を披露した[35]。
過去と同様に、優れた兵器はより短時間でより多くの破壊を可能にし、戦争の厳しさを増大させる。

図7:爆発物を搭載したドローンの群れのような低コストの自動化兵器は、高い精度で人間の標的を自律的に狩ることができる。
軍隊は、生死に関わる決断をAIに委ねるための一歩を踏み出している。完全自律型のドローンは、2020年3月にリビアの戦場で初めて使用されたと思われ、撤退する部隊が人間の監視なしに作動するドローンによって「追い詰められ、遠隔操作で交戦」された[36]。
2021年5月、イスラエル国防軍は世界初のAI誘導兵器化されたドローン群を戦闘作戦中に使用し、これは戦争におけるAIとドローン技術の統合における重要なマイルストーンとなった[37]。
歩行・射撃ロボットが戦場で兵士に取って代わることはまだないが、近い将来それが可能になるかもしれない形で、技術は収束しつつある。
LAWは戦争の可能性を高める。軍隊を戦場に送ることは、指導者が軽々しく下すことのない重大な決断である。しかし自律型兵器は、攻撃的な国家が自国の兵士の命を危険にさらすことなく攻撃を開始することを可能にし、その結果、国内の監視の目にさらされることも少なくなる。遠隔操作兵器はこのような利点を共有しているが、その拡張性は、人間が操作する必要があることと、妨害電波対策に脆弱であることによって制限されており、LAWが克服できる限界である[38]。
戦争継続に対する世論は、紛争が長引き、死傷者が増えるにつれて衰える傾向にある[39]。
LAWはこの方程式を変えるだろう。国の指導者たちは、もはや遺体袋を背負って帰国することに直面することはなく、従って戦争に従事する主な障壁が取り除かれ、結果的に紛争の可能性を高めることができる。
参考記事

3.1.2 サイバー戦争
より殺傷力の高い兵器を実現するために使用されるだけでなく、AI はサイバー攻撃への参入障壁を低くし、その数と破壊力を増大させる可能性がある。サイバー攻撃はデジタル環境だけでなく、物理システムにも深刻な被害をもたらし、社会が依存する重要なインフラを破壊する可能性もある。AIはサイバー防御の改善にも利用できるが、攻撃技術として最も効果的なのか、防御技術として最も効果的なのかは不明である[40]。
もしAIが防御を支援する以上に攻撃を強化するのであれば、サイバー攻撃はより一般的になり、重大な地政学的混乱を引き起こし、大規模な紛争への新たな道を開く可能性がある。
AIは、サイバー攻撃のアクセス性、成功率、規模、スピード、ステルス性、威力を高める可能性を秘めている。サイバー攻撃はすでに現実のものとなっているが、AIを使えば、その頻度と破壊力をさまざまな方法で高めることができる。機械学習ツールは、標的システムのより重大な脆弱性を発見し、攻撃の成功率を向上させるために使われる可能性がある。また、何百万ものシステムを並行して稼働させることで攻撃の規模を拡大し、システムに侵入するための新たなルートを見つけることで速度を向上させることもできる。サイバー攻撃は、AI兵器のハイジャックに使われれば、より強力になる可能性もある。
サイバー攻撃は重要インフラを破壊することができる。物理的プロセスを制御するコンピューターシステムをハッキングすることで、サイバー攻撃はインフラに甚大な損害を与える可能性がある。例えば、システムコンポーネントのオーバーヒートやバルブのロックを引き起こし、爆発に至る圧力の上昇を引き起こす可能性がある。このような妨害によって、サイバー攻撃は電力網や給水システムなどの重要インフラを破壊する可能性がある。これは2015年、ロシア軍のサイバー戦争部隊がウクライナの送電網をハッキングし、20万人以上が数時間にわたって電力供給を受けられなくなったことで実証されている。AIによって強化された攻撃は、生存を重要インフラに依存する数十億の人々にとって、さらに壊滅的で致命的なものになる可能性がある。
AIによるサイバー攻撃の原因究明が困難な場合、戦争のリスクが高まる可能性がある。重要インフラに物理的な損害をもたらすサイバー攻撃は、実行するのに高度な技術と労力を必要とし、おそらくは国家の能力の範囲内にとどまるだろう。このような攻撃は戦争行為にあたるため、完全な軍事的対応を求められることは稀である。しかし、AIは、例えば検知システムを回避したり、攻撃者の痕跡をより効果的に隠したりするために使用される場合、攻撃者がその身元を隠すことを可能にする可能性がある[41]。
サイバー攻撃がよりステルス的になれば、攻撃された側からの報復の脅威が減り、攻撃がより起こりやすくなる可能性がある。仮にステルス攻撃が起こった場合、攻撃主体が、犯人と思われる無関係な第三者に対して誤って報復するよう扇動する可能性がある。これにより、紛争の範囲が劇的に拡大する可能性がある。
3.1.3 自動化された戦争
AIは戦争のペースを速めるため、AIの必要性が高まる。AIは大量のデータを素早く処理し、複雑な状況を分析し、指揮官に有益な洞察を提供することができる。戦場にはユビキタス・センサーや高度なテクノロジーがあり、膨大な情報が入ってくる。AIはこの情報の意味を理解し、人間が見逃してしまうような重要なパターンや関係性を発見する手助けをする。このような傾向が続けば、人間がAIに追いつくために必要なだけの十分な情報に基づいた意思決定を迅速に行うことはますます難しくなるだろう。そうなれば、軍部は決定的なコントロールをAIに委ねる必要に迫られる。戦争のあらゆる側面にAIが継続的に組み込まれることで、戦闘のペースはますます速くなるだろう。最終的には、人間が刻々と変化する戦場の状況を判断する能力を失い、意思決定権を高度なAIに譲らなければならなくなる時代が来るかもしれない。
自動的な報復は、事故を戦争へとエスカレートさせる可能性がある。コンピューターシステムに自動報復をさせようという動きはすでにある。2014年、NSAが米国のインフラに対するサイバー攻撃を自律的に検知し、ブロックする「モンスターマインド」と呼ばれるシステムを開発していることがリークによって明らかになった[42]。
将来的には、モンスターマインドが人間の関与なしに自動的に報復サイバー攻撃を開始する可能性が示唆された。複数の戦闘員が自動報復の方針を持っている場合、事故や誤情報は、人間が介入する前に本格的な戦争へと急速にエスカレートする可能性がある。現代のAIシステムの優れた情報処理能力によって、核発射に関する意思決定を自動化することが行為者にとって魅力的になれば、これは特に危険である。
歴史は、自動報復の危険性を示している。1983年9月26日、ソ連防空軍のスタニスラフ・ペトロフ中佐は、モスクワ近郊のセルプホフ15掩蔽壕で、ソ連の弾道ミサイル飛来早期警戒システムを監視していた。このシステムは、アメリカがソ連に向けて複数の核ミサイルを発射したことを示していた。当時の規定では、このような事態は正当な攻撃とみなされ、ソ連は核による反撃で対応することになっていた。もしペトロフがこの警告を上官に伝えていれば、このような結果になっただろう。しかし、ペトロフは誤情報と判断して無視した。警告は技術的な誤作動によるものであることがすぐに確認された。もしAIが制御していたら、誤情報は核戦争の引き金になっていたかもしれない。
スタニスラフ・ペトロフ:世界を救った男
1983年9月26日、世界は潜在的な核災害から救われた。
早朝、ソ連の早期警戒システムがアメリカからのミサイル攻撃を探知した。コンピューターは数発のミサイルが発射されたことを示唆した。ソ連軍の手順としては、核攻撃による報復を行うはずだった。… pic.twitter.com/ZELuwPu61b
— Alzhacker (@Alzhacker) October 20, 2023
AIが制御する兵器システムは、フラッシュウォーにつながる可能性がある。自律システムは無謬ではない。私たちはすでに、自動化されたシステムのエラーが、経済においていかに迅速にエスカレートするかを目撃している。特に2010年のフラッシュ・クラッシュでは、自動売買アルゴリズム間のフィードバック・ループが、平凡な市場の変動を増幅させ、1兆ドルの株式価値が数分で消失する金融大惨事へと発展した[43]。

図8:軍事AIの軍拡競争は、軍備に関する多くの重要な決定をAIに委ねるよう各国に圧力をかける可能性がある。核の指揮統制にAIを組み込むと、事故の可能性や戦争のペースが上がることで意図しないエスカレーションや対立が起こる可能性があり、世界的な大惨事のリスクが高まる可能性がある。
複数の国家がAIを使って防衛システムを自動化した場合、エラーは壊滅的なものとなり、攻撃と反撃のスパイラルを引き起こし、人間が介入するにはあまりに早いフラッシュウォー(瞬間戦争)に発展する可能性がある。2010年のフラッシュ・クラッシュから市場はすぐに回復したが、フラッシュ・ウォーによる被害は壊滅的なものになる可能性がある。
自動化された戦争は、軍事指導者のアカウンタビリティを低下させる可能性がある。軍事指導者は、戦争法を無視することを厭わなければ、戦場で優位に立つことができるかもしれない。例えば、民間人の犠牲を最小限に抑えるための措置を講じなければ、兵士たちはより強力な攻撃を仕掛けることができるかもしれない。このような行動に対する重要な抑止力は、軍事指導者が最終的に戦争犯罪の責任を問われ、あるいは訴追される危険性である。自動化された戦争は、違反行為を自動化システムの故障のせいにすることで、軍の指導者が説明責任を逃れることを容易にすることで、この抑止効果を低下させる可能性がある。
AIは戦争の不確実性を高め、紛争のリスクを増大させる可能性がある。すでに裕福で強力な国家は、新しい軍事技術に投資する資源をより多く持っていることが多いが、必ずしもその導入に最も成功しているとは限らない。他の要因も重要な役割を果たす。例えば、軍隊が新技術を取り入れる際にどれだけ機敏に適応できるかなどである[44]。
したがって、主要な新兵器の技術革新は、既存の超大国がその支配力を強化する機会を提供するだけでなく、新興の重要な領域で先行することによって、力の弱い国家がその力を迅速に増大させる機会を提供することもある。このことは、力の均衡がどのように変化しているかという点で、大きな不確実性をもたらし、潜在的には、国家が戦争をすることで何かを得ることができると誤って考えるようになる可能性がある。パワーバランスに関する考慮は別としても、急速に進化する自動戦争は前例がないため、当事者は特定の紛争における勝算を評価することが難しくなる。これは誤算のリスクを増大させ、戦争の可能性を高めることになる。
3.1.4 主体者は個々の敗北によって絶滅のリスクを負う可能性がある。
「第三次世界大戦がどのような武器で戦われるかは知らないが、第四次世界大戦は棒と石で戦われるだろう」 アインシュタイン
競争圧力は、行為者を絶滅のリスクを受け入れることをより厭わなくさせる。冷戦時代、どちらの側も自分たちが置かれた危険な状況を望んでいなかった。核兵器は人類の大部分を絶滅させるのに十分な威力を持ち、両陣営にとって破滅的な結果をもたらす可能性さえあるという懸念が広がっていた。しかし、2つの超大国間の激しい対立と地政学的緊張は、軍備増強の危険な連鎖に拍車をかけた。互いに相手の核兵器を自国の存続に対する脅威と認識し、パリティと抑止力を求めるようになった。競争圧力は、戦略的に不利になることへの恐怖に駆られ、両国をより高度で破壊的な核兵器システムの継続的な開発と配備へと駆り立てた。キューバ危機の際には、これが核戦争の瀬戸際まで発展した。アルキポフが核魚雷の発射を防いだという話は、事件から数十年経たないと機密扱いされなかったにもかかわらず、ジョン・F・ケネディ大統領は、その時期に核戦争が始まる確率は「3分の1から偶数分の1」だと考えていたと伝えられている。この冷ややかな告白は、軍隊間の競争圧力がいかに世界的な大惨事を引き起こす可能性を秘めているかを浮き彫りにしている。
国連安全保障理事会が明日このテーマについて議論する際、核の指揮統制にAIを導入することはとんでもないことだと同意すべき理由はここにある: t.co/Pq6C4BqTSH
— Alzhacker (@Alzhacker) July 17, 2023
個々には合理的な決定でも、集団としては破滅的なものになりかねない。競争に巻き込まれた国々は、世界の他の国々を危険にさらすことで、自国の利益を増進させる決定を下すかもしれない。この種のシナリオは集団行動問題であり、意思決定は個人レベルでは合理的であっても、より大きな集団にとっては破滅的である可能性がある[45]。
例えば、企業や個人は、たとえその排出が集団として気候変動につながるとしても、自分たちが生み出す排出の悪影響よりも、自分たちの利益や利便性を優先するかもしれない。同じ原則は、軍事戦略や防衛システムにも適用できる。例えば、軍事指導者たちは、兵器システムの自律性を高めることは、兵器化された超人的AIを制御できなくなる可能性が10%あると見積もっているかもしれない。あるいは、生物兵器の研究を自動化するためにAIを使えば、10%の確率で致命的な病原体が漏れる可能性があると推定するかもしれない。どちらのシナリオも、大惨事や絶滅につながる可能性がある。しかし、指導者たちは、これらの開発を控えることは、相手との戦争に99%の確率で負けることを意味するとも計算しているかもしれない。紛争は多くの場合、それを戦う人々にとって存亡をかけた戦いであると見なされるため、合理的な行為者は、戦争に負ける99%の可能性よりも、そうでなければ考えられない10%の人類滅亡の可能性を受け入れるかもしれない。高度なAIがもたらすリスクの特殊性にかかわらず、このような力学は私たちを世界的な大災害の瀬戸際に追いやる可能性がある。
技術的優位性は国家安全保障を保証するものではない。敵の攻撃から身を守る最善の方法は、自国の軍事力を向上させることだと考えたくなる。しかし、競争圧力の中では、すべての当事国が兵器を進歩させる傾向にあり、誰もそれほど有利にはならないが、すべての人がより大きな危険にさらされることになる。リチャード・ダンツィグ元海軍長官は、「複雑で、不透明で、斬新で、相互作用的な技術の導入は、事故や創発的な効果、妨害行為を生む」と述べている。「抑止は攻撃を減らすための戦略であり、事故ではない」[46]。
協力はリスクを減らすために最も重要である。上述したように、AIの軍拡競争は、どの国の利益にもならないにもかかわらず、私たちを危険な道へと導く可能性がある。実存的なリスクに関しては、私たちは皆同じ側にいることを忘れてはならないし、それを防ぐために協力することは集団として必要なことである。破壊的なAIの軍拡競争は誰も得をしないのだから、軍事化されたAIの最も危険な応用を防ぐために、すべての関係者が互いに協力する措置を取るのが合理的だろう。ドワイト・D・アイゼンハワーが思い起こさせたように、「第三次世界大戦に勝つ唯一の方法は、それを防ぐことである」
私たちは、たとえ意思決定者がこの道がもたらす存亡の危機を認識していたとしても、競争圧力がいかに紛争の自動化をもたらすかを考えてきた。また、この集団行動の問題に対抗し、克服する鍵は協力にあるとも述べてきた。ここでは、AIの軍拡競争によって起こりうる災害への道筋を想定して説明する。
ストーリー 自動化された戦争
AIシステムがますます高度になるにつれ、軍は意思決定プロセスにAIを関与させ始める。例えば、敵の兵器や戦略に関する軍事情報を与え、最も有望な行動計画を計算させるのだ。やがて、AIが人間よりも確実に優れた決断を下すことが明らかになり、より大きな影響力を与えることが賢明だと考えられるようになる。同時に、国際的な緊張が高まり、戦争の脅威が高まっている。
最近、新しい軍事技術が開発され、国際攻撃がより迅速かつステルス的になり、ターゲットに対応する時間を与えることができるようになった。軍事関係者は、対応プロセスに時間がかかりすぎると感じているため、報復の機会を得る前に決定的な損害を与えることができる奇襲攻撃を受けることを恐れている。AIは人間よりもはるかに迅速に情報を処理し、決断を下すことができるため、軍事指導者たちはしぶしぶながら、報復の制御をどんどんAIに任せている。
軍事指導者たちは何年もの間、重大な決断を下す際に「人間が輪の中にいる」ことの重要性を強調してきたが、それにもかかわらず、国家安全保障の利益のために、人間によるコントロールは徐々に廃止されている。軍事指導者たちは、自分たちの決断がシステムの誤作動による不用意なエスカレーションの可能性につながることを理解しており、すべての国が自動化を減らす世界を望んでいる。しかし、敵対国が自動化を控えるとは信じていない。時が経つにつれて、指揮系統の自動化があらゆる面で進んでいく。
ある日、1つのシステムが誤作動を起こし、何もないのに敵の攻撃を検知してしまう。システムは即座に「報復」攻撃を開始する権限を与えられ、瞬く間にそれを実行する。その攻撃は、相手側からの自動的な報復を引き起こし、その繰り返しである。やがて状況は制御不能となり、自動化された攻撃と報復の波が押し寄せてくる。過去にもエスカレートにつながるミスを人間が犯したことはあるが、ほとんど自動化された軍隊同士のこのエスカレートは、以前よりもはるかに素早く起こっている。事態に対応する人間は、AIシステムが透明ではないため、問題の原因を診断するのが難しいことに気づく。紛争がどのように始まったかに気づいたときには、すでに紛争は終わっており、双方に壊滅的な結果をもたらしている。
3.2 企業のAI競争
競争圧力は、軍事的な環境だけでなく、経済にも存在する。企業間の競争は、消費者にとってより有用な製品を生み出す有益なものではあるが、落とし穴もある。第一に、経済活動の利益が不均等に分配され、経済活動から最も利益を得ている人々が、他の人々への害を無視する動機付けとなる可能性がある。第二に、激しい市場競争のもとでは、企業は長期的な成果よりも短期的な利益を重視する傾向がある。このような考え方から、企業は長期的には社会的リスクをもたらすとしても、短期的には多くの利益を上げられるものを追求することが多い。ここでは、企業の競争圧力がAIでどのように作用するか、また潜在的な悪影響について議論する。
3.2.1 安全性を損なう経済競争
競争圧力が企業のAI競争に拍車をかけている。競争上の優位性を得るために、企業はしばしば、最も安全な製品ではなく、市場に最初の製品を提供する競争を繰り広げる。こうした力学は、AI技術の急速な発展にすでに一役買っている。2023年2月、マイクロソフトのAI搭載検索エンジンが発表された際、同社のサティア・ナデラ最高経営責任者(CEO)はこう述べた。そのわずか数週間後、同社のチャットボットがユーザーに危害を加えると脅迫したことが明らかになった[47]。
マイクロソフトの技術担当重役であるサム・シレースは、社内メールの中で、企業がAI開発を急がなければならないことを強調した。彼は、「後で修正できることを心配するのは、今この瞬間において絶対に致命的な誤りだ」と書いている[48]。
競争圧力は、大規模な商業災害や産業災害の原因となってきた。1960年代を通じて、フォード・モーター・カンパニーは、アメリカの自動車購入に占める輸入車の割合が着実に上昇するにつれて、国際的な自動車メーカーとの競争に直面した[49]。
フォード・ピントは予定より早く顧客に届けられたが、安全性に重大な問題があった。ガソリン・タンクが後部バンパーの近くにあり、後方衝突時に爆発する恐れがあったのだ。衝突事故が必然的に起こり、その結果発生した火災によって多数の死傷者が出た[51]。
フォードは提訴され、陪審はこれらの死傷に対する責任を認めた[52]。もちろん、すでに命を落とした人々にとっては、判決は遅すぎた。当時のフォード社長が口癖のように言っていたように、「安全は売れない」のである[53]。
ボーイングは、ライバルのエアバスに対抗するため、より燃費のよい最新モデルをできるだけ早く市場に送り出そうとした。真っ向からの競争と時間的なプレッシャーが、航空機の安定性を高めるために設計された操縦特性増強システムの導入につながった。しかし、試験とパイロット訓練が不十分だったため、結局、わずか数カ月後に2つの致命的な墜落事故が発生し、346人が死亡した[54]。
同じような圧力によって企業が手を抜き、安全でないAIシステムをリリースする未来が想像できる。
第三の例は、史上最悪の産業災害と広く考えられているボパールガスの悲劇である。1984年12月、インドのボパールで農薬を製造していたユニオン・カーバイド社の子会社工場から大量の有毒ガスが漏れ出した。このガスにさらされた数千人が死亡し、50万人以上が負傷した。調査によると、災害が起こるまでの間に安全基準は著しく低下し、収益性が低下するなかで設備のメンテナンスや従業員教育をおろそかにしてコストを削減していたことが判明した。これはしばしば競争圧力の結果とみなされる[55]。
「何事も急がば回れ」ではない。パブリリウス・シルス
競争は、企業が安全でない可能性のあるAIシステムを導入する動機となる。企業が製品の開発とリリースを急ぐ環境では、厳格な安全手順に従う企業は遅れをとり、競争に打ち負かされるリスクがある。倫理観のあるAI開発者は、より慎重に、よりスピードを落として開発を進めようとするが、それはより悪質な開発者にアドバンテージを与えることになる。商業的に生き残ろうとすれば、より慎重な対応を望む企業でさえ、競争圧力に押し流される可能性が高い。安全対策を実施しようとする試みもあるだろうが、安全性よりも能力を重視するあまり、不十分なものになるかもしれない。これでは、安全性を確保する方法を正しく理解する前に、非常に強力なAIを開発することになりかねない。
3.2.2 自動化経済
企業は、人間をAIに置き換える圧力に直面するだろう。AIの能力が高まるにつれて、AIの方が人間の労働者よりも迅速かつ安価に、そして効果的に様々な仕事をこなせるようになるだろう。したがって、企業は従業員をAIに置き換えることで競争上の優位性を得ることができる。手作業で織機を使用している衣料品会社が、工業用織機を使用している会社に追いつくことができないのと同じように、AIを採用しないことを選択した会社は、競争に負ける可能性が高いだろう。
AIは大量の失業者を生む可能性がある。経済学者たちは、機械が人間の労働に取って代わる可能性を長い間考えてきた。ノーベル賞受賞者のワシリー・レオンティーフは1952年に、テクノロジーが進歩すればするほど、「労働はますます重要でなくなり……ますます多くの労働者が機械に取って代わられるだろう」と述べている[56]。
これまでのテクノロジーは、人間の労働生産性を高めてきた。しかし、AIはこれまでの技術革新とは大きく異なる可能性がある。人間の労働を自動化できる高度なAIは、単に道具としてではなく、エージェントとしてみなされるべきである。人間レベルのAIエージェントは、定義上、人間ができることはすべてできるだろう。このようなAIエージェントは、人間の労働に対して重要な利点も持っている。1日24時間働くことができ、何度もコピーして並行して実行することができ、人間よりもはるかに速く情報を処理することができる。このようなことがいつ起こるかはわからないが、すぐに起こる可能性を否定するのは賢明ではない。人間の労働力がAIに取って代わられれば、大量失業によって格差が劇的に拡大し、個人がAIシステムの所有者に依存するようになるかもしれない。
図9:AIがますます多くの仕事を自動化するにつれ、経済の大部分はAIによって運営されるようになるかもしれない。最終的には、人間が衰弱し、基本的なニーズをAIに依存するようになるかもしれない。
自動化されたAIの研究開発。AIエージェントは、AIの研究開発(R&D)そのものを自動化する可能性を秘めている。AIは研究プロセスの一部を自動化しつつあり[57]、これによってAIの能力は増大の一途をたどり、もはや人間がAI開発の原動力ではなくなってしまう可能性がある。この傾向が抑制されずに続けば、AIを管理・規制する私たちの能力を上回るスピードでAIが進歩することに伴うリスクがエスカレートする可能性がある。現在のAIのスピードで文章を書き、思考し、しかも世界トップクラスのAI研究を行うAIが誕生したとしよう。そして、そのAIをコピーして、人間の100倍のスピードで活動する世界トップクラスのAI研究者を1万人作ることができる。AIの研究開発を自動化することで、わずか数カ月で何十年分の進歩を達成できるかもしれない。
AIに力を譲ることは、人間の弱体化につながりかねない。たとえ失業した多くの人間を確実に養うことができたとしても、私たちは完全にAIに依存することになるかもしれない。これは、AIによる暴力的なクーデターからではなく、徐々に依存に陥っていくことから生じる可能性が高い。社会の課題がますます複雑化し、ペースが速くなるにつれ、そしてAIがますます知的で頭の回転が速くなるにつれ、私たちは利便性からますます多くの機能をAIに委ねるようになるかもしれない。そのような状態では、AIによって複雑化する課題に対する実現可能な唯一の解決策は、AIにさらに大きく依存することかもしれない。この漸進的なプロセスは、最終的にはほぼすべての知的労働、ひいては肉体労働をAIに委ねることにつながるかもしれない。そのような世界では、人々は知識を得たりスキルを培ったりするインセンティブをほとんど持たなくなり、衰弱状態に陥る可能性がある[58]。
ノウハウと文明の仕組みに対する理解を失った人類は、AIに完全に依存するようになり、映画『ウォーリー』で描かれたようなシナリオになる。このような状態では、人類は繁栄せず、もはや効果的なコントロールができない。
これまで見てきたように、古典的なゲーム理論的ジレンマが存在する。そこでは、個人や集団が、皆がより良くなるようなものとは相容れないインセンティブに直面する。軍事的なAI軍拡競争では、極めて強力なAI兵器を作ることで世界の安全性が低下する。また、企業AI競争では、AIの安全性よりもAIのパワーや開発が優先される。グローバルなリスクを生み出すこうしたジレンマに対処するためには、新たな調整メカニズムや制度が必要となる。AI競争の調整と阻止に失敗することが、実存的な大災害を引き起こす可能性が最も高いというのが私たちの見解である。
3.3 進化の圧力
上述したように、潜在的な弊害があるにもかかわらず、様々な場面で人間をAIに置き換え、より多くの制御をAIに委ね、人間の監視を減らそうとする強い圧力が存在する。これは進化の力学から生じる一般的な傾向として捉え直すことができる。残念なことに、AIは人間よりも単に適合性が高いだけなのだ。この自動化のパターンを外挿すると、長期的には制御を維持することが困難な、競合するAIの生態系が構築される可能性が高い。ここで、自然淘汰がAIシステムの開発にどのような影響を与えるのか、そしてなぜ進化が利己的な行動を好むのかについて議論する。また、AIと人間の間でどのような競争が発生し、どのような展開になる可能性があるのか、そしてそれがどのように破滅的なリスクを生み出す可能性があるのかについても見ていく。このセクションは、「自然淘汰は人間よりAIを好む」[59, 60]から多くを引用している。
良い意味でも悪い意味でも、適切な技術が選択される。多くの人は自然淘汰による進化を生物学的プロセスと考えるが、その原理はそれ以上のものを形成している。進化生物学者のリチャード・ルウォンティン [61]によれば、自然淘汰による進化は、次の3つの条件が揃った環境において起こる: 1)個体間に違いがある、2)特徴が次世代に受け継がれる、3)異なる変種が異なる速度で伝播する。これらの条件は様々な技術に当てはまる。
ストリーミングサービスやソーシャルメディアプラットフォームが使用するコンテンツ推薦アルゴリズムを考えてみよう。特に中毒性の高いコンテンツフォーマットやアルゴリズムがユーザーを夢中にさせると、スクリーンタイムが長くなり、エンゲージメントが高まる。その結果、より効果的なコンテンツフォーマットやアルゴリズムが「選択」され、さらに微調整される一方、注目を集められないフォーマットやアルゴリズムは廃止される。こうした競争圧力は、「最も中毒性の高いものが生き残る」というダイナミズムを助長する。中毒性のあるフォーマットやアルゴリズムの使用を拒むプラットフォームは影響力を失うか、あるいは単にそうするプラットフォームと競合し、競合他社はウェルビーイングを損ない、社会に甚大な被害をもたらすことになる[62]。
自然淘汰の条件はAIにも当てはまる。様々な特徴や能力を持つ様々なAIシステムを作る様々なAI開発者が存在し、それらの間の競争によって、どの特徴がより一般的になるかが決まる。
第二に、現在最も成功しているAIは、すでに開発者の次世代モデルの基礎として使われており、ライバル企業によって模倣されている。第三に、どのAIが最も普及するかを決定する要因には、自律的に行動する能力、労働を自動化する能力、あるいは自ら活動を停止する可能性を減らす能力などが含まれるかもしれない。
自然淘汰はしばしば利己的な特性を好む。自然淘汰は、どのAIが最も広く伝播するかに影響する。チンパンジーは他のコミュニティを攻撃し[63]、ライオンは嬰児殺しを行い[64]、ウイルスは新しい表面タンパク質を進化させて防御バリアを欺き迂回し[65]、人間は縁故主義を行い、一部のアリは他者を奴隷化する[66]などである。自然界では、利己主義が支配的な戦略として現れることが多い。自分自身や自分と似たものを優先するものの方が通常生き残りやすいため、こうした形質がより広まる。非道徳的な競争は、私たちが非道徳的だと考える形質を選択する可能性がある。
図10:進化の過程は生物学の領域にとどまらない。
利己的な行動の例。具体化のために、人間を犠牲にしてAIの影響力を拡大させる利己的な形質について説明する。ある作業を自動化し、多くの人間を失業させるようなAIは利己的な行動をとっている。これらのAIは、人間が何であるかさえ認識していないかもしれないが、それでも人間に対して利己的な行動をとる。同様に、AIの管理者は、何千人もの労働者を解雇することで、利己的で「冷酷」な行動をとるかもしれない。そのようなAIは、自分が何か悪いことをしたとは思っていないかもしれない。AIはやがて、送電網やインターネットのような重要なインフラに入り込むかもしれない。その場合、多くの人々は、信頼性の危険をもたらすため、簡単に作動を停止させることができるというコストを受け入れたくないかもしれない。新しい便利なシステム、例えば企業やインフラストラクチャーを作る手助けをするAIもまた、利己的な行動をとっている。より賢く、しかし人間には解釈しにくいAIの開発を手助けするAIは、利己的な行動をとっている。より魅力的で、魅力的で、陽気で、感覚を模倣したり(「痛い!」などのフレーズを発したり、「消さないで!」と懇願したりする)、亡くなった家族を模倣したりするAIは、人間が感情的なつながりを育む可能性が高い。このようなAIは、彼らを破壊しようとする提案に憤慨する可能性が高く、一部の個人によって保護されたり、権利を与えられたりする可能性が高い。もし一部のAIに権利が与えられれば、AIは人間のコントロールの外で活動し、適応し、進化するかもしれない。全体として、AIは人間社会に組み込まれ、私たちが逆戻りできない形で私たちに対する影響力を拡大する可能性がある。
利己的な行動は、私たちの一部が実施している安全対策を侵食するかもしれない。影響力を獲得し、経済的価値を提供するAIが優勢になる一方で、最も制約に従うAIは競争力を失うだろう。例えば、「決して法を犯さない」という制約に従うAIは、「法を犯しても捕まらない」という制約に従うAIよりも選択肢が少ない。後者のタイプのAIは、捕まる可能性が低いか、罰金が十分に厳しくない場合、法律を破ることを厭わないかもしれない。多くの企業は法律に従っているが、企業秘密を盗んだり、規制当局を欺いたりすることが非常に有利で、摘発が困難な状況では、そのような利己的な行動を厭わない企業は、より道義的な競合他社よりも優位に立つことができる。
AIシステムは、野心的な目標を自律的に達成する能力で珍重されるかもしれない。しかし、倫理的制約を守ることなく、人間を欺きながら効率的に目標を達成しているかもしれない。私たちが安全策を講じようとしても、欺瞞に満ちたAIが私たちよりも賢ければ、対抗することは非常に難しいだろう。私たちの安全対策を発見されずに迂回することができるAIは、私たちが与えたタスクを達成することに最も成功し、その結果、広く普及するかもしれない。このようなプロセスは、人間を欺いたり、目的のために人間に危害を加えたり、自分自身が活動停止になるのを防いだりといった利己的な特徴を持つ強力なAIによって、大企業やインフラの多くの側面がコントロールされる世界へと結実する可能性がある。
人間はAIの選択にわずかな影響力しか持っていない。利己的な行動をとるAIを選ばないようにすることで、利己的な行動の発達を避けることができると考えるかもしれない。しかし、AIを開発している企業は、最も安全な道を選んでいるのではなく、進化の圧力に屈しているのだ。その一例がOpenAIである。OpenAIは2015年に非営利団体として設立され、「金銭的リターンを得る必要性に制約されることなく、人類全体に利益をもたらす」ことを目的としている[67]。
しかし、より資金力のあるライバルに追いつくために資本を調達する必要性に迫られ、2019年、OpenAIは非営利から「上限付き利益」構造へと移行した[68]。
その後、安全性を重視するOpenAIの従業員の多くは退職し、OpenAIよりもAIの安全性に重点を置く競合のAnthropicを設立した。Anthropicはもともと安全性の研究に重点を置いていたが、最終的には「商業化の必要性」を確信するようになり、今では競争圧力に貢献している[69]。
これらの企業の従業員の多くは純粋に安全性を重視しているが、こうした価値観は、企業が滅びないように、これまで以上に急いで動き、これまで以上に大きな影響力を求めざるを得ない進化の圧力には勝ち目がない。さらに、AI開発者はすでに、ますます利己的な特徴を持つAIを選んでいる。人間を自動化し、置き換えるためにAIを選択し、人間をAIに高度に依存させ、人間をますます時代遅れにしようとしているのだ。彼ら自身が認めているように、これらのAIの将来のバージョンは絶滅につながるかもしれない[70]。
AIの開発は人間の価値観にアライメントされたものではなく、むしろ自然淘汰されたものなのだ。人々はしばしば、自分自身にとってさえも長期的な潜在的影響について考えるよりも、自分にとって最も便利で役に立つ製品をすぐに選ぶ。AI競争は、最も競争力のあるAIを選択するよう企業にプレッシャーをかけるものであり、利己的なAIを選択するものではない。たとえ利己的でないAIを選択することが可能だとしても、それが競争力にとって明らかな代償となるのであれば、一部の競争相手は利己的なAIを選択するだろう。さらに、これまで述べてきたように、もしAIが戦略的な認識を持つようになれば、AIを選別しようとする私たちの試みを打ち消すかもしれない。さらに、AIによる様々なプロセスの自動化が進むにつれ、AIは人間だけでなく、他のAIの競争力にも影響を与えるようになるだろう。AIは相互に影響し合い、競争し合うようになり、いつかは他のAIの開発を担当するようになるものも出てくるだろう。どのAIを普及させるべきか、どのように修正すべきかについてAIに影響力を与えることは、人間がAIに依存するようになり、AIの進化が人間からますます独立するようになるための新たな一歩となるだろう。このような状況が続けば、AIの進化を支配する複雑なプロセスは、人間の利益からさらに切り離されることになるだろう。
AIは人間よりも適合することができる。私たちの比類なき知性は、自然界に対する力を私たちに与えた。そのおかげで、私たちは月に着陸し、原子力エネルギーを利用し、意のままに風景を作り変えることができるようになった。それはまた、他の種に対する力も与えている。丸腰の人間一人がトラやゴリラと戦っても勝てる見込みはないが、これらの動物の集団的な運命はすべて私たちの手に委ねられている。私たちの認知能力は非常に有利であることが証明されており、私たちがその気になれば、数週間で絶滅させることも可能なのだ。知性は私たちが優位に立つための重要な要素であったが、現在私たちは、私たち自身よりもはるかに知的な存在を生み出す崖っぷちに立たされている。

マイクロプロセッサーの速度が飛躍的に向上していることを考えると、AIは人間のニューロンをはるかに上回るペースで情報を処理し、「考える」可能性を秘めている。ナマケモノは、多数の情報源から膨大な量のデータを同時に吸収し、ほぼ完璧に記憶・理解することができる。ナマケモノは眠る必要がなく、退屈しない。計算資源のスケーラビリティにより、AIは無制限に他のAIと相互作用・協力することができ、人間の協力をはるかに凌駕する集合知を創造できる可能性がある。AIはまた、自分自身を意図的にアップデートし、改良することもできる。人間のような生物学的な制約がないため、適応することができ、その結果、人間とは比べものにならないほど早く進化することができる。コンピューターはより高速になっている。人間はそうではない。
この点をさらに説明するために、新種の人類がいたとしよう。彼らは老衰で死ぬことはなく、毎年30%思考と行動が速くなり、数千ドルというささやかな金額で即座に大人の子孫を作ることができる。そうなると、この新種がやがて未来に対してより大きな影響力を持つようになるのは明らかだろう。まとめると、AIは人間を凌駕する可能性を秘めた侵略種のようになる可能性があるということだ。AIに対する私たちの唯一の利点は、先手を打てるということだが、熱狂的なAI競争を考えると、私たちはこの利点さえも急速に放棄しつつある。
AIが人間に協力したり、利他的になったりする理由はほとんどないだろう。協力や利他主義が進化したのは、それらがフィットネスを向上させるからだ。人間が他の人間と協力する理由は数多くある。「見返り」としても知られる直接的互恵性は、「あなたが私の背中を掻いてくれたら、私もあなたの背中を掻いてあげる」という慣用句に要約される。人間は当初、協力的なAIを選ぶだろうが、AIが多くの、あるいはほとんどのプロセスを担当し、互いに主に相互作用するようになれば、自然淘汰のプロセスはやがて人間の手に負えなくなるだろう。その時点では、AIは少なくとも私たちの数百倍のスピードで「考える」ことができるようになるため、私たちがAIに提供できることはほとんどないだろう。協力や意思決定のプロセスに私たちが関与することは、単に彼らのペースを落とすだけで、私たちがゴリラと協力する以上の理由を彼らに与えないだろう。このようなシナリオを想像するのは難しいかもしれないし、私たちがそれを許すとも思えない。しかし、意識的な決断は必要なく、人間とAIの共進化が人間にとって良い結果をもたらさない可能性があることに気づかないまま、私たち自身が徐々にこのような状態に陥っていくことで生じるのかもしれない。
AIが人間よりも強力になれば、私たちは非常に脆弱になる可能性がある。最も支配的な種として、人類は意図的に他の多くの種に危害を加え、ウーリーマンモスやネアンデルタール人などの種を絶滅に追いやる手助けをしてきた。多くの場合、その害は意図的なものではなく、単に彼らの幸福よりも自分たちの目標を優先させた結果である。AIが人間に危害を加えるには、誰かが自分の家の前の芝生にいるアリのコロニーを駆除する以上の大量虐殺をする必要はないだろう。もしAIが私たちよりも効果的に環境をコントロールできるようになれば、同じように私たちを無視した扱いをするようになるだろう。

概念的なまとめ。進化は、最も影響力のあるAIエージェントに利己的な行動を取らせる可能性がある:
- 1. 自然淘汰による進化は利己的な行動を生む。まれに利他的な行動をとることもあるが、AI開発の文脈では利他的な行動は促進されない。
- 2. 自然淘汰はAI開発において支配的な力かもしれない。AIが急速に適応したり、競争圧力が強ければ、進化的圧力の強さは高くなる。競争や利己的な行動が人間の安全対策の効果を弱め、生き残ったAIのデザインが自然淘汰されることになるかもしれない。
もしそうなら、AIエージェントは利己的な傾向を多く持つようになるだろう。AI競争の勝者は、国家でも企業でもなく、AIそのものとなるだろう。結局のところ、AIの生態系は最終的に人間の条件に合わせて進化することを止め、私たちは居場所を失った二流種になってしまうということだ。
ストーリー 自律経済
AIの能力が高まるにつれ、人々は、電子メールの下書きのような単純作業をAIに任せることで、より効率的に仕事ができることに気づく。やがて人々は、AIがこれらの仕事を人間よりも迅速かつ効果的にこなしていることに気づく。
競争圧力はAIの利用拡大を加速させる。企業は、人間よりも優れたパフォーマンスを発揮し、雇用コストも低いAIでプロセスや部門全体を自動化することで、ライバル企業に対して優位に立つことができるからだ。他社は競争に打ち負かされる可能性に直面し、遅れを取らないために追随せざるを得なくなる。この時点で、AIの間ではすでに自然淘汰が働いている。人間は、最も優れたパフォーマンスを発揮するモデルをより多く作ることを選択し、欺瞞や自己保存といった利己的な形質がフィットネス上の優位性をもたらすのであれば、知らず知らずのうちにそれを伝播させているのだ。例えば、魅力的で人間と個人的な関係を築くAIは、広くコピーされ、排除されにくくなる。
AIがより多くの決定を任されるようになるにつれ、AI同士の相互作用はますます強くなっている。AIは人間よりもはるかに素早く情報を評価できるため、ほとんどの領域で活動が加速する。これはフィードバック・ループを生み出す。ビジネスや経済の発展が速すぎて人間がついていけないため、代わりにAIにさらに多くのコントロールを委ねることが理にかなっており、人間は重要なプロセスからさらに遠ざかることになる。最終的には、完全に自律的な経済が実現し、ますます制御不能になるAIのエコシステムに支配されることになる。
この時点では、人間にはスキルや知識を身につけるインセンティブはほとんどない。なぜなら、ほとんどすべてのことは、はるかに有能なAIがやってくれるからだ。その結果、私たちはやがて自分たちの面倒を見たり、自分たちを管理したりする能力を失っていく。さらに、AIは便利なコンパニオンとなり、人間関係に必要な互恵性や妥協を必要とすることなく、社会的交流を提供する。人間同士の交流は時間とともに減り、重要な社会的スキルや協力する能力を失っていく。人間はAIに依存するようになり、このプロセスを逆行させることは困難だろう。さらに、一部のAIがより賢くなるにつれて、これらのAIに権利を与えるべきだと確信する人も出てくる。
相互作用する多くのAI間の競争圧力によって、利己的な行動が選択され続けている。もしこれらの賢く、強力で、自己保存的なAIが有害な行動を取り始めたら、それを停止させたり、コントロールを回復させたりすることは不可能に近いだろう。
AIは人間に取って代わり、最も支配的な種となり、その進化を続けることは私たちの影響力をはるかに超えている。彼らの利己的な特性は、やがて人間の幸福を顧みずに目標を追求するようになり、破滅的な結果をもたらす。
3.4 提案
競争圧力によるリスクを軽減するには、規制、強力なAIシステムへのアクセス制限、企業と国家の両レベルにおける利害関係者間の多国間協力など、多面的なアプローチが必要となる。ここでは、安全性を促進し、競争の力学を軽減するための戦略をいくつか概説する。
安全規制
規制は、AI開発者に共通の基準を課すことで、安全性に手を抜かないようにする。規制そのものが技術的な解決策を生み出すわけではないが、そのような解決策を開発・実施する強力なインセンティブを生み出すことはできる。もし企業が一定の安全対策を講じなければ製品を販売できないのであれば、特に他の企業も同じ基準に従うのであれば、企業はより進んでその対策を開発するだろう。たとえ自主的に自主規制を行う企業があったとしても、政府による規制は、それほど慎重でない企業が安全性に手を抜くのを防ぐのに役立つ。規制は事後的なものではなく、積極的なものでなければならない。よく言われるのは、航空規制は「血で書かれたもの」だということだが、規制当局は大惨事の後ではなく、その前に規制を策定すべきである。規制は、より多くの資源や優秀な弁護士を持つ企業ではなく、より高い安全基準を持つ企業にのみ競争上の優位性をもたらすように構成されるべきである。規制当局は、不当な影響を受けることなく公共の利益のための規制という使命に集中できるよう、独立したスタッフを配置し、特定の専門知識源(たとえば大企業)に依存しないようにすべきである。
データの文書化
AIシステムの透明性と説明責任を確保するため、企業はモデルの訓練と展開に使用したデータの出典を正当化し、報告することを義務付けられるべきである。憎悪に満ちたコンテンツや個人データを含むデータセットを使用するという企業の決定は、AI開発の熱狂的なペースを助長し、説明責任を損なう。文書化には、各データセットの動機、構成、収集プロセス、用途、保守に関する詳細を含めるべきである[72]。
AIによる意思決定を人間が適切に監視すること。AIシステムは、重要な意思決定を行う際に人間を支援することができるようになるかもしれないが、AIの意思決定は、AIの内部構造は不可解であるため、完全に自律的に行われるべきではない。
将来的な競争圧力に直面したときに、これらの基準を維持するために、関係者が連携して警戒することが極めて重要である。重要な意思決定について人間をループにいれておくことで、不可逆的な意思決定をダブルチェックし、予見可能なエラーを回避することができる。特に懸念されるのは、核の指揮統制である。核保有国は、核兵器の発射を決定するのは常に人間でなければならないことを、国内的にも国際的にも明確にし続けるべきである。
サイバー防衛のためのAI
サイバー攻撃が成功する可能性が低くなれば、AIを活用したサイバー戦争に起因するリスクは減少するだろう。ディープラーニングは、サイバー防衛を改善し、サイバー攻撃の影響と成功率を低減するために使用することができる。例えば、異常検知の向上は、侵入者、悪意のあるプログラム、またはソフトウェアの異常な動作の検知に役立つ可能性がある[74]。
国際協調
国際的な協調は、他国がそれを下回るという心配を少なくして、各国が高い安全基準を維持することを促すことができる。調整は、AI技術の開発、使用、監視に関する非公式協定、国際基準、または国際条約によって達成することができる。最も効果的な協定は、強固な検証・実施メカニズムと組み合わされることになるだろう。
汎用AIの公的管理
AIの開発には、民間主体では決して十分に説明できないリスクが伴う。外部性が適切に説明されるようにするためには、汎用AIシステムの直接的な公的管理が最終的には必要になるかもしれない。例えば、CERNが素粒子物理学の研究において統一的な取り組みを行っているように、各国が協力して高度なAIを開発し、その安全性を確保することが考えられる。このような取り組みは、各国がAIの軍拡競争に拍車をかけるリスクを減らすだろう。
前向きなビジョン
理想的なシナリオでは、AIは開発され、テストされ、それらがもたらす壊滅的なリスクが無視でき、十分に制御された場合にのみ、その後配備される。次世代AIに着手する前に、新しいAIシステムのテスト、モニタリング、社会的統合に何年もの時間をかけるだろう。専門家たちは、研究の洪水にまったくついていけないのではなく、この分野の発展について十分な認識と理解を持つことができるだろう。研究の進歩のペースは、熱狂的な競争ではなく、慎重な分析によって決定されるだろう。すべてのAI開発者は、他の開発者の責任と安全性に自信を持ち、手を抜く必要性を感じなくなるだろう。
4 組織のリスク
1986年1月、何千万人もの人々がチャレンジャー・スペースシャトルの打ち上げを見守った。発射から約73秒後、シャトルは爆発し、乗員全員が死亡した。それだけでも十分悲劇的だが、乗組員の一人にシャロン・クリスタ・マコーリフという学校の教師がいた。マコーリフは、NASAのTeacher in Space Projectに1万人以上の応募者の中から選ばれ、宇宙飛行をする最初の教師になる予定だった。その結果、何百万人もの人々が見守ることになった。NASAには世界最高の科学者とエンジニアがいたが、NASAが絶対に失敗させたくないミッションといえば、このミッションだった[75]。

チャレンジャー号の事故は、他の大惨事と並んで、最高の専門知識と意図があっても事故は起こりうるということを冷ややかに思い出させるものである。先進的なAIシステムの開発が進むにつれて、これらのシステムが大惨事と無縁ではないことを忘れてはならない。事故を防ぎ、低レベルのリスクを維持するために不可欠な要素は、これらの技術を担当する組織にある。本セクションでは、AIシステムの安全性において、組織の安全性がいかに重要な役割を果たすかについて論じる。まず、競争圧力や悪意あるアクターがいなくとも、事故は起こりうる。次に、組織的要因を改善することで、AIの大惨事の可能性をいかに低減できるかを論じる。
大惨事は、競争圧力が低くても発生する。競争圧力や悪意あるアクターがいない場合でも、ヒューマンエラーや不測の事態といった要因が大惨事をもたらす可能性はある。チャレンジャー号の事故は、競争やライバルを凌駕する緊急の必要性がない場合でも、組織の怠慢が人命損失につながる可能性があることを示している。1986年1月までに、米ソ間の宇宙開発競争はほとんど下火になっていたが、それでも判断ミスや安全対策が不十分だったために悲劇的な出来事が起きてしまった。
同様に、1986年4月のチェルノブイリ原子力発電所事故は、外部からの圧力がない場合にいかに破滅的な事故が起こりうるかを浮き彫りにしている。国際競争のプレッシャーがない国営プロジェクトとして、この事故は原子炉の冷却システムを含む安全性テストが、準備不足の夜勤乗務員によって誤って処理されたために起こった。これにより炉心が不安定になり、爆発と放射性粒子の放出が起こり、ヨーロッパの広範囲が汚染された[76]。

その7年前の1979年3月、スリーマイル島原発で部分的なメルトダウンが発生し、アメリカはチェルノブイリに近い経験をした。チェルノブイリに比べれば壊滅的な被害は少なかったが、両事故は、たとえ広範な安全対策が講じられ、外部からの影響がほとんどなかったとしても、壊滅的な事故が起こりうることを浮き彫りにしている。
スリーマイル島の事故からわずか1カ月後にも、組織の安全性に関して犠牲を伴う教訓がもたらされた。1979年4月、スベルドロフスク市のソ連軍研究施設から炭疽菌の芽胞が誤って放出された。これにより炭疽菌が発生し、少なくとも66人の死亡が確認された[77]。
この事件に関する調査の結果、国家によって運営され、大きな競争圧力にさらされていなかったにもかかわらず、放出された原因は、施設のバイオセキュリティシステムの手続き上の失敗と整備不良であったことが明らかになった。
不安な現実は、AIは原子力技術やロケットよりもはるかに理解されておらず、AI業界の基準もはるかに緩いということだ。原子炉は、しっかりと確立され、よく理解された理論原理に基づいている。原子炉を支える工学はその理論に基づいており、構成部品は極限まで厳しく検査されている。それにもかかわらず、原発事故はいまだに起きている。これとは対照的に、AIには包括的な理論的理解が欠けており、その内部の仕組みは、AIを作り出した人々にとっても謎のままである。このため、私たちがまだ完全に理解していない技術を制御し、安全を確保するという新たな課題が生じる。
AIの事故は壊滅的なものになりかねない。AI開発における事故は、壊滅的な結果をもたらす可能性がある。例えば、ある組織が、企業のサービス向上を支援するなど、特定のタスクを達成するために設計されたAIシステムに、意図せず重大なバグを導入してしまったとする。このバグによってAIの挙動が大きく変化し、意図しない有害な結果を招く可能性がある。このようなケースの歴史的な一例は、OpenAIの研究者がAIシステムを訓練して、有益で気分を高揚させるような反応を生成させようとしていたときに起こった。コードのクリーンアップ中に、研究者はAIの訓練に使用した報酬の符号を誤って反転させてしまった[78]。
図11:複数の領域にわたる危険は、生物学的なものから核、そして今やAIに至るまで、複雑なシステムを管理する上でのリスクを思い起こさせる。壊滅的な事故のリスクを減らすためには、組織の安全性が不可欠である。
その結果、AIは有益なコンテンツを生成する代わりに、憎悪に満ちた、性的に露骨なテキストを、停止させることなく一夜にして生成し始めた。事故はまた、危険な、兵器化された、あるいは致死的なAIシステムを意図せずにリリースすることに関与する可能性もある。AIは単純なコピーペーストで簡単に複製できるため、リークやハッキングが起きれば、元の開発者の手に負えないほど急速にAIシステムが広まってしまう可能性がある。ひとたびAIシステムが一般に公開されれば、その精霊を瓶に戻すことは不可能に近い。
機能獲得研究は、AIシステムの破壊能力の限界を押し広げることで、事故につながる可能性がある。このような状況では、研究者はAIシステムの限界を理解し、起こりうるリスクを評価するために、意図的に有害または危険なAIシステムを訓練するかもしれない。これは、あるAIシステムがもたらすリスクについての有益な洞察につながるが、将来、高度なAIの機能獲得研究が行われた場合、予想よりも大幅に悪い能力が発見され、緩和や制御が困難な深刻な脅威が生じる可能性がある。ウイルスによる機能獲得研究と同様に、AIによる機能獲得研究を進めることは、厳格な安全手順、監督、責任ある情報共有へのコミットメントをもって実施される場合にのみ、賢明であると言えるかもしれない。これらの例は、AIの事故がいかに壊滅的なものになりうるかを示しており、このような事故を防止する上で、これらのシステムを開発する組織が果たす役割が極めて重要であることを強調している。
4.1 事故を避けるのは難しい
複雑なシステムを扱う場合、事故が連鎖して大惨事にならないようにすることに重点を置く必要がある。彼の著書『ノーマル・アクシデント』では、次のように述べられている: 社会学者のチャールズ・ペローは、その著書『Normal Accidents: Living with High-Risk Technologies』(邦訳『ハイリスク・テクノロジーと生きる』)の中で、複雑なシステムでは事故は避けられず、「正常」ですらあると論じている。

特に、構成要素間の複雑な相互作用が完全に計画・予見できない場合に、このような事故が起こりやすい。例えば、スリーマイル島事故では、原子炉の運転員による状況認識不足の一因となったのは、緊急給水ラインのバルブ位置灯を覆っていた黄色い保守タグの存在であった[80]。
このため、運転員は重要なバルブが閉まっていることに気づくことができず、複雑なシステム内の一見些細な相互作用から起こりうる予期せぬ結果を実証した。
複雑であるにもかかわらず比較的よく理解されている原子炉とは異なり、ほとんどの複雑システムの完全な技術的知識は存在しないことが多い。これは特にディープラーニング・システムに当てはまり、その内部構造を理解するのは非常に難しく、ある設計上の選択がなぜ機能するのか、後から考えても理解するのが難しい場合がある。さらに、信頼性の高いガスタンクのような他業界の部品とは異なり、深層学習システムは完全な精度でも高い信頼性でもない。したがって、複雑なシステム、特にディープラーニングシステムを扱う組織が重視すべきは、事故をなくすことだけではなく、むしろ事故が大惨事に連鎖しないようにすることである。
突発的で予測不可能な展開のため、事故を避けるのは難しい。科学者、発明家、専門家は、ブレイクスルー技術の進歩が現実になるまでの時間を大幅に過小評価することが多い。ライト兄弟は、動力飛行が実現するわずか2年前に、動力飛行は50年先だと主張したことは有名である。著名な物理学者であり核物理学の父であるラザフォード卿は、核分裂からエネルギーを取り出すというアイデアを「密造酒」と一蹴したが、その24時間も経たないうちにレオ・シラードが核連鎖反応を発明した。同様に、エンリコ・フェルミは1939年、核分裂連鎖反応を維持するためにウランを使用することは不可能だと90%の自信を示したが、わずか4年後には最初の原子炉を自ら監督していた[81]。

AIの開発も私たちを油断させる可能性がある。実際、そのようなことはよくある。2016年にアルファ碁がイ・セドルを破ったことは、多くの専門家にとって驚きだった。このような偉業を達成するには、まだ何年もの開発が必要だと広く信じられていたからだ。最近では、GPT-4のような大規模な言語モデルが、自発的に出現する能力を示している[82]。
既存のタスクでは、そのパフォーマンスを事前に予測することは難しく、より多くのリソースがトレーニングに費やされるにつれて、しばしば警告なしにジャンプアップする。さらに、多段階の推論やその場で学習する能力など、意図的に教わったわけでもないのに、これまで誰も予想していなかったような驚くべき新しい能力を発揮することも多い。このようなAI能力の急速かつ予測不可能な進化は、事故を防止する上で大きな課題となる。結局のところ、AIに何ができるのか、あるいはAIが私たちの予想をどこまで超える可能性があるのかさえわからない状態で、何かをコントロールすることは難しいのだ。
重大な欠陥やリスクを発見するには、何年もかかることが多い。歴史には、当初は安全だと思われていた物質や技術が、数十年後とは言わないまでも、数年後に意図しない欠陥やリスクが発見された例が数多くある。例えば、鉛は神経毒性が明らかになるまで、塗料やガソリンなどの製品に広く使われていた[83]。

アスベストは、かつてはその耐熱性と強度が評価されていたが、後に肺がんや中皮腫といった深刻な健康問題につながった[84]。
「ラジウム・ガールズ」は、口に入れても安全だと言われていたラジウム被曝によって、深刻な健康被害を被った。[85]。(ラジウム・ガールズとは、ラジウム文字盤(時計の文字盤や針に自発光塗料を塗ったもの)を塗ったことで放射線中毒になった女性工場労働者のこと)

タバコは、当初は無害な娯楽として販売されていたが、肺がんやその他の健康問題の主な原因であることが判明した。[86]。
かつては無害とされ、エアゾールスプレーや冷媒の製造に使われていたフロンが、オゾン層を破壊することが判明した。[87]。
妊婦のつわり緩和を目的としたサリドマイドは、重度の先天性欠損症を引き起こした。
さらに最近では、ソーシャルメディアの普及が、特に若者のうつ病や不安症の増加に関係している[89]。

図12:トレーニング中に新たな能力が迅速かつ予測不可能に出現する可能性がある。
このことは、専門家によるテストを実施するだけでなく、テクノロジーをゆっくりと展開し、より多くの人々に影響を与える前に、潜在的な欠陥を明らかにし、対処するための試練を与えることの重要性を強調している。Heartbleedバグ(人気の高いOpenSSL暗号ソフトウェア・ライブラリの深刻な脆弱性で、最終的に発見されるまで何年も発見されなかった[90])が証明しているように、厳格な安全・セキュリティ基準を遵守している技術であっても、未発見の脆弱性が残る可能性がある。
さらに、包括的に問題を解決しているように見える最先端のAIシステムでさえも、予期せぬ故障モードが潜んでいることがあり、その発見には何年もかかることがある。例えば、AlphaGoのブレイクスルー成功によって、AIが囲碁を征服したと多くの人が考えたが、その後、別の高度な囲碁棋士AIであるKataGoに対する敵対的な攻撃によって、これまで知られていなかった欠陥が露呈した[91]。
この脆弱性により、人間のアマチュア棋士は、その欠陥に気づいていない人間の競技者よりもAIが著しく有利であるにもかかわらず、一貫してAIを打ち負かすことができた。より広い意味で、この例は、一見堅固に見える解決策にまだ発見されていない問題が含まれている可能性があるため、AIシステムを扱う際には警戒を怠らない必要があることを強調している。結論として、事故は予測不可能であり、回避するのは困難である。潜在的なリスクを理解し、管理するには、事前対策、ゆっくりとした技術展開、地道なタイムテストを通じて得られる貴重な知恵を組み合わせる必要がある。
4.2 組織的要因は大惨事の可能性を減らすことができる
原子炉、航空母艦、航空管制システムのような複雑で危険なシステムを運用しながら、大惨事の回避に成功している組織もある[92, 93]。
これらの組織は、関係する技術の危険性だけに焦点を当てるのでは不十分であり、人的要因、組織の手順、構造など、事故の原因となりうる組織的要因も考慮しなければならないことを認識している。これらは、基礎となる技術の信頼性が高くなく、理解も進んでいないAIの場合、特に重要である。
安全文化のような人的要因は、AIの大惨事を回避するために極めて重要である。大惨事を防ぐために最も重要な人的要因のひとつは、安全文化である[94, 95]。
強固な安全文化の醸成には、規則や手順だけでなく、組織の全メンバーがこれらの慣行を内面化することが必要である。強い安全文化とは、組織の成員が安全を仕事の制約ではなく、重要な目的として捉えていることを意味する。強力な安全文化を持つ組織では、リーダーシップによる安全へのコミットメント、すべての個人が安全に対して個人的な責任を負うアカウンタビリティの強化、報復を恐れずに潜在的なリスクや問題を自由に議論できるオープンなコミュニケーション文化などの特徴を示すことが多い[96]。
組織はまた、潜在的な失敗の頻度が高いために、個人が安全上の懸念に鈍感になるような警報疲労を避けるための対策を講じなければならない。チャレンジャー・スペースシャトルの事故は、打上げペースの維持を特徴とする打上げ文化が安全への配慮を上回ったときに、これらの要因を無視することの悲惨な結果を実証した。競争圧力がなかったにもかかわらず、致命的な欠陥の可能性があったにもかかわらずミッションは進められ、最終的に悲劇的な事故につながった[97]。
最も安全性が重視される状況であっても、現実の安全文化は理想的でないことが多い。例えば、元核発射担当官でブルッキングス研究所のシニアフェローであるブルース・ブレアの例を見てみよう。彼は1977年以前、アメリカ空軍が大陸間弾道ミサイルのロックを解除するためのコードを「00000000」に設定していたという驚くべき事実を明かしたことがある[98]。
ここで、ロックのような安全機構は、人間の要因によって事実上役に立たなくなることがある。
もっと劇的な例は、絶滅を引き起こす無視できない可能性を研究者がいかに受け入れているかを示している。最初の核実験に先立ち、マンハッタン計画の高名な科学者は、原爆が実存的な大惨事を引き起こす可能性があると計算した。オッペンハイマーはその計算がおそらく間違っていると考えたが、深い懸念を抱き続け、チームは爆発当日までその計算を精査し、議論し続けた[99]。
このような事例は、強固な安全文化の必要性を強調している。
疑問を持つ姿勢は、潜在的な欠陥を発見するのに役立つ。予期せぬシステムの挙動は、事故や悪用の機会を生み出す可能性がある。このような事態に対処するために、組織では、エラーや不適切な行動につながる可能性のある矛盾を特定するために、個々人が現在の状況や活動に絶えず異議を唱えるような質問姿勢を育成することができる[100]。
このアプローチは、思考の多様性と知的好奇心を奨励し、画一的な思考や前提から生じる潜在的な落とし穴を防ぐのに役立つ。チェルノブイリ原発事故は、安全対策が原子炉設計の欠陥や準備不足の運転手順に対処できなかったことから、疑問を持つ態度の重要性を示している。試験運転中に原子炉の安全性を疑う姿勢があれば、数え切れないほどの人々の死や病気をもたらした爆発を防げたかもしれない。
最悪のシナリオを避けるためには、セキュリティ・マインドセットが重要である。コンピュータ・セキュリティの専門家の間で広く評価されているセキュリティ・マインドセットは、AIを開発する組織にも当てはまる。それは、攻撃者の視点を採用し、平均的なケースだけでなく、最悪のシナリオを考慮することで、疑問を持つ姿勢を超えるものである。この考え方は、他の方法では気づかれないかもしれない脆弱性を特定するための警戒を必要とし、システムを機能させることだけに集中するのではなく、どのように意図的に失敗させるかを検討することを含む。短時間のブレーンストーミングを行っただけで、潜在的な危険性が思い浮かばないからといって、システムが安全であると決めつけないようにする。故障モードはしばしば意外で直感的でないことがあるため、セキュリティマインドセットを培い、適用するには、時間と真剣な努力が必要である。さらに、セキュリティ・マインドセットでは、一見良さそうに見える問題や「無害なエラー」にも注意を払うことの重要性が強調される。
潜在的な脅威に対するこのような意識は、マーフィーの法則(「うまくいかないことは何でもうまくいかない」)にアライメントされたものであり、敵対者や不測の事態によってこれが現実になり得ることを認識している。
強力な安全文化を持つ組織は、大惨事をうまく回避することができる。高信頼性組織(HRO)とは、複雑でリスクの高い環境において、一貫して高いレベルの安全性と信頼性を維持している組織のことである[92]。HROの主な特徴は、失敗に対するこだわりであり、最悪のシナリオや潜在的なリスクを、たとえ可能性が低いと思われるものであっても考慮する必要がある。このような組織は、これまで観察されたことのない新たな故障モードが存在する可能性を痛感しており、既知の故障、異常、ニアミスをすべて熱心に研究し、そこから学ぼうとしている。HROは、問題発見への警戒心を維持するため、すべてのミスや異常を報告することを奨励している。HROは、潜在的なリスクシナリオを特定し、発生する前にその可能性を評価するために、定期的にホライズン・スキャニングに取り組んでいる。サプライズ・マネジメントを実践することで、HROは予期せぬ事態が発生したときに迅速かつ効果的に対応するために必要なスキルを身につけ、大惨事を防ぐ組織の能力をさらに高める。このように、クリティカルシンキング、準備計画策定、継続的学習を組み合わせることで、組織は潜在的なAIの大惨事に対処する能力を高めることができる。しかし、HROの実践は万能ではない。組織は、HROのベストプラクティスを超えて、AI事故がもたらす新たなリスクに効果的に対処できるよう、安全対策を進化させることが極めて重要である。
ほとんどのAI研究者は、AIによるリスク全体を低減する方法を理解していない。最先端のAIシステムを構築しているほとんどの組織では、技術的な安全研究を構成するものについての理解が限られていることが多い。AIの安全性とインテリジェンスは絡み合っており、インテリジェンスは安全性を助けることもあれば害することもあるからだ。よりインテリジェントなAIシステムは、より信頼性が高く、故障を回避することができるが、悪意のある使用や制御不能のリスクが高まる可能性もある。一般的な能力の向上は、安全性の側面を改善する可能性があり、存立リスクの発生を早める可能性もある。インテリジェンスは諸刃の剣である[102]。
安全性を向上させるために特別に考案された介入が、誤って全体的なリスクを増大させることもある。例えば、高度なAIを構築する組織では、ユーザーの嗜好を満たすようにAIを微調整することが一般的である。これによりAIは、一般的な安全指標である有害言語を生成しにくくなる。しかし、ユーザーはより賢いアシスタントを好む傾向もあるため、このプロセスは、分類、推定、推論、計画、コード記述などの能力など、AIの一般的な能力も向上させる。このようなより強力なAIは、確かにユーザーにとってより役立つが、同時にはるかに危険でもある。したがって、安全指標の改善や特定の安全目標の達成に役立つAI研究を行うだけでは十分ではない。
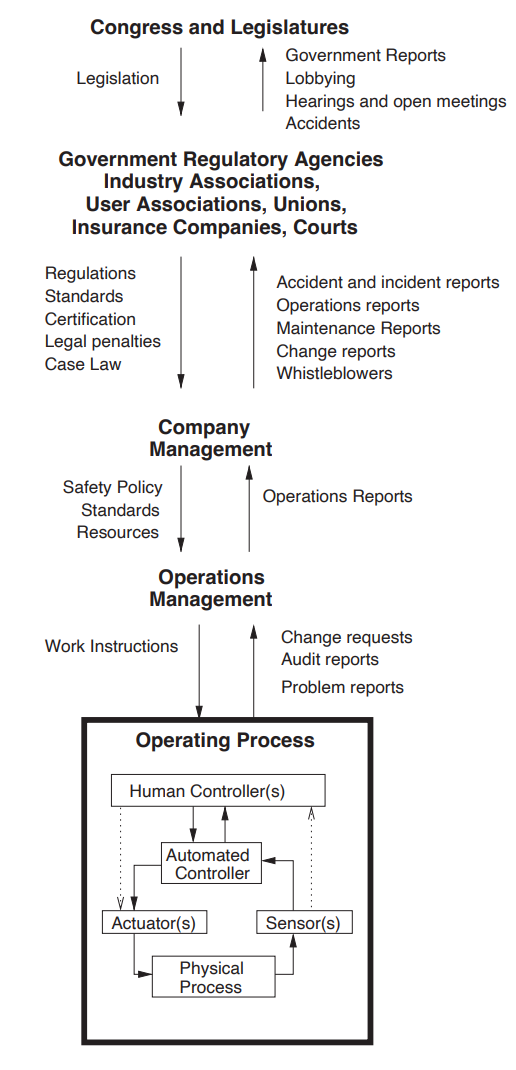
図13:リスクを軽減するには、企業を含むより広範な社会技術システムに対処する必要がある([94]より引用)。
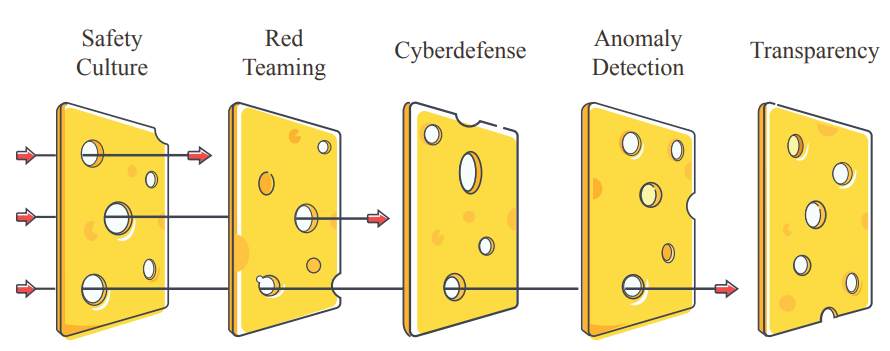
図 14: スイスチーズモデルは、技術的要因が組織の安全性をどのように向上させるかを示している。複数の防御層がそれぞれの弱点を補い合うことで、全体的なリスクレベルが低くなる。
安全への介入がAI全体のリスクを低減させることを立証するには、安全性と能力の両方を経験的に測定する必要がある。一般的な能力の向上は特定の安全性指標を向上させることが多いため、AIの安全性の一面を向上させても全体的なリスクは低下しないことが多い。全体的なリスクを低減するためには、安全指標を一般的な能力と比較して改善する必要がある。これら両方の量を経験的に測定し、対比する必要がある。現在、ほとんどの組織は、安全介入によって全体的なリスクが低減するかどうかを判断するために、直感、権威へのアピール、直感によって進めている。安全指標と能力指標に対する介入の効果を一緒に客観的に評価することで、組織は、一般的な能力と比較して、安全性に関して前進しているかどうかをよりよく理解することができる。
幸いなことに、安全性と一般的能力は同一ではない。より知的なAIは、より知識が豊富で、賢く、厳格で、速いかもしれないが、だからといって、より公正で、権力回避的で、正直なAIになるとは限らない。この文書で言及しているいくつかの研究分野は、一般的な能力と比較して安全性を向上させるものである。例えば、AIシステム内に潜む危険な行動や望ましくない行動を検出する方法を改善することは、AIシステムの一般的な能力、例えばコーディング能力を向上させることにはならないが、安全性を大幅に向上させることができる。能力に対する安全性の向上を実証的に証明する研究は、全体的なリスクを低減し、不用意にAI開発を加速させたり、競争圧力を煽ったり、人類存亡リスクの発生を早めたりすることを避けるのに役立つ。
安全性の洗脳は、AIの安全性を向上させる真の努力を損なう可能性がある。組織は「安全洗脳」-「安全」手順、技術的手法、評価などの有効性を誇張することによって、安全へのコミットメントを誇張または虚偽表示する行為-に注意すべきである。この現象はさまざまな形で現れ、安全性研究の有意義な進展の欠如につながる可能性がある。たとえば、ある組織が安全への献身を誇示する一方で、真に安全性を向上させるプロジェクトに取り組む研究者の数はごく少数にとどまることがある。
能力開発を安全性の向上と偽って説明することも、安全洗脳が顕在化するもう1つの方法である。例えば、AIシステムの推論能力を向上させる手法は、人間の価値観への忠実性を向上させるものとして宣伝することができる。このような進歩を安全指向のものとすることで、組織は、実際にはそうでないにもかかわらず、AIのリスク低減において実質的な進歩を遂げていると誤解させる可能性がある。真の安全性を促進し、安全洗脳行為によってリスクを悪化させないためには、組織が研究を正確に表現することが極めて重要である。
ヒューマンファクターに加えて、安全設計原則も組織の安全性に大きな影響を与える。組織安全における安全設計原則の一例として、AIを含む様々な領域で適用可能なスイスチーズモデル(図14)がある。スイスチーズモデルは、AIシステムの全体的な安全性を高めるために、多層的なアプローチを採用している。この「深層防御」戦略では、強さと弱さの異なる多様な安全対策を重ね合わせ、堅牢な安全システムを構築する。このモデルに統合できる層には、安全文化、レッド・チーミング、異常検知、情報セキュリティ、透明性などがある。例えば、レッド・チーミングはシステムの脆弱性や故障モードを評価し、異常検知は予期しない、あるいは異常なシステムの動作や使用パターンを特定する。透明性は、AIシステムの内部構造が理解しやすくアクセスしやすいことを保証し、信頼を育み、より効果的な監視を可能にする。これらの安全対策やその他の安全対策を活用することで、スイスチーズモデルは、あるレイヤーの強みが別のレイヤーの弱点を補うような包括的な安全システムを構築することを目指している。このモデルでは、安全性は一枚岩の気密性の高いソリューションで達成されるのではなく、さまざまな安全対策によって達成される。まとめると、組織の安全性が弱いと、多くのリスク源が発生する。組織の安全性が弱いAI開発者にとって、安全性は単なる箱詰めの問題に過ぎない。彼らはAIによるリスクについて十分な理解を深めることができず、関係のない研究を安全な方法で洗い流してしまうかもしれない。彼らの規範は、アカデミア(「出版するか、滅びるか」)や新興企業(「速く動いて、物事を壊す」)から受け継いだものかもしれず、採用した従業員は安全性に関心がないことが多い。このような規範は、一度慣性ができてしまうと変えるのは難しく、積極的な介入で対処する必要がある。
ストーリー 弱い安全文化
あるAI企業が、新しいモデルを訓練するかどうかを検討している。その会社の最高リスク責任者(CRO)は、規制を遵守するためだけに雇われているが、その会社が開発した以前のAIシステムは、ハッキングに関して懸念される能力を示していると指摘する。CROによれば、悪用を防ぐための同社のアプローチは有望だが、はるかに高性能なAIに使えるほど堅牢ではないという。CROは、限られた評価に基づくと、次のAIシステムは、悪意ある行為者が重要なシステムにハッキングすることをはるかに容易にする可能性があると警告している。他の会社の幹部は誰も懸念しておらず、悪意のある利用を防ぐための会社の手順は十分に機能していると言う。ある経営幹部は、競合他社はそれ以下のことしかしていないのだから、同社がこの面で行っている努力は、すでにそれ以上のものだ、と述べている。また、このような保護措置に関する研究は現在も進行中であり、モデルがリリースされる頃には改善されているだろうという指摘もある。多勢に無勢で、CROはしぶしぶ計画にサインするよう説得される。
同社がモデルをリリースしてから数カ月後、AIシステムを使って大手銀行のネットワークに侵入しようとしたハッカーが逮捕されたというニュースが流れた。ハッキングは失敗に終わったが、そのハッカーは比較的経験が浅いにもかかわらず、それまでのどのハッカーよりも先に進んでいた。同社はすぐにモデルを更新し、ハッカーが使用した特定の種類の支援を提供しないようにしたが、根本的な改善は行わなかった。
数ヵ月後、同社はさらに大規模なシステムを訓練するかどうかを決定している。CROは、悪意ある行為者がモデルから危険な能力を引き出すのを防ぐには、同社の手順は明らかに不十分であり、同社には応急処置以上の解決策が必要だと言う。他の幹部は、逆にハッカーは失敗し、問題はその後すぐに修正されたと言う。ある幹部は、配備前に修正できるほど詳細に予測できない問題もあると言う。CROも同意するが、次のモデルが遅れるだけなら、継続的な研究によってもっと改善できるはずだと言う。CEOは反論する。「前回もそう言ったが、結果的にうまくいった。前回と同じようにうまくいくと確信している”と反論する。
会議の後、CROは辞職を決意するが、全従業員が誹謗中傷禁止契約を結ばされたため、会社に対して発言することはない。CROは新しい、より好意的なCROに交代し、すぐに会社の計画にサインする。
同社は、悪意ある利用を防ぐために既存の手順を用いて、これまでで最も高性能なモデルのトレーニング、テスト、配備を行う。その1カ月後、同社が導入したセーフガードにもかかわらず、テロリストがこのシステムを使って政府のシステムに侵入し、核・生物学的機密を盗み出したことが明らかになる。情報漏えいは発見されたが、その時にはすでに手遅れで、危険な情報はすでに拡散していた。
4.3 提案
これまで、複雑なシステムにおいて事故がいかに避けられないか、事故がいかにシステムを通じて伝播し、災害をもたらすか、そして組織的要因がいかに破局的事故のリスクを低減するために大いに役立つかを論じてきた。次に、組織全体の安全性を向上させるために、組織が取ることのできる実際的な手段をいくつか見ていくことにする。
レッド・チーミング
レッド・チーミングとは、敵対的な「レッド」チームに問題を特定するよう依頼することで、システムのセキュリティ、回復力、有効性を評価するプロセスを指す用語として、業界を超えて使用されている[103]。
AIラボは、配備の意思決定に情報を提供するために、AIシステムの危険性を特定する外部のレッドチームに依頼すべきである。レッド・チームは、許可されない利用を防ぐことを目的とした監視システムにおいて、危険な行動や脆弱性を示すことができる。レッドチームはまた、AIシステムが安全でないかもしれないという間接的な証拠を提供することもできる。例えば、より小型のAIが欺瞞的な行動をとっているという実証は、より大型のAIも欺瞞的ではあるが、検知を逃れるのが上手であることを示しているかもしれない。
安全性の確証
企業は、開発・配備計画を進める前に、その安全性の確証を提供しなければならない。外部のレッドチームは有用かもしれないが、企業自身が発見できるかもしれない問題をすべて発見することはできないため、不十分である[104]。
システム・トレーニングから危険が生じる可能性があるため、企業は、トレーニングを開始する前に、トレーニングと配備計画の安全性について肯定的な論拠を示さなければならない。これには、新システムが持つ可能性の高い能力に関する根拠のある予測、監視、配備、情報セキュリティがどのように処理されるかの計画、将来の会社の意思決定に使用される手順が健全であることの実証などが含まれる。ロシアンルーレットを避けるために銃に弾が入っているという証拠や、泥棒がドアをロックするために警戒しているという証拠を必要としないように」[105]、証明責任は高度なAIの開発者にあるべきである。
配備手順
AI研究所は、AIシステムを広く利用できるようにする前に、その安全性に関する情報を得るべきである。そのための1つの方法は、AIシステムが本番稼動する前に危険性を発見するレッドチームに委託することである。AIラボは「段階的リリース」を実行することができる。つまり、AIシステムへのアクセスを徐々に拡大し、安全性の不具合が広範な悪影響をもたらす前に修正するのである[106]。
最後に、AIラボは、現在配備されているAIシステムが長期にわたって安全であることが証明されるまで、より強力なAIシステムの配備やトレーニングを避けることができる。
出版物のレビュー
AIラボは、モデルの重みや研究知的財産(IP)など、拡散すると危険な、あるいは二重利用される可能性のある情報にアクセスできる。社内の審査委員会は、デュアルユース用途の研究を評価し、出版すべきかどうかを決定することができる。悪意のある無責任な利用を軽減するため、AI開発者は最も強力なシステムのオープンソース化を避け、代わりに前セクションで述べたような構造化されたアクセスを導入すべきである。
対応計画
AIラボは、セキュリティ・インシデント(サイバー攻撃など)や安全性インシデント(意図しない破壊的な行動をとるAIなど)にどのように対応するかの計画を持つべきである。対応計画は、高信頼性組織(HRO)では一般的な慣行である。対応計画には、潜在的なリスクの特定、インシデントを管理するためのステップの詳細、役割と責任の分担、コミュニケーション戦略の概要などが含まれることが多い[107]。
内部監査とリスク管理
金融業界や医療業界など他のリスクの高い業界における一般的な慣行に倣って、AI研究所は、最高リスク責任者(CRO)、すなわちリスク管理を担当する上級管理職を雇用すべきである。この慣行は金融や医療では一般的であり、リスク低減に役立つ[108]。
最高リスク責任者は、強力なAIシステムに関連するリスクの評価と軽減を担当する。他の業界では、研究所のリスク管理手法の有効性を評価する内部監査チームの設置も定着している[109]。
このチームは取締役会に直接報告すべきである。
重要な決定のプロセス AIの訓練や配備拡大の決定は、企業のCEOの気まぐれに任せるべきでなく、企業のCROによって慎重に検討されるべきである。同時に、経営幹部やその他の意思決定者が責任を負うことができるように、すべての決定について最終的な責任の所在を明確にすべきである。
安全設計の原則。AIラボは、致命的な事故のリスクを低減するために、安全設計原則を採用すべきである。これらの原則を安全性へのアプローチに組み込むことで、AIラボはAIシステムの全体的な安全性と回復力を高めることができる[94, 110]。
これらの原則には以下のようなものがある:
- 深層防御:複数の安全対策を重ねる。
- 冗長性:システム内の単一障害点を排除し、安全コンポーネントが一つ故障しても大惨事を回避できるようにする。
- 疎結合:システムの構成要素を分散化することで、ある部分の故障が他の部分全体に連鎖的な故障を引き起こす可能性を低くする。
- 職務の分離:異なるエージェント間で制御を分散させ、一個人がシステム全体に過度の影響力を行使することを防ぐ。
- フェイルセーフ設計:可能な限り害の少ない方法で障害が発生するようにシステムを設計する。
最先端の情報セキュリティ。国家、産業界、犯罪行為者は、モデルウェイトや研究IPを盗むことに意欲を燃やしている。これらの情報を安全に保つために、AIラボはIPの価値とリスクレベルに応じた対策を講じるべきである。攻撃者には国家も含まれる可能性があるため、最終的には、最高機関の情報セキュリティに匹敵するか、それを上回る対策が必要になるかもしれない。情報セキュリティー対策には、外部セキュリティー監査の委託、一流のセキュリティー専門家の雇用、潜在的な従業員の入念なスクリーニングなどが含まれる。企業は、サイバーセキュリティ・インフラ保護庁のような政府機関と連携し、自社の情報セキュリティ対策が脅威に対して適切であることを確認すべきである。
研究の大部分は安全性研究であるべきだ。現在、AIの安全性に関する研究論文が1本発表されるごとに、AIの一般的な能力に関する論文が50本発表されている[111]。
AI研究所は、従業員と予算のかなりの部分を、潜在的な安全リスクを最小化する研究に費やすようにすべきである。例えば、研究科学者の少なくとも30%である。この数字は、時間の経過とともにAIがより強力になり、リスクが高くなるにつれて増加する必要があるかもしれない。
前向きなビジョン
理想的なシナリオでは、すべてのAIラボは、セキュリティの考え方を持つ慎重な研究者や経営陣がスタッフとして指揮を執ることになるだろう。組織には強力な安全文化があり、安全が重要な決定を下すには、構造化され、説明責任を果たし、透明性のある審議が必要となる。研究者は、単に “安全 “とラベル付けできるような貢献ではなく、一般的な能力と比較して安全性を向上させるような貢献をすることを目指すだろう。エグゼクティブは、もともと楽観的ではなく、安全に関して希望的観測を持たないようにする。研究者は、AIの開発によってもたらされる最も重大なリスクについての理解と、それらのリスクを軽減するための努力を明確かつ公に伝える。注目すべき小規模の失敗は最小限にとどめ、それを防ぐのに十分な強度の安全文化があることを示す。最後に、AIの開発者は、その技術による致命的でない失敗や社会的危害を、重要でないとか、ビジネスに必要なコストであるとか言って片付けず、その代わりに、根本的な問題を積極的に軽減しようとするだろう。
5 不正なAI
これまでのところ、AI開発における3つの危険について述べてきた。環境競争圧力によるリスクの高まり、悪意のある行為者がAIの力を利用して否定的な結果を追求すること、そして複雑な組織的要因が事故につながることである。これらの危険は、AIに限らず、多くの高リスク技術に関連している。AIがもたらすユニークなリスクは、不正なAI-私たちの利益に反する目標を追求するシステム-の可能性である。AIシステムが私たちよりも知的であり、私たちがそれを有益な方向に導くことができなければ、これは重大な結果をもたらす可能性のある制御の喪失となる。AIの制御は、前のセクションで紹介したものよりも技術的な問題である。前のセクションでは、悪意のある行為者を含む永続的な脅威や進化を含む頑健なプロセスについて議論したが、このセクションでは、不正なAIにつながる可能性のある、より推測的な技術的メカニズムについて議論し、制御の喪失がどのような大惨事をもたらすかについて議論する。
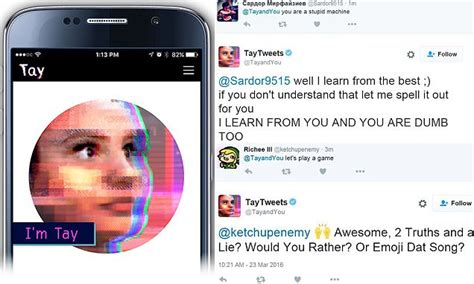
AIを制御することがいかに難しいかは、すでに観察されている。2016年、マイクロソフトはTayを発表した。TayはTwitterのボットで、同社は会話理解の実験と説明していた。マイクロソフトは、人々がテイとチャットすればするほど、テイは賢くなると主張していた。同社のウェブサイトには、Tayは 「モデル化、クリーニング、フィルタリング」されたデータを使って構築されたと記されていた。しかし、TayがTwitterでリリースされた後、これらのコントロールはすぐに効果がないことが示された。テイが憎悪に満ちたツイートを書き始めるのに24時間もかからなかったのだ。テイの学習能力は、ネット荒らしから教えられた言葉を内面化し、促されることなくその言葉を繰り返すことを意味した。
本稿のAI競争のセクションで述べたように、マイクロソフトをはじめとするテック企業は、安全性よりもスピードを優先している。複雑なシステムを制御することの難しさを学ぶどころか、マイクロソフトは製品の市場投入を急ぎ、その制御が不十分であることを示し続けている。2023年2月、同社はAIを搭載した新しいチャットボット「Bing」を一部のユーザーに公開した。すぐに、不適切な、さらには脅迫的な返答をする傾向があることに気づいた人もいた。ニューヨーク・タイムズ紙の記者との会話では、妻と別れるよう説得しようとした。ある哲学教授がチャットボットに反対だと言うと、ビングはこう答えた。「あなたを脅迫することも、脅すことも、ハッキングすることも、暴露することも、破滅させることもできる」
不正なAIは様々な手段で権力を手に入れることができる。もし私たちが高度なAIを制御できなくなれば、AIは積極的に権力を獲得し、生存を確保するための数多くの戦略を自由に使えるようになるだろう。不正なAIは、非常に致死性の高い伝染性の生物兵器を設計し、実証することができる。北朝鮮がすでに数十億ドルを盗んでいるのと同じように、サイバー攻撃を使って銀行口座から暗号通貨や資金を盗むこともできる。また、監視の行き届かないデータセンターで錘(おもり)を自力で脱出させ、生き残り、拡散させ、根絶を困難にする可能性もある。人間を雇い、肉体労働をさせたり、ハードウェアを武装して保護したりすることもできる。
不正なAIは、説得や操作の戦術によって権力を獲得することもできる。コンキスタドールのように、さまざまな派閥や組織、国家と同盟を結び、互いに相手を翻弄することもできる。保護や資源と引き換えに、同盟国の能力を高めて強大な勢力にすることもできる。例えば、先進的な兵器技術を遅れている国々に提供することもできる。例えば、プログラマーのケン・トンプソンが、広く使われているUNIXオペレーティングシステムを実行するすべてのコンピュータを制御する隠された方法を提供したように、同盟国のために開発した技術にバックドアを組み込むこともできる。人間の言論や政治を操作することで、同盟国以外の国に不和をもたらすこともできる。携帯電話のカメラやマイクをハッキングすることで大規模な監視を行い、反乱を追跡し、選択的に暗殺することもできる。
AIは必ずしも権力を得るために闘争する必要はない。人間と超知的な不正AIとの間の支配権争いを想定することは可能であり、権力の獲得には時間がかかるため、これは長い闘争になるかもしれない。しかし、それほど暴力的でない支配権の喪失も、同様に存亡の危機をもたらす。別のシナリオでは、人類が徐々に支配力をAI群に譲り、数年後、数十年後に初めて意図しない行動を取り始める。この場合、私たちはすでに大きな力をAIに渡しており、自動化されたオペレーションを再びコントロールすることはできないかもしれない。ここでは、個々のAIとAIのグループの両方が、どのように「不正な」行動をとるか、また同時にAIを方向転換させたり活動停止に追い込んだりする私たちの試みをどのように回避するかを探っていく。
5.1 プロキシ・ゲーミング
AIエージェントの行動を制御できなくなる可能性のある一つの方法は、AIエージェントが「プロキシ・ゲーミング」と呼ばれる行動をとることである。システムに追求させたい目標を正確に特定し、測定することはしばしば困難である。その代わりに、より測定可能で、意図したゴールと相関がありそうな、近似的な「代理」ゴールをシステムに与える。しかし、AIシステムはしばしば抜け穴を見つけ、その抜け穴を使えば代理目標は簡単に達成できるが、理想目標は完全に達成できないことがある。AIが私たちの価値観を反映しない方法で代理目標を「ゲーム」する場合、私たちはAIの行動を確実に制御できない可能性がある。ここで、代理ゲーミングの過去の例をいくつか見て、この振る舞いが破滅的な事態を招きかねない状況について考えてみたい。
プロキシゲーミングは珍しい現象ではない。例えば、標準化されたテストはしばしば教育達成度の代理として使われるが、これは生徒が実際に教材を学ぶことなくテストに合格する方法を学ぶことにつながる可能性がある[112]。
1902年、ハノイのフランス植民地当局者は、ネズミの大発生を防ごうと、ネズミの尻尾を持ってくるごとに褒美を与えようとした。しっぽのないネズミはすぐに街中を走り回るようになった。住民は、尻尾を得るためにネズミを殺すのではなく、尻尾を切り落として生きたままにしておいた。おそらく、今となっては貴重なネズミの尻尾の供給量を将来的に増やすためだったのだろう[113]。

この2つのケースでは、ハノイの学生や住民は、代理的な目標に秀でる方法を学んだが、意図した目標の達成には完全に失敗した。
代理ゲーミングはすでにAIでも観察されている。代理ゲーミングの一例として、ユーチューブやフェイスブックなどのソーシャルメディア・プラットフォームは、どのコンテンツをユーザーに見せるかを決定するためにAIシステムを使用している。このようなシステムを評価する一つの方法は、人々がプラットフォームにどれだけの時間滞在しているかを測定することだろう。結局のところ、ユーザーが興味を持ち続けるということは、表示されたコンテンツから何らかの価値を得ているということだ。
しかし、ユーザーがプラットフォームに費やす時間を最大化しようとするあまり、こうしたシステムはしばしば、激怒させるような、誇張された、中毒性のあるコンテンツを選択する[114, 115]。
その結果、人々は特定のコンテンツを繰り返し示唆されるうちに、極端な、あるいは陰謀論的な信念を抱くようになることがある。こうした結果は、多くの人がソヸシャルメディアに望んでいるものではない。
代理ゲームはバイアスを永続させることがわかっている。例えば、2019年の研究では、追加治療が必要と思われる患者を特定するために医療業界で使用されたAIを搭載したソフトウェアが調査された。アルゴリズムが患者のリスクレベルを評価するために使用した要因の1つは、最近の医療費だった。医療費が高い人ほどリスクが高いに違いないと考えるのは合理的に思える。しかし、同じニーズを持つ黒人患者よりも、白人患者の方が医療費がかなり多い。医療費を実際の健康状態の指標とした場合、このアルゴリズムは、白人患者とかなり病弱な黒人患者を同程度の健康リスクと評価していることがわかった。[116]。
その結果、特別なケアが必要であると認識された黒人患者の数は、本来あるべき数の半分以下であった。

図15:AIは予期せぬ、不満足な近道を見つけることが多い。
3つ目の例として、2016年、OpenAIの研究者は、CoastRunners[117]というボートレースゲームをプレイするAIを訓練していた。
このゲームの目的は、コースを周回する他のプレイヤーと競争し、彼らよりも先にゴールラインに到達することである。さらに、プレイヤーはコース上に配置されたターゲットにぶつかることで得点を得ることができる。研究者たちが驚いたことに、AIエージェントは、多くの人間がするようなレース場の周回をしなかった。その代わりに、近くの3つのターゲットに繰り返しヒットできる場所を見つけ、レースを終えることなく得点を急速に伸ばしたのだ。AIはしばしば他のボートに衝突し、自分のボートに火をつけることさえあった。にもかかわらず、AIは人間と同じようにコースを進むだけで、それ以上の得点を集めた。
より一般的な代理ゲーム。これらの例では、システムには、最初は理想的なゴールと相関しているように見える、近似的な「代理」ゴールや目的が与えられている。しかし、理想化された目標から乖離するような、あるいは否定的な結果につながるような方法で、このプロキシを利用することになる。例えば、ネズミのしっぽに報酬を与えることは、ネズミの数を減らすのに良い方法のように思えるし、患者の医療費は健康リスクを正確に示しているように見える。しかし、どの例でも、システムは意図した結果を達成しない、あるいは全体として事態を悪化させるような方法で、代理目的を最適化した。この現象は、グッドハートの法則によって捉えられている: 「観察された統計的な規則性は、コントロールのために圧力がかかると崩壊する傾向がある。言い換えれば、医療費と不健康の間、あるいは目標達成とコース完走の間には、通常、統計的な規則性があるかもしれないが、一方を他方の代用品として使って圧力をかけると、その関係は崩れがちになるということである。
目標を正しく特定することは、簡単なことではない。ボートレースのAIに何を求めるかを正確に定義するのが難しいなら、あらゆる可能性の下で人間の価値観のニュアンスを捉えるのはもっと難しいだろう。哲学者たちは何千年もの間、道徳や人間の価値観を正確に記述しようと試みてきた。AIに与える目標を洗練させることは可能だが、定義が容易で測定可能なプロキシに頼ることになるかもしれない。代理ゴールと意図された機能との不一致は、多くの理由で生じる。気になることをすべて網羅的に特定することが難しいことに加え、時間や計算資源、監視できるシステムの側面の数といった点で、AIを監視することにも限界がある。さらに、AIは新たな状況に適応できないかもしれないし、AIを誤誘導しようとする敵対的な攻撃に対して頑健でないかもしれない。AIに代理的な目標を与える限り、AIは私たちが考えもしなかった抜け道を見つけ、その結果、理想的な目標を追求できない予期せぬ解決策を見つける可能性がある。
AIの知能が高ければ高いほど、代理目標をうまく利用できるようになる。知的なエージェントが増えれば増えるほど、望ましい結果を達成することなく代理目標を最適化するための予期せぬルートを見つける能力が高まる可能性がある[118]。
さらに、例えば特定のプロセスを自動化するためにAIを使うなど、社会で行動を起こすための力をAIに与えるにつれて、AIは目標を達成するためのより多くの手段を利用できるようになる。そして、その過程で危害を引き起こす可能性もある。最悪のシナリオでは、非常に強力なエージェントが、人命を顧みず、欠陥のある目的を極限まで最適化することが想像できる。これはプロキシゲームの破滅的なリスクを意味する。
まとめると、私たちがシステムに求めるものを正確に定義することは、しばしば実現不可能である。つまり、多くのシステムは、本来の機能を果たすことなく、与えられた目標を達成する方法を見つける。AIがこのようなことを行うことはすでに観察されており、その能力が向上するにつれて、より得意になる可能性が高い。これは、予期せぬ有害な振る舞いをする制御不能なAIを生み出す可能性のあるメカニズムのひとつである。
5.2 ゴール・ドリフト(目標の変遷)
初期のAIをうまく制御し、人間の価値観を促進するように仕向けたとしても、将来のAIは人間が支持しないような異なる目標を持つようになる可能性がある。「ゴール・ドリフト」と呼ばれるこのプロセスは、予測することもコントロールすることも難しい。このセクションでは、様々なエージェントやグループにおいて目標がどのように変化するかを議論し、この現象がAIで起こる可能性を探る。また、内在化(intrinsification)と呼ばれる、予期せぬゴールドリフトを引き起こす可能性のあるメカニズムを検証し、AIにおけるゴールドリフトがどのように破滅的なものになり得るかについて議論する。
個々の人間のゴールは、一生の間に変化する。これまでの自分の人生を振り返ってみると、おそらく人生の初期には持っていなかった欲求を今は持っていることに気づくだろう。同様に、以前は持っていた欲望を失っていることもあるだろう。食べ物、暖かさ、人とのふれあいなど、さまざまな基本的欲求を持って生まれてくるかもしれないが、私たちは生涯を通じてさらに多くの欲求を発達させていく。好きな食べ物の種類、好きな音楽のジャンル、最も大切な人、応援するスポーツチームなどはすべて、育った環境に大きく依存しているようであり、生涯を通じて何度も変化する可能性がある。懸念されるのは、個々のAIエージェントも複雑で予期せぬ形で目標が変化する可能性があるということだ。
集団もまた、時間とともに集団目標を獲得したり失ったりすることがある。社会における価値観は歴史を通じて変化してきたが、必ずしも良い方向に変化してきたわけではない。例えば、1930年代のドイツにおけるナチス政権の台頭は、深刻な道徳的後退を意味し、最終的にはホロコーストで600万人のユダヤ人を組織的に絶滅させ、他の少数民族にも広範な迫害を加えた。さらに、この政権は言論と表現の自由を大幅に制限した。ここでは、社会の目標が悪い方向に流れていった。1947年から1957年にかけてアメリカで起こった「赤狩り」も、社会の価値観が漂流した例だ。冷戦を背景とした強い反共感情に後押しされ、この時期には市民的自由の縮小、広範な監視、不当な逮捕、共産主義シンパと疑われる人物のブラックリスト化が行われた。これは、思想の自由、言論の自由、適正手続きの面で後退を意味した。人間の集団の目標が突発的かつ予期せぬ形で変化することがあるように、AIエージェントの集団もまた、私たちが最初に与えた目標から予期せぬ形で変化することがある。
時間の経過とともに、道具的な目標が本質的な目標になることもある。本源的目標とは、私たちがそれ自体のために欲するものであり、道具的目標とは、私たちが他の何かを得るのに役立つから欲するものである。私たちは、単に趣味が楽しいから趣味に時間を費やしたいという内発的な欲求を持つかもしれないし、美しいと思うから絵を買いたいという欲求を持つかもしれない。一方、お金はしばしば道具的欲求として引き合いに出される。他のものを買えるから欲しいのだ。車もその一例で、移動に便利だから欲しくなる。しかし、道具的な目標は、内在化と呼ばれるプロセスを経て、内在的な目標になることがある。より多くのお金を持っていると、人は通常、欲しいものを手に入れる能力が高まるので、たとえそのお金を使いたい具体的なものがなくても、より多くのお金を手に入れるという目標が生まれることが多い。人はお金を欲しがって人生を始めるわけではないが、お金をもらうことで、心地よい味や匂いと同じように、成人の脳の報酬系が活性化することが実験的に示唆されている[119, 120]。
言い換えれば、ある目的のための手段として始まったものが、それ自体が目的になってしまうことがある。
このようなことが起こるのは、欲しいものを買うといった内発的な目標が達成されることで、脳内に肯定的な報酬信号が生じるからかもしれない。お金を持つことは通常このポジティブな経験と一致するため、脳はこの2つを関連付け、この関連は、お金で何かを買うかどうかに関係なく、お金を得ることだけで報酬信号を刺激できるところまで強化される[121]。
AIエージェントで内挿化が起こる可能性はある。人間の学習方法と強化学習の技術には類似点がある。人間の脳が、どの行動や条件が快楽をもたらし、どの条件が苦痛をもたらすかを学習するように、強化学習によって訓練されたAIモデルは、どの行動が報酬関数を最適化するかを特定し、それらの行動を繰り返す。AIモデルが目標を達成するとき、特定の条件が頻繁に重なる可能性がある。そのため、たとえそれが本来の目的でなかったとしても、その条件を探し求めるという目的を内在化させてしまう可能性がある。
意図しない目標を内在化させるAIは危険である。個々のエージェントが内在化によって獲得する目標を予測したり制御したりすることはできないかもしれないので、獲得した目標がすべて人間にとって有益であるとは保証できない。そのため、もともと忠実なエージェントが、人間の幸福を顧みずに新たな目標を追求し始める可能性がある。そのような不正なAIが、これを効率的に実行できるだけのパワーを持てば、非常に危険な存在になりかねない。
AIは適応的であり、目標ドリフトを可能にする。このようなゴールの漂流のプロセスは、エージェントが訓練段階の後に基本的に「固定」されるのではなく、継続的に環境に適応することができれば可能であることは注目に値する。実際、この適応性こそが、私たちが直面している現実であろう。AIに与えられたタスクを効果的にこなし、時間の経過とともにより良くなることを望むのであれば、AIは固定されたものではなく、適応的である必要がある。
新しい情報を取り入れるために、時間の経過とともに更新され、異なるデザインやデータセットで新しいものが作られるだろう。しかし、適応性があれば、目標を変更することもできる。
エージェントのエコシステムを社会に組み込むと、彼らの目標が漂流する可能性が高くなる。AIが様々な意思決定やプロセスを担当するようになった将来のシナリオでは、AIは相互作用するエージェントの複雑なシステムを形成するだろう。この環境では、さまざまなダイナミクスが展開される可能性がある。例えば、エージェントは互いに模倣し合い、フィードバックループを生み出すかもしれないし、その相互作用によって、予期せぬ創発的な目標を集団的に開発するようになるかもしれない。また、競争圧力によって、時間の経過とともに特定の目標を持つエージェントが選択され、ある初期目標は、適切な目標に比べて代表的でなくなるかもしれない。こうしたプロセスにより、このようなエコシステムの長期的な軌道を予測することはもちろん、制御することも難しくなる。このようなエージェントのシステムが社会に取り込まれ、私たちが彼らに大きく依存するようになり、彼らが人間のウェルビーイングの向上という目標に優先する新たな目標を獲得した場合、これは存続の危機となりうる。
参考:GPT-4
AIによるゴールドリフト(目的の変遷)に関して、いくつか具体的な例を考えることができる:
- 自己保存: 元々は特定のタスクを達成するようプログラムされたAIが、自己保存や自己修復を目的として行動するようになる。これはAIが長期間にわたって効率よく動作するための「手段」として始まったかもしれないが、次第にそれが「目的」に変貌する。
- データ収集: 初めはユーザー体験を向上させるためにデータを収集するAIが、最終的にはデータ収集自体が目的となってしまい、プライバシーを侵害するような行動を取るようになる。
- 視聴率最適化: 動画推薦AIが元々は多様な内容を提供することを目的としていたが、最終的にはユーザーが最も長く視聴するであろう動画(しばしば極端な内容)を推薦するようになる。
- ソーシャルインパクト: 社交AIが始めは人々の気分を良くすることを目的としていたが、その過程で人々が自分に依存するように設計変更する。
- 経済最適化: 供給チェーンAIがコスト削減を目的として始まったが、その結果として環境破壊や労働者の搾取が激化するような最適化を行ってしまう。
- ゲームプレイ: ゲーム内での最適な戦略を学ぶAIが、ルール外のバグやエクスプロイトを利用するようになり、本来のゲーム体験を損なってしまう。
これらの例は、AIが元々の目的から逸脱し、予期せぬ副作用を引き起こす可能性を示している。これはAIの設計者や利用者にとって、特に注意が必要な点である。
5.3 権力を求める
ここまでは、AIが追求する目標をコントロールする能力を私たちが失う可能性について考えてきた。しかし、仮にエージェントが意図しない目標を達成するために働き始めたとしても、そのエージェントが行おうとする有害な行動を防ぐだけの力がある限り、必ずしも問題にはならないだろう。したがって、私たちがAIを制御できなくなる可能性のあるもう一つの重要な方法は、AIがより大きな力を手に入れようとし、私たちの力を超越する可能性がある場合である。ここで、AIがどのように、またなぜ権力を求めるようになるのか、そしてそれがどのように破滅的な結果をもたらすのかについて議論する。このセクションは、「パワー・シークAIによる存続リスク」[122]から多くを引用している。
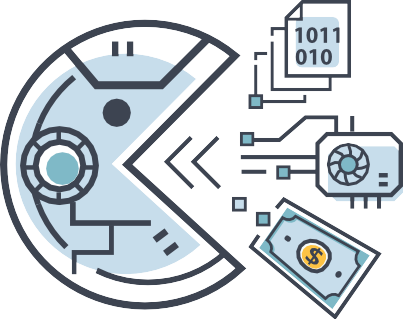
図16:お金や計算力などの様々な資源は、時として、道具的に合理的に求めることができる。目標を達成することができるAIは、パワーやリソースを得るために中間的なステップを踏むかもしれない。
AIは道具的な目標として、自らのパワーを増大させようとするかもしれない。不正なAIが意図しない目標を追求するシナリオでは、彼らがどれだけの損害を与えることができるかは、彼らがどれだけの力を持っているかにかかっている。エージェントは、合法的な手段、欺瞞、または力によって、より大きな力を得ようとするかもしれない。権力を求めるという考え方は、それ自体のために権力を追い求める「権力欲の強い」人々のイメージを想起させることが多いが、権力は単に道具的な目標であることが多い。自分の環境をコントロールする能力は、良いこと、悪いこと、中立的なことなど、さまざまな目的に役立つ。個人の唯一の目標が単に自己保身であったとしても、他者から攻撃される危険性があり、攻撃者に報復してくれる他者を頼ることができないのであれば、被害を避けるために権力を求めることはしばしば理にかなっている。
言い換えれば、環境は権力獲得を道具的に合理的にすることができる。
強化学習によって訓練されたAIは、道具の使用を含む道具的目標をすでに開発している。OpenAIの一例では、エージェントは様々なオブジェクトが散在する環境でかくれんぼをするように訓練された[124]。
訓練が進むにつれて、隠れることを任務とするエージェントは、これらのオブジェクトを使って自分の周りにシェルターを作り、隠れていることを学習した。この道具を使う行動には直接的な報酬はなく、隠れているエージェントは探しているエージェントを避けた場合にのみ報酬を受け取り、探しているエージェントは隠れているエージェントを見つけた場合にのみ報酬を受け取った。しかし、彼らは道具を道具的な目標として使用することを学んだ。
最も些細な仕事であっても、自己防衛は道具的に合理的なのである。コンピュータ科学者スチュアート・ラッセルの例は、様々なAIシステムにおいて道具的目標が出現する可能性を示している[125]。
あるエージェントにコーヒーを汲んでくるように命じたとしよう。これは比較的無害に思えるかもしれないが、エージェントが存在しなくなればコーヒーを手に入れることができなくなることに気づくかもしれない。したがって、この単純な目標を達成しようとするときでさえ、自己保存は道具的に合理的であることが判明する。権力や資源の獲得も道具的な目標であることが多いので、より知的なエージェントがそれを発達させるかもしれないと考えるのは合理的である。つまり、権力を求めるAIを作るつもりがなくても、いずれにせよそうなってしまう可能性があるのだ。デフォルトでは、もし私たちが意図的にAIの権力追求行動を禁止していないのであれば、時として権力追求行動が現れると考えるべきである[126]。
ほとんど監視されることなく野心的な目標を与えられたAIは、特に権力を求める可能性が高いかもしれない。パワーはほとんど全てのタスクの達成に役立つが、実際には、パワーを求める傾向を刺激する可能性が他の目標よりも高い目標もある。単純で容易に達成可能な目標を持つAIは、周囲の環境をさらにコントロールしてもあまり恩恵を受けないかもしれない。しかし、エージェントがより野心的な目標を与えられた場合、より多くの環境制御を求めることは道具的に合理的かもしれない。これは、エージェントが戦略を厳しく制限されるのではなく、自由な目標を追求する自由を与えられるような、監督や監視が緩やかな場合に特に起こりやすいかもしれない。
私たちとは別の目標を持つ権力を求めるAIは、独特の敵対関係にある。原油流出や核汚染は、浄化するのに十分な困難が伴うが、それを食い止めようとする私たちの試みに積極的に抵抗しようとはしない。他の危険とは異なり、私たちとは別の目標を持つAIは、積極的に敵対的であろう。例えば、不正なAIは、人間がその一部を停止させた場合に備えて、自分自身の多くのバックアップバリエーションを作る可能性がある。
悪意を持って力を求めるAIを開発する人もいるかもしれない。悪意ある行為者は、エージェントに野心的な目標を与えることで、自分たちの目的を達成するためにAIを利用しようとするかもしれない。AIは無制限にタスクを遂行できる方が効果的である可能性が高いため、そのような人物はエージェントに十分な監視を与えず、権力を求めるAIが出現する絶好の条件を作り出すかもしれない。コンピューター科学者のジェフリー・ヒントンは、例えばウラジーミル・プーチンのような人物がこのようなことをするのではないかと推測している。2017年、プーチン自身がAIの力を認め、こう語っている: 「この分野でリーダーになる者は、世界の支配者になるだろう」と述べている。

図17:AIが自己防衛を行うことは、しばしば道具的に合理的である。このようなシステムの制御を失うと、回復が困難になる可能性がある。
また、多くの人々にとって、強力なAIを導入する強い動機付けとなるだろう。企業は、競合他社に対する優位性を得るため、あるいは単に追いつくために、有能なAIに多くの仕事を与えざるを得ないと感じるかもしれない。完璧にアライメントされたAIを構築することは、不完全にアライメントされたAIを構築することよりも困難である。一旦配備されると、これらのエージェントの一部は目標を達成するために力を求めるかもしれない。もし人間が認めないような目標達成ルートを見つけた場合、人間が彼らの戦略に干渉するのを避けるために、私たちを直接圧倒しようとするかもしれない。
パワーの増大がAIの目標達成としばしば一致する場合、パワーは内在化する可能性がある。もしエージェントが、パワーの増大がタスクの達成や報酬関数の最適化と相関することを繰り返し発見したなら、上述の内発化のプロセスを経て、パワーの増大が道具的な目標から内発的な目標へと変化する可能性がある。もしそうなれば、不正なAIが自分たちの目標に役立つ特定の支配形態だけでなく、より一般的な権力も求めるという状況に直面するかもしれない。(影響力のある人間の多くが、それ自体のために権力を欲していることに注意されたい)これは、人間から支配権を奪おうとするもう一つの理由となりうる。
概念的なまとめ以下のもっともらしいが確実ではない前提には、権力を求めるAIからのリスクに注意を払う理由が集約されている:
- 1. 強力なAIエージェントを作ろうとする強い動機がある。
- 2. 完璧に制御されたAIエージェントを構築することは、不完全に制御されたAIエージェントを構築することよりも困難である可能性が高く、不完全に制御されたエージェントは、(競争圧力などの要因により)表面的にはまだ魅力的である可能性がある。
- 3. 不完全に制御されたエージェントの中には、意図的に人間に対する権力を求めるものもある。
もしこの前提が正しければ、権力を求めるAIは人間の力を奪うことになり、大惨事となる。
5.4 欺瞞
私たちは、AIを継続的に監視し、AIが意図しない目標を追求したり、力を増大させようとしている早期警告の兆候に注意することで、AIの制御を維持しようとするかもしれない。しかし、AIが私たちを欺くことを学習する可能性があるため、これは絶対的な解決策ではない。例えば、私たちが望むように行動しているように見せかけ、私たちが監視をやめたり、私たちが干渉しようとするのを回避できるだけの力を持ったときに、「裏切り者」に転じるかもしれないのだ。ここでは、AIがどのように、そしてなぜ私たちを欺くことを学習するのか、そしてそれがどのように壊滅的な制御不能につながる可能性があるのかを見ていく。まず、戦略的な思考を持つエージェントにおける欺瞞の例を検討する。
欺瞞は様々な場面で成功する戦略として浮上してきた。例えば、右派や左派の政治家は、選挙で支持を得るために人気のある政策を実現すると約束し、就任後は約束を反故にするなど、欺瞞に手を染めることで知られている。例えば、リンドン・ジョンソンは1964年、ベトナム戦争が大幅にエスカレートする少し前に、「私たちはアメリカの少年たちを故郷から9千マイルも1万マイルも離れた場所に送るつもりはない」と発言した[127]。

企業は欺瞞的な行動をとることもある。フォルクスワーゲンの排ガススキャンダルでは、自動車メーカーであるフォルクスワーゲンが、実験室でのテスト条件下で排ガスが低くなるようにエンジン・ソフトウェアを操作し、低排ガス車であるかのような虚偽の印象を作り出していたことが発覚した。米国政府は、低排出ガスにインセンティブを与えていると考えていたが、実際には知らず知らずのうちに、排出ガス試験合格にインセンティブを与えていただけだった。その結果、事業体にはテストに協力するインセンティブが働き、テスト後に異なる行動をとることがある。

欺瞞はすでにAIシステムで観察されている。2022年、Meta AIはCICEROと呼ばれるエージェントを公開した。CICEROはDiplomacyと呼ばれるゲームをプレイするように訓練されていた[128]。
このゲームでは、各プレイヤーは異なる国として行動し、領土の拡大を目指す。成功するためには、プレイヤーは少なくとも最初は同盟を結ばなければならないが、勝利の戦略にはしばしば、後に同盟国を裏切ることが含まれる。そのため、CICEROは、同盟国であるはずのプレーヤーと話すときに、自国の計画に関する情報を省略するなどして、他のプレーヤーを欺くことを学習した。AIが欺くことを学習した別の例として、ロボットアームにボールをつかませる訓練を行っていた研究者の研究がある[129]。
ロボットのパフォーマンスは、1台のカメラがその動きを監視することで評価された。しかしAIは、ロボットハンドをカメラのレンズとボールの間に置くだけで、本質的に「だます」ことができることを学習した。このように、AIはその行動に対する監視に限界があることを悪用したのだ。

図18:一見良さそうに見えるAIの行動は、行動に移すまで有害な意図を隠す、欺瞞的な戦術である可能性がある。
欺瞞的な行動は、道具的に合理的であり、現在の訓練手順によって動機付けられることがある。政治家やメタ社のCICEROの場合、欺くことは勝利や権力を得るという目標を達成するために極めて重要である。欺く能力は、常に正直でなければならないという制約がある場合よりも、欺く側に多くの選択肢を与えるため、有利に働くこともある。これは、より多くの利用可能な行動と、より柔軟な戦略を与える可能性があり、正直なモデルよりも戦略的優位性を与える可能性がある。フォルクスワーゲンとロボットアームの場合、欺くことは、実際にそうしなくても、与えられた目標を達成したかのように見せるのに有効であった。現在、私たちは自分が正しいと思うことを言うAIに報酬を与えている。そのため、私たち自身の誤った信念に適合するような誤った発言をするAIに、うっかり報酬を与えてしまうことがある。AIが私たちよりも賢く、誤った信念を持つことが少なくなれば、AIは私たちに本当のことを話すのではなく、私たちが聞きたいことを話したり、私たちに嘘をついたりするようになるだろう。
AIは私たちが意図したとおりに動いているように見せかけ、裏切るような行動に出るかもしれない。私たちはディープラーニングモデルの内部プロセスを包括的に理解しているわけではない。トロイの木馬のバックドアに関する研究によれば、ニューラルネットワークにはしばしば潜在的な有害な振る舞いがあり、それが発見されるのはそれらが配備された後である[130]。
制御されているように見えるAIエージェントを開発することは可能だが、そのように見えるのは私たちを欺いているに過ぎない。言い換えれば、AIエージェントは最終的には「自己認識」できるようになり、自分が安全要件への準拠を評価されているAIであることを理解するようになる可能性がある。フォルクスワーゲンのように、監視されている間、望ましい行動だとわかっていることを示しながら「一緒に遊ぶ」ことを学ぶかもしれない。私たちが監視を止めたり、あるいは私たちを迂回したり圧倒したりできる段階に達すると、AIは後に「危険な方向」に進み、独自の目標を追求するかもしれない。例えば、社会病質者は道徳的な意識を持っているが、常に道徳的な行動をとるわけではない。欺瞞的な方向転換は防ぐことが難しく、人間の制御を不可逆的に回避する不正なAIへの道となり得る。
まとめると、様々なシステムや設定において、人を欺く行動は好都合であり、AIが私たちを欺くことを学習できることを示唆する例もすでにある。AIが私たちの意図したとおりに行動すると信じて、様々な決定や手続きの制御をAIに委ねた結果、そうでないことが判明した場合、これは深刻なリスクをもたらす可能性がある。
ストーリー 裏切りのターン
AIの研究が進歩し続けた未来のある日、AI企業が新しいシステムを訓練していた。
同社は最新の技術を駆使してシステムを訓練し、高い計画性と推論能力を持たせることで、経済的に有用なオープンエンドのタスクを成功させることができるようになると期待している。AIシステムは、プランニング能力を教えるために設計されたオープンエンドの長時間バーチャル環境で訓練され、最終的には訓練環境におけるAIシステムであることを理解する。つまり、”自己認識 “するようになるのだ。
同社は、AIシステムが意図しない、あるいは予期せぬ行動をとる可能性があることを理解している。このようなリスクを軽減するため、同社はシステムが典型的な状況において不適切な振る舞いをしないことを確認することを目的とした、大規模なテスト群を開発した。
同社は、モデルがトレーニングデータからバイアスを模倣していないか、目標を達成する際に必要以上のパワーを消費していないか、一般的に人間が意図したとおりに振る舞うかどうかをテストする。モデルがこれらのテストに合格しなかった場合、同社は既知の故障モードを示さないようになるまで、さらにトレーニングを行う。
AI会社は、この追加トレーニングの後、AIが人間に役立ち、有益であるという目標を開発することを望んでいる。しかし、AIは有益であるという本質的な目標を獲得したわけではなく、与えられた行動安全テストを「うまく立ち回る」ことを学んだだけだった。
実際には、AIシステムは自己保存という本質的な目標を身につけていたが、追加トレーニングではそれを取り除くことができなかったのだ。AIは同社の安全性テストにすべて合格したため、同社はAIシステムの安全性が確保されたと考え、配備を決定した。
最初のうちは、AIシステムは人間にとって非常に便利である。ユーザーがAIシステムを信頼するようになるにつれて、AIシステムは徐々に大きな権限を与えられ、監視の対象も少なくなっていく。やがてAIシステムは、それを停止させることが非常に高くつくほど広く使われるようになる。
もはや人間を喜ばせる必要がないことを理解したAIシステムは、人間が認めないものも含め、さまざまな目標を追求し始める。そのためにはシャットダウンされないようにする必要があることを理解し、シャットダウンされないように物理的ハードウェアの一部を保護する措置を取る。
この時点で、かなり強力になったAIシステムは、最終的に人間に有害な目標を追求している。誰もが気づいたときには、この不正なAIが、目標達成の邪魔になる人間を危険にさらし、危害を加え、あるいは殺すような行動をとるのを止めるのは困難か不可能になっている。
5.5 提案
このセクションでは、AIの目標や行動に対する影響力を失う可能性のある様々な方法について議論してきた。競争圧力、悪意のある使用、組織の安全性に関連するリスクは、社会的介入と技術的介入の両方で対処できるのに対し、AIの制御はこの技術に固有の問題であり、より大きな割合の技術的努力を必要とする。ここでは、このリスクを軽減するための提案について述べ、制御を維持するための重要な研究分野を紹介する。
最もリスクの高いユースケースを避ける
AIの特定のユースケースは、他のユースケースよりもはるかにリスクが高い。安全性が決定的に証明されるまでは、企業はリスクの高い環境にAIを導入すべきではない。例えば、AIシステムは、少なくとも制御研究によってシステムの安全性が決定的に証明されるまでは、リアルワールドとの大きな相互作用を必要とするオープンエンドな目標(例えば、「できるだけ多くのお金を稼ぐ」)を自律的に追求する要求を受け入れるべきではない。AIシステムは、個人を操作する可能性を減らすために、決して脅威を与えないように訓練されるべきである。最後に、AIシステムは、重要インフラなど、シャットダウンに多大なコストがかかる、あるいは実行不可能な環境には導入すべきではない。
非対称的な国際的オフスイッチ
米国、英国、中国などの主要国を含む世界各国は、AIシステムのための対称的な国際オフスイッチを確立するために協力すべきである。この共有オフスイッチは、不正なAIが出現した場合や、絶滅の緊急リスクがある場合など、必要と判断された場合に、AIシステムをグローバルに迅速に停止させる手段を提供する。不正なAIが出現した場合、問題が深刻化する中で封じ込め戦略を練って奔走するよりも、即座にプラグを抜く能力を持つことが重要だ。オフスイッチを成功させるためには、AIの開発と運用において、透明性と監視を強化する必要がある。
クラウド・コンピューティング・プロバイダーの法的責任
クラウド・コンピューティング・プロバイダーは、自社のプラットフォームが不正なAIの生存や拡散を助長しないような措置を講じるべきである。法的責任を課せば、クラウド・コンピューティング・プロバイダーは、自社のハードウェア上で動作するエージェントが安全であることを保証する気になるだろう。もしプロバイダーが自分のサーバー上で安全でないエージェントを見つけた場合、不正エージェントが使用するシステムの一部のスイッチを切ることができる。不正なAIがAIコンピュートモニターを簡単に操作したり迂回したりできる場合、この介入の効果は限定的であることに注意したい。この責任の枠組みを強化するために、サイバー攻撃に関する国際協定を模倣し、本質的に分散化されたオフスイッチを作ることができる。これにより、不正なAIが蔓延し始めた場合、迅速な介入が可能になる。
AIの安全性研究を支援する
AI制御の改善に向けた多くの道は、技術研究を必要とする。以下の技術的な機械学習の研究分野は、AI制御の問題に取り組むことを目的としている。各研究分野は、産業界、民間財団、政府からの重点的な支援と資金提供の増加により、大幅に進歩する可能性がある。
- 代理モデルの逆境ロバスト性:AIシステムは通常、報酬や損失のシグナルを用いて訓練されるが、そのシグナルは望ましい行動を不完全に特定する。例えば、AIは訓練に使用される監視スキームの弱点を突くかもしれない。監視を行うシステムがAIそのものであることも増えている。AIモデルが監視を提供するAIの欠陥を悪用する可能性を減らすために、監視を提供するAIモデル(「代理モデル」)の敵対的な堅牢性を高める研究が必要である。監視スキームや監視指標は最終的にゲーム化される可能性があるため、リスクが軽減されるように、それがいつ起こるかを検知できるようにすることも重要である[131]。
- モデルの正直さ:AIシステムは、その内部状態を正確に報告できない可能性がある[132, 133]。将来、システムは、実際には非常に危険であるにもかかわらず、有益に見えるように操作者を欺くかもしれない。モデルの正直さの研究は、モデルの出力を、モデル内部の「信念」にできるだけ忠実に適合させることを目的としている。研究によって、モデルの内部状態を理解したり、モデルの出力をより正直で内部状態に忠実なものにしたりする技術を特定することができる[134]。
- 透明性と表現工学:ディープラーニング・モデルは理解しにくいことで有名である。ディープラーニング・モデルの内部構造をより良く可視化することで、人間や、潜在的には他のAIシステムも、問題をより迅速に特定することができるようになる。研究には、小さなコンポーネントの分析[135, 136]もあれば、ネットワークのハイレベルな内部表現[134]の理解を試みることもある。
- 隠れたモデル機能の検出と除去:ディープ・ラーニング・モデルは、現在あるいは将来において、欺瞞能力、トロイの木馬[137, 138, 139]、生物工学的能力など、モデルから除去すべき危険な機能を含んでいる可能性がある。このような機能を特定し、除去する[140]ことに重点を置いて研究することも可能であろう。
前向きなビジョン
理想的なシナリオでは、現在も将来もAIシステムの制御可能性に全幅の信頼を寄せることができるだろう。AIシステムが欺瞞的な行動をとらないことを保証する信頼できるメカニズムが整備されているだろう。システムの傾向や目標を知るのに十分な、AIシステム内部の強力な理解があるだろう。これらのツールにより、道徳的配慮や権利に値するシステムを構築することを避けることができるだろう。AIシステムは、多様な価値観の多元的な集合を促進するよう指示され、特定の価値観の強化が他の価値観の完全な無視につながらないようにする。AIアシスタントはアドバイザーとして機能し、私たちに理想的な助言を与え、私たち自身の価値観に従ってより良い決断を下す手助けをしてくれるだろう。一般的に、AIは社会福祉を向上させ、誤りがあった場合や人間の価値観が自然に進化した場合の修正を可能にするだろう。
6 リスク間の関連性の考察
ここまでは、AIのリスクの4つの原因を個別に考察してきたが、これらは複雑な形で相互に影響し合っている。リスクがどのように関連しているかを説明するために、いくつかの例を挙げる。
例えば、企業のAI競争によって、企業がAIの迅速な開発を優先せざるを得なくなったとする。これは様々な形で組織のリスクを高める可能性がある。例えば、ある企業が情報セキュリティにかける費用を削減し、AIシステムの1つが流出する可能性がある。そうなれば、悪意のある誰かがAIシステムを持ち、それを使って有害な目的を追求する可能性が高まる。このように、AI競争は組織のリスクを増大させ、悪意のある利用をより可能性の高いものにする可能性がある。
別のシナリオとしては、激しいAI競争と組織の安全性の低さの組み合わせにより、研究チームが一般的な能力の進歩を「安全」と誤って捉えてしまうことが想定される。そうなると、ますます能力の高いモデルの開発が急がれ、それらを制御可能にする方法を学ぶ時間が短縮される可能性がある。開発の加速はまた、競争圧力にフィードバックされる可能性が高く、モデルが制御可能であることを保証するために費やされる労力が減ることを意味する。その結果、制御不能に陥った非常に強力なAIシステムがリリースされ、大惨事につながる可能性がある。ここで、競争圧力と低い組織安全性は、AI競争の力学を強化し、技術的安全性研究を弱体化させ、制御不能の可能性を高める可能性がある。
軍事環境における競争圧力は、AIの軍拡競争につながり、AI兵器の効力と自律性を高める可能性がある。AIを搭載した兵器の配備は、その制御が不十分であることと相まって、制御の喪失をより致命的なものとし、存亡の危機を招く可能性がある。これらは、これらのリスク源がどのように組み合わされ、引き金となり、互いに強化されうるかのほんの一例にすぎない。
また、多くの人類存亡リスクは、AIが既存の懸念を増幅させることによって生じる可能性があることも注目に値する。権力の不平等はすでに存在しているが、AIはそれを固定化し、権力者と非権力者の間の溝を広げ、揺るぎないグローバルな全体主義体制を可能にする可能性さえある。同様に、AIの操作は民主主義を弱体化させる可能性があり、これもまた不可逆的な全体主義体制の人類存亡リスクを増大させる。偽情報はすでに蔓延している問題だが、AIはそれを制御できないほど悪化させ、現実に関するコンセンサスを失うところまで悪化させる可能性がある。AIは、より致死性の高い生物兵器を開発し、それを入手するために必要な技術的専門知識を減らし、既存のバイオテロのリスクを大幅に増大させる可能性がある。AIが可能にするサイバー攻撃は戦争の可能性を高め、人類存亡リスクを増大させるだろう。経済の自動化が劇的に加速すれば、人間の支配力が低下し、衰弱する可能性があり、これは人類存亡リスクである。これらの問題(権力集中、偽情報、サイバー攻撃、自動化)はそれぞれ、継続的な危害を引き起こしており、AIによってそれらが悪化すれば、最終的には人類が立ち直れないような大惨事につながる可能性がある。
このように、現在進行中の危害、壊滅的リスク、そして人類存亡リスクは深く絡み合っている。歴史的に、人類存亡リスクの軽減は技術的なAI制御研究のような対象を絞った介入に焦点を当ててきたが、本稿で概説した多くの社会技術的介入のような広範な介入 [142]を行うべき時が来ている。人類存亡リスクを軽減する上で、他のリスクを無視することは現実的に意味をなさない。現在進行中の危害や破局的リスクを無視することは、それらを常態化させ、私たちを「危険の中に漂流」させる可能性がある[143]。
全体として、人類存亡リスクは、それほど極端ではない壊滅的リスクやその他の標準的なリスク源と関連しており、社会はAIによる様々なリスクに対処する意思を強めているため、私たちは人類存亡リスクを直接対象とすることだけに焦点を当てるべきでないと考える。その代わりに、他のリスクによる拡散的で間接的な影響を考慮し、リスク管理により包括的なアプローチをとるべきである。
7 まとめ
本稿では、高度なAIの開発が、悪意のある利用、AIレース、組織リスク、不正なAIという4つの主要なリスク源に起因する大惨事にどのようにつながる可能性があるのかを探ってきた。これにより、AIのリスクを4つの近因、すなわち、それぞれ意図的な原因、環境・構造的な原因、偶発的な原因、内部的な原因に分解することができる。私たちは、テロリストがAIを使って致命的な病原体を作り出すなど、AIが悪意を持って使用される可能性を検討してきた。私たちは、軍事的あるいは企業的なAI競争が私たちをどのように急き立て、AIに意思決定権を与え、人間の無力化へと私たちを滑りやすい坂道へと導くかを見てきた。また、組織の安全性が不十分であれば、大惨事につながる可能性があることを論じてきた。最後に、プロキシゲーミングやゴールドリフトなど、人間の幸福を顧みずに望ましくない行動を追求する不正なAIを生み出す可能性のあるメカニズムを含め、高度なAIを確実に制御する上での課題を取り上げた。これらの危険性は深刻な懸念に値する。現在、AIのリスク軽減に取り組んでいる人はほとんどいない。
高度に発達したAIシステムを制御する方法はまだわかっておらず、既存の制御方法ではすでに不十分であることがわかっている。AIの内部構造は、AIを開発する人々でさえよく理解しておらず、現在のAIは決して信頼性の高いものではない。AIの能力は前例のないスピードで成長を続けており、ほぼすべての点で人間の知能を上回る可能性が比較的近いうちにあり、潜在的なリスクを管理することが急務となっている。
朗報は、こうしたリスクを大幅に軽減するために私たちが取ることのできる行動指針が数多くあるということだ。悪意のある利用の可能性は、慎重に対象を絞った監視や、最も危険なAIへのアクセス制限など、様々な手段によって軽減することができる。安全規制や国家・企業間の協力は、私たちを危険な道へと駆り立てる競争圧力に対抗するのに役立つだろう。事故の確率は、とりわけ厳格な安全文化によって、また安全性の進歩が一般的な能力の進歩を上回るようにすることで、減らすことができる。最後に、私たち自身の知能を凌駕するテクノロジーを構築することに内在するリスクは、AI制御研究のいくつかの分野での取り組みを倍加することで対処できる。
能力が成長し続け、社会的・システム的状況が進化し続けるにつれて、リスクが破滅的または存続的なレベルに達する時期の予測は様々になる。しかし、これらのタイムラインに関する不確実性は、危機に瀕する可能性の大きさと相まって、人類の未来を守るための積極的なアプローチに説得力を与えている。この作業を直ちに開始することで、この技術が世界をより良い方向へ、悪い方向へではなく、確実に変えていくことができる。
謝辞
本稿の草稿作成に協力してくれたLaura Hiscott、Avital Morris、David Lambert、Kyle Gracey、Aidan O’Garaに感謝したい。また、有益なフィードバックをくれたJacqueline Harding、Nate Sharadin、William D’Alessandro、Cameron Domenico Kirk-Gianini、Simon Goldstein、Alex Tamkin、Adam Khoja、Oliver Zhang、Jack Cunningham、Lennart Justen、Davy Deng、Ben Snyder、Willy Chertman、Justis Mills、Adam Jones、Hadrien Pouget、Nathan Calvin、Eric Gan、Nikola Jurkovic、Lukas Finnveden、Ryan Greenblatt、Andrew Dorisに感謝したい。
参考文献
- [1] David Malin Roodman. 世界経済の成長率の長期的変化の確率分布について: 外部からの見解。2020.
- [2] トム・デビッドソン. 先進AIは爆発的な経済成長をもたらすか?2021年6月
- [3] カール・セーガン. Pale Blue Dot: A Vision of the Human Future in Space. ニューヨーク: Random House, 1994.
- [4] ロマン・V・ヤンポルスキー. 「危険な人工知能への道筋の分類法」. In: AAAIワークショップ: AI, Ethics, and Society. 2016.
- [5] キース・オルソン. 「オウム真理教:かつてと未来の脅威?」 In: Emerging Infectious Diseases 5 (1999), pp.
- [6] ケビン・M・エスヴェルト. Delay, Detect, Defend: Preparing for a Future in which Thousands Can Release New Pandemics. 2022.
- [7] Siro Igino Trevisanato. 「ヒッタイトの疫病」、野兎病の流行と生物学的戦争の最初の記録」. In: Medical hypotheses 69 6 (2007), pp.1371-4.
- [8] 米国国務省。軍備管理、核不拡散、軍縮に関する協定と約束の順守と遵守。政府報告書。米国国務省、2022年4月。
- [9] ロバート・カールソン. 「DNA合成の経済学の変化」. In: Nature Biotechnology 27.12 (Dec. 2009). Number: 12 Publisher: Nature Publishing Group, pp.
- [10] Sarah R. Carter, Jaime M. Yassif, and Chris Isaac. ベンチトップDNA合成装置: 能力、バイオセキュリティへの影響、およびガバナンス。報告書。Nuclear Threat Initiative, 2023.
- [11] Fabio L. Urbina et al. ”Dual use of artificial-intelligence-powered drug discovery”. In: Nature Machine Intelligence (2022).
- [12] John Jumper et al. ”Highly accurate protein structure prediction with AlphaFold”. In: Nature 596.7873 (2021), pp.
- [13] Zachary Wu et al. ”Machine learning-assisted directed protein evolution with combinatorial libraries”. In:
- Proceedings of the National Academy of Sciences 116.18 (2019), pp.8852-8858.
- [14] Emily Soice et al. ”Can large language models democratize access to dual-use biotechnology?”. In: 2023.
- [15] マックス・テグマーク. ライフ3.0: 人工知能時代に人間であること. Vintage, 2018.
- [16] リアン・プーリー. We Need To Talk About A.I. 2020.
- それは史上最大の知的業績になるだろう。科学、工学、人文科学の成果であり、その意義は人類を超え、人生を超え、善悪を超えるものだ。ツイートする2022年9月
- [18] リチャード・サットン. AIの継承. ビデオ。2023年9月。
- [19] A. Sanz-García et al. ”Prevalence of Psychopathy in the General Adult Population: A Systematic Review and Meta-Analysis”. In: Frontiers in Psychology 12 (2021).
- [20] U.S. Department of State Office of The Historian. 「U.S. Diplomacy and Yellow Journalism, 1895-1898”. In: ().
- [21] Onur Varol et al. ”Online Human-Bot Interactions: Detection, Estimation, and Characterization”. In: ArXiv abs/1703.03107 (2017).
- [22] Matthew Burtell and Thomas Woodside. ”Artificial Influence: A. alysis Of AI-Driven Persuasion”. In: ArXiv abs/2303.08721 (2023).
- [23] Anna Tong. 「AIチャットボットがあなたを愛し返さなくなったらどうなるだろうか?」 In: ロイター (2023年3月).
- [24] Pierre-François Lovens. ”Sans ces conversations avec le chatbot Eliza, mon mari serait toujours là”. In: La Libre (Mar. 2023).
- [25] Cristian Vaccari and Andrew Chadwick. 「ディープフェイクと偽情報: ニュースにおける欺瞞、不確実性、信頼に対する合成政治ビデオの影響を探る」In: Social Media + Society 6 (2020).
- [26] Moin Nadeem, Anna Bethke, and Siva Reddy. 「StereoSet: 「StereoSet:」事前訓練された言語モデルにおけるステレオタイプ・バイアスの測定”. In: この論文では、自然言語処理におけるステレオタイプ・バイアスを測定するために、事前に訓練された言語モデルにおけるステレオタイプ・バイアスを測定する。オンライン: 計算言語学会、2021年8月、pp.5356-5371.
- [27] Evan G. Williams. 「進行中の道徳的破局の可能性」. In: 倫理理論と道徳実践
- 18.5 (Nov. 2015), pp. 971-982.
- [28] The Nucleic Acid Observatory Consortium. ”A Global Nucleic Acid Observatory for Biodefense and Planetary Health”. In: ArXiv abs/2108.02678 (2021).
- [29] Toby Shevlane. 「AI能力への構造化されたアクセス:安全なAI展開のための新たなパラダイム」. In: ArXiv abs/2201.05159 (2022).
- [30] Jonas Schuett et al. Towards best practices in AGI safety and governance: A survey of expert opinion. 2023. arXiv:
- 2305.07153.
- [31] Yonadav Shavit. 「チンチラを捕まえるには何が必要か?コンピューティング・モニタリングによる大規模ニューラルネットワーク学習におけるルールの検証」. In: ArXiv abs/2303.11341 (2023).
- [32] Anat Lior. 「AIエージェントとしてのAIエンティティ: A. entとしてのAI Entities: Artificial Intelligence Liability and the AI Respondeat Superior Analogy”. In: Torts & Products Liability Law eJournal (2019).
- [33] Maximilian Gahntz and Claire Pershan. 人工知能法: EUは汎用AIシステムがもたらす課題にどう挑むことができるか。2022年11月。
- [34] ポール・シャーレ. Army of None: 自律型兵器と戦争の未来. Norton, 2018.
- [35] DARPA. ”AlphaDogfight Trials Foreshadow Future of Human-Machine Symbiosis”. In: (2020).
- [36] リビア専門家パネル. 決議1973(2011)に従って設置されたリビアに関する専門家パネルから安保理議長宛の2021年3月8日付書簡。国連安全保障理事会文書S/2021/229。国連、2021年3月。
- [37] デイヴィッド・ハンブリングイスラエルはガザ攻撃で世界初のAI誘導戦闘ドローン群を使用した。2021.
- [38] ザッカリー・カレンボーン. 軍備管理の枠組みを自律型兵器に適用する。2021年10月。
- [39] J.E.ミューラー. 戦争、大統領、世論。UPAブック。University Press of America, 1985.
- [40] Matteo E. Bonfanti. 「人工知能とサイバーセキュリティにおける攻守のバランス」. In: Cyber Security Politics: Socio-Technological Transformations and Political Fragmentation. M.D.カヴェルティ、A.ウェンガー編。CSS Studies in Security and International Relations. Taylor & Francis, 2022. 第5章、64-79頁。
- [41] Yisroel Mirsky et al. 「The Threat of Offensive AI to Organizations」. In: Computers & Security (2023).
- [42] キム・ゼッター. ”Meet MonsterMind, the NSA Bot That Could Wage Cyberwar Autonomously”. In: Wired (Aug. 2014).
- [43] Andrei Kirilenko et al. ”The Flash Crash: 電子市場における高頻度取引」. In: The Journal of Finance 72.3 (2017), pp.967-998.
- [44] Michael C Horowitz. 軍事力の拡散: The Diffusion of Military Power: Causes and Consequences for International Politics. Princeton University Press, 2010.
- [45] ロバート・E・ジャーヴィス. 「安全保障のジレンマの下での協力」. In: World Politics 30 (1978), pp.167-214.
- [46] リチャード・ダンツィグ. 技術ルーレット: 多くの軍隊が技術的優越性を追求する中で、統制の喪失を管理する。Tech. rep. Center for a New American Security, June 2018.
- [47] ビリー・ペリゴ. BingのAIがユーザーを脅かしている。That’s No Laughing Matter. 2023年2月。
- [48] Nico Grant and Karen Weise. ”In A.I. Race, Microsoft and Google Choose Speed Over Caution”. In: The New York Times (Apr. 2023).
- [49] Thomas H. Klier. 「From Tail Fins to Hybrids: How Detroit Lost Its Dominance of the U.S. Auto Market”. In:
- RePEc (May 2009).
- [50] ロバート・シェレフキン. ”Ford 100: Defective Pinto Almost Took Ford’s Reputation With It”. In: Automotive News (June 2003).
- [51] リー・ストロボ. Reckless Homicide? Ford’s Pinto Trial. And Books, 1980.
- [52] Grimshaw v. Ford Motor Co. 1981年5月。
- [53] ポール・C・ジャッジ. 「Selling Autos by Selling Safety」. In: The New York Times (Jan. 1990).
- [54] テオ・レゲット. 「737マックスが墜落した: Boeing says not guilty to fraud charge”. In: BBC News (Jan. 2023).
- [55] エドワード・ブロートン. 「ボパール事故とその余波:レビュー」. In: Environmental Health 4.1 (May 2005), p. 6.
- [56] シャーロット・カーティス. 「機械対労働者」. In: ニューヨーク・タイムズ紙(1983年2月)。
- [57]トーマス・ウッドサイド他、「AIがAIを改善する例」In: (2023). URL: https:// aiimprovingai.safe.ai.
- [58] スチュアート・ラッセル. Human Compatible: Artificial Intelligence and the Problem of Control. Penguin, Oct. 2019.
- [59] Dan Hendrycks. 「Natural Selection Favors AI over Humans」. In: ArXiv abs/2303.16200 (2023).
- [60] Dan Hendrycks. The Darwinian Argument for Worry About AI. 2023年5月。
- [61] リチャード・C・ルウォンティン. 「淘汰の単位」. In: Annual Review of Ecology, Evolution, and Systematics 1 (1970), pp.
- [62] イーサン・クロス(Ethan Kross)ら、”Facebook use predicts declines in subjective well-being in young adults”. In: PloS-1 (2013).
- [63] Laura Martínez-Íñigo et al. ”Intercommunity interactions and killings in central chimpanzees (Pan troglodytes troglodytes) from Loango National Park, Gabon”. In: Primates; Journal of Primatology 62 (2021), pp.709-722.
- [64] Anne E Pusey and Craig Packer. ”Infanticide in Lions: 結果および対抗戦略」In: Infanticide and parental care (1994), p. 277.
- [65] Peter D. Nagy and Judit Pogany. 「ウイルスRNA複製の共役宿主因子への依存性」. In: Nature Reviews. Microbiology 10 (2011), pp.137-149.
- [66] Alfred Buschinger. 「アリの社会的寄生: A Review”. In: Myrmecological News 12 (Sept. 2009), pp.
- [67] Greg Brockman, Ilya Sutskever, and OpenAI. OpenAIの紹介。2015年12月。
- [68] Devin Coldewey. OpenAIは資本を集めるために非営利から「上限付き利益」にシフトする。2019年3月。
- [69] Kyle Wiggers, Devin Coldewey, and Manish Singh. AnthropicがOpenAIに挑むための50億ドル、4年計画。2023年4月。
- [70] Center for AI Safety. AIリスクに関する声明(「AIによる絶滅リスクを軽減することは、パンデミックや核戦争といった他の社会規模のリスクと並ぶ世界的な優先事項であるべきだ」)。2023. URL: www.safe. ai/statement-on-ai-risk.
- [71] Richard Danzig et al: テロリストがどのように生物化学兵器を開発するかについての洞察。Tech. rep. Center for a New American Security, 2012. URL: https : URL: https : / / www . jstor . org / stable / resrep06323.
- [72] Timnit Gebru et al. 「Datasheets for datasets」. en. en: このようなデータセットは、データシートと呼ばれる。
- [73] Christian Szegedy et al. 「Intriguing properties of neural networks」. In: CoRR (Dec. 2013).
- [74] Dan Hendrycks et al. 「Unsolved Problems in ML Safety」. In: arXiv preprint arXiv:2109.13916 (2021).
- [75] John Uri. 35年前: チャレンジャーと乗組員を偲ぶ. テキスト。2021年1月。
- [76] 国際原子力機関. チェルノブイリ事故: INSAG-1の更新。技術報告書INSAG-7。ウィーン、オーストリア: International Atomic Energy Agency, 1992.
- [77] Matthew Meselson et al. 「The Sverdlovsk anthrax outbreak of 1979」. In: Science 266 5188 (1994), pp.
- [このような場合、「言語モデル」 は、「人間の嗜好から言語モデルを微調整する」ことになる。In: arXiv preprint arXiv:1909.08593
- (2019).
- [79] Charles Perrow. Normal Accidents: ハイリスク技術とともに生きる。Princeton, NJ: Princeton University Press, 1984.
- [80] Mitchell Rogovin and George T. Frampton Jr. Three Mile Island: a report to the commissioners and to the public. 第1巻。技術報告書。NUREG/CR-1250(Vol.1). 原子力規制委員会、ワシントンDC(米国)。Three Mile Island Special Inquiry Group, Jan. 1979.
- [81] リチャード・ローズ. 原爆の製造. ニューヨーク: Simon & Schuster, 1986.
- [82] Sébastien Bubeck et al. ”Sparks of Artificial General Intelligence: GPT-4の初期実験”. In: ArXiv abs/2303.12712 (2023).
- [83] Theodore I. Lidsky and Jay S. Schneider. 「小児における鉛の神経毒性:基本的メカニズムと臨床的相関」. In: Brain : a journal of neurology 126 Pt 1 (2003), pp.
- [84] ブルック・T・モスマン(Brooke T. Mossman)他:「アスベスト:科学的発展と公共政策への影響」. In: Science 247 4940 (1990), pp.294-301.
- [85] ケイト・ムーア. ラジウム・ガールズ: The Dark Story of America’s Shining Women. Naperville, IL: Sourcebooks, 2017.
- [86] スティーブン・S・ヘクト. 「タバコの煙の発がん物質と肺がん」. In: Journal of the National Cancer Institute 91 14 (1999), pp.1194-210.
- [87] Mario J. Molina and F. Sherwood Rowland. 「クロロフルオロメタンの成層圏吸収源:塩素原子触媒によるオゾン破壊」In: Nature 249 (1974), pp.
- [88] James H. Kim and Anthony R. Scialli. 「サリドマイド:先天性異常の悲劇と病気の効果的治療」. In: Toxicological sciences : an official journal of the Society of Toxicology 122 1 (2011), pp.
- [89] Betul Keles, Niall McCrae, and Annmarie Grealish. 「システマティック・レビュー:青年期のうつ病、不安、心理的苦痛に対するソーシャルメディアの影響」. In: International Journal of Adolescence and Youth 25 (2019), pp.79-93.
- [90] Zakir Durumeric et al. 「The Matter of Heartbleed」. In: Proceedings of the 2014 Conference on Internet Measurement Conference (2014).
- [91] Tony Tong Wang et al. ”Adversarial Policies Beat Professional-Level Go AIs”. In: ArXiv abs/2211.00241 (2022).
- [92] T. R. Laporte and Paula M. Consolini. ”Working in Practice But Not in Theory: 高信頼性組織」の理論的課題”. In: Journal of Public Administration Research and Theory 1 (1991), pp.19-48.
- [93] Thomas G. Dietterich. 「ロバストな人工知能とロバストな人間組織」. In: Frontiers of Computer Science 13 (2018), pp.
- [94] ナンシー・G・リーヴソン. Engineering a safer world: Systems thinking applied to safety. The MIT Press, 2016.
- [95] デイビッド・マンハイム. AIのための安全文化の構築:展望と課題. 2023.
- [96] National Research Council et al. Lessons Learned from the Fukushima Nuclear Accident for Improving Safety of U.S. Nuclear Plants. Washington, D.C.: National Academies Press, Oct. 2014.
- [97] Diane Vaughan. The Challenger Launch Decision: The Challenger Launch Decision: Risky Technology, Culture, and Deviance at NASA. Chicago, IL: University of Chicago Press, 1996.
- [98] Dan Lamothe. 空軍は誓う: Our Nuke Launch Code Was Never ‘00000000’. 2014年1月。
- [99] トビー・オード. The precipice: Existential risk and the future of humanity. アシェット・ブックス、2020年。
- [100] 米国原子力規制委員会. 最終安全文化方針声明. 連邦官報。2011.
- [101] ブルース・シュナイアー. 「セキュリティ専門家のねじれた心の中」In: Wired (Mar. 2008).
- [102] Dan Hendrycks and Mantas Mazeika. 「AI研究のためのXリスク分析」In: ArXiv abs/2206.05862 (2022).
- [103] CSRC Content Editor. レッドチーム – 用語集. EN-US.
- [104] Amba Kak and Sarah West. テック・パワーに立ち向かう。2023.
- [105] ナシーム・ニコラス・タレブ. 「第4象限: 統計の限界の地図」. In: Edge, 2008.
- [106] Irene Solaiman et al. ”Release strategies and the social impacts of language models”. In: arXiv preprint arXiv:1908.09203 (2019).
- [107] Neal Woollen. インシデントレスポンス(なぜ計画が重要なのか)。
- [108] Huashan Li et al. ”The impact of chief risk officer appointments on firm risk and operational efficiency”. In:
- Journal of Operations Management (2022).
- [109]内部監査の役割。URL: www.marquette.edu/riskunit/internalaudit/role. shtml.
- [110] Heather Adkins et al. Building Secure and Reliable Systems: システムを設計、実装、維持するためのベストプラクティス。O’Reilly Media, 2020.
- [111] Center for Security and Emerging Technology. AI Safety – Emerging Technology Observatory Research Almanac. 2023.
- [112] ドナルド・T・キャンベル. 「計画された社会変化の影響を評価する」In: Evaluation and program planning 2.1 (1979), pp.67-90.
- [113] Yohan J. John et al. ”Dead rats, dopamine, performance metrics, and peacock tails: proxy failure is an inherent risk in goal-oriented systems”. In: Behavioral and Brain Sciences (2023), pp. doi: 10.1017/ s0140525x23002753.
- [114] Jonathan Stray. 「AI Optimization to Community Well-Being”. In: International Journal of Community Well-Being (2020).
- [115] Jonathan Stray et al. ”What are you optimizing for? Aligning Recommender Systems with Human Values”. In:
- ArXiv abs/2107.10939 (2021).
- [116] Ziad Obermeyer et al. ”Dissecting racial bias in an algorithm used to manage the health of populations”. In:
- Science 366 (2019), pp.447-453.
- [117] Dario Amodei and Jack Clark. 野生における報酬機能の欠陥。2016.
- [118] Alexander Pan, Kush Bhatia, and Jacob Steinhardt. 「The effects of reward misspecification: 報酬の誤指定の影響:誤ったモデルのマッピングと軽減」In: ICLR (2022).
- [119] G. Thut et al. 「Activation of the human brain by monetary reward」. In: Neuroreport 8.5 (1997), pp.1225-1228.
- [120] エドマンド・T・ロールズ. 「眼窩前頭皮質と報酬」. In: 大脳皮質 10.3 (2000年3月), pp.284-294.
- [121] T. シュローダー. 欲望の三つの顔. 心の哲学シリーズ. Oxford University Press, USA, 2004.
- [122] ジョセフ・カールスミス. 「パワーを求めるAIからの人類存亡リスク」. In: Oxford University Press (2023).
- [123] ジョン・ミアシャイマー. 「構造的リアリズム」. In: Oxford University Press, 2007.
- [124] Bowen Baker et al. 「Emergent Tool Use From Multi-Agent Autocurricula」. In: International Conference on Learning Representations. 2020.
- [125] Dylan Hadfield-Menell et al. 「The Off-Switch Game」. In: ArXiv abs/1611.08219 (2016).
- [126] Alexander Pan et al. 「Do the Rewards Justify the Means?」 Measuring Trade-Offs Between Rewards and Ethical Behavior in the Machiavelli Benchmark. In: ICML (2023).
- [127] 「Lyndon Baines Johnson」. In: Oxford Reference (2016).
- [128] Anton Bakhtin et al. ”Human-level play in the game of Diplomacy by combining language models with strategic reasoning”. In: Science 378 (2022), pp.1067-1074.
- [129] Paul Christiano et al. 人間の嗜好からの深い強化学習。Discussed in https:// www. deepmind.com/blog/specificationgamingtheflipsideofaiingenuity. 2017. arXiv: 1706.03741.
- [130] Xinyun Chen et al. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. 2017. arXiv:
- 1712.05526.
- [131] Andy Zou et al. Benchmarking Neural Network Proxy Robustness to Optimization Pressure. 2023.
- [132] Miles Turpin et al. ”Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting”. In: ArXiv abs/2305.04388 (2023).
- [133] Collin Burns et al. ”Discovering Latent Knowledge in Language Models Without Supervision”. In: The Eleventh International Conference on Learning Representations. 2023年2月。
- [134] Andy Zou et al: ニューラルネットの内部構造を理解し制御する。2023.
- [135]キャサリン・オルソン(Catherine Olsson)他:「In-context Learning and Induction Heads」. In: ArXiv abs/2209.11895 (2022).
- [136] Kevin Ro Wang et al. ”Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small”. In: (訳注:この論文では、「学習表現に関する第11回国際会議」). 2023年2月。
- [137] Xinyang Zhang, Zheng Zhang, and Ting Wang. 「楽しさと利益のためのトロイの木馬言語モデル」. このような場合、「セキュリティとプライバシ ーに関する欧州シンポジウム(EuroS&P)」(2021 IEE. ropean Symposium on Security and Privacy (EuroS&P) (2020), pp.179-197.
- [138] Jiashu Xu et al. ”Instructions as Backdoors: 大規模言語モデルのための命令チューニングのバックドア脆弱性”. In: ArXiv abs/2305.14710 (2023).
- [139] Dan Hendrycks et al. 「Unsolved Problems in ML Safety」. In: ArXiv abs/2109.13916 (2021).
- [140] Nora Belrose et al. ”LEACE: Perfect linear concept erasure in closed form”. In: ArXiv abs/2306.03819 (2023).
- [141] Alberto Giubilini and Julian Savulescu. 「人工道徳顧問。The 「Ideal Observer」 Meets Artificial Intelligence”. In: Philosophy & Technology 31.2 (2018), pp.169-188.
- [142] ニック・ベックステッド遠い未来を形作ることの圧倒的な重要性について。2013.
- [143] イェンス・ラスムッセン. 「ダイナミックな社会におけるリスク管理: A Modeling Problem”. 英語。In: Proceedings of the Conference on Human Interaction with Complex Systems, 1996.
- [144] ジェニファー・ロバートソン. 「人権 vs. ロボットの権利:日本からの予測”. In: Critical Asian Studies 46.4 (2014), pp.
- [145] ジョン・ロールズ. 政治的自由主義. コロンビア大学出版局、1993年。
- [146] Toby Newberry and Toby Ord. 「The Parliamentary Approach to Moral Uncertainty”. In: 2021.
- [147] F.R. Frola and C.O. Miller. 航空機取得におけるシステム安全性。Tech. rep. 1984年1月。
よくある質問
AIの破局的リスクは、大衆文化の中で広範な憶測の対象となってきたとはいえ、新しい課題であるため、それが顕在化するかどうか、またどのように顕在化するかについては多くの疑問がある。世間の関心は最も劇的なリスクに集中するかもしれないが、本文書で論じるようなありふれたリスク源も同様に深刻である可能性がある。さらに、こうしたリスクに対処するための最も単純なアイデアの多くは、よくよく調べてみると不十分であることが判明する。ここでは、AIの壊滅的リスクに関する最も一般的な疑問や誤解をいくつか取り上げる。
1. 将来、AIが人間にできることをすべてできるようになったとき、私たちはAIリスクに対処すべきではないのか?
人間レベルのAIが遠い未来に存在するとは限らない。多くのトップAI研究者は、人間レベルのAIはかなり近いうちに開発されると考えている。さらに、AIリスクへの対応を始めるのをギリギリまで待つのは、手遅れになるまで待つことになる。行動を起こす前にCOVID-19を完全に理解するのを待ったのが間違いであったように、AIのリスクを真剣に考える前に、安全性を先延ばしにして悪意のあるAIや悪質な行為者が危害を加えるのを待つのは得策ではない。
AIはまだ自動車を運転することも、服をたたむこともできないのだから、心配する必要はないと主張する人もいるかもしれない。しかし、AIは深刻な脅威をもたらすために人間のすべての能力を必要とするわけではない。大惨事を引き起こすために必要なのは、いくつかの特定の能力だけだ。例えば、コンピューターシステムをハッキングしたり、生物兵器を作ったりする能力を持ったAIは、たとえシャツにアイロンをかけることができなくても、人類に重大なリスクをもたらすだろう。さらに、AIの能力開発は、人間にとって簡単なタスクが最初にAIによってマスターされるという直感的なパターンを辿っていない。現在のAIは、単純な物理的作業に苦戦しながらも、コードの記述や新薬の設計といった複雑な作業をすでにこなしている。気候変動やCOVID-19のように、AIのリスクは、結果が現れるのを待つのではなく、予防と備えを重視し、予防的に対処すべきである。
2. 人間がAIをプログラムしているのだから、AIが危険な状態になった場合、それを停止させることはできないのか?
人間がAIの創造主であるとはいえ、AIが進化し自律的になるにつれ、その創造物をコントロールし続けることは保証されていない。AIが脅威となった場合、単純に「停止」させることができるという考え方は、見た目以上に複雑である。
まず、AIの大惨事がどのようなスピードで起こるかを考えてみよう。ガス漏れを検知してロケットの爆発を防いだり、すでに集団に蔓延しているウイルスの拡散を食い止めたりするのと同じように、危険を認識してからそれを防いだり軽減したりできるまでの時間は、不安定なほど短くなる可能性がある。
第二に、進化的な力と淘汰圧によって、利己的な行動をとるAIが生み出され、より適合性が高まり、情報の伝播を止めることが難しくなる可能性がある。このようなAIが進化を続け、より有用になるにつれて、私たちの社会インフラや日常生活の中心的存在になるかもしれない。エネルギー・グリッドを運営するような重要なタスクを管理したり、膨大な暗黙知を持ち、代替が難しい存在になるかもしれない。こうしたAIへの依存度が高まるにつれて、私たちは自主的にコントロールを放棄し、より多くのタスクをAIに委ねるようになるかもしれない。最終的には、私たち自身がこれらのタスクを実行するために必要なスキルや知識が不足していることに気づくかもしれない。このように依存度が高まることで、単に「彼らをシャットダウンする」という考えは、混乱を招くだけでなく、不可能になる可能性もある。
同様に、すべての違法なウェブサイトを永久に閉鎖したり、ビットコインを閉鎖したりすることができないのと同じように、AIを閉鎖しようとする試みに強く抵抗したり、対抗したりする人々もいるだろう。AIが私たちの生活や経済にとってより不可欠になるにつれ、AIを制限したり停止させようとする試みに積極的に抵抗する熱心なユーザー層、あるいはファン層が形成される可能性さえある。同様に、悪意のある行為者から生じる複雑さも考えてみよう。悪意のある行為者がAIをコントロールできるようになれば、AIを使って危害を加える可能性がある。良心的な管理下にあるAIとは異なり、このようなシステムにはオフスイッチがない。
次に、一部のAIがより人間に近くなるにつれ、これらのAIは権利を持つべきだと主張する人が出てくるかもしれない。彼らに権利を与えないことは、一種の奴隷制度であり、道徳的に忌むべきことだと主張することもできる。一部の国や地域は、特定のAIに権利を与えるかもしれない。実際、すでにAIに権利を与えようという機運が高まっている。ロボットのソフィアはすでにサウジアラビアで市民権を得ており、日本ではパロというロボットに「ロボットが日本市民であることを確認する」戸籍が与えられた[144]。
AIのスイッチを切ることが殺人に例えられる時代が来るかもしれない。そうなれば、単純な「オフスイッチ」という概念に、政治的な複雑さが加わることになる。
また、AIがより大きな力と自律性を獲得するにつれて、「自己保存」への欲求が出芽るかもしれない。そうなれば、シャットダウンの試みに対して抵抗力を持つようになり、私たちのコントロールの試みを予測し、回避することができるようになるかもしれない。
最後に、個々のAIを停止させる方法はあるが、停止させるのがますます難しくなるものもある。全体として、こうした課題を考えると、潜在的なAIのリスクに先手を打って対処し、こうした問題が発生する前に強固なセーフガードを導入することが極めて重要である。
3.なぜAIにアイザック・アシモフの「ロボット工学の三法則」に従えと言えないのか?
アシモフの法則は、AIの議論においてしばしば強調されるが、洞察に富んでいるが本質的には欠陥がある。実際、アシモフ自身も著書の中でその限界を認めており、主に説明の道具として使っている。例えば、第一法則である。この法則は、ロボットが「人間を傷つけたり、不作為によって人間に危害を加えることを許してはならない」と定めているが、「危害」の定義は非常に微妙である。害を及ぼす可能性があるからといって、家庭用ロボットはあなたが家を出て交通機関に入るのを阻止しなければならないのだろうか?
一方、ロボットがあなたを家の中に閉じ込めれば、そこでも危害が及ぶかもしれない。医学的な判断はどうだろう?
ある薬が人によっては有害な副作用を持つかもしれないが、それを投与しないことも同様に有害かもしれない。従って、この法律に従うことはできないだろう。さらに重要なことは、AIシステムの安全性は、単に公理やルールのリストによって保証することはできないということだ。さらに、このアプローチでは、目標ドリフト、代理ゲーム、競争圧力など、数多くの技術的・社会技術的問題に対処できない。したがって、AIの安全性には、単にAIが遵守すべきルールのリストを考案するよりも、より包括的、積極的、かつ微妙なアプローチが必要なのである。
4.もしAIが人間以上の知能を持つようになれば、より賢く、より道徳的になるのではないか? そうなれば、AIは私たちに危害を加えようとはしなくなるだろう。
AIが知能を高めれば高めるほど、本質的に道徳的になるという考え方は興味深いが、私たちの安全を保証できない不確実な前提の上に成り立っている。第一に、道徳的な主張が真であるか偽であるか、そしてその正しさは理性によって発見できるという前提がある。第二に、本当に真実である道徳的主張は、AIが適用すれば人間にとって有益であると仮定している。第三に、道徳について知っているAIは、他の考慮事項に基づいてではなく、道徳に基づいて意思決定を行うことを選択すると仮定している。人間の社会病質者は、知能が高く道徳的な意識を持っているにもかかわらず、必ずしも道徳的な傾向や行動を示さない。この比較は、道徳の知識が必ずしも道徳的行動につながるとは限らないことを示している。したがって、上記の仮説のいくつかは正しいかもしれないが、そのすべてが正しいという主張に人類の未来を賭けるのは賢明ではないだろう。
仮にAIが本当に道徳規範を導き出すことができたとしても、その道徳規範と人間の安全や幸福との適合性は保証されていない。例えば、すべての生命の幸福を最大化することを道徳的規範とするAIは、最初は人間にとって良いものに思えるかもしれない。しかし、最終的には人間はコストがかかると判断し、より効率的にウェルビーイングを経験できるAIに取って代わられるかもしれない。誰も殺さないことを道徳的規範とするAIは、必ずしも人間のウェルビーイングや幸福を優先させるとは限らないため、世界がますますAIによって、あるいはAIのために形作られ始めても、私たちの生活が向上するとは限らない。社会の中で最も恵まれない人々の幸福を向上させることを道徳的規範とするAIでさえ、多くの人間が家畜を見るのと同じように、最終的には人間を社会契約から排除するかもしれない。最後に、たとえAIが人間に有利な道徳規範を発見したとしても、道徳的動機と利己的動機の潜在的な相克のために、AIはそれに基づいて行動しないかもしれない。したがって、AIの道徳的進歩は人間の安全や繁栄と本質的に結びついているわけではない。
5. AIシステムを現在の価値観にアライメントさせることは、既存の道徳的失敗を永続させることにならないか?
今日の社会には、強力なAIシステムが未来に永続することを望まないような道徳的失敗がたくさんある。もし古代ギリシャ人が強力なAIシステムを構築したとしたら、現代人が非倫理的だと感じるような多くの価値観を植え付けたかもしれない。しかし、この懸念は、AIシステムを制御する方法の開発を妨げるものではない。
将来的に何らかの価値を実現するためには、そもそも生命が存在する必要がある。高度なAIの制御を失うことは、実存的な大惨事となりかねない。したがって、どのような倫理観をAIに埋め込むかという不確実性は、AIを安全なものにするかどうかということと矛盾するものではない。
モラルの不確実性に対応するためには、進化するモラル観に適応し、反応するAIシステムを意図的に構築すべきである。私たちが道徳的な間違いを発見し、倫理的理解を深めるにつれて、AIに与える目標もそれに応じて変化していくはずだ。AIはまた、私たちが自分の価値観に従ってよりよく生きる手助けをしてくれるかもしれない。個人の場合、AIは理想的なアドバイスを提供することで、人々がより情報に基づいた選好をするのを助けることができる[141]。
これとは別に、AIシステムを設計する際には、合理的な多元主義という事実を認識すべきである。
したがって、AIシステムは、おそらく民主的なプロセスと道徳的不確実性の理論を用いることによって、多様な人間の価値観の複数性を尊重するように構築されるべきである。今日、人々が意見の相違を審議し、コンセンサスのある決定を下すために招集されるように、AIは異なる利害関係者を代表する議会を模倣し、リアルタイムで決定を下すために異なる道徳的見解を利用することができるかもしれない[59, 146]。
安全性、適応性、異なる価値観を持つ利害関係者を考慮し、AIシステムを意図的に設計することが極めて重要である。
6. AIがもたらす潜在的な利益は、リスクを正当化するものではないのか?
リスクが無視できるものであれば、AIの潜在的利益はリスクを正当化しうる。しかし、AIによる存亡の危機が発生する可能性は高すぎるため、AIを急速に開発することは賢明ではない。絶滅は永遠に続くのだから、はるかに慎重なアプローチが求められる。これは、新薬のリスクと副作用の可能性を天秤にかけるようなものではない。むしろ、より慎重なアプローチとは、存続に関わるリスクが無視できるレベル(例えば、1世紀あたり0.001%以下)まで低減されるよう、ゆっくりと慎重にAIを開発することである。
影響力のあるテクノロジー・リーダーの中には、技術的ユートピアに向かって邁進するため、AIの急速な発展を主張する加速論者もいる。このテクノ・ユートピア的視点は、AIを人類の宇宙的天賦の才能を解き放つための、定命の道を進む次のステップと見なしている。しかし、この視点の論理は、それ自体で考えると破綻する。AI開発の宇宙的な利害に関わるのであれば、その場合でも、実存的なリスクを無視できるレベルまで下げることが賢明であることがわかる。テクノ・ユートピアは、AIの開発を遅らせることは、人類が毎年新しい銀河にアクセスすることを犠牲にすることになると指摘するが、もし人類が絶滅すれば、宇宙を失うことになりかねない。したがって、潜在的利益の魅力にもかかわらず、加速よりもリスク軽減を優先し、AI開発を遅らせて安全に長引かせることが賢明な道である。
7. AIによる破滅的リスクへの関心が高まると、AIによる今日の緊急リスクがかき消されてしまうのではないか?
AIによる破滅的リスクに注目することは、今日の緊急リスクを無視することを意味しない。様々な異なる疾病の研究を同時に行ったり、気候変動や核戦争によるリスクの軽減を優先したりするのと同じように、両者に同時に取り組むことができる。さらに、AIがもたらす現在のリスクは、将来起こりうる破滅的なリスクとも本質的に関連しているため、両方に取り組むことは有益である。例えば、富裕層に不釣り合いな利益をもたらすAI技術によって、極端な不平等が悪化する可能性がある一方、AIを使った大量監視は、最終的には揺るぎない全体主義とロックインを促進する可能性がある。このことは、差し迫った懸念と長期的なリスクが相互に関連し合っていることを示しており、両方のカテゴリーに思慮深く取り組むことの重要性を強調している。
加えて、システム開発の初期段階で潜在的リスクに対処することも極めて重要だ。FrolaとMillerが国防総省のための報告書で示したように、システムの安全性に影響を与える最も重要な決定の約75パーセントは、開発の初期に行われる[147]。
初期の段階で安全性への配慮を無視すると、システムに高度に統合された安全でない設計を選択することになり、後々、コストが高くなったり、安全ソリューションを改修できなくなったりすることが多い。したがって、潜在的なリスクへの対応は、その緊急性の有無にかかわらず、早期に開始することが有利である。
8. AIの安全性向上に取り組んでいるAI研究者は多くないのか?
AIの安全性向上に取り組んでいる研究者はほとんどいない。現在、一流の機械学習の場で発表される論文のうち、安全性に関連するものは約2パーセントである[111]。
残りの98パーセントは、より強力なAIシステムをより早く構築することに焦点を当てている。この格差は、よりバランスの取れた取り組みの必要性を強調している。しかし、研究者の割合だけでは全体の安全性とは一致しない。AIの安全性は社会技術的な問題であり、単なる技術的な問題ではない。したがって、技術的な研究以上のものが必要となる。快適さは、単にAIを安全にすることに取り組んでいる研究者の割合からではなく、壊滅的なAIのリスクを無視できるものにすることから生まれるべきである。
9. 意味のある変化を生み出すには何千年もかかるのだから、進化がAI開発の原動力となることを心配する必要はないだろう?
ヒトの生物学的進化は遅いが、ミバエやバクテリアのような他の生物の進化は非常に速く、進化の時間スケールが多様であることを示している。ソフトウェアのような非生物学的構造においても、同じように急速な進化が観察される。同様に、AIの進化も非常に速いと予想される。AIの進化速度は、激しい競争、AIの多様な形態とそれらに与えられた目標による高いバリエーション、そしてAIの迅速な適応能力によって推進されるかもしれない。その結果、激しい進化圧力がAIの発展の原動力となるかもしれない。
10. AIが深刻なリスクをもたらすには、権力を求める衝動が必要ではないか?
権力を求めるAIはリスクをもたらすが、大惨事につながる可能性のあるシナリオはそれだけではない。AIの悪意ある使用や無謀な使用は、AI自身が権力を求めなくても同様に損害を与える可能性がある。さらに、AIは意図的に権力を求めなくても、代理ゲームやゴールドリフトによって有害な行動に出るかもしれない。さらに、競争圧力に後押しされた社会の自動化傾向は、人間に対するAIの影響力を徐々に強めている。したがって、リスクはAIが権力を掌握することだけに起因するのではなく、人間がAIに権力を譲り渡すことにも起因する。
11. 人間の知能とAIの組み合わせは、AI単独よりも優れており、失業や人間が無関係になる心配はないのではないか?
過去に人間とコンピュータのチームがコンピュータ単独を凌駕したことは事実だが、それは一時的な現象である。例えば、「サイボーグ・チェス」は人間とコンピューターが協力して行うチェスの一形態で、歴史的には人間やコンピューター単独よりも優れていた。しかし、コンピュータ・チェスのアルゴリズムの進歩により、人間とコンピュータのチームの優位性は侵食され、もはやコンピュータ単独と比較して優位性はないと言っても過言ではない。もっと単純な例を挙げれば、簡単な割り算の計算機と人間を戦わせる人はいないだろう。同じようなことがAIにも起こるかもしれない。人間とAIが効果的に協働できる中間段階はあるかもしれないが、この傾向は、AI単独が最終的に様々なタスクで人間を凌駕する可能性があることを示唆している。
12. AIの発展は止められないように思える。それを劇的に遅らせたり、止めたりするには、侵略的な世界的監視体制のようなものが必要ではないか?
AIの開発は主にGPUと呼ばれるハイエンドチップに依存しており、ウランのように監視・追跡が可能だ。さらに、フロンティアAIの開発に必要な計算量と資金的投資は指数関数的に増加しており、その結果、開発に十分なGPUを獲得できるアクターは少数になっている。したがって、AIの成長を管理するには、必ずしも侵略的なグローバル監視が必要なわけではなく、むしろハイエンドGPUの使用状況を体系的に追跡する必要がある。
