
Understanding and misunderstanding randomized controlled trials
www.sciencedirect.com/science/article/pii/S0277953617307359
2018年8月
Angus Deaton Nancy Cartwrightde

ハイライト
- 無作為化はどの単一の試験においても交絡因子のバランスをとることはできない。
- 偏りのなさは精度と比べて実用的な価値は低い。
- 治療効果の非対称な分布は、有意性の検定に脅威を与える。
- 最良の方法は、検証される仮説、知られていること、ミスのコストによって異なる。
- RCTの結果は科学に役立つが、「何が効くか」を推論する根拠としては弱い。
概要
無作為化比較試験(RCT)は、医学だけでなく、社会科学においてもますます普及している。私たちは、一般の人々や、時には研究者が、他の調査方法よりもRCTを信頼しすぎていると主張する。
応用文献で頻繁に主張されていることとは逆に、無作為化は治療群と対照群において治療以外のすべてのものを均等化するものではなく、平均治療効果(ATE)の正確な推定値を自動的に提供するものでもなく、(観察されたまたは観察されていない)共変量について考える必要性から解放されるものでもない。
推定値が偶然に生まれたものかどうかを見極めるのは、一般に考えられているよりも難しいことである。せいぜいRCTでは不偏の推定値が得られるが、この特性は実用的な価値が限られている。たとえそうであっても、推定値は試験のために選択されたサンプルにのみ適用され、多くの場合、利便性の高いサンプル以上のものではなく、試験サンプルが属する集団を含む他のグループや、試験に参加した個人を含む任意の個人に結果を拡大するには、正当な理由が必要である「外部妥当性」を求めることは、RCTの潜在的な貢献度を過小評価しつつ、RCTに過剰な期待を寄せることになるので、役に立たない。
RCTは確かに最小限の仮定しか必要とせず、ほとんど予備知識なしに実施できる。これは、不信感を持っている聴衆を説得する際には有利であるが、科学の累積的進歩にとっては不利である。
RCTは、科学的知識と有用な予測を構築する役割を果たすことができるが、それは、「何が効くか」ではなく「なぜ効くか」を発見するために、概念的・理論的な開発を含む他の方法と組み合わせた、累積的なプログラムの一部としてのみ行うことができる。
1. はじめに
無作為化比較試験(RCT)は、因果関係を推論するための理想的な方法として広く奨励されている。これは医学の分野では古くから言われてきたことである(例えば、FDAによる医薬品の臨床試験など)。注目すべき例外は、米国疾病管理予防センターの元所長であるFrieden(2017)による最近の論文であり、RCTの重要な限界を挙げるとともに、RCTが実行可能であっても他の方法に支配されている様々な状況を挙げている。医学における以前の批評には、Feinstein and Horwitz, 1997, Concato et al 2000, Rawlins, 2008, and Concato (2013))がある。また、他の健康科学や、心理学、経済学、教育学、政治学、社会学などの社会科学の分野でも、その傾向が強まっている。研究者や一般の人々の間では、RCTは、他の経験的手法によるものよりも信頼性が高く、信用できる因果推論や平均治療効果(ATE)の推定値をもたらすと考えられている。RCTは、観察研究の特徴である無数の問題からほとんど除外されており、最小限の実質的な仮定、ほとんどあるいは全くない事前情報を必要とし、しばしば操作可能、政治的に偏っている、あるいは疑わしいとみなされる「専門家」の知識からほとんど独立していると考えられている。また、試験登録や事前に指定された分析計画が必須であるか、少なくとも標準的であることから、非ランダム化試験よりも研究者や出版社の自由度(例えば、p-hacking、選択的分析、出版バイアスなど)に対する抵抗力が強いと感じられることもある。
私たちは、RCTが特別な地位を占めることは正当化されないと主張する。どの方法が良い因果推論をもたらす可能性が高いかは、我々が何を発見しようとしているか、また何が既に知られているかに依存する。予備知識が少ない場合は、どの方法でも裏付けのある結論が得られる可能性は低い。この論文は、RCT自体を批判するものではなく、証拠の階層化を提案するものでも、良い研究と悪い研究を特定しようとするものでもない。むしろ、何を発見したいのか、なぜそれを発見したいのか、そして何をすでに知っているのかによって、優れた調査ルートが存在することが多く、また、RCTが役立つ多くの問題については、RCTの結果を実用的なものにするために、経験的、理論的、概念的な他の多くの作業が必要であることを論じる。
私たちの議論は、因果推論の技術的なことに無頓着な人のためだけでなく、この分野に精通している人にも何かを提供することを目的としている。この論文に書かれていることのほとんどは、何らかのテーマで誰かに知られていることである。しかし、疫学が知っていることは、経済学、政治学、社会学、哲学が知っていることではないし、その逆もまた然りである。これらの分野のRCTに関する文献は重なり合っているが、しばしば全く異なっている。それぞれが独自の言語を使用し、異なる理解や誤解が異なる分野や異なる種類のプロジェクトを特徴づけている。ここでは、様々な分野において、その分野の専門家全員が共有していなくても、真摯な研究者や研究利用者の間で誤解が見られる問題を取り上げている。分野を超えた幅広い視点を目指しているが、私たち自身の専門的な背景から、これらの問題が経済学でどのように生じているか、また哲学者がどのように扱ってきたかを最もよく理解できるようにしている。
我々は2つの論点を提示する。1つ目は、RCTから推定されたATEは、他の方法で推定されたものよりも真実に近い可能性があるという考えについての調査である。2つ目は、RCTの結果が得られた場合、それをどのように利用するかを検討するものである。
第1章では、偏りや精度、あるいは効率や期待損失といった、統計学でおなじみの用語を使って議論を進めた。不偏性とは、平均的に正しいことを意味する。平均は、試験で同じ被験者のセットを使用して無限の繰り返しにわたって取られるが、1つの推定値が真実からどれだけ離れているかに制限はない。一方、正確性とは、平均的に真実に近いことを意味する。期待値における共変量のバランスと、1回の実験におけるバランスの違い(疫学では「ランダム交絡」や「実現交絡」と呼ばれることもあり、例えばGreenland and Mansournia (2015)やVan der Weele (2012)を参照)と、それに関連した精度と不偏性の区別についてレビューする。これらの区別は、RCTが実施されたり、RCTの結果が使用されたりする場所ではよく知られているはずであるが、議論の多くは、混乱していないとしても、役に立たないほど不正確である。さらにあまり認識されていないのが、統計的推論の問題であり、特に研究集団における個々の治療効果の分布が非対称である場合に生じる有意性検定への脅威である。
第2章では、RCTから得られるエビデンスを利用するいくつかの異なる方法について説明する。私たちが特定した使用方法のタイプは、異なるラベルを使用した類似のものであり、分野を超えている。このセクションでは、RCTの結果を使用する際には、問題となっている仮説と調査の目的を明確にすることが重要であることを強調している。このセクションでは、外挿と一般化を強調する通常の文献において、RCTが過小評価されていると同時に過剰評価されていることを論じている。過剰評価されているのは、RCTの結果を外挿したり一般化したりするには、RCTからは得られない多くの追加情報が必要だからであり、過小評価されているのは、RCTは、ある試験集団で得られた結果が他の場所でも有効であることを予測する以外にも、多くの目的を果たすことができるからである。
この2つのセクションを「内部的妥当性」と「外部的妥当性」と名付けたいと思うかもしれない。しかし、私たちはこれに抵抗がある。外部妥当性とは、「同じATEがこの新しい環境でも保持される」、「試験から得られたATEが一般的に保持される」、あるいは「新しい環境でのATEが研究集団でのATEから何らかの合理的な方法で計算できる」ということを意味する場合、RCTは十分に評価されていない。RCTの結果は、より広範囲に役立つ可能性がある。RCTは、そのノンパラメトリックで理論のない性質が、推定や内部妥当性において間違いなく有利であるにもかかわらず、その有用性の論拠として使われすぎている。構造を持たないことは、結果が得られた文脈の外で結果を使おうとすると、しばしば不利になる。推定における信頼性は、使用における信じられなさにつながる。RCTの結果が、自分がすでに持っている世界の知識とどのように関連しているのか、その知識の多くは他の方法で得られたものであることをまず理解しなければ、臨床試験の結果をどのように使えばよいのかを知ることはできない。RCTがこのような幅広い知識と推論の構造の中に位置づけられ、それを強化するように設計されていれば、RCTは有効性の主張を正当化するだけでなく、科学の進歩全般にとって非常に有用なものとなる。累積的な科学は困難であるが、行動したときに何が起こるかを確実に予測することも同様である。
この論文で述べていることは、RCTに対する一般的な議論として受け取られるべきではない。私たちは単に、正当化できない主張に異議を唱え、誤解を明らかにしようとしているだけである。私たちはRCTに反対しているのではなく、RCTについての魔法のような考え方に反対しているだけだ。誤解が問題なのは、RCTが常に因果関係と有効性に関する最も強力な証拠を提供するという共通の認識を助長し、より一般的な科学的プロジェクトの一部としてのRCT証拠の有用性を損ねるからである。特に、私たちはRCTと他の方法を比較して順位付けしようとはしない。どのような方法をどのように組み合わせて使うのがベストかは、問題となっている正確な問題、許容できる背景の仮定、そしてさまざまな種類のミスのコストに依存する。第2節では、RCTには何ができて、何ができないのかを明らかにし、第3節ではRCTで確保された情報を利用するためのさまざまな方法を提示することで、エビデンスランキング制度につきまとう「メソッドの直接対決」(head-to-head between methods)という言説がいかに役に立たないかを明らかにしたいと思う。
2. RCTは平均的な治療効果の良い推定値を与えるか?
私たちは試験サンプルから始める。試験サンプルとは、試験の治療群または対照群のいずれかに無作為に割り振られる被験者の集まりである。この「サンプル」は、対象となる母集団からの無作為抽出である可能性もあるが、そうなることは滅多にない。より頻繁には、何らかの方法で選択されたものであり、例えば、参加を希望している人や、試験を実施する人が利用できる単なる便宜的なサンプルである。治療とコントロールに無作為に割り当てられた場合、試験からのデータは、試験サンプル内の治療されたケースと治療されていないケースの結果の2つの(限界)分布、および、を特定することを可能にする。ATEの推定値は、2つの分布の平均値の差であり、社会科学や医学における多くの文献の焦点となっている。
政策立案者や研究者は、ここでの主な焦点であるATEだけでなく、2つの限界分布の特徴に興味を持つかもしれない。例えば、Yが病気の負担で、おそらくQALYsで測定される場合、公衆衛生担当者は、治療法が病気の負担の不平等を減らしたかどうか、あるいは、治療法とコントロールの分布で異なる人々がこれらのパーセントを占めていても、分布の10パーセントや90パーセントに何をしたかに関心があるかもしれない。経済学者は日常的に、所得分布における10分の90の比率や、ある政策がそれにどのような影響を与えるかについて関心を持っている(米国の福祉政策における関連した例については、Bitler er al)。(2006)を参照してほしい)。がんの臨床試験では、生存率の差の中央値を標準的に使用している。これは、各アームで患者の半数が死亡するまでの時間を比較するものである。より包括的には、政策立案者は、2つの分布の下で治療を受けた場合と受けていない場合の期待効用を比較し、被験者の特性を条件として期待効用を最大化する最適な治療ルールを検討したいと思うかもしれない(応用例としてManski, 2004, Manski and Tetenov, 2016, Bhattacharya and Dupas, 2012を参照)。これらの他の種類の情報は重要であるが、我々はATEに焦点を当てており、本稿ではRCTのこれらの他の用途についてはそれ以上考慮しない。
2.1. 平均治療効果の推定
治療効果の推定を考える上で有用な方法は、次のような形式の概略的な線形因果モデルを使用することである。

ここで、Yiはユニットi(人、村、病棟など)のアウトカムであり、iが治療を受けたかどうかを示す二分法(1,0)の治療ダミーであり、iに対する治療の個人治療効果である:Tの値tが個人iのアウトカムYにどれだけ寄与するかを表している(または規制している)。Jは(非常に)大きいかもしれない。個々の治療効果の無制限の異質性(unrestricted heterogeneity)は、治療がx’sまたは他の変数と相互作用する可能性を許容し、Tの効果が他の変数に依存する(修正される)ようにする。他の原因の効果を制御する’sにiの添え字は必要ないことに注意してほしい。個人によってその効果が異なる場合、個人の特性と元のx’sの相互作用を新しいx’sとして含める。x’sが観測不能である可能性があることを考えると、これは制限的ではない。ここでの使い方は分野によって異なるが、通常、(1)の右辺で表されるT以外の要因を共変量という言葉で呼ぶことにしている。また、異なる観測結果に対して異なるベースラインが存在する可能性も捉えられる。
(1)は、現在、疫学では一般的であり、経済学でも増加しているRubin Causal Modelと呼ばれる反面教師的アプローチと結びつけることができる(疫学者向けの説明はRubin (2005)、またはHernán (2004)、歴史的な説明はFreedman (2006)を参照)。例として、Tが二項対立であると仮定する。各ユニットiには2つの可能な結果があり、一般的には「および」とラベル付けされている。(1)を見ると、2つの結果の違いは、個々の処理効果であり、これは通常、ユニットごとに異なる。どのユニットも、同時に処理されたものと処理されていないものの両方を持つことはできないので、結果のどちらか一方のみが発生し、両方が発生することはない-もう一方は反実例なので、個々の処理効果は原則として観察不可能である。
この設定から得られる基本的な定理は、驚くべきものである。平均治療効果は、治療群の平均的な結果から対照群の平均的な結果を差し引いた差であるとし、個々の治療効果を観察することはできないが、その平均を観察することができるとしている。平均治療効果の推定値は、単純に2つのグループの平均値の差であり、2つの平均値の差に適用される統計理論を用いて推定できる標準誤差を持つが、詳細は後述する。平均値の差は、平均治療効果の不偏推定量である。この定理は、平均が線形演算子であるという事実に依存しており、平均の差は差の平均であるということになるが、仮定をほとんど必要としないので注目に値する。治療効果の中央値、パーセンタイル、分散などの他の統計については、同様の事実はなく、実質的な追加の仮定なしにRCTから特定することはできない。そうでなければ、モデルは必要なく、共変量、交絡因子、その他の原因についての仮定も必要なく、治療効果は不均一であり得、統計的分布の形状については、反実結果の値の存在以外には何も必要ない。
Dawid (2000)は、反事実の存在は経験的な証拠によって確認(または反論)できない形而上学的な仮定であり、ある状況下では因果推論に解決できない恣意性が存在するため、例えば(1)には当てはまらないことから議論になっていると主張している。経験主義の哲学者、ライヘンバッハ(1954)の議論も参照してほしい(ライヘンバッハ(1976)として復刊されている)。経済学の分野では、Imbens and Wooldridge (2009, Introduction)が反事実的アプローチのケースを雄弁に語っており、治療効果の異質性がほぼ無制限であるという理論に基づかない仕様の利点を強調している。(Heckman and Vytlacil (2007, Introduction)は、欠点についても同様に雄弁に語っており、反実例的なアプローチでは、治療の正確な性質について不明瞭なままであることが多く、治療効果を他の場所で有用な不変量(Hurwicz (1966)の意味での不変量)に結びつけることが困難であることを指摘している。
治療効果について何かを伝えることを目的とした実験を考えてみよう。この実験では無作為化を使用する場合もあれば、使用しない場合もある。いずれにしても、治療群は「…」を持ち、対照群は「…」を持つと表現することができる。調査(または試験)サンプルがある場合、治療法の平均的な結果から対照群の平均的な結果を引くと、次のようになる。
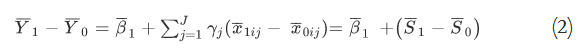
(2)の右端の第1項は、試験サンプルの治療群におけるATEであり、一般的にRCTの実施を選択する際に関心のある量であるが、第2項または誤差項は、2つのグループ間の他の原因の正味の平均バランスの合計であり、一般的にゼロではないため、何らかの処理が必要である。他のすべての原因の平均値が2つのグループで同一である場合、より正確には(そしてより負担が少ないように)それらの正味の差の合計がゼロである場合、我々は望むものを得ることができる。完璧なバランスでは、2つの平均値の差は、被治療者の治療効果の平均値と正確に等しいので、少なくともこの線形ケースでは、試験サンプルの真実を知るという究極の精度を手に入れることができる。いつものように、ここでの「真実」はトライアルサンプルのことであり、トライアルサンプルは、トライアルサンプルから得られた母集団を含めて、最終的に関心のある母集団を代表していないかもしれないということを常に意識することが重要だ;そのような拡張は、さらなる議論を必要とする。
どのようにしてバランスを取るのか、あるいはそれに近いことをするのか。実験室での実験では、通常、他の原因について多くの事前知識があるので、実験者は(2)の最後の項がゼロに近くなるように他の原因を制御(またはその影響を差し引く)することができる。このような知識や制御ができない場合、代替手段としてマッチングがあり、これは無作為化されていない統計学、医学(症例対照研究)経済学の研究で頻繁に使用されている(Heckman er al)。(1997)参照)。各被験者に対して、疑われるすべての原因について可能な限り近いマッチング被験者を見つけることで、再び(2)の最後の項を小さく保つことができる。原因がはっきりしている場合は、マッチングによって正確な推定値が得られることもある。もちろん、未知の、あるいは観察不可能な原因が重要な影響を及ぼしている場合には、実験室での管理も照合も保護にはならない。
では、無作為化ではどうであろうか。例えば、被験者が割り当てを受け入れなかったり、治療プロトコルがコントロールに使用されたものと異なっていたりして、xのYとの相関が無作為化後にもたらされることはないと仮定する。この仮定により、無作為化によって、式(1)で表される他の原因に対する治療法の直交性が得られる。治療法とコントロールは同じ基礎的な分布から得られるので、無作為化によって(2)の右端の最後の項が期待値でゼロになることが構造上保証される。この期待値は、治療法と対照薬をそれぞれ割り当てた、試験サンプルに対する繰り返しの無作為化で得られる。私たちの注意事項が有効であると仮定すると、(2)の最後の項は、この無限の(完全に仮想の)再現にわたって平均化されるとゼロになり、推定されたATEの平均は、試験サンプルの真のATEになる。このように、試験サンプル中の治療を受けた人のATEを不偏的に推定することは、原因が観察されていてもいなくても同じことである。不偏性のためには、共変量、交絡因子、その他の原因について何も知らなくてもよいのであるが、無作為化後に治療法と相関するように変化しないことが必要である。
どの試験においても、平均値の差は、治療を受けた人の平均的な治療効果に、他の原因の正味の効果でランダムに発生した不均衡を反映した項を加えたものである。この誤差項の大きさはわからないし、無作為化によってその大きさが制限されることはないが、後述するように、大きなサンプルでは小さくなる傾向がある。単一の試験において、無作為化の偶然性により、除外された重要な原因が一方の群に過剰に存在することがあり、その場合、2つの群の平均値の間に治療によるものではない差が生じる。疫学では、これを「ランダム交絡」または「実現交絡」(realized confounding)と呼ぶことがあり、Fisherが農業試験で認識していた現象である。(完全なランダム交絡の有益な例はGreenland (1990)によって構築されている)。
試験を何度も繰り返すと、不均衡な原因の過剰な再現は、あるときは治療法に、あるときはコントロールに見られる。この不均衡は、試験の再現期間中に変化し、単一の試験からはわからないが、推定標準誤差からATEの推定値への影響を捉えることができるはずである。これはFisherの洞察であり、無作為化によって治療法と対照法の間の共変量が均衡するのではなく、無作為化後に共変量との相関が生じないことを条件に、無作為化によって誤差の大きさを計算するための基礎が得られるということである。標準誤差とそれに伴う有意差の記述を正しく行うことが最も重要であり、そこに無作為化の美点があり、バランスによって正確な推定値が得られるということではない。
2.2. 誤解:主張のしすぎ
無作為化が何をするのかということは、実用的で一般的な文献ではよくわからない。実験室での実験や観察不可能な原因のない完全なマッチングのような完全なコントロールと,ランダム化が貢献する期待値でのコントロールとがしばしば混同されている.もし、問題について十分な知識があり、うまくコントロールできるのであれば、それが私たちのすることであり、すべきことである。ランダム化は、コントロールするのに十分な知識がない場合の代替手段であるが、知識がある場合には一般的に優れたコントロールよりも劣る。私たちは、RCTが構造的に正確であるという信念と同様に、RCTに対する一般の人々や専門家の熱意の少なくとも一部は、バランスに関する誤解から来ているのではないかと考えている。つまり、疫学的な言葉で言えば、ランダムまたは実現された交絡と、予想される交絡についての誤解である。このような誤解は、迫られればたいてい研究者の間でも正しい説明があまり見られない。このような誤解は、研究者の不正確な発言が、研究者が熱心にアプローチしようとしている一般の聴衆に文字通りに受け取られてしまうことから生じており、ますます成功している。
このような誤解は、米州開発銀行と世界銀行が共同で発行しているインパクト評価に関するオンラインマニュアルの第2版(2011年の第1版も同様)からの引用によく表れている。
私たちは、結果の違いをもっともらしく説明する可能性のある観察された要因と観察されていない要因をすべて排除しているので、推定されたインパクトがプログラムの真のインパクトを構成していると確信することができる。(ガートラー et al 2016, 69)
この記述は、単一の試験における実際のバランスと、多くの(仮説的な)試験における期待値のバランスを混同しているため、誤っている。もしこれが本当で、すべての要因が実際にコントロールされていたら(そして無作為化後に不均衡が導入されていなかったら)差は(少なくとも測定誤差がなければ)試験集団における被治療者間の平均的な治療効果の正確な測定値となるであろう。私たちは自分の推定値に自信を持つだけでなく、引用文にあるように、それが真実であることを知ることができるであろう。この文章にはサンプルサイズについての言及がないことに注意してほしい。私たちは、多数の観察結果からではなく、バランスによって真実を得るのである。
経済学の文献には、同じような言葉がたくさんある。医学文献からは、RCTからの証拠の使用に深く懐疑的な、著名な精神科医の言葉を紹介する。
無作為化試験の長所は、研究者が結果に影響を与えるすべての要因を理解する必要がないことである。例えば、まだ発見されていない遺伝子の変異によって、ある人が薬に反応しなくなったとする。無作為化プロセスにより、試験の各群にその遺伝子変異を持つ被験者が同数含まれることが保証されるか、またはその可能性が高くなる。その結果、公正な試験となる。Kramer (2016,18)
RCTはエラーの可能性なしに知識を明らかにするという主張がなされている。米国政府の政策に関するRCTを45年間実施してきたMDRC(元々はManpower Development Research Corporation)の長年の社長であるJudy Gueronは、度重なる困難にもかかわらず、また他の方法が利用可能であったにもかかわらず、なぜ連邦政府や州政府の役人が無作為化を支持する用意があったのかを問いかけ、それは「彼らが真実を知りたかったから」だと結論づけている、Gueron and Rolston (2013, 429)である。「無作為化試験で評価されたから、【プロジェクトX】がうまくいったことがわかった」という形の記述も多い、Dynarski(2015)。
RCTから得られたATEを、試験サンプルに限らず、より一般的に真実であるかのように扱うのはよくあることだ。経済学では、有名な例としてLalonde(1986)の労働市場訓練プログラムに関する研究があり、その結果は過去の多くの非無作為化研究と相反するものであった。この論文をきっかけに、観察研究を一致させようと大規模な再調査が行われたが、現在では、異なる研究結果が異なる集団に適用されているという事実に違いがあると考えられている(Heckman et al 1999)。治療効果が不均一な場合、ATEは、それが得られた研究サンプルと同じくらい良いものとなる(医薬品の規制における同じ問題を懸念しているLongford and Nelder (1999)を参照)。この点については、3.3節の関連因子とモデレーター変数の議論で触れる)。) 疫学において、Davey-Smith and Ibrahim (2002)は、「観察研究は提案し、RCTは処分する」(observational studies propose, RCTs dispose )と述べている。もう一つの良い例は、閉経後の女性に対するホルモン補充療法(HRT)の RCT である。HRTは、それまでに行われていた質の高い長期の観察研究で肯定的な結果が得られてたが、治療群で過剰死亡が発生したため、RCTは中止された。RCTの否定的な結果により、治療を広く放棄することになったが、これは間違いだったかもしれない(あるいは間違いではなかったかもしれない)(Vandenbroucke(2009)およびFrieden(2017)を参照)。しかし、医学や一般の文献では、先の研究が無作為化されていなかったという理由だけで、RCTは正しく、先の研究は間違っていたと日常的に述べられている。ゴールドスタンダードや「真実」という見方は、累積的な理解のプロセスでRCTの結果を他の証拠と調和させるという科学の義務を損なうときに害をなす。
自動的に正確になるという誤った信念は、(1)や(2)の他の原因に注意を払う必要がないことを示唆している。実際、Gerber and Green (2012, 5)は、政治学におけるRCTの標準的なテキストの中で、RCTは「潜在的な交絡因子をすべて特定することはもちろん、測定することも必要としない研究戦略」という研究者のニーズをうまく解決したものであると述べている。しかし、RCT戦略が成功するのは、一連の架空の実験で誤差が相殺される限り、恣意的に真実からかけ離れた推定値でも満足できる場合に限られる。現実には、治療法に起因する因果関係は、実際には、我々の特定の実験における他の原因の不均衡から来ているかもしれない。これを制限するには、可能な共変量について真剣に考える必要がある。
2.3. サンプルサイズ、バランス、および精度
RCTから推定されたATEの精度に関する文献は、最初の頃にさかのぼる。Gosset (written as ‘Student’) は、農業の野外試験における無作為化に関するFisherの議論を受け入れず、治療とコントロールの配置に関する独自の非ランダム設計が治療効果のより正確な推定値をもたらすと説得力のある議論を行った(Student (1938) and Ziliak (2014)を参照)。ゴッセはギネス社で働いてたが、そこでは非効率性が収益の低下を意味していたため、私たちと同様に気にかける理由があった。フィッシャーが最終的に議論に勝ったのは、Gossetが効率性について間違っていたからではなく、Gossetの手順とは異なり、無作為化は統計的推論のための健全な基礎を提供し、その結果、推定ATEが偶然にゼロと異なるかどうかを判断することができたからである。さらに、フィッシャーのブロッキング手順は、無作為化による非効率性を抑えることができる(Yates (1939)参照)。Gossetの懸念は、Savage (1962)のコメントにも反映されている。ベイズ主義者は、治療法とコントロールの配分を無作為に選ぶのではなく、テーマと被験者について他に何が知られているかを考慮して、それらの配置が研究者にとって最も明らかになるような方法で選ぶべきである。これについては後述する。
無作為化の時点で、また無作為化後に他の原因による変化がない場合、サンプルサイズが大きいと試験がバランスよく行われる可能性が高くなる。サンプルサイズが無限に近づくと、治療群と対照群のxの平均値が恣意的に近くなる。しかし、これは有限のサンプルではほとんど役に立たない。Fisher (1926)は次のように述べている。”Morgan and Rubin (2012, 1263)で引用されているように、「無作為割当を実施したほとんどの実験者は、プロットがどれほど均等から離れて分布しているかを知ってショックを受けるだろう。サンプルサイズが非常に大きくても、原因の数が多ければ、原因ごとにバランスを取ることは不可能かもしれない。Vandenbroucke (2004)は、ヒトゲノムには30億の塩基対があり、その多くまたはすべてが、影響を与えようとする生物学的転帰に関連する予後因子である可能性があると指摘している。確かに、(2)で明らかにしたように、私たちはそれぞれの原因について個別にバランスをとる必要はなく、それらの正味の効果(用語)についてのみバランスをとればよいのである。しかし、ヒトゲノムの塩基対を考えてみよう。数十億の中で重要なのは1つだけかもしれないし、その1つのバランスが悪ければ、1つの試験の結果は「ランダムに混同」され、真実からかけ離れたものになってしまう。大規模なサンプルがバランスを保証するという発言は、どの程度の規模が十分かという指針がなければ役に立たないし、そのような発言は、他の原因とそれが結果にどのように影響するかについての知識がなければできない。もちろん、(2)の観測変数または非観測変数の正味の効果にバランスが欠けていても、非バイアスATEの標準誤差を得るという意味で、RCTにおける推論が損なわれることはない(特に明確な記述についてはSenn (2013)を参照してほしい)が、信頼できる標準誤差を持つことの重要性が明らかになる。
RCTを実施した後、治療法とコントロールの間のバランスについて、利用可能な共変量を調べることは理にかなっている。観察された変数xが原因である可能性があり、その平均値が2つのグループで大きく異なっていることが疑われる場合は、結果を適切に疑って取り扱うべきである。実際には、研究者は無作為化の後、分析の前にバランスの統計的検定を行うことがよくあるが、これはおそらくバランスが取れなかった場合に何らかの適切な処置を取ることを目的としている。論文の最初の表は、通常、対照群と治療群の観察可能な共変量の標本平均とその差を示し、それらがゼロから有意に異なるかどうかの検定を、変数ごとに、または合同で行う。これらの検定は、乱数発生器が故障しているかもしれないと心配している場合や、盲検化されていない被験者が組織的に割り付けを妨害することによって無作為化が損なわれていると心配している場合に、不偏性に対して適切である。そうでなければ、無作為化後の相関が導入されないと仮定すると、テストが示すものが何であれ、無作為化によって不偏性が保証され、テストは精度につながるバランスについての情報ではない。Begg (1990, 223)は、「(I)tは、真であることが知られている帰無仮説のテストである。したがって、もしテストが有意であると判明した場合、それは定義上、偽陽性である。” と述べている。Consort 2010 updated statement, guideline 15には、”残念ながらベースライン差の有意差検定は未だに一般的であり、1997年に主要な一般誌に掲載された50件のRCT試験の半数で報告されている。” とある。他の社会科学全体での実践を体系的に調査したわけではないが、経済学では、Science誌に掲載された(Banerjee er al)。(2015a)のような一流誌での高品質な研究でも標準的である。
もちろん、例えば正規化された平均値の差(Imbens and Wooldridge, 2009, equation (3) )のような、より適切な距離尺度を用いて、単一の試験における観測された共変量間の不均衡を調べることは、常に良い習慣である。同様に、治療と対照の圃場が無作為に選択されていて、構造上、標準的な(不正確な)バランステストを用いても「有意に」異なることができないにもかかわらず、圃場全体の圃場の(ランダムな)分布に明らかなパターンがあった場合、フィッシャーは無作為化を放棄するのが良い方法だったであろう。このような不均衡がATEの推定値を損なうと見るべきかどうかは、どの共変量がどの程度重要であるかについての優先順位による。
バランスを改善するための1つの方法は、無作為化の前にデザインを適合させることであり、例えば、層別化することである。上の引用文が示すように、無作為化による精度の低下をよく知っていたフィッシャーは、農業試験における「ブロッキング」(層別)やラテン二乗法の使用を主張したが、いずれも不均衡の量を制限するものであった。層化が有用であるためには、重要であると思われる要因を事前に理解しておく必要があり、RCTの「知識不要」または「前提条件不要」という魅力から離れることになるが、それには交絡因子について考え、測定する必要がある。しかし、Scriven (1974, 69)が指摘するように “しかし、Scriven (1974, 69) は次のように述べている:「(C)ause huntingは、ライオン狩りと同様に、かなりの量の関連する背景知識を持っている場合にのみ成功しそうである。Cartwright (1994, Chapter 2)はさらに強く、”No causes in, No causes out “と言っている。RCTにおける層化は、他の形態のサンプリングと同様に、推定量の精度を高めるために背景知識を利用するための標準的な方法である。また、層別に異なるATEを検討できるという利点もあり、これは結果を他の場所に適応させたり、移植したりする際に有用である(セクション3参照)。
層化は、共変量が多すぎる場合、または各共変量が多くの値を持つ場合には不可能であり、サンプルサイズを満たすことができないほど多くのセルが存在することになる。5つの共変量、それぞれに10個の値があり、構造を制限するプライヤーがない場合、100,000個の層が考えられる。これらを埋めることは、ほとんどの試験のサンプルサイズをはるかに超えている。より一般的な方法として、再ランダム化がある。無作為化によって、既知の共変量が明らかに不均衡になった場合、例えば、治療区画がすべてフィールドの片側にあったり、治療クリニックがすべてある地域にあったり、対照群に富裕層が多く貧困層が少なかったりした場合、再度無作為化を行い、2群で観察された共変量の平均値の間の距離が十分に小さくなることでバランスがとれるようになるまで、無作為化を続ける。MorganとRubin (2012)は、マハラノビスD統計量を基準として使用し、フィッシャーの無作為化推論(後述)を用いて、再無作為化を考慮した標準誤差を計算することを提案している。実際に広く採用されている別の方法は、結果を左辺に、治療ダミーと共変量を説明変数として、共変量と治療ダミーの間の可能な相互作用を含めて、回帰(または共分散)分析を実行して共変量を調整することである。Freedman (2008)は、ATEの調整済み推定値は有限サンプルではバイアスがかかり、そのバイアスは治療効果の二乗と共変量の相関に依存することを示している。精度の向上と引き換えに多少のバイアスを受け入れることは、しばしば意味のあることであるが、精度を考慮せずに不偏性に依存するゴールドスタンダードの議論が損なわれるのは確かである。
2.4. 無作為化すべきか?
Fisher、Gosset、Savageにまで遡る無作為化と精度の間の緊張関係は、Kasy, 2016,Banerjee et al, 2016,Banerjee er al)。
バイアスと精度の間のトレードオフは、いくつかの方法で形式化することができ、例えば、ATEの推定値が真実から逸脱した場合にユーザーがどのような影響を受けるかに依存する損失または効用関数を指定し、期待損失を最小化または期待効用を最大化する推定器または実験デザインを選択することができる。Savage (1962, 34)が述べているように、ベイズ主義者にとって、これは「最も多くのことを教えてくれると約束された特定のレイアウト」で治療法とコントロールを割り当てることを意味するが、無作為化は行わない。もちろん、このためにはATEの基礎となるメカニズムについて真剣に、そしておそらく困難に考えなければならないが、これは無作為化では避けられない。また、Savageは、異なるプリオールを持つ複数の人が調査に関与する可能性があり、個々のプリオールが「曖昧さと自己欺瞞への誘惑」のために信頼できない可能性があることを指摘しているが、これは無作為化によって軽減されるか、少なくとも回避される可能性がある欠陥である。BCMS(2017)はベイズの無作為化なしの定理を証明しており、BCS(2016)は、学校の成果は学校の質ではなく親の背景によって決まると長年信じてきた学校管理者が、恵まれない子どもを(想定される)質の高い学校に、恵まれた子どもを(想定される)質の低い学校に配置することで最も多くのことを学べるという、ケーススタディ方法論が得意とする研究設定の例を示している。BCSが指摘しているように、このような配分では異なるプリオールを持つ人々を納得させることはできず、彼らは懐疑的なオブザーバーを満足させる手段として無作為化を提案している。この例が示すように、事前情報を形式的な事前確率のセットにコード化することは必ずしも必要ではないが、何を学ぼうとしているのかを考えることは常に必要である。
いくつかの重要なポイントがある。まず、反ランダム化定理は、ランダム化されていないデザイン(例えば、観察不能なものを選択できるようなデザイン)を正当化するものではなく、最も情報量の多い最適なデザインを正当化するものである。Chalmers (2001)やBothwell and Podolsky (2016)によると、医学における無作為化の発展はBradford-Hillに端を発している。Bradford-Hillは医学における最初のRCTであるストレプトマイシン試験に無作為化を用ったが、その理由は、医師が必要性の認識に基づいて(あるいは必要性の認識に反して、いわば後ろ向きになって)患者を選択することを防ぐためであり、最近ではWorrall (2007)もこの議論を繰り返している。必要なのは、例えば被験者が自分で割り当てを選ぶことができる場合のように、隠れた情報が割り当てに影響を与えることがあってはならないということである。
第二に、ユニットが治療またはコントロールに割り当てられる理想的なルールは、共変量と、それらが結果にどのように影響するかについての研究者のプリオールに依存する。これにより、純粋な無作為化では除外されていた、長い間親しまれてきたあらゆる種類の推論方法が可能になる。例えば、哲学者が仮説演繹法と呼んでいるものは、理論を使って予測を立て、それをデータに当てはめて反証することができる(上記の学校の例のように)。これは物理学者が学ぶ方法であり、他の研究者が理論を使って予測を導き出し、それをデータに照らし合わせて検証する場合も同様である。Lakatos 1970などが強調しているように、最も実りある研究の進歩は、データがそのような理論的予測と一致しないときに生じるパズルによって生み出される。経済学では、株式プレミアム・パズル、様々な購買力平価パズル、Feldstein-Horiokaパズル、消費平滑性パズル、栄養不良が蔓延しているインドでなぜ急激な所得増加に伴って消費カロリーが減少したのかというパズルなど、様々な例がある。
第三に、無作為化は、理論や共変量から得られる事前情報を無視することで、リスクの高い実験で人々や不必要に多くの人々を危険にさらすことになり、無駄であり、非倫理的でさえある。Worrall (2008) は、持続性肺高血圧症の新生児に対する新しい治療法であるECMO (Extracorporeal Membrane Oxygenation) の (極端な) ケースを記録している。この治療法は、1970年代に、病気の理論と酸素供給装置がどのように機能すべきかを十分に理解した上で、知的で指示された試行錯誤によって開発された。発明者たちによる初期の実験では、死亡率が80%から 20%に減少した。研究者たちは、RCTを実施しなければならないと考えた。ただし、ある群で成功するたびに、次の赤ちゃんがその群に割り振られる確率が高くなるという、適応型の「勝者の遊び」デザインを採用した。1人の赤ちゃんが従来の治療を受けて亡くなり、11人の赤ちゃんがECMOを受けて生き延びました。それでも、標準的な無作為化比較試験が必要だと考えた。死亡者数4人という停止ルールを設けたところ、対照群では4人(10人中)の赤ちゃんが死亡し、ECMOを受けた9人は1人も死亡しなかった。
第4に、非ランダム法は事前の情報を利用しているので、ランダム化よりも良い結果が得られる。これは、見方によってはメリットでもありデメリットでもある。事前情報が広く受け入れられていなかったり、説得しようとしている人たちに信用されていないと見られていたりする場合、それらの事前情報を使用しない方が、より信頼性の高い推定値を生み出すことができる。実際、BCMS(2017)が医療や開発経済などで無作為化設計を推奨しているのはこのためである。彼らは、事前情報に異議を唱え、それに基づく結果を拒否できる可能性さえある敵対的な聴衆に直面している研究者の理論を展開している(FDAなどの行政機関やジャーナルの査読者を考えてみてほしい)。実験者は、事前情報を必要とする正確さ(および被験者への危害の可能性を防ぐこと)に対する自分の欲求と、事前情報に関わりたくない聴衆の欲求とを引き換えにする。完全に無作為化された実験が行われた後に、批判者が「無作為化は、他の重要な原因とのバランスがとれていないため、実際には公正なテストを提供していない」と主張するのを止めることはできない。RCT、特にメタアナリシスを使用する医師の間では、このような議論は(適切に)一般的である(Kramer (2016)参照)。この話題は3.1節で戻る。
一般の人々が専門家の事前知識に疑問を持つようになった今日、RCTは盛んになるであろう。実験者の誠意を疑うに足る理由がある場合、無作為化は確かに適切な対応となるだろう。しかし、このような単純なアプローチは、科学的努力(FDAの目的ではない)を破壊するものであり、科学的研究における一般的な処方箋としては控えるべきだと考える。過去の知識は、捨て去るのではなく、新たな知識に組み入れる必要がある。過去の知識を使用することを組織的に拒否し、それに関連してRCTを好むことは、科学の累積的な進歩を妨げるレシピである。結局のところ、それは自滅的でもある。ロドリック(D. Rodrik, personal communication, April 6, 2016)の言葉を引用すると、“the promise of RCTs as theory-free learning machine is a false one. “(理論のない学習マシンとしてRCTが約束するものは偽りである。)となる。
2.5. RCTにおける統計的推論
単純なRCTにおける推定ATEは、治療群と対照群の平均値の差である。経済学におけるほとんどのRCTのように共変量が許容される場合、ATEは通常、(1)のような回帰における治療ダミーの係数から推定されるが、異質性は無視される。最近の研究では、標準誤差をクラスタリングすることにより、治療群と対照群で残差分散が異なる可能性を考慮して標準誤差を計算しているが、これは共変量がない場合のおなじみの2標本標準誤差と同じである。統計的な推論は、通常の方法でt-値を用いて行われる。残念ながら、これらの手順では常に正しい答えが得られるわけではない。繰り返しになるが、無作為化の価値はATEの推定値を推測できることであり、これらの推定値の質を保証するものではないので、RCTの議論には信頼できる推測が不可欠である。
(1)を振り返ると、基本的な関心事は、試験サンプル中の各個人に対する個別の治療効果である。RCTは仮定が少なく、それが強みになっている場合が多いので、分布の平均値を特定することしかできない。多くの観察研究では、研究者は関数形や分布についてより多くの仮定を立てる準備ができており、その代償として我々は関心のある他の量を特定することができる。これらの仮定がない場合、推論は2つの平均値の差に基づかなければならないが、この統計量は後述するように、ときにおかしな挙動を示す。この問題はRCT自体とは関係ないが、RCTとその最小限の仮定の中では、平均値から関心のある他の量に簡単に切り替えることができない。
フィッシャーは、統計的推論は「無作為化推論」として知られているものを用いて行うべきであると提案した。この手順は、RCTに基づくATEの推定と同様にノンパラメトリックなものである。すべてのiについて次のような帰無仮説を検定するために、治療がどの個人にも効果がないという帰無仮説の下では、ゼロではないATEの推定値は、それを生み出した特定の無作為割当の結果でしかありえないことに注意してほしい(無作為化後の共変量の分布に差がないと仮定する)。試験サンプル中の治療法と対照薬のすべての可能な組み合わせと、それぞれに関連するATEを表にすることで、ヌルの下での推定ATEの正確な分布を計算することができる。これにより、治療法に効果がない場合に、実際の推定値と同じ大きさの推定値が算出される確率を計算することができる。この無作為化検定は、有限のサンプルを必要とするが、任意のサンプルサイズでも機能する(手順の優れた説明については、Imbens and Wooldridge (2009)を参照してほしい)。
無作為化推論は,上記の例のように,すべての治療効果がゼロであるという帰無仮説を検定するために用いることができるが,しばしば関心の対象となる平均治療効果がゼロであるという仮説を検定するためには用いることができない.農業試験や医学では、治療効果がないというより強い(鋭い)仮説がしばしば関心事となる。多くの公衆衛生のアプリケーションでは、平均的な健康を改善することに満足している。また、福祉実験や費用便益分析などのお金を伴う経済的なアプリケーションでは、治療の純効果が正か負かに関心があり、これらのケースでは無作為化推論は使用できない。これらのことは、適切な場合に社会科学において無作為化推論が広く使用されることを否定するものではない。
無作為化推論が使用できない場合は、2つの平均値の差についての検定を構築しなければならない。標準的な手順はよく機能するが、2つの潜在的な落とし穴がある。1つは,”Fisher-Behrens問題 “で,2つの標本が異なる分散を持っている場合(これは通常,許可したい),通常計算されるt-統計量はt-分布を持たないという事実に由来する.2つ目の問題は、治療効果の分布が対称ではない場合に発生する(Bahadur and Savage, 1956)。どちらの落とし穴もRCTに特有のものではないが、RCTは治療効果を推定する際に手段を用いて作業することを余儀なくされ、文献上ではわずかな例外を除いて、RCTを使用する社会科学者はその困難さに気づいていないようである。
RCTにおける2つの平均値を比較するという単純なケースでは、通常、ATEを次式で与えられる推定標準誤差で割って計算される2標本のt統計量に基づいて推論される。
![]()
ここで,0は対照群、1は治療群を表し、治療群と対照群があり、andは2つの平均値を表する。昔から知られているように、(3)に基づくt統計量は、2つの分散(治療と対照)が同一でない場合、Studentのtとして分布せず、Behrens-Fisher分布となる。極端に言えば、一方の分散がゼロの場合、t統計量は有効自由度が名目自由度の半分になるので、検定統計量は許容されるよりも尾が太くなり、帰無が真の場合に棄却が多すぎることになる。
Young (2017) は、試験結果を治療ダミーだけでなく追加の共変量に回帰して分析する場合や、クラスター化した標準誤差やロバスト標準誤差を用いる場合に、この問題が悪化すると主張している。デザインマトリックスが最大の影響力を持つような場合(共変量の分布が歪んでいて、いくつかのオブザベーションに対してアウトカムが自身の予測値に大きな影響を与えるような場合)には、平均的な治療効果のt値(複数可)の有効な自由度が減少し、誤った有意性の発見につながる。Young氏は、アメリカ経済学会誌に掲載された53件のRCT論文に報告された2027件の回帰を調べ、著者のオリジナルデータに無作為化推論を適用して推定値の有意性を再計算した。有意であると報告された係数を持つ個々の方程式における推定治療効果の30〜40%において、彼はどの観測でも効果なしという帰無を棄却することができなかった。このような偽の発見は、複数の治療法を用いた回帰内と回帰間の多重仮説検定の問題に起因している。回帰内では、治療法はほぼ直交しているが、著者は対応するF検定が有意でなくても、有意なt値を強調する傾向がある。回帰間では、結果はしばしば強く相関しており、最悪の場合、異なる回帰が同じ結果のバリエーションを報告しているため、有意な効果の「kill count」が偽りなく追加されている。同時に、高い影響力を持つオブザベーションが広く存在すると、それ自体が偽の有意性を生み出する。
これらの問題は、少なくとも経済学の分野では、より真剣に取り組まれている。Young, 2017に加えて、Imbens and Kolesár, 2016はFisher-Behrens問題に対処するための実践的なアドバイスを提供しており、現在の最良の実践では多重仮説検定に注意しようとしている。しかし、文献に報告されている結果の多くが、スプリアスに有意であることに変わりはない。
治療効果の分布に外れ値が含まれていたり、より一般的には対称性がない場合にも、偽の有意性が生じる。標準的なt検定は、十分に歪んだ分布では破綻する(Lehman and Romano (2005, 466-8)参照)。対称性を保つことはどれほど難しいのであろうか?また、治療効果の分布が対称でない場合、推論にどれほどの影響があるのであろうか?重要な例として、医療費の支出がある。ほとんどの人はどの期間も支出がゼロであるが、支出があった人の中には、全体の中で大きな割合を占める巨額の支出をする人がいる。実際、有名なランドの健康実験(Manning er al)。1987, Manning er al)。1988参照)では、非常に大きな異常値が1つ存在する。この著者は、治療群間の平均値の比較が脆弱であることを認識しており、ここで述べられているように問題を正確に把握しているわけではないが、支出の歪度をモデル化するように明示的に設計されたアプローチを用いて、好ましい推定値を得ている。もう1つの例は、多くの試験で結果が金銭で評価される経済学から来ている。例えばマイクロファイナンスのような反貧困イノベーションは、参加者の所得を増加させるか?所得自体は対称的に分布しているわけではない。もし、才能はあるが信用に乏しい起業家で、治療効果が大きく正である少数の人々がいる一方で、大多数の借り手は融資を無駄にしているか、せいぜい正だがささやかな利益を上げているのであれば、これは治療効果にも当てはまるかもしれない。最近の文献のまとめでは、これと一致している(Banerjee er al)。(2015b)参照)。
場合によっては、推定値に大きな影響を与える観測値をトリミング、変換、または排除することで、外れ値に対処することが適切であろう。しかし、実験が政策の純利益を推定するように設計されたプロジェクト評価である場合、ランドの健康実験のように真の外れ値を排除すると、分析が曖昧になってしまう。プログラムの良し悪しを決めるのは、まさに外れ値である。対数を取るなどの変換は、対称性を生み出すのに役立つかもしれないが、問われている問題の性質を変えてしまう。費用便益分析や医療改革のコスト計算は、対数ドルではなく、ドルで行う必要がある。
ここでは、現実的だが単純化されたケースで何が起こりうるかを示す例を考えてみる。ここでは、それぞれが治療効果を持つ個人の集団を想像する。治療効果の母集団の平均値はゼロであるが、正の値のロングテールがある;左シフト対数正規分布を使用する。これは、ヘルスケア支出の試験やマイクロファイナンスの試験のようなもので、非常に高いコストを負担したり、クレジットを使って素晴らしいことができる稀な個人の長い正のテールがある一方で、ほとんどの人は調査期間中に何のコストもかからなかったり、クレジットを効果的に使えなかったりする。親集団から無作為に抽出された個人の試行標本は、n個の治療群とn個の対照群に無作為に分けられる。サンプリングのために真のATEが一般的にゼロとは異なる各試行サンプルの中で、多くのRCTを実施し、それぞれのATEの値を表にする。
標準的なt検定を用いて、ATEがゼロであるという(親の分布では真の)仮説は、14%()から6%()の確率で棄却される。これらの棄却は、2つの別々の問題に起因しており、どちらも実際には重要な問題である。(a) トライアルサンプルのATEが対象となる親集団のATEと異なること,(b) 外れ値が存在する場合,t値がtとして分布しないことである、問題となるのは、試験サンプルにたまたま1つ以上の外れ値が含まれていた場合で、親の分布が正の長い尾を持つことを考えると、常にリスクがあると言える.このような場合、すべては外れ値が治療群と対照群のどちらにあるかに依存する。事実上、外れ値はサンプルとなり、有効な自由度の数を減らす。図A1に示すような極端なケースでは、推定ATEの分布は、外れ値がどのグループに割り当てられているかによって二峰性になる。外れ値が治療群にある場合、推定標準誤差と同様に結果の分散が大きく、そのため標準的なt値表を用いてもこれらの結果が帰無を棄却することはほとんどない。過剰な棄却は、外れ値が対照群にあり、結果がそれほど分散しておらず、t値が大きく、負であり、有意である場合に生じる。このような二峰性分布のケースは一般的ではなく、大きな外れ値の存在に依存しているが、過剰排除と偽の有意性を発生させるプロセスを示している。ここでは、平均的な治療効果がゼロであるという仮説に関心があるため、無作為化推論による救済策はないことに注意してほしい。
社会・公衆衛生政策分野でのRCTに関する文献を読むと、これらの懸念から逃れることはできないことがわかる。多くの試験は(時には非常に)小さなサンプルで実施され、非対称性を排除するのが難しい治療効果を持ち、特に結果が金銭である場合には、不可解な、あるいは少なくとも理論的には容易に解釈できない結果が得られることが多いのである。開発研究の文脈では、多くのRCTを引用しているBanerjee and Duflo (2012)もKarlan and Appel (2011)も、誤解を招くような推論に対する懸念を示し、暗にすべての結果を信頼できるものとして扱っている。これらの結果の中には、標準的な理論と矛盾するものもある。世の中には従来の経済学と矛盾する行動があるのは間違いないし、行動経済学の標準的なバイアスで説明できるものもあるが、予想外の発見が十分に支持されていて、理論を修正しなければならないと受け入れる前に、有意差検定を疑ってみるのもいいかもしれない。異なる環境で結果を再現することは、それが適切な場所であれば、役に立つかもしれない(セクション3での議論を参照)。しかし、非対称性が異なる環境でも同じ方向にある可能性があり、対象となる母集団についての推論に使用するために元の試験環境と十分に似ている環境ではそうなる可能性が高く、「有意な」t値が同じ方向の帰無からの逸脱を示すことを考えると、問題の解決にはならない。これにより、偽の所見を再現することができる。
2.6. 不偏性への身近な脅威
無作為化後の差異が2つのグループに影響を与えることが許されるならば、無作為化それ自体は不偏性を保証するのに十分ではないことに注意することは非常に重要だ。そのためには、被験者、実験者、分析者の盲検化や、治療法や結果の違いが被験者に明らかにならないようにするなど、実験を「取り締まる」必要がある。選択バイアスや、プラシーボ効果、ピグマリオン効果、ホーソン効果、ジョン・ヘンリー効果、「教師とセラピスト」効果など、おなじみの懸念は、医療や社会的介入の研究に広く見られる。プラシーボ効果をコントロールすることの難しさは、医療介入の試験では特に顕著であり(批判的レビューはHowick (2011)、第7章を参照)心理療法の試験ではプラシーボ効果とセラピスト変数の効果の両方をコントロールすることの難しさも同様である。例えば、(Pitman et al 2017)は、心理療法が何で構成されているかを特定することがいかに難しいかを示唆しており、KramerとStiles(2015)は、新たな文脈に対するセラピストの反応を分類する「応答性」の問題を扱っている。また、症状の変化は主に認知技術が発揮される前に起こるというデータに基づいて、うつ病に対する認知療法の効果に認知的な変化のメカニズムが関与しているかどうかについて、活発な議論が行われている(IlardiとCraighead、1999,Vittengl et al 2014)。
多くの社会的・経済的試験、医療試験、公衆衛生試験は、盲検化されておらず、また他のバイアス源についても十分にコントロールされておらず、実際に多くのものはそうすることができず、不偏性が損なわれていないという十分な弁明がなされることはほとんどない。一般的には、盲検化を参加者や治験責任医師だけでなく、アウトカムを測定する人やデータを分析する人にまで拡大することが推奨されており、これらの人は全員、意識的および無意識的なバイアスの影響を受ける可能性がある。結果を評価する人の盲検化の必要性は、適用が透明でチェック可能な厳密に規定された手順によって結果が決定されるのではなく、判断の要素を必要とする場合に特に重要である。
試験参加者の盲検化は、「心理的」または「プラセボ」効果をコントロールする必要性に加えて、強制力がない場合にも重要であり、治療群に無作為に割り振られた人々は治療を拒否することを自由に選択することができる。多くの場合、人々は自分の利益になるならば、参加することを選択すると考えるのが妥当である。その結果、治療プロトコルに従うことで得られる利益が、認識された欠点を相殺するほど高くないと(意識的または無意識的に)見積もった人は、治療を避けることができる。治療の選択的受け入れは、治療を拒否しているが、政策が実施されれば受け入れざるを得ない人々について分析者が知る能力を制限する。このような場合、intention-to-treat推定量と、治療を受けた人と受けていない人を比較する「as treated」推定量の両方が、無作為化が排除するように設計されている選択効果の種類によって影響を受ける。
そのため、盲検化は不偏不党のために重要であり、非常に頻繁に欠落している(Hernán er al)。 これは、どの時点でも盲検化を行わないとバイアスが発生すると議論なく仮定すべきだということではない。それはケースバイケースで評価されるべき問題である。しかし、その逆を自動的に仮定することはできない。このことから、盲検化が容易であったり、バイアスの原因のいくつかが見落とされていたり、バイアスを修正する方法について理解が深かったりする観察研究からの推定値と、バイアスがかかっている可能性が高く、その対処方法について良いアイデアを持っていないRCTに基づく推定値との間で、トレードオフが生じることになる。例えば、行政記録などの観察研究では、盲検化が自動的に行われることがある。(例えば、大規模なWomen’s Health Trialにおいて、治療の副作用の存在により「HRT使用者の半数近くで盲検化が破られたが、プラセボ使用者ではわずかな割合であった」と指摘され、結果の分析が複雑になったことについては(Horwitz et al 2017)を参照のこと[1248]。
盲検化の欠如は、無作為化後のバイアスの原因となる唯一のものではない。その後の治療決定が異なることがあり、治療と対照が異なる場所で、異なる訓練を受けた施術者によって、あるいは異なる時間帯に取り扱われることがあり、これらの違いは、2つのグループがさらされる他の原因に系統的な違いをもたらす可能性がある。このような違いを防ぐことは可能であり、またそうすべきである。しかし、そうするためには、これらの因果関係のある要因が何であるかを理解する必要がある。
2.7. まとめ
本節の議論は、無作為化の重要性と無作為化試験から推定されたATEに与えられるべき解釈について、どのような意味を持つのであろうか。
第一に、試験集団に対するATEの偏りのない推定値が、試験の実施費用を正当化するのに十分な有用性を持つ可能性があることを確認する必要がある。
第二に、無作為化は直交性を保証しないので、推定値が不偏であると結論づけるためには、無作為化後に治療法との有意な相関がないことを保証する必要がある。
第三に、ここで検討した推論の問題は、単に推定で片付けられるものではない。実質的な異質性がある場合、たとえ試験が対象となる母集団から無作為に選択されたとしても、試験サンプルのATEは対象となる母集団のATEとはかなり異なる可能性がある。実際には、試験サンプルと母集団との関係はしばしば不明瞭である(Longford and Nelder (1999)を参照)。
第4に、多くの場合、統計的な推論は問題ないが、治療効果に外れ値がある可能性に真剣に注意を払う必要がある。これは、問題に関する知識が示唆することであり、治療法とコントロールの周辺分布の検査が有益な場合がある。例えば、両者が対称的であれば、治療効果が高度に歪んでいる可能性は低いと思われる(確かに不可能ではないが)。Fisher-Behrensに対処する手段を用い、目的の仮説に適している場合には無作為化推論を考慮すべきである。
これらはすべて、現在の実践に対する挑戦ではなく、改善のための提言と考えることができる。より根本的には、RCTから算出されたATEは自動的に信頼できる、無作為化は自動的に観察されないものをコントロールする、あるいは最悪の場合、算出されたATEが真実であるという、よく言われる考えに強く異議を唱える。たまたまそれが真実に近かったとしても、私たちが言う真実とは、試験サンプルの中だけの真実のことである。それ以上の推論をするには、次節で検討するような議論が必要である。また、何を測定しようとしているのか、何のためにその測定値を使用したいのかによって、RCTがそれを推定するための最良の手段であるという前提はないことを論じた。これもまた、推定ではなく議論が必要である。
3. ランダム化比較試験の結果の利用
3.1. はじめに
試行サンプルに対する適切に実施されたRCTからATEを推定し、その標準誤差から、効果が偶然に生じたものではないと信じる理由が得られたとする。このようにして、統計的推論の限界まで、治療法がトライアルサンプルに効果をもたらすという良い保証が得られた。このような知見は何のためにあるのであろうか?
RCTを論じた文献は、結果を得ることに注意を払っており、それによって何が正当に行われるかを検討していない。発見をどのように、どのような目的で使用するかを示す理論的、経験的な研究は十分ではない。あるのは、同じ結果が元の設定の外でも通用する条件や、他の場所で使用するためにどのように適応されるかに焦点が当てられている傾向があり、治療と研究で調査された結果との間の直接的な関係を超えて、仮説を立て、検証し、理解し、調べるためにどのように使用されるかにはほとんど注意が払われていない。しかし、結果の利用方法を知ることが、結果の実証方法を知ることよりも重要でないということはありえない。エビデンスの連鎖は、最も弱いリンクほど強固であり、厳密に確立された効果であっても、その適用可能性を例えという緩い宣言で正当化することはほとんど意味がない。試験が有用であるためには、試験と同様に慎重に構築された使用方法が必要である。
(Shadish et al 2002)が行った「内部妥当性のプライマシー」の議論は、悪いRCTは一般化できそうにないという警告としては妥当かもしれないが、Cook(2014)が指摘するように、「内部妥当性に関する推論は必然的に確率的なものである」。さらに、primacyステートメントは、内部妥当性のある試験の結果は、自動的に、または多くの場合、他の場所で「そのまま」適用されることを暗示していると誤って解釈されることがある。また、これは、一度よく確立されたパラメータは、設定を超えて不変であることが期待できるかのように、それに反する議論がない限り、デフォルトの仮定であるべきである。不変性の仮定は、例えば、医療においてよく行われる。病気のすべての段階でその効果が同じであることはないが、特定の処置や薬剤がどこでも同じように作用することは、時にはもっともなことである。より一般的には、Horton (2000)が強い反対意見を示し、Rothwell (2005)が賛否両論の議論を展開している。また、最近では、女性やマイノリティを対象とした医薬品の試験を行うようにしようという動きがあるが、これは、これらのグループのメンバーが、ほとんどが健康な若い白人男性を対象とした試験の結果は自分たちには当てはまらないと考えているからである。また、(Williams et al: “また、Williams et al 2015)にあるように、「実用的な試験とは…『効果があることはわかっているが、実際の臨床現場ではどの程度効果があるのか』を問うものである」としている。
RCTの結果を利用するための私たちのアプローチは、RCTの結果がエビデンスになるかどうか、またどのような方法でエビデンスになるかは、その結果がエビデンスになるとされる仮説が正確に何であるかに依存し、またどのような種類の仮説であるかは、提供されるべき目的に依存するという観察に基づいている。このことは、試験のデザインにも影響する。このことは、医学文献において、説明的試験と実用的試験の区別や、試験デザインを質問された内容に適合させるための提案として認識されており、例えばPatsopoulos(2011, 218)は次のように述べている。「説明的試験は、介入が機能するかどうか、どのように機能するかを探るための最適なデザインである」一方、「調査中の研究課題は、介入が実際に実生活で機能するかどうかである」。また、例えば(Rothman et al 2013, 1013)にも反映されており、単純な外挿がRCTの結果を適用できる唯一の目的ではないと主張している。「間違いは、統計的推論が科学的推論と同じであると考えることだ。」”The mistake is to think that statistical inference is the same as scientific inference. “と述べている。私たちは、いくつかの異なる目的を区別し、RCTがどのように、そしていつ、それらに役立つかを議論する。(a)単純な外挿と単純な一般化、(b)試験に登録された集団についての教訓を引き出す、(c)調整を伴う外挿、(d)スケールアップした場合に何が起こるかを推定する、(e)個人に対する治療の結果を予測する、(f)理論の構築と検証。
このリストは完全なものではない。セクション2.4では、ここでは追求しないもう一つの用途について述べた。それは、RCTが正しい答えを与えてくれるということが広く知られており、ほとんど批判されていないことから、政治的な対立を解決するための紛争和解メカニズムとして利用されていることである。例えば、米国の連邦レベルでは、将来の政策は超党派のCongressional Budget Office (CBO)によって吟味され、CBOは予算への影響を独自に見積もっている。CBOに悪い評価をされたプログラムを持つイデオローグは、自分を納得させるためではなく、反対派を納得させるためにRCTを支持するインセンティブを持つ。繰り返しになるが、RCTは、あなたの対戦相手があなたの優先順位を共有していない場合に価値がある。
3.2. 単純な外挿と単純な一般化
ある試験で、特定の環境下で(確率的に)結果が出たとする。他の場所でも「同じ」結果が得られれば、それは外的妥当性があると言われる。外部妥当性とは、単に因果関係の再現を指す場合もあれば、さらに進んでATEの大きさの再現を必要とする場合もある。いずれにしても、その結果は、どこでも、あるいは広く、あるいはある特定の場所で成り立つか、あるいは成り立たないかである。
外部妥当性に関するこの二元的な概念は、RCTの結果に、臨床試験が有用であるために必要でも十分でもない条件を満たすことを求め、その価値を過大評価したり過小評価したりするため、役に立たないことが多い。また、同じ結果が他の場所でも通用するかどうかという単純な外挿や、普遍的あるいは少なくとも広く通用するという単純な一般化を求め、より複雑ではあるが同様に有用な結果の応用から遠ざけてしまう。単純な一般化や外挿と解釈される外部妥当性の失敗は、試験結果の価値をほとんど語っていない。
RCTには、結果を元の文脈を超えて適用する必要のない利用法がいくつかあるが、これらについてはセクション3.4で述べている。それ以外にも、十分に実施され、情報量が多く、潜在的に有用なRCTの結果が、単純な方法で他の場所に適用されないことを期待する十分な理由がしばしばある。さらなる理解と分析がなければ、成功した再現実験であっても、単純な一般化の賛否はほとんどわからず、次の実験も同じように機能するという結論を裏付けるものではない。また、再現に失敗したからといって、元の結果が役に立たなくなるわけでもない。再現が失敗した理由を理解することで多くのことを学ぶことができ、その知識を元の結果を引き起こした要因が異なる環境でどのように作用するかを調べるために利用することができる。第三に、科学の進歩にとって特に重要なことであるが、RCTの結果は、RCTから報告された結果とは全く異なる主張を検証または探求する証拠や仮説のネットワークに組み込むことができる。RCTの結果が他の場所では通用しないという(通常の)意味で、外部的に妥当ではないRCTの価値ある利用法について、以下に例を挙げてみる。
ランドの健康実験(Manning et al 1987, 88)は、その結果がそれ以来、ヘルスケアに関する学術的・政策的議論に浸透しているという点で、参考になる話である。そもそもこの実験は、保険を手厚くすることで、人々がより多くの医療を利用するようになるかどうか、もしそうだとすれば、どの程度になるかを検証するために行われた。この研究の不滅性は、むしろ、マルチアーム(応答面)デザインにより、自己負担額が何パーセント増加するごとに医療費が-0.1〜-0.2パーセント減少するという、研究対象者の弾性値を算出できたことにある。(Aron-Dine et al 2013)によると、この無次元の数字は輸出可能な数字であるため、それ以来、医療政策の設計を議論する際に使用され、弾性値は普遍的な定数として扱われるようになったという。皮肉なことに、この推定値は最近の研究では再現できず、元の証拠にしっかりと基づいているかどうかは不明であるとしている。この結果の単純で直接的な輸出可能性は、おそらく幻想だったのであろう。
RCTの結果を輸出して一般化しようとする動きは、医学や社会科学の分野で影響力を持つ「what works」運動の中核をなすものである。最も野心的なものでは、普遍的な到達を目指している。例えば、開発経済学の文献では、Duflo and Kremer (2008, 93) が「信頼できる影響評価は、国境を越えて国際機関、政府、ドナー、非政府組織(NGO)に信頼できるガイダンスを提供できるという意味で、グローバルな公共財である」と論じている。1つのRCTの結果が広く適用可能であると提唱されることがあり、少なくとも1つの再現実験がある場合には特に強く支持される。
RCTの結果をある環境から別の環境に移すために、単純な外挿がしばしば用いられる。「What works」の文献に書かれていることの多くは、反対の証拠がない限り、治療効果の方向性と大きさは、深刻な調整なしにある場所から別の場所に移すことができると示唆している。アブドゥル・ラティフ・ジャミール貧困アクションラボ(J-PAL)は、世界中でRCTを実施し、その結果をまとめ、「科学的な証拠を政策に反映させる」ことで貧困削減を目指している。J-PALのレポートの中には、結果を一般的な費用対効果の指標に変換しているものがある。例えば、「生徒の参加向上-どのプログラムが最も効果的に子どもたちを学校に入れるか」では、結果を「通学時間」「補助金・送金」「健康」「知覚的リターン」「教育の質」「ジェンダー特有の障壁」の6つに分類し、「100米ドルの支出で教育を受けられる追加年数」という共通の単位で報告している。圧倒的に高い評価を得ている「健康」には、ケニアの「虫下し」(11.91)とインドの「鉄分・ビタミンA」(2.61)の2つの研究が含まれており、教育の「知覚的リターン」にはドミニカ共和国の1つの研究(0.23)が含まれている。 「補助金・給付金」では、ガーナの「二次奨学金」の0.17から、メキシコのCCT(条件付現金給付)の0.01,マラウイのCCTの0.09と0.07まで、6件の研究があった。
このような比較から何を結論づけることができるだろうか。教育に関心のある慈善団体のドナーは、限界効果と平均効果が同じであると仮定すると、限界ドルを投入するのに最適な場所はケニアで、虫下しに使われるということを知るかもしれない。これは確かに有用であるが、ビタミンAや奨学金を含むプログラムよりも虫下しプログラムの方がどこでも費用対効果が高い、あるいはどこでもとは言わないまでも、少なくともいくつかの領域では費用対効果が高い、と言うことほど有用ではないし、「何が効果的かを見つける」という約束を真に満たすのは、このような2番目の比較である。しかし、このような比較が意味を持つのは、ある場所での結果が別の場所でもあてはまる場合だけである。ケニアでの結果が、ドミニカ共和国、メキシコ、ガーナ、または特定の場所のリストでもあてはまる場合である。
J-PALの結論は?ここでは、彼らが報告した「実用的な意味」を2つ紹介する。「条件付および無条件の現金給付は就学と出席を増加させることができるが、実施には費用がかかる。.小さな費用を排除することで、学校参加に大きな影響を与えることができる」。ここでの「できる」は、確かに曖昧な言葉である。あるプログラムが与えられた結果を達成したならば、そのプログラムはそうすることができるというのは、確かに論理的な意味では正しい。しかし、読者にとってより自然な意味は、特別な問題がなければ、他のほとんどの場所でそのプログラムがそうすることが「できるかもしれない」ということではないかと思う。
広く知られているように、試験はしばしば人工的な環境で行われるため、外挿するにはよく知られた問題がある。例えば、経済発展に関して、ドレーズ(J. Drèze, personal communications, November 8, 2017)は、インドでの豊富な経験に基づいて、「外国の機関が重いブーツと深いポケットを持ってやってきて、現地のNGOや政府などを通してであれ、『治療』を行うと、治療以外にもいろいろなことが起こりがちである」と指摘している。また、効果のある治療法は、海外から来た「治療者」がいるから効果があるのであって、実際に治療を行う人がいるから効果があるわけではないという疑念もある。
J-PALの費用対効果のマニュアル(Dhaliwal er al)。2012)では、サイト間のコストのばらつきを処理する方法が(まったく適切に)詳細に説明されており、人口密度、価格、為替レート、割引率、インフレ、一括割引などの変動要因が記されている。しかし、このマニュアルでは、費用対効果の計算に重要な役割を果たすATEのサイズのサイト間のばらつきについてはあまり触れられていない。このマニュアルでは、理論的には収穫逓減(またはラストマイル問題)が重要であるかもしれないと簡単に述べているが、成果のベースラインレベルはパイロット地域とレプリケーション地域で類似している可能性が高いため、ATEがそのまま適用されると仮定しても安全であると主張している。これらの主張には、結果を外挿することの正当性や、結果を外挿できる場合とできない場合についての理解が欠けている。また、新しい環境で適用するためには、どのように結果を修正すべきかについての理解もない。「白鳥1は白い、白鳥2も白い、……だから白鳥はみんな白い」というような、単純な列挙による帰納法に過ぎない。フランシス・ベーコン(1859, 1.105)が教えたように、「……単純な列挙によって進められる帰納法は子供じみている」のである。
バートランド・ラッセルのニワトリ(Russell, 1912)は、繰り返し成功した再現からの単純な推定には限界があることを示す優れた例を示している。この鳥は、繰り返される証拠から、農夫が朝やってくると自分に餌をくれると推測する。この推論は、クリスマスの朝、農夫が彼女の首を絞めて夕食に出すまで、彼女に役立つ。この鶏はRCTに基づいて推論したわけではないが、もし私たちが彼女のためにRCTを構築していたら、彼女と同じ結果が得られたであろう。彼女の問題は方法論ではなく、自分が観察した因果関係を生み出した社会的・経済的構造を理解していなかったことにある。(どのような因果関係がありそうで、どのような因果関係がなさそうかを理解するためには、基礎となる構造が重要であることは後述する)。
単純な外挿と単純な一般化の問題は、RCTにとどまらず、「完全にコントロールされた」実験室での実験や、ほとんどの非実験的な知見にまで及んでいる。ここでの私たちの主張は、RCTから得られた証拠は自動的に単純に一般化できるものではなく、優れた内部妥当性があったとしても、それが文脈を超えた独自の不変性を提供するものではないということである。単純な外挿と単純な一般化が自動的とは程遠いということは、類似した介入の(たとえ理想的な)RCTが異なる設定で異なる答えを出し、大規模なRCTの結果が同じ治療法に関するメタアナリシスの結果と異なる場合がある理由も教えてくれる(LeLorierら(1997)のように)。このような違いは、必ずしも方法論の失敗を反映しているわけではなく、観察研究の場合と同様に、完璧に実行されたRCTでも当てはまるであろう。
我々の議論は、外挿や一般化が決して合理的でないことを示唆するものではない。例えば、条件付現金給付は、様々な場所で様々な成果を上げており、内部妥当性の高い評価が政策の急速な普及につながった代表的な例として挙げられる。CCTが成功するために必要な因果関係を考えてみよう。人々がお金を好きであること、子どもが教育や予防接種を受けることを好きである(あるいはあまり反対しない)こと、仕事をするのに十分な距離と人員を備えた学校や診療所が存在すること、スキームを運営する政府や機関が家族や子どもの幸福を気にかけていること、である。このような条件が(すべてではないが)さまざまな国で成立していることから、CCTが多くの再現例で「機能する」のは当然のことといえる。ただし、Levy(2006)などのように学校や診療所が存在しない場所や、教育やワクチン接種に強く反対する人々がいる場所では機能しないことは確かである。つまり、CCTの結果が輸出されるには、構造的な理由があるのである。私たちが異議を唱えるのは、確立された結果が輸出されるのは「当然」であるという仮定である。
要約すると 因果関係を確立しても、それだけでは、一般的な場合はもちろん、ある新しいケースでも因果関係が成立することを保証するものではない。また、理想的なRCTが選択や省略された変数によるバイアスを排除できるからといって、試験サンプルから得られた結果のATEが他の場所でも適用できるということにはならない。この問題は、因果関係の主張が確立される際の厳密さと、関係を外挿したり一般化したりする際に必要となるその他の主張(多くの場合、明言されていない)の厳密さとの対比において、現在、非常に大きな比重を占めていることから、言及する価値があると考えられる。
3.3. 関連因子とATE
一般に、原因の作用には関連因子(support factors)(「相互作用変数」または「モデレーター」とも呼ばれる)の存在が必要である。ある場所で目標とする効果を生み出す原因が、他の場所に存在して作用する能力を持っていたとしても、それがなければ潜在的で作用しないままとなる因子である。Mackie(1974)がINUS因果と呼んだものは、式(1)に反映されている因果の種類である(不足しているが重複していない部分で、それ自体は不要だが結果に貢献するのに十分な条件のもの)。疫学においても同様の考え方があり、「因果のパイ」という言葉を使って、ある結果に寄与するために共同ではあるが単独では十分ではない原因の集合を指している)。典型的な例としては、テレビをつけっぱなしにしていたために家が燃えてしまったというものがあるが、テレビは配線の不具合や火種の存在などのサポート要因がなければこのようには作動しない。
ATEの値は、TがYに寄与するために必要な「関連要因」の値の分布に依存する。これは、(1)を次のような形に書き直すと明らかになる。
![]()
ここで、この関数![]() は、k個の「関連因子」のkベクトル
は、k個の「関連因子」のkベクトル![]() が個人iの治療効果
が個人iの治療効果![]() にどのように影響するかを制御する。関連因子には、xのいくつかが含まれる。ATEはkベクトルの平均であるため、2つの集団が同じATEを持つのは、治療の効果に必要な関連因子の正味の効果、すなわち
にどのように影響するかを制御する。関連因子には、xのいくつかが含まれる。ATEはkベクトルの平均であるため、2つの集団が同じATEを持つのは、治療の効果に必要な関連因子の正味の効果、すなわち![]() の前の量の平均
の前の量の平均![]() が同じである場合に限られる。 しかし、これらの因子は、異なる集団で異なる分布をしている可能性がある種類の因子である。
が同じである場合に限られる。 しかし、これらの因子は、異なる集団で異なる分布をしている可能性がある種類の因子である。
例えば、Vivalt社のAidGradeウェブサイトには、就学率に対するCCTの標準化された(結果の地域標準偏差で割った)効果について、様々な国から得られた29の推定値が掲載されているが、4つを除くすべての国が期待された正の効果を示しており、その範囲は-8~38%ポイントとなっている(Vivalt, 2016)。このように、CCTが子どもたちの就学に「効果がある」と合理的に結論づけられるようなケースであっても、信頼できる費用対効果の数値を算出したり、CCTが他の可能な政策よりも費用対効果が高いか低いかについて一般的な結論を出すことは難しいであろう。コストと効果の大きさは、新しい設定では、観察された設定と同じように異なることが予想され、これらの予測を困難にしている。
(AidGradeでは、Banerjee et al 2015a)による主要な多国間研究と同様に、効果の大きさをベースライン時の結果の標準偏差で割った標準化された尺度を使用している。しかし、J-PALの「支出100米ドルあたりの学校教育の追加月数」のように、経済的な解釈ができる測定法の方がいいかもしれない(例えば、私たちが指摘したように、ドナーがどこに支出すべきかを決めようとしている場合など)。栄養は、身長や身長の対数で測定されるかもしれない。1つの測定方法によるATEが引き継がれたとしても、別の測定方法では、2つの測定方法の関係が両方の状況で同じである場合にのみ、そうなる。これはまさに、単純な外挿が正当化される理由と、単純な外挿が正当化されない場合に予測値をどのように調整するかについての正式な分析が、私たちに考えさせていることなのである。また、オリジナルのRCTにおけるATEは、結果がレベルで測定されているか、ログで測定されているかによって異なる可能性があることに注意してほしい。
心配なのは、新しい環境での関連因子の値の分布が試験での分布と異なることだけではなく、その関連因子が何であるか、あるいは、新しい環境で治療を効果的に行うことができるものがあるかどうかということである。因果関係のプロセスには、高度に専門化された経済的、文化的、社会的な構造が必要になることが多い。構造が異なれば、異なる原因と異なる関連要因を持つ異なるプロセスが可能になる。凧揚げをすると鉛筆が削れるように仕組まれたルーブ・ゴールドバーグ・マシンを考えてみてほしい(Cartwright and Hardie, 2012, 77)。この基本的な構造は、他の場所では因果関係のプロセスを記述することができない、非常に特殊な形の(4)を可能にする。ルーブ・ゴールドバーグ・マシンは誇張された例であるが、因果構造に関する知識がほとんどない場合、単純な外挿がいかに信頼性に欠けるかを明らかにしている。
もっと典型的な例として、システムデザインを考えてみよう。ここでは、自分の好きな因果関係を生成し、自分の嫌いな因果関係を排除するようなシステムを構築することを目指す。医療システムは、看護師や医師がミスをしないように設計され、自動車は逆走しても発進できないように設計され、パイロットのワークスケジュールは、覚醒度やパフォーマンスが低下するために、連続した時間を休まずに飛行しないように設計される。哲学では、因果関係のあるプロセスを支え、あることは可能だがあることは不可能であり、あることはありそうだがあることはありそうにないことを可能にする、相互作用する部品のシステムを「メカニズム」と呼んでいる。特に、(Suzuki er al 2011)のように、治療から結果までの因果関係を表す意味での「メカニズム」ではない。メカニズムは、生物学における因果プロセスの説明を理解する上で特に重要であり、哲学の文献には、Shepherd (1988)が化学的シナプスにおける生化学的メカニズムを用いて、あるニューロンから別のニューロンへの電気信号の伝達プロセスを説明したことを示す、代表的な(Machamer et al 2000)の説明のように、生物学的な例が数多く見られる(Bechtel, 2006も参照)。(Bechtel, 2006, Craver, 2007も参照)。この意味での「メカニズム」は、物理的な部品とその相互作用や制約に限らず、社会的、文化的、経済的な取り決め、制度、規範、習慣、個人の心理なども含まれる(例えば、HIV-AIDsの治療法の効果を決定する上でのコンテキストの重要性に関するSeckinelgin (2017)を参照)。
ルーブ・ゴールドバーグ・マシンや、車や仕事のスケジュールのデザインのように、物理的、社会的、経済的な構造と均衡は、異なる種類の因果関係をサポート、許可、またはブロックする方法で異なる可能性があり、その結果、ある設定での試験が別の設定では役に立たなくなる。例えば、政治システムが人々を社会的・経済的地位に固定している州では、個人的な昇進のためのインセンティブを提供することに依存した試験は役に立たない。親が子どもを診療所に連れて行くことを条件とした現金給付は、診療所が機能していない場合、子どもの健康を改善することはできない。男性を対象とした政策は、女性には通用しない。私たちはパンをトーストするときにレバーを使うが、レバーはトースターでパンをトーストするためだけに作動するもので、アクセルを踏んでトーストを焼くことはできない。設定を誤解したり、RCTの治療法がなぜ効果があるのかを理解していないと、Russellの鶏と同じようなリスクを抱えることになる(機構的構造に関する主張を用いて外挿をサポートすることの難しさについては(Little (2007) and Howick er al 2013)を、内的妥当性と外挿の両方における機構的推論の重要性については(Parkkinen er al)。
3.4. RCTが語る場合:外挿や一般化の必要なし
私たちが学びたいことの中には、RCTがそれだけで十分なものもある。RCTは、一般的な理論上の命題に対する反例を提供するものであり、その命題自体(単純な反論テスト)またはその命題の何らかの結果(複雑な反論テスト)のいずれかである。RCTはまた、ある理論の予測を確認することもある。これは理論を確証するものではないが、特にその予測が事前に本質的にありえないと思われる場合には、その理論を支持する証拠となる。このように、RCTには何の特徴もなく、数ある試験方法の中の一つに過ぎない。理論がない、あるいは非常に弱い理論であっても、RCTは、ある集団において因果関係を証明することで、その治療法がどこかに効くという概念の証明と考えることができる(臨床試験方法の著名な専門家であるCurtis Meinert氏の発言のように)。”臨床試験方法論の著名な専門家であるCurtis Meinert氏の発言にあるように、「ある治療法が誰かに効くことが示されるまでは、男女で効き目が同じか違うかを心配することには意味がない」(Epstein (2007, 108)より引用))。これは、内部妥当性の重要性を示す議論の一つである。
また、RCTが評価のために使用される場合、例えば、資金を提供したプロジェクトが、実施された集団において目的を達成したことをドナーに納得させるために、外挿は求められない。しかし、世界銀行のような評価が世界全体に役立つ(グローバルな公共財となる)ためには、その結果を他の場所で何らかの形で使用することを正当化する議論やガイドラインが必要である。世界的な公共財は、世銀が受託者責任を果たすための自動的な副産物ではない。私たちは何か、何らかの規則性や不変性を必要としている。
RCTの第3の問題のない重要な使用法は、関心のあるパラメータが、試験サンプル自体がランダムなサンプルである、明確に定義された母集団におけるATEである場合である。この場合、サンプル平均治療効果(SATE)は、仮定上、我々の目標である母集団平均治療効果(PATE)の不偏推定量となる(これらの用語についてはImbens (2004)を参照)。多くの公衆衛生上の介入と同様に、ターゲットは平均的な「集団の健康」であり、個人の健康ではない。このようなRCTの使用における主要な(そして広く認識されている)危険性は、個人または個人のグループの結果が他の人の行動を変える場合、(たとえランダムな)サンプルからの結果を集団にエクスポートしても、単純な方法ではうまくいかないということである。
3.5. 再重み付けと層化(Reweighting and stratifying)
RCTの支持者の多くは、「何が効くか」を「どのような状況で何が効くか」に修飾する必要があることを理解し、そのような状況がどのようなものであるかについて何かを言おうとしている。たとえば、RCTをさまざまな場所で再現し、結果の違いを見つけたときにそれについて賢く考えることによってである。例えば、同じ試験で複数の治療法を行い、治療法の様々な組み合わせに結果を結びつける「反応面」を推定できるようにするなど、体系的な方法で行われることもある(Greenbergら(1999)やShadish et al 2002)を参照)。例えば、ランドの健康実験では、複数の治療法があり、異なる状況下で健康保険がどれだけ支出を増加させるかを調べることができた。1960年代と1970年代に行われた負の所得税実験(NITs)のいくつかは、応答面を推定するように設計されており、各群における治療法と対照法の数は、全体的なコスト制限のもとで推定応答関数の精度を最大化するように最適化されていた(Conlisk (1973)を参照)。電力の時間帯別価格設定の実験も同様の構造を持っていた(Aigner (1985)参照)。
また、MDRCの実験は、都市の特徴とRCTの結果を関連付けるために、都市を横断して分析されている(Bloom er al)。(2005)参照)。RANDやNITの例とは異なり、これらは終了した試験の事後分析である。Vivalt(2016)も同様で、彼女が調査した試験の集合体では、政府機関が実施した開発関連のRCTは、学識経験者やNGOが実施したRCTよりも一般的に小さい(標準化された)効果量を示していることがわかっている。NGOまたはケニア政府によって実施された介入に関するRCTを並行して実施したBold et al 2013)は、そこで同様の結果を得ている。なお,これらの分析は,異なる試験が同じパラメータをノイズまで推定し,精度を高めるために平均化することを前提としたメタアナリシスとは目的が異なる。
また、統計的アプローチは、試験集団の結果を調整して対象集団の結果を予測するために広く用いられている。これらは、治療効果が関連因子の変動によって系統的に変化するという事実に対処するためのものである。これに対処するための手順の1つが実験後の層別化であり、これはサンプル調査における調査後の層別化と類似している。試験は、既知の観察可能なWの組み合わせ(例えば、年齢、人種、性別、併存疾患)が同じであるサブグループに分割され、各サブグループ内のATEが計算され、その後、新しい文脈におけるWの構成に応じて再構成される。この方法は、新しい文脈でのATEを推定するため、あるいは試験サンプルが親の無作為サンプルではない場合に親集団への推定値を修正するために用いることができる。他の方法は、層別化するにはWの数が多すぎる場合に用いることができる。例えば、母集団の各観察者が試験サンプルに含まれる確率をWの関数として推定し、これらの傾向スコアの逆数で各観察者を重み付けする。これらの方法の良い参考文献としては、Stuart er al)。(2011)があり、経済学では(Angrist2004)と(Hotz er al 2005)がある。
しかし、これらの方法は、しばしば適用できない。第一に、再重み付けは、再重み付けに使用される観測可能な要因が、すべての(そして唯一の)真の相互作用的原因(サポート/モデレータ要因)を含む場合にのみ機能する。第二に、どのような形の再重み付けであっても、重み付けに使用される変数は、元の文脈と新しい文脈の両方に存在しなければならない。例えば、結果を過去に持ち越す場合、低インフレの時期から高インフレの時期に外挿することはできないかもしれないし、寒冷地で効果のある医療行為が熱帯では効果がないかもしれない。Hotz er al)。 (2005)が指摘しているように、時間的にも場所的にも、このような「マクロ」効果を除外することが一般的に必要となる。第3に、再重み付けは、同じ支配方程式(4)が試験と対象集団の両方をカバーするという仮定にも依存する。
Pearl and Bareinboim, 2011, Pearl and Bareinboim, 2014, Bareinboim and Pearl, 2013, Bareinboim and Pearl, 2014は、再重み付けよりも一般的な、試験結果から新しい集団に関する情報を推測するための戦略を提供している。彼らは、母集団A(例えば実験対象)については因果関係と確率的な情報の両方が得られるが、母集団B(対象)については確率的な情報(一部)しか得られないと仮定し、また、ある確率的な事実と因果関係のある事実は両者の間で共有され、ある事実は共有されないことを知っているとしている。彼らは、それによって母集団Bに関するどのような因果関係の結論が確定するかを記述した定理を提供している。彼らの研究は、ある集団に関するどのような結論が他の集団に関する情報によって支持されるかは、それらがどのような因果的・確率的事実を共有しているかによって決まるという事実を強調している。しかし、Muller (2015)が指摘するように、これは単純な再重み付けの問題と同様に、因果構造の完全で正しい仕様から始めなければならないという、RCTが避けるように設計されている状況に戻ってしまう。RCTは推定においてこのような事態を避けることができ、それがRCTの強みであり、信頼性を支えているが、その結果を新たな文脈に持ち込もうとするとすぐにその利点は消えてしまう。
この議論から、いくつかのポイントが見えていた。特定のRCTで推定されたATEが不変のパラメータであるという便利な仮定や、典型的なRCTで測定される介入とアウトカムの種類が一般的な因果関係に関与しているという仮定には何の保証もない。
第二に、RCTにおける実験前の慎重な層別化は、一般化や外挿に有用な情報を提供することができるため、価値があると思われるが、そうでない場合は、サブグループ分析が必要である。例えば、Kremer and Holla (2009)は、彼らの試験において、就学率が少額の補助金に驚くほど敏感であることを指摘している。これは、学校に通うか通わないかの(経済的な)境界線上にいる多くの生徒や親がいるためであると示唆している。また、セクション3.3の最後で述べたように、新しい目標設定でもこの同じメカニズムが働くことを知っておく必要がある。
第三に、因果構造を明確にする必要がある。そのためには、モデルの構築やRCTの支持者が納得する以上の仮定が必要となる。私たちは何か、何らかの規則性や不変性を必要としており、そのようなものは単に試験を一般化することではほとんど回復できない。はっきり言って、因果構造のモデル化は、経済学における構造モデル化の特徴である、精巧でしばしば信じられないような仮定を約束するものではないが、物事がどのように機能するかについて考えることから逃れることはできない。
第4に、再重み付けや層別化のためにこれらの技術を使用するには、RCT自体の結果よりも多くのことを知る必要がある。例えば、社会的、経済的、文化的な構造の違いや、原因となる変数の共同分布についてなど、多くの場合、観察研究を通してのみ得られる知識が必要である。また、RCTに登録された集団の有益な特徴を決定するためには、理論的および経験的な外部情報が必要となる。なぜなら、その集団がどのように記述されているかは、他のどの集団が同様の結果をもたらすかを示す何らかの指標となると一般的に考えられているからである。
多くの医学・心理学雑誌はこのことを明確にしている。例えば、International Committee of Medical Journal Editors(ICMJE)が推奨する投稿規定(2015, 14)では、論文要旨に 「観察または実験参加者(対照群を含む健常者または患者)の選択について、適格性および除外基準、ソース集団の説明を含めて明確に記述すること」と主張している。RCTは、特定の個人の集団から何らかの方法で抽出された特定の試験サンプルに対して実施される。得られた結果は、そのサンプル、その時点での特定の個人の特徴であり、例えば、試験サンプルが満たす無限の記述の1つを満たすかもしれない、異なる個人を持つ他の集団ではない。ICMJEのアドバイスに従うことで、試験集団から他の集団への正当な外挿(単純または調整済み)を行う場合、試験集団の記述子を正しく選択しなければならない。我々が論じたように、これらの記述子は、同じ形式の式(4)が成り立ち、2つの母集団における関連因子の正味の効果についてほぼ同じ平均値(または調整方法がわかっている平均値)を持つ母集団を選ばなければならない。
この同じ問題は、研究デザインにおいてもすでに直面している。成果報酬型の事後評価のような特殊なケースを除けば、私たちは試験に登録された非常に多くの個人について知ることに特に関心はない。ほとんどの実験は、その結果が他の集団について何を学ぶのに役立つかを念頭に置いて実施され、またそうすべきである。これは、何が研究結果の生成に関連するか、また何が関連しないかについての実質的な仮定なしにはできない。つまり、知的な研究デザインも、研究結果の責任ある報告も、その背景にはかなりの仮定が必要なのである。
もちろん、これはすべての研究に当てはまることである。しかし、RCTを実施するためには特別な条件が必要であり、特に成功させるためには、例えば、現地での合意、遵守する被験者、手頃な価格の管理者、複数の盲検化、結果を確実に測定・記録する能力のある人、無作為割当が道徳的・政治的に許容される環境などが必要であるが、観察データは多くの場合、より容易にかつ広く利用可能である。RCTの場合、このような配慮が効きすぎてしまう危険性がある。特に、試験サンプルが持つべき特徴が正当化されず、明確にされず、真剣な批判的レビューを受けていない場合には、この点が懸念される。
観察的知識の必要性は、RCTがゴールドスタンダードであると主張したり、あるカテゴリーのエビデンスを他よりも優先すべきであると主張することが逆効果である多くの理由の1つである。このような戦略では、本来の文脈を超えてRCTを使用する際に、私たちは無力になってしまう。RCTの結果は、それが構築された文脈の外で使用できるようにするためには、政策立案者の実践的な知恵を含む他の知識と統合されなければならない。
医学界や経済学界の多くの慣行とは異なり、RCTと観察結果の間の矛盾は、例えば、それぞれで研究された異なる集団の異なる特性を参照することによって説明される必要がある。RCTの有効性は、観察研究が異なる答えを見つけた理由を理解するのに役立つことがあるが、観察研究がRCTではないので無効であるに違いないという理由だけで、観察研究を否定する一般的な慣行には根拠(または言い訳)がない。科学の進歩の基本的な考え方は、知識が増えれば増えるほど、新しい発見はそれまでの結果、たとえ今では無効と考えられている結果であっても、それを説明し、統合することができなければならないということである。
3.6. 理論の構築と検証のためのRCTの使用
RCTの結果は、確立された科学的主張と同様に、おなじみの仮説演繹的な方法で理論を検証するために使用することができる。
例えば,(Banerjee er al 2015a) は,極貧層の人々を貧困から恒久的に救うための「卒業」プログラムをテストしている.このプログラムでは,生産的資産(モルモット,(通常の)豚,羊,ヤギ,鶏の中から地域に応じたもの)の贈与,訓練と支援,生活技能の指導,消費・貯蓄・保健サービスの支援を行うことで,極貧層の人々を貧困から恒久的に救うことを目的としている.このプログラムは、1回の介入では不可能な、貧困の罠からの脱却を支援するものである。このプログラムの比較可能なバージョンは、エチオピア、ガーナ、ホンジュラス、インド、パキスタン、ペルーでテストされ、ホンジュラス(鶏が死んでしまった)を除いて、さまざまなアウトカム(経済、心身の健康、女性のエンパワーメント)について、同様の(標準化された)効果の大きさで、おおむね肯定的で持続的な効果が認められた。1つのサイトでは、基本的に全員が割り当てを受け入れた。このような広範囲の場所でポジティブなATEを再現することは、確かにこのようなスキームのコンセプトを証明するものである。しかし、(Bauchet et al 2015)は南インドでの結果を再現することができず、対照群はほぼ同じ利益を得ることができた。(Heckman et al 2000)はこれを「代替」バイアスと呼んでいる。それでも、この結果は重要である。というのも、貧困の罠には長年の関心があるものの、多くの経済学者はその存在を懐疑的に見ており、また、このような援助に基づく政策によってその罠が破られる可能性があると考えてきたからである。この意味で、本研究は経済発展の理論に重要な貢献をしている。理論的な命題を検証し、それについての考え方を変えることになる(はずだ)。
経済学者は、初期の実験以来、理論と無作為化比較試験をさまざまな形で組み合わせていた。試験は、理論の構築と検証に役立ち、理論は、試験結果の単純な外挿や一般化では答えられない新しい環境や集団に関する疑問に答えることができる。ここでは、理論と結果の相互作用がどのように機能するかを示すために、いくつかの経済学的な例を紹介する。
Orcutt and Orcutt (1968)は、労働供給に関する単純な静的理論を用いて、所得税の試行を行うきっかけを作りました。これによると、人々は、働かない場合には最低限のGを受け取り、働く場合には1時間ごとに(1-t)wを追加で受け取るという環境の中で、仕事と余暇の間で自分の時間をどのように分割するかを選択する。この試験では、異なるグループに異なるGとtの組み合わせを割り当てることで、労働供給関数を追跡し、選好のパラメータを推定することができた。これにより、例えば、労働者の効用損失を最小限に抑えて収入を上げるなど、幅広い政策計算に利用することができた。
このような初期の試みに続いて、一般的に使用される構造モデルを適合させるために、試行のために収集されたベースラインデータとともに試行結果を使用するという伝統が続いている。初期の例としては、労働供給に関するMoffitt (1979)や住宅に関するWise (1985)があり、最近の例としては、Perry就学前教育プログラムに関するHeckman et al (2013)がある。開発経済学の例としては、(Attanasio et al 2012, Attanasio et al 2015, Todd and Wolpin, 2006, Wolpin, 2013, and Duflo er al 2012)がある。これらの構造モデルは、時として関数形や非観測変数の分布に関する手ごわい補助的な仮定を必要とするが、理論と証拠の統合、サンプル外の予測、厚生の分析が可能であること、RCTの証拠を使用することで、同定に必要な仮定の少なくとも一部を緩和することができることなど、補償的な利点がある。このように、構造モデルはRCTから信頼性を借り、その代わりにRCTの結果を首尾一貫したフレームワークの中で設定するのに役立つ。このような解釈がなければ、RCTの結果の福祉への影響は問題になることがある。ある政策に対して人々が一般的にどのように反応するかを知るだけでは、人々がより良くなるかどうかを知るには十分ではない。伝統的な福祉経済学では、選好から行動へのリンクを描いている。このリンクは、構造的な研究では尊重されているが、「何が効果的か」という文献では失われていることが多く、これがなければ行動から福祉を推測する根拠がない「何が効果的か」は「何があるべきか」と同じではない。
単純な理論であっても、RCTの結果を解釈し、拡張し、利用するために多くのことができる。ランドの健康実験と負の所得税の実験では、短期的な反応と長期的な反応の違いが当面の問題となった。健康と税のRCTは、消費者や労働者が恒常的に価格や賃金の上昇や低下に直面した場合に何が起こるかを明らかにすることを目的としているが、実験は限られた期間しか実施できない。収入に対する一時的な高税率は、事実上、余暇に対する「特売」であるため、実験では、休暇を取って後で収入を補う機会が与えられ、恒久的な制度では得られないインセンティブが得られたのである。では、実験で得られた短期的な反応から、知りたい長期的な反応を得るにはどうすればよいのであろうか。Metcalf (1973)とAshenfelter (1978)は所得税の実験について、Arrow (1975)はRandの健康実験について、それぞれ答えを出している。
Arrowの分析は、構造データと観測データの両方を使用し、ある設定での結果を組み合わせて別の設定での結果を予測する方法を示している。彼は、健康実験を、第1期のみ医療費が引き下げられる2期モデルとしてモデル化し、求めるもの、すなわち、第1期と第2期で同じ割合で医療費が引き下げられた場合の第1期の反応を導き出す方法を示している。求める大きさは、第1期と第2期の両方で「および」が同じように増加した場合の、第1期の医療の補償付き価格微分値であるSである。これは、2つの価格に対する第1期の需要の微分の総和であるSに等しい。しかし、治療者と対照者の両方の医療サービスに関する試験後のデータがあれば、実験的な価格操作が実験後のケアに与える影響を、「」と推測することができる。選択理論では、Slutsky対称性の形で、「それでArrowはSを推測できる」としている。これに対して、Metcalfの代替案では、「2期間の選好は一時的に加法的である」という異なる仮定を置いている。この場合、長期弾性値は、実験後の医療の所得弾性値の知識から得られるが、これは観察分析から得られるものでなければならない。
これらの2つの代替アプローチは、仮定を立てる意思と手持ちのデータに基づいて、試験結果を適応して利用するために、(初歩的で透明性のある)理論的仮定と観察データの適切な組み合わせをどのように選択できるかを示している。このような分析は、一時的な治療の結果を利用して必要な永続的効果を推定するために何を知る必要があるかを明確にすることで、最初の臨床試験の設計にも役立つ。Ashenfelter氏は、3つ目の解決策として、2期間モデルは2人モデルと形式的には同じであるため、2人の労働供給に関する情報を利用してダイナミクスを知ることができると指摘している。ランドのケースでは、短期的な反応と長期的な反応が実際にはあまり変わらなかったことを内部的な証拠が示しているが、アローの分析は、理論がどのようにして「得られるもの」から「望むもの」への橋渡しをすることができるかを示している。
理論は、新しい状況や未知の状況を、すでに背景知識がある状況に類似したものとして再分類することを可能にする。経済学では、新しい政策を、回答者が直面している価格や収入の変化と同等のものとして捉え直すことができる場合に、このような方法がよく用いられる。新しい政策の影響は、その影響がよく理解され、よく研究されている所得や価格の変化に相当するものに置き換えることができれば、予測が容易になるかもしれない。Todd and Wolpin (2008)とWolpin (2013)がこの点を指摘し、例を挙げている。労働供給のケースでは、税率の上昇は賃金率の低下と同じ効果があるため、税率を変更した場合に何が起こるかを予測するには、過去の文献に頼ることができる。メキシコの条件付現金給付プログラム「PROGRESA」の場合、ToddとWolpinは、子供が学校に行った場合に親に支払われる補助金は、子供の賃金の減少と親の所得の増加の組み合わせと考えることができ、限られた追加の仮定で条件付現金実験の結果を予測することができると指摘している。彼らの分析で部分的にそうなっているように、これがうまくいけば、この実験はこれまでの知識を整理し、進化しつつある理論と、実験を含む実証的な証拠に貢献することになる。
政策の変化を価格や所得の変化と同等に考えるというプログラムは、経済学では長い歴史があり、合理的選択理論の多くはこのように解釈することができる(多くの例については、Deaton and Muellbauer (1980)を参照)。この変換が信頼できるものであれば、また、一見無関係なテーマの裁判を価格や所得の変化と同等にモデル化でき、異なる環境にいる人々が価格や所得の変化に同様に反応すると仮定できる場合には、裁判の結果を既存の知識に組み込むだけでなく、裁判の結果を拡張して他の場所で使用するためのすぐに使えるフレームワークを手に入れることができる。もちろん、すべては理論の妥当性と信頼性にかかっている。人々は実際には増税を余暇の価格の低下として扱うことはないかもしれないし、行動経済学には、一見同等の刺激が非同等の結果を生み出す例がたくさんある。現世代の研究者の多くが行動経済学を受け入れていることは、従来の選択理論をこのような形で使用することにあまり積極的でないことの説明になるかもしれない。残念ながら、行動経済学は、この点で非常に有用な選択理論の一般的な枠組みに代わるものをまだ提供していない。
理論は、第2節のまとめで提起した、治療群に無作為に割り振られた人々が治療を拒否する可能性があるという問題にも役立つ。理論が十分に優れていて、治験参加者がコンプライアンスの根拠とするであろう利益と損失をどのように表現すべきかを示すことができれば、分析によって、治験の推定値を我々が知りたいと思うものに調整することができる場合がある。
3.7. スケールアップ:母集団の平均値を利用する
多くのRCTは小規模でローカルなものであり、例えば、特定の地理的、文化的、社会経済的な環境にあるいくつかの学校、診療所、農場などで行われる。例えば、費用対効果の基準に照らして成功した場合は、スケールアップの候補となり、同じ介入策をより広い地域、多くの場合は国全体、場合によってはそれ以上の地域に適用することになる。スケールアップでも試験と同じ結果になると予測することは、単純な外挿のケースである。しかし、特別な問題が生じる可能性があるため、別途議論する。介入が規模に応じて異なる働きをする可能性があるという事実は、経済学の文献で古くから指摘されており、例えば、Garfinkel and Manski, 1992, Heckman, 1992, and Moffitt (1992)などがあり、Banerjee and Duflo (2009)による最近のレビューでも認められている。
人と人との間の生物学的相互作用は、社会科学における社会的相互作用に比べてあまり一般的ではないが、医学においては、依然として重要な意味を持つ。感染症がその例で、予防接種プログラムが集団免疫を通じた疾病伝播のダイナミクスに影響を与えている(Fine and Clarkson 1986)と(Manski 2013, 52)を参照)。社会的・経済的環境は、医薬品が実際にどのように使用されるかにも影響し、同様の問題が生じる可能性がある。臨床試験における有効性と効果の区別は、この事実を認識している部分もある。ここでは、このような効果が広く存在することを強調するとともに、RCTの使用に反対する論拠としてではなく、規模に応じた効果が臨床試験と同じである可能性が高いという考えに反対するだけであることを再度指摘したいと思う。
「一般均衡効果」と呼ばれるものの例として、農業が挙げられる。例えば、あるRCTで、新しい肥料の使い方が、例えばカカオの収穫量にかなりのプラスの効果があることが実証され、新しい方法を使った農家は、対照群に比べて生産量と収入が増加したとする。この方法を国全体、あるいは世界中のココア農家に拡大すれば、価格は下がり、少なくとも短期的には、通常考えられているように、ココアの需要が価格非弾力的であれば、ココア農家の収入は減少する。実際、多くの作物では、農家は収穫量が多いよりも少ない方が良いという常識がある。この場合、スケールアップ効果は試行効果とは逆の符号になる。問題はトライアルの結果にあるのではなく、トライアルで推定された反応を組み込んだ、より包括的な市場モデルに有用な形で組み込むことができる。問題は、集合体が個人に似ていると仮定した場合にのみ生じる。集計モデルの他の要素が観察研究から得られなければならないことは、RCTを支持する人にとっても批判すべきことではない。
需要や供給を変化させる可能性のある介入は数多くあり、その効果は全体として、最初のRCTで一定に保たれていた価格や賃金を変化させることになる。実際、労働供給を含む人々の需要や供給の量を変化させる試験は、論理的な問題として、新しい需要を満たしたり、新しい供給に対応したりしなければならないため、他の人々に影響を与えなければならない。Rubin因果モデルの言葉を借りれば、これはSUTVA(安定した単位治療価値の仮定)の失敗である。もちろん、1つ1つのユニットは小さすぎて、それだけでは知覚できるほどの効果はないかもしれない。そのため、SUTVAは試験では高度な近似性を保っているが、いったん集団に集約すると、その効果は試験の結果を修正したり、逆転させたりするのに十分な大きさになることが多いのである。例えば、教育によって熟練労働者と非熟練労働者の供給が変化し、相対的な賃金率に影響を与えることがある。条件付現金給付は、学校や診療所の需要(おそらく供給)を増加させ、価格や待機列、あるいはその両方を変化させる。規模でのみ作用する人々の間の相互作用がある。一人の子供に私立学校に通うためのバウチャーを与えることで、その子の将来を向上させることができるかもしれないが、全員にそうすることで、公立学校に残された子供たちの教育の質が低下する可能性がある(Angrist er al)。(2002)とHsieh and Urquiola(2006)の対照的な研究を参照)。Crépon et al 2014)は、この問題を認識し、RCTを適用して対処する方法を示している。
経済学の多くは均衡の分析に関係しており、最も明らかなのは需要と供給の均衡である。複数の因果関係のメカニズムは、価格などの変数を調整することで調整される。RCTは、平衡化する変数が一定である場合に、1つまたは他のメカニズムを分析するのに役立つことが多く、それらのRCTの結果は、政策の平衡効果を分析・予測するのに利用できる。しかし、政策を実施した結果は、上記のココアの例のように、トライアルの結果とは全く異なるものになることが多い。よく言われるように、経済学が均衡の分析を目的としているのであれば、RCTの結果を単純に外挿することはほとんど意味がない。私たちは、分析や予測における経済モデルの成功を主張しているわけではないことに注意してほしい。しかし、均衡の分析は、論理的一貫性の問題であり、これがないと矛盾した命題が残ることになる。
3.8. ドリルダウン:個人に対する平均値の使用
スケールアップに問題があるように、RCTの結果を個々のユニット、たとえ試験に含まれた個々のユニットのレベルでどのように使用するかは明らかではない。適切に実施されたRCTでは、試験対象者のATEが得られるが、一般的には、その平均値がすべての人に当てはまるわけではない。例えば、American Medical AssociationのUsers’ guide to the medical literatureで主張されているように、「患者が試験に参加していたら登録されていたであろう場合、つまり、彼女がすべての組み入れ基準を満たし、どの除外基準にも違反していない場合、結果が適用可能であることにほとんど疑問はない」というのは真実ではない(Guyattら(1994, 60)参照)。さらに誤解を招くのは、平均治療効果がゼロと有意に異なるRCTが、その治療法が誰にも効かないことを示しているという、よく耳にする発言である。
このような問題は、エビデンスに基づく医療を実践している医師にとっては馴染み深いものであり、そのガイドラインでは、「個人の臨床的専門知識と、系統的研究から得られる最良の外部臨床証拠とを統合する」ことが求められている(Sackettら(1996, 71))。これが何を意味するのか正確には不明である。医師は、RCTから得られるATEで許容されるよりもはるかに多くのことを患者について知っているし(ただし、繰り返しになるが、臨床試験での層別化は役立つ可能性が高い)長年の診療から得られる直感的な専門知識を持っていることが多く、それによって特定の患者の特徴を特定し、その患者に対する所定の治療法の有効性に影響を与えることができる(Horwitz (1996)参照)。しかし、ここでは奇妙なバランスがとられている。これらの判断は、個々の患者との話し合いの中では認められると考えられるが、ほとんどのEBMサイトで採用されている基準では、信憑性についての通常の注意を払った上で、一般に公開されるべき証拠にはならないのである。また、医師が偏見や知識を持っている場合があることも事実である。明らかに、個々の患者にとっても、開業医に平均値に従わせることがより良い結果をもたらす状況と、その逆の状況がある(Kahneman and Klein (2009)参照 Horwitz et al 2017)は、医療行為はエビデンスに基づく医療から、すべての個別症例の履歴を集めて照合し、RCTの平均値から逸脱する根拠とするメディシンベースのエビデンスと呼ぶものに移行すべきだと提案している。
平均値が個人にとって有用であるかどうかは、社会科学の研究においても同じ問題がある。St. Joseph’sとSt. Mary’sという2つの学校を想像してみてほしい。この2つの学校は、ある授業改革のRCTに含まれてた。そのイノベーションは平均して成功しているが、学校はそれを採用すべきであろうか?St Mary’sは、St Joseph’sでの以前の試みが失敗と判断されたことに影響されるべきであろうか?多くの人は、この経験を逸話として片付け、「厳密な」証拠がないのに、どうしてSt Joseph’sが失敗だとわかったのかと問うであろう。しかし、もしSt Mary’sがSt Joseph’sと同じように、同じような生徒構成、同じようなカリキュラム、同じような学力を持っているのであれば、St Joseph’sの経験はRCTから得られるポジティブな平均値よりもSt Mary’sで起こりうることに関連しているのではないだろうか?St Mary’sの教師とガバナーがSt Joseph’sに行き、何が起こったのか、なぜ起こったのかを知ることは良いアイデアではないであろうか?彼らは、失敗のメカニズムを観察し、同じ問題が自分たちにも当てはまるかどうか、あるいは技術革新を適応させて自分たちにもうまくいくかどうか、もしかしたら試験の正平均値よりもうまくいくかもしれないかどうかを見極めることができるかもしれない。
繰り返しになるが、これらの質問には実際には簡単に答えられないであろう。しかし、輸出可能性と同様に、試してみることは重大な選択肢ではない。平均値がうまくいくと仮定することは、多くの場合、間違っているであろうし、少なくとも時々は、より良い方法をとることができるであろう。例えば、理論の賢明な使用、類推による推論、プロセスの追跡、メカニズムの特定、サブグループ分析、あるいは、Hill (1965)のように、因果関係の経路が可能な様々な症状を認識することによってですある(Cartwright, 2015, Reiss, 2017, Humphreys and Jacobs (2017)も参照してほしい)。医療の場合と同様に、個々の学校へのアドバイスは具体性に欠けることが多い。例えば,米国教育科学研究所は,厳密なエビデンスに裏付けられた実践方法を「ユーザーフレンドリーな」ガイドとして提供している(米国教育省,2003)。そのアドバイスは、エビデンスに基づく社会政策や健康政策の文献にある推奨事項と同様で、介入は、複数の施設での十分にデザインされたRCTによって効果的であることが実証されるべきであり、「試験は、あなたの学校に似た学校環境での介入の効果を実証すべきである」というものである(2003, 17)。なお、「類似」の運用上の定義は示されていない。
4. 結論
医学と社会科学の2つの課題に答えることは有益である。医学的な課題は、「もしあなたが新しい薬を処方されるのであれば、それがRCTを経たものであってほしいと思わないか?2つ目の課題は、「RCTの問題点を指摘されたが、他の方法にもそれらの問題点があり、さらに独自の問題点もあるのではないか 」というものである。私たちは、論文の中でこの2つの問題に答えたと考えているが、再確認しておくと役に立つ。
医学的な課題は、特定の人であるあなたに関するものである。つまり、一つの答えは、あなたは平均的な人とは異なる可能性があり、あなたには、それがあなたのためになるかどうかについての理論と証拠を求める権利があり、またそうすべきであるということである。これは、あなたと、あなたのことをよく知っている医師との間で交わされる会話のようなものである。あなたは、このクラスの薬がどのように作用すると考えられているのか、そしてそのメカニズムがあなたに作用する可能性があるのかを知りたいであろう。他の患者さん、特にあなたのような症状や状況の患者さんからのエビデンスがあるのか、それとも理論からの示唆があるのか。この種の薬剤で成功するためには、どのようなサポート要因が重要であるかを特定するために、どのような科学的研究が行われているのであろうか?もし、結果に何らかの影響を与えているかもしれない製薬会社からの情報しかないのであれば、RCTを行うことは良いアイデアだと思えるかもしれない。しかし、たとえそうであっても、あるグループの平均的な効果を知ることは確かに価値があるが、試験で選択された方法で参加者が選択されているRCTや、結果が自分に関連しているかどうかについての情報がほとんどないRCTは、ほとんど重視しないかもしれない。多くの新薬が、試験されていない目的のために「適応外」で処方されていることを思い出してほしい。さらに言えば、多くの新薬がRCTのないところで投与されているのは、あなたが実際にRCTに登録されているからなのである。新薬の臨床試験に参加することが最後のチャンスである患者さんにとっては、まさにこのような会話を主治医と交わすべきであり(続いて主治医に、自分が有効成分群に入っているかどうかを明らかにしてもらい、入っていない場合には切り替えられるようにしてもらう)このような会話は、あなたにとって新しい処方箋のすべてについて行う必要がある。このような会話の中では、RCTの結果はわずかな価値しかないかもしれない。もしあなたの主治医が、エビデンスに基づく医療を支持し、RCTが「効く」と示したからその薬があなたに効くと言うなら、あなたと平均値が同じではないことを知っている主治医を探すべき時である。
2つ目の課題は、他の方法は常にRCTに支配されているという主張である。それは、ある査読者がチャーチルの言葉を引用して私たちに挑戦したように、「RCTは、他の方法と比較した場合を除き、恐ろしいものである 」ということだ。私たちは、この挑戦は十分な形ではないと考えている。どのような質問に、どのような目的で答えるために支配されているのか?RCTの主な利点は、適切に実施されていれば、研究(試験)サンプルにおけるATEの偏りのない推定値を得ることができ、その結果、治療法がサンプル内の一部の個人に結果をもたらしたという証拠を提供できることである。「十分に実施された」ということは、損耗、意図的な盲検化の欠如または意図的な盲検化の解除、その他の無作為化後の交絡および選択バイアスなど、実際にはほとんど常に起こることをすべて除外することに注意してほしい(Hernán er al2013を参照)。ATEの偏りのない推定が必要で、利用可能な背景知識がほとんどなく、価格が適切であれば、RCTが最良の選択となるかもしれない。他の質問に関しては、RCTの結果は、(a)一般的な主張、(b)治療法が他の何人かの人にその結果を引き起こすという主張、(c)他の集団におけるATEがどうなるかという主張、あるいは(d)RCTの結果が検証しているのとは全く異なる何かについての主張の一部になり得るが、通常はごく一部に過ぎない。しかし、それだけではこれらの事業にはほとんど役立たない。これらの問題に取り組むための研究活動の全体的なパッケージとして、最も費用対効果が高く、正しい結果が得られる可能性が高いものは、我々が知っていることや、さまざまな種類の研究にかかる費用によって異なる。
RCTが観察研究よりも優れている例があり、RCTを擁護する人はこのような例を思い浮かべるようである。例えば、メディケイドに加入している人が民間保険に加入している人よりも良いか悪いかという回帰分析は、2つの集団の他の特性の大きな違いによって無効になってしまう。しかし、RCTが問題を解決できることは言うまでもなく、RCTが問題を解決する唯一の方法であることを言うには、そこから長いステップが必要である。RCTは被験者一人当たりのコストが高いだけでなく、選択された、ほぼ確実に代表性のない研究サンプルしか登録できず、一時的にしか実施できず、実験への参加者の募集は、恒久的で有資格者全員に開かれた計画での参加者の募集とは必然的に異なることになる。試験に参加した被験者は、治療自体が盲検化を妨げているため、あるいは副作用やプロトコルの違いによって、自分が治療群にいるかどうかを知ることになるだろう。いずれにしても、観察研究の欠点を取り除くことはできないが、その困難さを軽減する方法は数多くある。そのため、最終的には、信頼性の高い補正を行い、より関連性の高い、はるかに多くの研究サンプル(今日では、盲検化や選択の問題が存在しない行政記録を通じて対象となる全人口を対象とすることが多い)を用いた観察研究が、より良い推定値を提供することができる。
医学界は、因果推論の他の信頼できる方法を取り入れるのが遅く、消極的なようである。Academy of Medical Sciences(2017, 4)は、医療の有効性と効果に関するエビデンスのソースをレビューした中で、“エビデンスの種類と、そのエビデンスを分析するために必要な方法は、問われている研究課題に依存する “という点で我々に同意している。しかし、道具変数、計量経済学的モデリング、理論からの推論、因果ベイジアンネット、プロセストレーシング、質的比較分析など、社会・経済科学で広く用いられている手法については言及していない。これらの手法にはそれぞれ長所と短所があり、因果関係の推論が可能であるが、すべての手法で効果の大きさを推定できるわけではない。また、どの手法でもそうであるが、因果関係の結論を導き出すためには、カジュアルな背景知識をインプットする必要がある。しかし、盲検化が進み、RCTのコストが増加している中で、これらを利用しないのはもったいないことである。すべてはケースバイケースで判断しなければならない。RCTを辞書的に優先する正当な議論はない。
また、RCTだけでなく、RCTや回帰、あるいは制御された、あるいは制御されていない比較のあらゆる形態に共通する「差異の方法」を超えた、重要な探求の一線がある。仮説演繹法は、理論に基づいた推論を、観察的または実験的なデータと対峙させるものである。先に述べたように、経済学者は日常的に理論を用いて、データに反映させることができる新たな意味合いを導き出しているが、医学においても良い例がある。Bleyer and Welch (2012)は、マンモグラフィー検診の効果が限定的であることを示している。これは、RCTが20~30年前のものであり、急速に変化している現在の環境に比べて時代遅れであるという理由だけで、優柔不断で論争の的となっているテーマです(Marmot et al 2013)参照)。このような仮説演繹法の使用は、通常意味すると思われる「観察研究」とは異なり、交絡因子のコントロールに疑問がある状態で群を比較するものであり、不十分であるにもかかわらず無作為化の方が間違いなく優れている。
RCTは、異質性、因果構造、変数の選択、関数形に関する仮定が非常に少ないため、試験サンプルにおける平均治療効果をノンパラメトリックに推定する究極の方法である。RCTは、実験者が制御する分散を導入するための便利な方法であることが多い。何が起こるかを見たいなら、蹴って見て、ライオンの尻尾をねじってみよう。しかし、経済学で最も重要な(そしてノーベル賞を受賞した)実験の多くを含む多くの実験は、無作為化を使用していないし、使用していなかったことに注意してほしい(Harrison, 2013, Svorencik, 2015を参照)。しかし、結果の信頼性は、内部的にも、不均衡な共変量や回答の過度な異質性によって損なわれる可能性があり、特に効果の分布が非対称である場合には、平均値での推論は危険を伴う。皮肉なことに、RCTにおける信頼性の代償は、治療効果の分布の平均値しか回復できないことであり、それも試験サンプルについてのみである。しかし、治療効果や共変量に外れ値がある場合、平均値の信頼できる推論は困難である。実験集団への意図的な選択は、割り付けへの意図的な選択や割り付けからの意図的な選択と同様に、観察研究における選択と同じように、推論を弱める。被験者、治験責任医師、データ収集者、分析者のいずれに対する盲検化の欠如は、道具変数分析における除外制限の失敗と同様に、推論を弱める。
RCTの結果を、プログラム評価、仮説検証、概念実証など、いくつかの文脈以外で使おうとすると、構造の欠如は深刻な障害となる。それ以外にも、より多くの構造、より多くの事前情報、そして治療効果を場所や時間によって変化させる要因についての何らかのアイデアがなければ、結果を試験サンプルを超えた予測に役立てることはできない。RCTの証拠を元の文脈から離れてどのように使用するかを知るためには、何らかの因果構造にコミットする以外に選択肢はない。単純な一般化や単純な外挿では意味がない。これは、実験的、観察的を問わず、どのような研究にも言えることである。しかし、観察研究は、RCTが避けると主張する(しかしそうではない)仮定のようなものに慣れ親しんでおり、日常的に取り組んでいる。そのため、経験的な証拠を使用することを目的とする場合、RCTが推定上持っている信頼性の優位性はもはや機能しない。また、RCTはなぜ結果が出るのかということをほとんど教えてくれないので、メカニズムを解明するために幅広い事前情報やデータを利用する研究に比べて不利になる。
しかし、このようなコミットメントがなされると、RCTの証拠は、構造の一部を明らかにし、より強い理解と知識を構築し、福祉的な結果を評価するのに非常に役立つ。私たちの例が示すように、これはしばしば構造モデルとして考えられているような完全な複雑さにコミットすることなく行うことができる。しかし、RCTの結果を文脈の中に置き、その結果の背後にあるメカニズムを理解することを可能にする構造がなければ、他の場所で「それがうまくいく」かどうかを輸送することができないだけでなく、経済学の標準的なタスクの1つである、介入が実際に福祉を改善しているかどうかを言うこともできない。なぜ物事が起こるのか、なぜ人々は物事を行うのかを知らなければ、価値のないカジュアルな(「おとぎ話」のような)因果関係の理論化を行う危険性があり、経済学やその他の社会科学の中心的な課題の一つを放棄していることになる。
私たちは、理論化を拒否したり、無限の異質性を扱う能力に酔いしれたりするのをやめて、実際に何かを言わなければならない。逆説的かもしれないが、仮定を立て、知っていることを言い、一部の人には信じられないような発言をする覚悟がなければ、RCTの信頼性はほとんど意味がない。
付録 外れ値を含むRCTのモンテカルロ実験
この例では、各メンバーがそれぞれの治療効果を持つ親集団がある。これらは、母集団のATEがゼロになるように、平均がゼロのシフトした対数正規分布で連続的に分布している。個々の治療効果は、標準化された対数正規分布で次のように分布する。治療がない場合,サンプルの全員がゼロを記録するので,任意の1つの試験におけるサンプル平均治療効果は,単にn個の治療の平均結果である.nの値が25,50,100,200,500の場合、親集団から 2nの大きさの100個の試験サンプルを抽出する。これらの500個のサンプルのそれぞれについて、n個の対照とn個の治療に無作為に分け、ATEとその推定t値を推定し(標準的な2標本のt値を使用するか、または同等に、ロバストなt値で回帰を実行する)それを1000回繰り返すことで、500個の試験サンプルのそれぞれについて1000個のATE推定値とt値が得られる。これにより、各試験のATE推定値とその公称t値の分布を評価することができる。
その結果を表A1に示する。各行はサンプルサイズに対応している。各行には,100個の試行(実験)サンプルのそれぞれについて1000回の再現からなる100,000回の個々の試行の結果を示している.列は,100,000回の試行の平均値である.
表A1. 治療効果が歪んでいるRCT
| サンプルサイズ | ATE 推定値の平均 |
公称t値の平均 | 分数nullが拒否されました(パーセント) |
|---|---|---|---|
| 25 | 0.0268 | −0.4274 | 13.54 |
| 50 | 0.0266 | −0.2952 | 11.20 |
| 100 | −0.0018 | −0.2600 | 8.71 |
| 200 | 0.0184 | −0.1748 | 7.09 |
| 500 | −0.0024 | −0.1362 | 6.06 |
注:平均がゼロになるようにシフトされた治療効果の対数正規分布から無作為に抽出された試行サンプルの100回の抽選ごとに1000回の無作為化を行った。
最後の列は、母集団では真である帰無が試行サンプルでは棄却される割合を示しており、これが重要な結果である。治療法が50個、コントロールが50個しかない場合(2行目)(真の)帰無が棄却される割合は11.2%であり、問題を知らない場合に期待する5%ではない。各アームに500個のユニットがある場合、棄却率は6.06%で、公称の5%にかなり近い値になる。
図A1. トライアルサンプルに異常値がある場合のATEの推定値
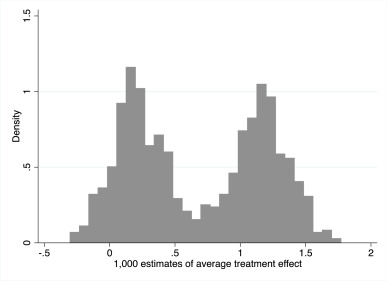
図A1は、2行目のシミュレーションからの極端なトライアルサンプルからのATEの推定値を示しており、ヒストグラムはそのトライアルサンプルのATEの1000個の推定値を示している。このトライアルサンプルには、48.3の大きな外れた治療効果が1つあり、他の99個のオブザベーションの平均(s.d.)は-0.51(2.1)で、外れ値が治療群にあるときは右回りのオブザベーションが得られ、対照群にあるときは左回りのオブザベーションが得られる。