
Injecting some numbers into the AGI debate
日日 〜ボアズ・バラク
[またもや「哲学的」な記事だが、実際の数字がいくつかある。このフォローアップも見てほしい。-ボアズ]
最近、「人工知能」(AGI)について、現在のAIシステムをスケールアップすることで実現に近づけるかどうかという議論が盛んに行われている。今回は、この議論をもう少し定量的なものにするために、「スケールアップ」とはどのようなものかを理解してみたいと思う。計算は非常に大雑把で、封筒の裏に貼られたポストイットをイメージしてほしい。しかし、これが少なくとも、この問題をより具体的にするための出発点になればと思う。
第一の問題は、「人工知能」とは何かということについての合意がないことである。人々はこの言葉を、次のような可能性の間のものを意味するものとして使っているのだ。
- SATやIQテストで満点を取り、「チューリングテスト」に合格するようなベンチマークを満たすことができるシステムの存在。これは、Metaculus社が使用している定義とほぼ同じだ(ただし、最近より厳しいバージョンに更新された)。
- 経済的生産性において、多くの人間を代替することができるシステムの存在。具体的には、多くの産業において、平均以上の労働者として機能することができるとする。(ロボットの問題を回避するために、遠隔操作のみの仕事に限定してもよい)。
- AIの大規模な展開、大きな割合の人々の仕事内容を置き換えたり、根本的に変えたりすること。
- 意識、悪意、超知能など、より極端なシナリオ。例えば、人権と自分の弁護士を与えられるほど意識・感覚のあるシステムや、インターネットからDNAを取り寄せたり、ナノ工場を作ってミニチュアロケットに乗ったダイヤモンド型細菌を作り、全人類の血流に入り、検出されないようにしながら全員を即死させるほど悪意のあるシステムなどである。
私は、最初のシナリオ、すなわちIQテストやチューリング・テストに合格することは、実際の知能というよりも「パーラー・トリック」だと考えている。人工知能の歴史は、特定のベンチマークにおける将来の成果を過小評価するものだが、同時にそれらのベンチマークが持つ幅広い意味を過大評価するものでもある。初期のAI研究者たちは、コンピュータ・プログラムがチェスの世界チャンピオンになるまでにかかる時間について間違っていただけでなく、そのようなプログラムは一般的に知的でなければならないとも間違って想定していたのである。1970年のインタビューでミンスキーは、1970年代の終わりまでに「平均的な人間の一般的な知能を持った機械ができるだろう…シェークスピアを読むことができ、車に油を差し、政治を行い、冗談を言い、喧嘩をすることができる」と述べたことが引用されている。
「その時、機械は素晴らしいスピードで自己啓発を始めるだろう。効率、コスト削減、反応の速さのために、国防総省はますます人間の軍事政策の指揮を機械に委ねざるを得なくなるかもしれない」
ブルックスは、初期のAI研究者たちは、知能とは「高学歴の男性科学者がやりがいを感じるものとして最もよく特徴づけられる」と考えていたと説明している。チャンピオン・レベルのチェスをするのは彼らにとって難しいので、もっとつまらないと思っていた他のすべての作業をせずに、機械がそれをすることは想像できなかったのである。SATやIQテストの高得点を取ることは、(機械にとっても人間にとっても)チェスでうまくやること以上に意味のあることではない。
4つ目のシナリオは、現時点では定量的な議論を行うにはあまりに推測的であるため、この投稿には適していない(ただし、以下の補遺を参照)。ここでは、より極端な4つ目のオプションのための足掛かりとなる、2つ目と3つ目のシナリオに焦点を当てる。具体性を持たせるために、これらのシナリオのいずれかを実現するためには「規模が大きければよい」という楽観的な仮定をすることにする。そして、どの程度の規模をどの程度のコストで実現するかについて、私たちの最良の見積もりを見てみたいと思う。
この記事のポイントは、シナリオ2や3を絶対に達成できないと主張することではない。そうではなく、そのために克服しなければならない課題について、定量的な見積もりを得ようとするものである。私はそれが可能だと信じているが、それは単にハードウェアを良くする以上のものだろう。
長い投稿になってしまった。一言で言えば、「AGIに必要なスケールには大きな不確実性がある」ということである。10-100兆個のパラメータに拡張することで、シナリオ2またはそれに近いものが得られるかもしれない。しかし、実際の展開に必要な信頼性と汎用性を実現するには、学習と推論のコストが膨大になる可能性がある。私たちが直面している課題は以下の通りである。
- (1)モデルサイズを爆発させることなく、長期的なコンテクストを維持すること。
- (2)学習の効率化、特にN個のモデルをNの2乗ではなく、ほぼ直線的なコストで学習させる方法を見つけること。
- (3)データが不足しないように、動画・画像やプログラムで生成されたインタラクティブなシミュレーションを使用する。
- (4)相互作用が「レールから外れる」ことなく、また政策/価値勾配を実現不可能な数まで拡大する必要なく、多段階の相互作用を扱う(おそらく、大きな静的訓練済みモデルによって生成された選択肢の中から選択するために、より小さなRL訓練済み「検証モデル」を用いる)こと。
パラメーターとは
パラメーターとは、機械学習においてモデルの特徴を表す数値のことです。例えば、画像を分類するモデルの場合、パラメーターは画像を表すピクセルの値や、画像内に存在する特定の形状の数などです。
モデルを作るとき、パラメーターの値を調整することで、モデルの性能を向上させることができます。しかし、パラメーターの数が多くなると、モデルの複雑度が増し、コンピューターの処理時間が増え、訓練に必要なデータ量も増えます。そのため、適切なパラメーターを選択することが大切です。
例えば、犬と猫を分類するモデルを作る場合、耳の長さ、体の大きさ、尾の長さなどをパラメーターとして使用することができます。これらのパラメーターをうまく選択することで、高い精度で犬と猫を分類することができるようになります。
この記事は、「意識」やAIのリスクといった問題ではなく、定量的な問題に焦点をあてている。これらは独自の記事に値するものである。より哲学的・思索的な議論については、末尾の補遺を見てほしい。
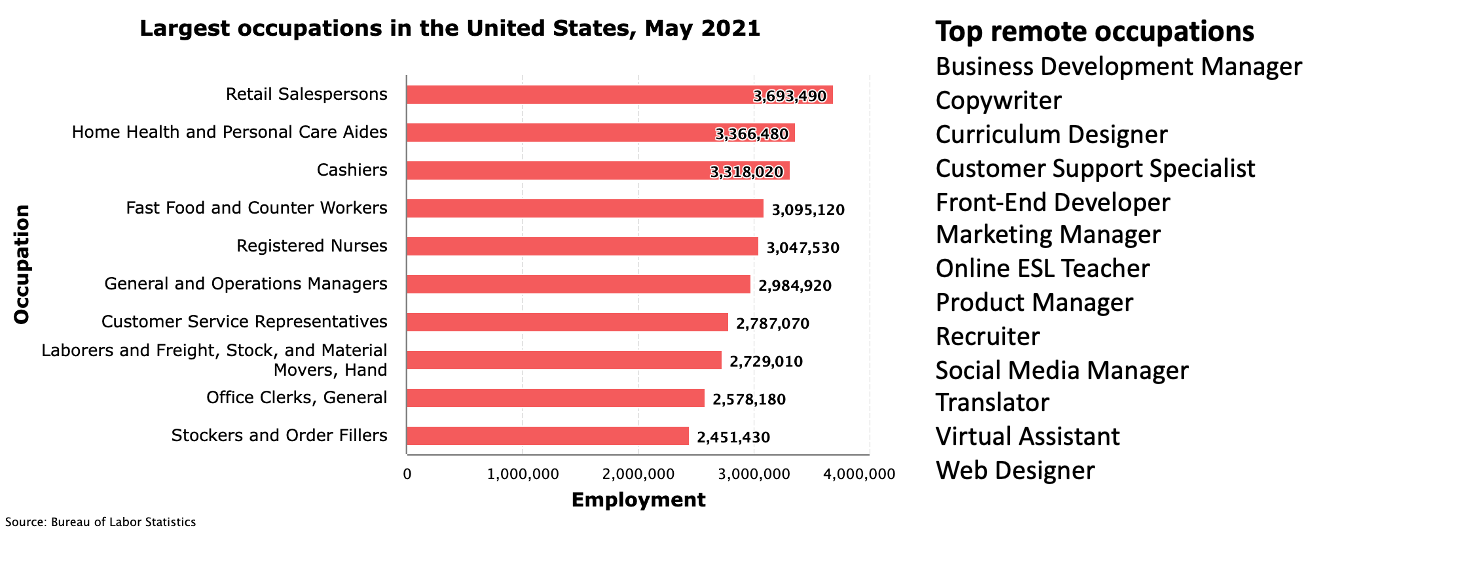
図:BLSによる米国最大の職業と、FlexJobsによるリモート専用投稿の人気リスト。このうち、医療補助員、看護師、教師などは、すぐにAIに取って代わられる可能性は低いと思われる。また、小売店の販売員やレジ係、ファストフード店やカウンターで働く人たちの代替も、現在のAIの質がネックになっているわけではない。同様に、労働者や資材運搬員など、常に変化する環境の中で肉体労働を行う職種も、近い将来、自動化の費用対効果が見込めないという。
初期設定
人工知能は仮想空間に存在するため、人々はしばしば、任意の回数だけクローンを作ることができると思いがちである。しかし、現代のAIシステムは、非常に非自明な物理的フットプリントを持っている。現在のモデルは、パラメータを保存するために数十個のGPUを必要とし、将来のものはさらに大規模になるだろう。このようなシステムのコピーを多数作成することは、困難なことである。
また、ムーアの法則により、(例えば)小学6年生のレベルで何とかシステムを構築すれば、1年後には仮想のアインシュタインが出来上がるという仮定もよくある話である。しかし、多くの場合、測定による性能は、パラメータ数の対数でスケールする(例えば、ビッグベンチとパルティの図を参照)。なので、「6年生の仮想少年を作ったら、翌年には7年生の仮想少年を作る」というのが、より適切な仮定と言えるかもしれない。
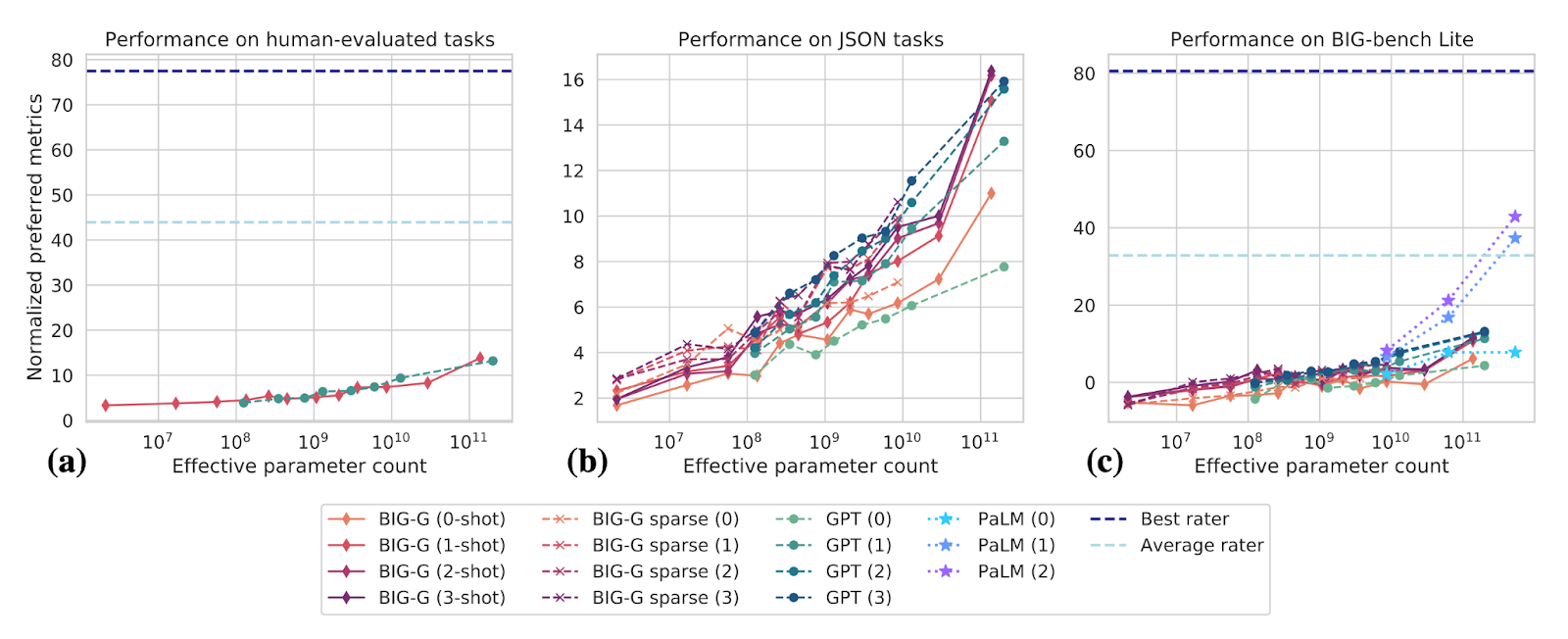
図:BIG-benchタスクにおけるモデルの性能(Srivastava et al., 22)。性能はパラメータ数の対数でスケールすることに注意してほしい。これは、飽和に近いメトリクスで典型的に現れる、パラメータ数に対するべき乗依存性とは対照的である。JSONタスクの場合、108から1011への単純な外挿は、1桁あたり約4ポイントの改善を示唆する。しかし、PaLMモデルが示す急速な成長は、より良い改善の可能性を示唆している。Jascha Sohl-Diksteinの概算では、80%のタスクでエキスパートレベルの性能を達成するためには、1~10兆個のパラメータで十分だと思われる。

図:GoogleのPartiモデルで生成した画像(パラメータはモデルのメインコンポーネントを指し、トークナイザーと超解像モジュールは無視している)。左から2.1倍、5.3倍、6.6倍とモデルが増加している。MS-COCOでは、これらのモデルのFrechet Inception Distance(FID)スコアはそれぞれ14.1,10.7,8.1,7.23であった。
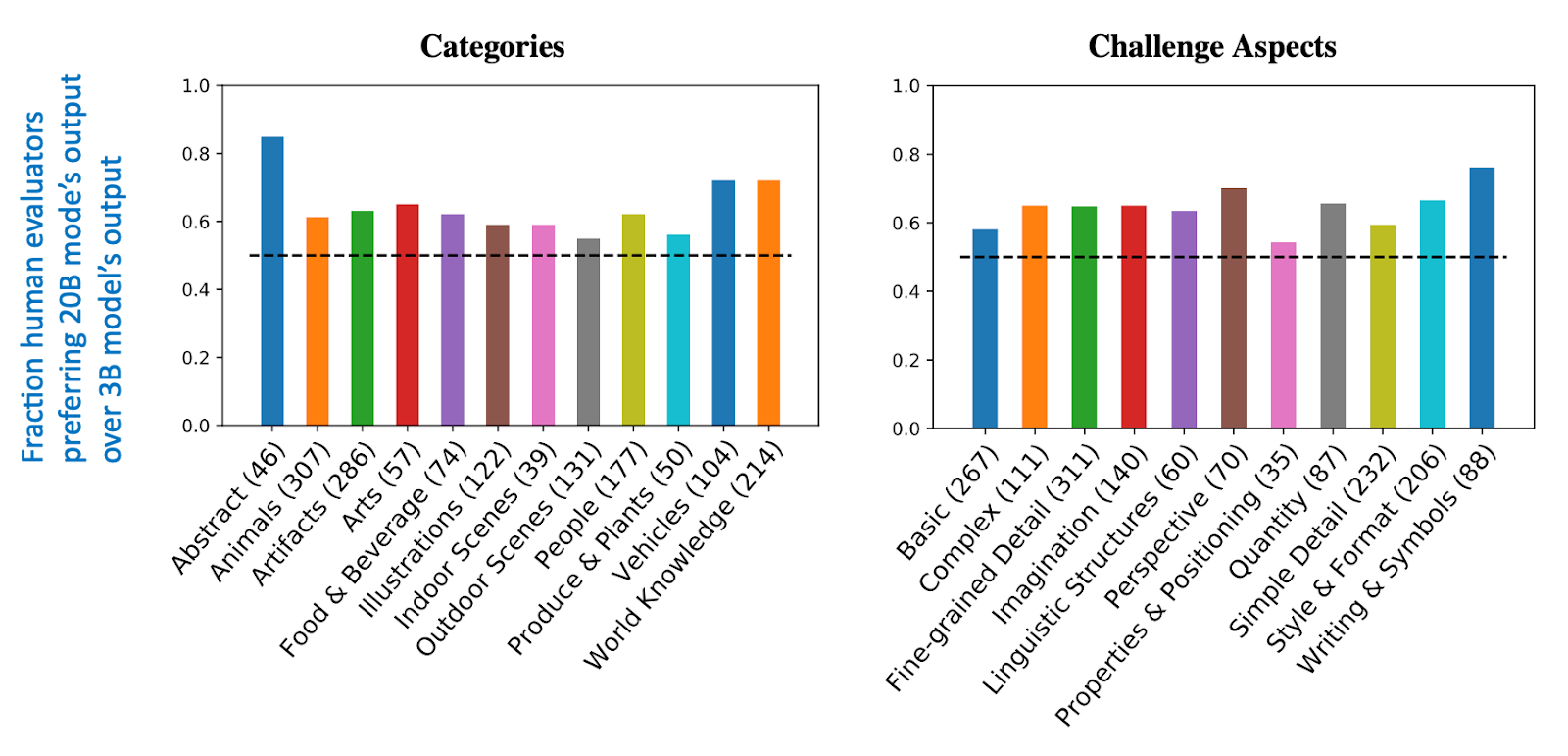
図:Parti論文(Yu et al.)の図12。人間による評価によると、20B Partiモデルはほとんどの面で3Bモデルより中程度に改善され(約60%のケースで3B出力より20B出力が人間に好まれた)、抽象概念や文字・記号を含む画像の生成で強く改善された(約80%のケースで20B出力が好まれた)。
スケールだけでいいのなら、どれくらいのスケールが必要なのだろう?
仮に、現在の自動回帰言語モデルをX倍にスケールアップするだけで、2番目のシナリオ(概念実証の一般的なAIシステム)に到達できるとする。Xは何倍だろうか?
適応性
現在、私たちが言語モデルをテストしているタスクと一般的な知能との決定的な違いの1つは、適応性である。ある質問に95%の確率で正解するモデルは優秀である。しかし、5%の確率で間違うようなモデルでは、20以上のステップを往復する会話で「レールから外れる」可能性がある。ロボット工学の性能が(たとえ仮想世界のシミュレーションであっても)人間に大きく遅れをとっている理由のひとつは、この適応性にある。物理環境が言語モデルの入力よりも高次元であることよりも、ロボットの行動がそれに影響を与えるという事実の方が大きい(チェスや囲碁、アタリの場合と違って、無制限にリスタートやシミュレーションができるわけでもない)のである。職場の社会的・技術的環境をナビゲートすることは、(たとえバーチャルであっても)それほど難しいことではない。最終的なパフォーマンス(例えば95%から99%)を引き出すには、通常、べき乗則が働き、誤差をk分の1に減らし、kのa>1乗の乗法的オーバーヘッドを必要とする。
コンテキストの長さ
スケーリングを考えるもう一つの方法は、モデルが保持するコンテキストの長さである。人間の労働者を置き換えるのに役立つように、私たちは、彼らの出勤初日のシミュレーションを継続的に行いたいわけではない。昨日、先週、今年と何をしたかを覚えているような従業員が欲しいのである。GPT-3は2048個のトークンを保持しており、これはおよそ1500ワード、つまり3ページ分のテキストに相当する。しかし、もしあなたが未来の自分に、これまでのやり取りで覚えておくべきことを詳細に書いた手紙を書くとしたら、もっと長くなる可能性がある。(歴史上最も多くの日記を書いたとされるクロード・フレデリックスは、約65,000ページの日記を書いている)。
残念ながら、標準的な変換器モデルでは、計算とメモリのコストはコンテキストに二次的に依存する(ただし、異なるトークン間の重み付けにより、学習パラメータの数は増加する必要はない)。つまり、コンテキストを(例えば)100倍増やすと、モデルサイズを1万倍増やす必要があるのだ。しかし、いくつかの代替変換器アーキテクチャは、コンテキストに対して線形または線形に近いモデルサイズのスケーリングを達成することを目的としている。
性能の経験的スケーリング
最近のBIG-benchの論文は、大規模言語モデルの性能がスケールに応じてどのように向上するかについての、おそらく最も包括的な研究である。彼らは広範なタスクを集め、それぞれのスコアを0から100の間に収まるように正規化した。スコア0はつまらない(例えばランダム)性能、スコア100はほぼ完璧な性能(例えば熟練した人間)に対応する。これらのタスクの多くで、現在のモデルは20点以下である。しかし、本当に大規模なモデルがどのような挙動を示すかについては、まだ十分なデータがない。一方では、素朴な外挿により、高い性能(例えば80点以上)を得るためには何桁も必要であることが示唆されている。一方、Google PaLMのような大規模なモデルでは、サイズの対数に対して超直線的に性能が向上する「ブレークスルー能力」が確認されている。このベンチマークを完全に解くには、1/2兆パラメータのPaLMモデルに対して少なくとも1/10の性能向上が必要なようだ。
脳と比較する
もう一つの比較対象は人間の脳かもしれない。しかし、人間の脳と人工ニューラルネットワークでは、そのアーキテクチャが大きく異なっており、1つのニューロンやシナプスに対応するパラメータがいくつあるかは分かっていない。Scott Alexanderは、脳の大きさについて、この100兆個のパラメータという見積もりを引用しているが、これは現在のモデルよりも100倍から1000倍大きいことに相当する。しかし、この推定はかなり手垢がついているし、そうでなくても、人工ニューラルネットワークが人間の脳と同じ「パラメータあたりの能力」の比率を持つと期待する根拠はない。特に、人工ニューラルネットワークは、相対的に弱い推論能力を、大量のデータを摂取することで補うようで、データとともに、モデルサイズも大きくなっていく。
結論から言うと全体として、Xは少なくとも10~100は必要だと思われるが、これは極めて大雑把な見積もりである。また、Xトリリオンのモデルは、人間に代わるシステムの「核」になるかもしれないが、それが全てではないだろうし、これらの他の構成要素についても、スケールを超えた新しいアイディアが必要になると思われる。特に、一進一退のやりとりを想定したモデルでは、ブラックボックスとして自動回帰型の言語モデルを使うだけでは、思考の連鎖を推論することはできないだろう。
費用はどのくらいかかるのだろうか?
仮に、現在のモデルをX倍に拡大することで、様々な職業(例えば、FlexJobs社のリストにある上位のリモートワークの全て)において人間と同等の生産性を実現できるシステムを生み出すという意味で、「AGI」を達成できるとする。この規模のシステムを1つ構築し、(2)広く展開するためには、どれくらいのコストがかかると予想されるだろうか?
「コンセプトの実証」と実際の配備との間には、かなり大きな隔たりがある場合がある。例えば 2007年にCMUは都市部のDARPAグランドチャレンジで優勝し、2012年にはGoogleの自律走行車が走行テストに合格している。しかし、それから10年経った今でも、自動運転車の大幅な配備には至っていない。また、『Hidden Figures』という本(映画)にも描かれているように、ムーアの法則が30年代に始まったにもかかわらず、NASAでは1960年代まで人間のコンピュータが採用されていたのである。
この投稿では、概念実証と配備の違いは、システムの訓練コストとそのシステムで推論を行うコストの違いに相当するという楽観的(かつ非現実的)な仮定をする。もしシステムが訓練に1億ドル以上かかるなら、それは決して構築できないかもしれない(比較として、大型ハドロン衝突型加速器の構築コストは50ドル未満だった)。同様に、1時間あたり1000ドルのコストがかかるシステムは、人間の労働者を大規模に置き換えることはできないだろう。
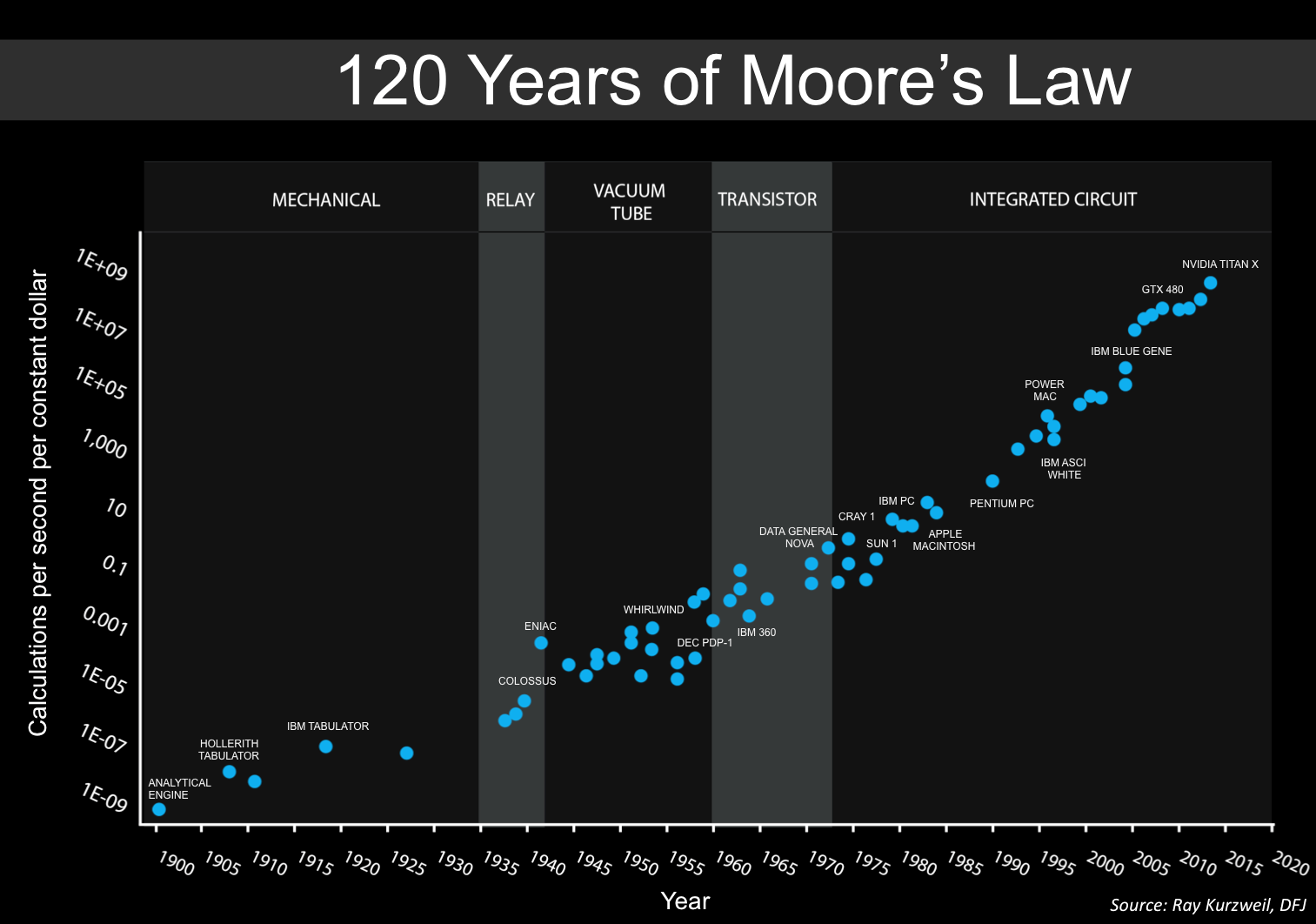
図:ムーアの法則は、1秒間に1ドルあたりの計算量で表される。ムーアの法則は1900年代に始まり、1930年代から本格化したが、1960年代までは、まだ一部の計算を「人間のコンピュータ」が行っていた。Ray Kurzweil il ilのオリジナルグラフをもとにSteve Jurvetsonが作成。
以下のコストは、現在のドルおよび現在のハードウェアで計算されている。もちろん、ハードウェアの向上は、学習や推論をより安価にすることにつながる。しかし、ノード間の通信、巨大なクラスタの管理など、モデルサイズに比例して大きくなるコストは無視している。ここでは、スケールの大きなモデルの学習や推論を行う際に重要な、償却されたコストのみを考える。
トレーニング費用
大きなモデルを学習させても、十分な時間をかけて学習させなければ意味がない。大きなモデルの性能上の利点は、「飽和」することなく、より多くのデータで学習できるようにすることで実現される。チンチラ論文の言葉を借りれば、「モデルサイズが2倍になるごとに、訓練トークンの数も2倍になるはず」ということだ。(ディープブートストラップ論文も参照)。つまり、モデルがX倍になると、1つの推論のコストと推論の総数がX倍になり、学習コストがX2倍になる。特に、100倍のモデルの学習コストは10,000倍になると予想される!このように、学習コストはモデルによって大きく異なる。
100BパラメータのGPT3モデルの学習コストは、様々な試算があるが、500万ドルから2000万ドルの範囲である。(Xトリリオンのモデル(チンチラと同様だが、PaLMとは異なり、その利点を最大限に生かすために完全に訓練される)には、100X2倍のコストがかかると思われる。X=10の場合、これは500億ドルのコストになる。X=100の場合、これは5兆ドルになる。
N個のトークンに対してN個のサイズのモデルをO(N2)ステップ以下(例えばO(N log N))で学習する方法を見つけることが、より大きなモデルをスケールアップするために重要であることは明らかである。また、より大きな言語モデルを学習する場合、利用可能なテキストデータをほぼ「使い切った」という問題にも直面する。現代のモデルはすでに何千億もの単語で学習されているが、80億人の人口を抱える地球が生み出す新規テキストの量には限りがある。(しかし、ビデオで学習するマルチモーダルモデルなら、もっと多くのデータにアクセスできるだろう)
推論1回あたりのコスト
X兆個のパラメータを持つ大規模なモデルを学習させることができたとする。推論にかかるコストはドル換算でいくらになるのだろうか?トランスフォーマーアーキテクチャでは、1回のモデル評価(すなわち推論)に必要な浮動小数点演算の数は、パラメータ数とほぼ同じだ。
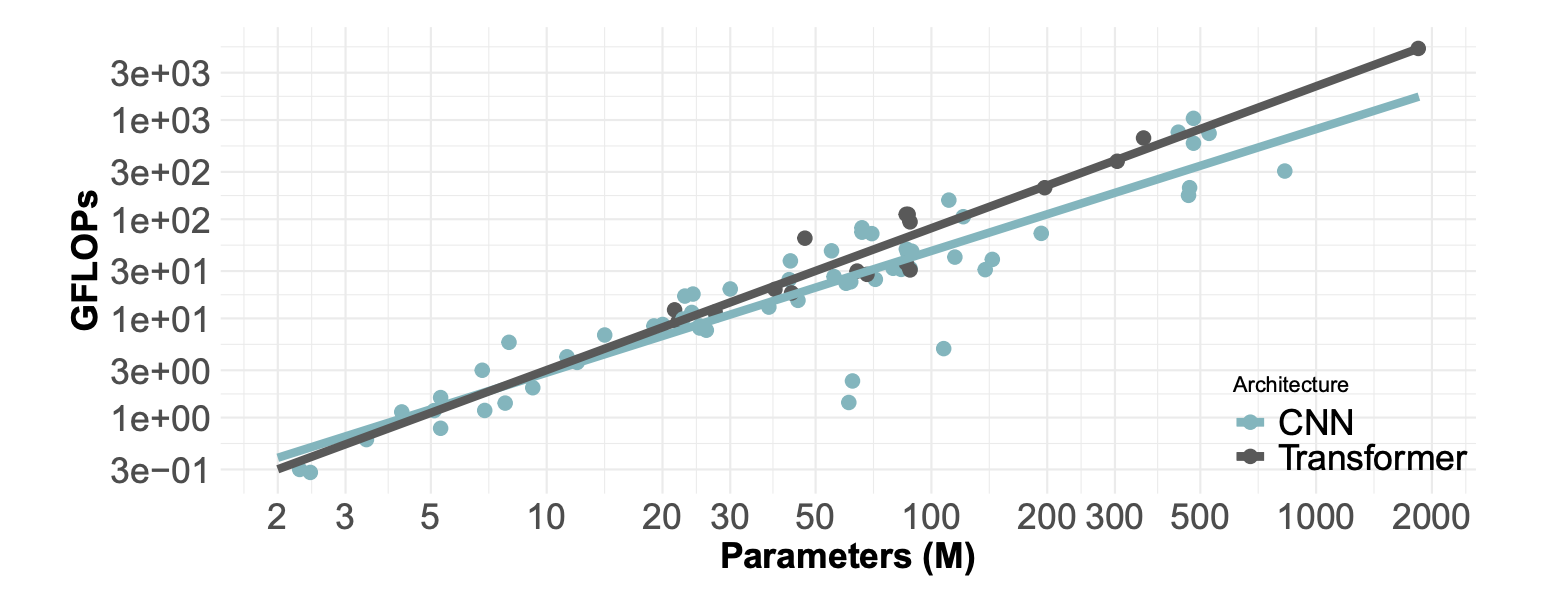
図:パラメータ数とFLOPsの関係(Desislavovらによる) 両軸は対数である。変換器の場合、傾きは1に非常に近く(1パラメータにつき1FLOP)、CNNの場合はおおよそ0.8である。
従って、X兆個のパラメータを持つモデルには、約XテラFLOPs(TFLOPs)が必要となる。Nvidia社のA-100GPUのピーク性能は約300TFLOP/sとされている。(Nvidia社のA-100 GPUのピーク性能は約300TFLOP/sとされている(16ビット精度で100%使用できない場合の影響はほぼ相殺される)。このようなマシンのレンタル料は1時間あたり約1ドルなので、1ドルあたり約300*3600〜1M TFLOPsを得ることができる。(これは桁外れに大きく、ウォールクロック時間ではなく総FLOPsだけを気にしている。推論時間に関する慎重な計算については、Carol ChenとJacob Steinhardtのブログを参照してほしい)。
X兆個のパラメータを持つモデルに対して、1ドルあたり106/Xの推論が可能である。同じNvidiaのブログによると、A-100は340MパラメータのBert Largeの6000inferences/secを処理できることが示されている。Xトリリオンのモデルは3000倍大きいので、1秒間に2/Xの推論、1時間/ドルあたり7200/Xの推論に相当することになる。上記の計算では、0.2兆パラメータのGPT-3は、1ドルあたり7200*5~35Kの推論を行うことができると予測される。しかし、OpenAIは1Kトークン(入力トークンも含む!)あたり6セントを課金しており、入力の長さによっては、1ドルあたり10個の推論しかできないことになる。Bhavsarは、GPT-3が1GPU時間あたり約18Kの推論を処理できると見積もっている。全体として、1ドルあたり104/Xの推論は楽観的な見積もりであると思われる。
しかし、人間をシミュレートするためには、1時間にどれだけの推論をすればいいのかが問題だ。平均的な人は1分間に約150語(200トークン)を話すようである。ということは、人間をシミュレートするためには、1時間に約200×60〜1万個の推論が必要ということになる。Xトリリオンサイズのモデルでは、1時間あたりXドルのコストがかかるが、Xが10〜100の間であれば、それほど悪いことではない。
上記の価格帯はかなり良いように聞こえるが、おそらく過小評価だろう。まず、実際に人間をシミュレートするためには、彼らが何を言うかだけでなく、何を考えるかもシミュレートする必要がある。つまり、「思考の連鎖」推論を行うには、発した言葉ではなく、考えた言葉ごとに推論を実行する必要がある。思考のスピードはわからないが、必要な推論の数は増えるだろう。一般に、深さKの推論の連鎖をシミュレートするためには、最終結果が単一のトークンであっても、推論の数はKに比例して増加する。第二に、高い信頼性を得るためには、Y個の推論を行い、そのY個の選択肢の中から最適なものを選択するメカニズムが必要になると思われる。例えば、AlphaCodeはプログラミングの課題に対して数百万の解答候補を生成し、その中から10個の候補にフィルタリングする。職場の環境でYがどの程度になるかを推定するのは難しいが、10〜100の間くらいになるのではないかと思われる。
推論コストの結論
上記の試算によると、X兆個のパラメータを持つモデルが人間をシミュレートするためには、1時間あたり約105から106の推論が必要となり、そのコストは1時間あたり10Xドルから100Xドルになる。これはX=10ではすでにきつく、X=100では多すぎるだろう。しかし、ある職業ごとにどれだけの言葉・思考をシミュレートする必要があるかは明らかではないので、この試算は非常に大雑把なものとなっている。
結論
上記の試算は大きな塩の粒で受け止めるべきですが、私は一般的に有用な人工知能は達成できる可能性が高いと信じている。原理的には、完璧な単語拡張器は完璧な強化学習器でもあるのだが、規模だけでは完璧に近づけることはできないかもしれない。私は、特定の結論よりも、議論が一般的な哲学的議論から、数値的な答えのある定量的な質問へと移行することを望んでいる。
追記:「Cワード」と人類存亡リスク
私は、この投稿を計算の範囲内にとどめ、哲学から遠ざけようとした。しかし、AIシステムが「意識」や「感覚」を獲得できるかどうか、そしてそれが独自の人類存亡リスクをもたらすかどうかに関する最近の議論や宣伝を考えると、少なくともこのことについて簡単に触れておかなければならないと思う。哲学や不当な推測にアレルギーがある読者は、ここでやめても構わないだろう。
スタンフォード大学の哲学百科事典には、意識に関する9つの異なる理論が掲載されており、さらに多くの理論が存在する。ある生き物に意識がある、あるいは感覚があると考えた場合、その生き物をどう扱ってよいかの境界線は、倫理の問題になる。コンピュータ科学者(あるいは他の科学者)が道徳的な哲学を考え出すのは、私たちの仕事ではないと思うし、同様に、意識の定義も私たちの領域ではないと思う。
歴史的に見ると、人間以外の存在で意識や感覚があると考えられるものは2種類あるようだ。ひとつは動物で、人はそれに対して優越感を抱いてきた。もうひとつは、人が劣等感を抱いてきた神々である。惑星の動きや気象現象などの自然現象は、その原因が解明されるまでは、さまざまな神々の意識的な働きによるものだと考えられてきた。予測も説明もできない自然現象を制御するには、その制御者である意識的な存在に祈り、生贄を捧げるしかなかったのである。
将来起こりうるAIについての議論の中には、そうした過去の神々を彷彿とさせるものがある。ある人によれば、AIは意識だけでなく気まぐれで、「地球上のすべての人が同じ秒数のうちに突然倒れて死んでしまう」ことを確実にすることができる(だろう)、という。もちろん、AIシステムが核戦争を起こしたり、致死的なウイルスを設計したりするような仮想シナリオを構築することは可能だ。私たちは皆、そのような本を読み、そのような映画を見たことがある。また、人間が核戦争を始めたり、致死的なウイルスを設計したりするシナリオを構築することも可能である。後者のタイプの本や映画もたくさんある。実際、多くのAIの「破滅のシナリオ」は、超人的な知能レベルを必要としないように思われる。
実は、これまで地球が滅亡しなかったのは、人間の知能が低かったからでもなく、悪意がなかったからでもない。第一に、人類の歴史の大半において、核兵器など地球規模の破壊を引き起こす可能性のある技術を持たなかったこと。第二に、不完全ではあるが、国際機関、核不拡散条約、バイオラボの基準、パンデミック対策など、これらの能力のいくつかを抑制するための制度を整備してきたことである。第三に、私たちは幸運であった。
気候変動からパンデミック対策、核軍縮に至るまで、人類は自分たちが作り出したリスクや害悪に立ち向かうために、もっともっと努力しなければならないはずだ。しかし、これは人工知能とは関係なく言えることである。人間と同じように、私がAIに望むことは、システムを本質的に道徳的あるいは善良なものにしようとすることではなく(AI用語で「アライン」)、むしろ「信頼するが、検証せよ」というアプローチを用いることである。計算複雑さの理論の1つの教訓は、計算能力の弱いエージェントが、より強力なプロセスの計算を検証することができるということである。
上記の計算の多くは、「スケールアップ」がいかに自明でないものになるかを示している。ある日AIがレストランの予約をし、次の日には世界を破壊するナノテクノロジー研究所を建設するためにネット経由で材料を密かに注文するというのは、ありそうもない話である。たとえ大規模なモデルが、外部のデータを追加することなく、パフォーマンスを向上させるために「自己学習」することが可能だとしても、そのモデルには、上で計算したような学習に必要な相当な計算コストがかかるだろう。
前回の記事で、私が「長期主義者」でない理由を説明した。上記は、私が「AGIの暴走」を短期的な存亡の危機と見なさない理由である。だからといって、AIに安全性の問題がないわけではない。AIは新しい技術であり、どんな新しい技術にも新しいリスクはつきものである。差別や偏見といったAI導入による意図しない結果も、兵器や監視、社会操作のためのAI導入による意図的な結果も、SFでなくとも現実的なリスクとして捉えることができる。意識の概念について議論したり、終末のシナリオを作ったりすることが、これらのいずれかに対処するために役立つとは思えない。
謝辞Jascha Sohl-Diksteinには、このブログ記事のドラフトや、BIG-benchの論文の結果の解釈について、多くの有益なコメントをいただいた。