Contents
A 30% Chance of AI Catastrophe: Samotsvety’s Forecasts on AI Risks and the Impact of a Strong AI Treaty

概要
- 我々は、2200年までに人類の大多数が死亡するAI大災害のリスクを、全体として30.5%と推定した。
- 予測者の大半は、そのような大災害が起こるとすれば、今後27年以内に起こる可能性が高いと考えた。
- 9人の予測者全員が、少なくとも8%の確率でAIによる大災害が起こると予測した。
- 我々は、このようなリスクを減らすことを目的とした2つの潜在的な政策の効果を調査しようとした:
- 生命の未来研究所が提案しているように、GPT-4より強力なモデルの訓練を最低6ヶ月間休止する。
- その結果、リスクが大幅に減少することがわかった。
- 強力なAI条約であるTAISCは、グローバルな計算上限や、AIの安全のためのCERNのような研究所の設立などの対策を提案している。
- リスクは大幅に減少した。
- 生命の未来研究所が提案しているように、GPT-4より強力なモデルの訓練を最低6ヶ月間休止する。
- また、これらの事象が発生する確率の見積もりと、その根拠と分析も示す。
はじめに
近年の人工知能(AI)の進歩は、専門家、政策立案者、一般市民の間に熱狂と懸念の両方を生み出している。AIの潜在的なメリットは非常に大きいが、こうしたメリットとともに、AI技術の継続的な開発が人類に重大な存亡の危機をもたらす可能性があることも広く認識されている。この理解により、AI技術の安全かつ責任ある発展を保証する政策的解決策が急務となっている。
GPT-4の最近のリリースは、高度なAIシステムに関連する潜在的なリスクに注目を集め、このトピックに関する世論の高まりにつながった。GPT-4のリリース直後、Future of Life Institute(FLI)は公開書簡を発表し、GPT-4より強力なAIシステムの訓練を6ヶ月間休止するよう呼びかけた。GPT-4の発表とタイムリーなFLIの公開書簡はともに、AIリスクに関する一般市民の議論を広げ、政策的解決策を求める機運を高める上で重要な役割を果たした。ここ数カ月では、AI安全センター(CAIS)の声明や政治指導者の発言により、強力なAIシステムに関連するリスクへの関心がさらに高まり、11月には世界的なAI安全サミットが開催される予定だ。
サモツベティ予測では、AIリスクの低減を目指す2つの潜在的政策に焦点を当てた条件付き予測を最近実施した。1つ目の政策PAUSEは、FLIの公開書簡で推奨されたGPT-4より強力なAIシステムの6ヶ月間の訓練モラトリアムの実施である。
2つ目の政策TAISCは、最低でも米国と中国、およびその他の潜在的な署名国を含む国家連合による人工知能安全協力条約(TAISC)案(概要、全文)の署名と実施に関するものである。TAISCは、政治的な実現可能性とAIの経済的利益を維持しつつ、AIのリスクを大幅に低減するために最低限必要な政策を策定することを目的として設計された。TAISCには、大規模なAIトレーニングの禁止、大規模GPUクラスターの解体、AIの安全性に関する国際協力と能力開発の促進に関する条項が含まれている。
TAISCの重要な側面は、国際AI安全協力委員会(IASC)とCERNのようなAI安全共同研究所(JAISL)の設立である。IASCは条約の遵守とAIの安全性研究を監督し、JAISLはAIの安全性に関する研究、開発、技術革新を行う。JAISLは合理的な計算制約の中で責任を持って設計されたAIモデルを開発し、安全性を損なうことなく高度なAIにアクセスできるようAPIアクセスを提供する。JAISLはまた、研究機関、学界、民間セクターと提携することで、AIの安全性におけるイノベーション、コラボレーション、能力開発を促進している。
本稿では、政策PAUSEと政策TAISCの条件付き予測を提示し、AIリスクへの影響を議論し、TAISC、IASC、JAISLの概要と主要な条項を紹介する。我々の目的は、AIリスクとそれを軽減するための潜在的戦略に関する継続的な議論に貢献し、AIリスク軽減におけるこれらの政策の有効性に関する洞察を提供することである。AI技術の将来とその社会への影響は極めて重要であるため、この重要な分野における社会的議論に情報を提供し、さらなる研究と行動を促すことを目的としている。
目次
- 概要
- はじめに
- 方法論
- 結果
- TAISCの概要
- 予測の運用
- 根拠
- 限界
- 改善すべき点
- 結論
- サモツベティ予測とは何者か?
- 謝辞
方法論
政策PAUSEと政策TAISCがAIリスクに与える影響について正確で信頼性の高い予測を行うため、我々は構造化された透明性の高いアプローチを採用した。
我々の方法論には以下のステップが含まれる:
- 1. 予測者の選定 Samotsvetyの9人の専門家予測者を集めた。Samotsvetyの予測者は全員、INFER、Metaculus、Good Judgment Openなど、過去の予測プロジェクトで精度の高さと賢明な推論を実証している。
彼らの何人かはスーパー予測者である。ほとんどの予測者は、AI xリスクに関するジョー・カールスミスのレポート「パワーを求めるAIは存続的リスクか」を少なくとも読んでおり、AIの専門知識を持つ予測者もいる。これらの予測者は、過去に「サモツベティのAIリスク予測」や「サモツベティのAGIタイムラインの更新」で使用された予測を提供している。 - 2. 調査デザインとデータ収集 調査設計とデータ収集:AIリスク削減におけるPAUSE政策とTAISC政策の実施と効果に関する質問を含む調査を設計した。この調査には定量的な質問と定性的な質問の両方が含まれており、予測者は確率の推定値だけでなく、予測の根拠も記入することができる。予測担当者はそれぞれ独立して調査を行った。
第1ラウンドの予測終了後、我々は予測について議論するためのミーティングを開催し、予測者は議論に基づいて予測を更新することができた。 - 3. データの集計と分析 予測の集計を行うために、予測者が提示した確率のオッズの幾何平均[1]を計算した。
- 4. 結果の発表 集計された予測と、定性的な回答から得られた重要な洞察の要約を提示する。加えて、TAISCの概要とその主要な条項について説明し、読者に政策の背景を包括的に理解してもらう。
この方法論に従うことで、政策PAUSEと政策TAISCがAIリスクに与える潜在的な影響について、確実で実行可能な予測を作成し、AIの安全性に関する継続的な議論と効果的な政策ソリューションの開発に貢献することを目指した。
結果
結果について この予測は2023年4月下旬に行われたものであるため、一部の予測は古い可能性がある。この結果および本レポートの草稿は、作成後数週間から数ヶ月の間に、AIセーフティ・コミュニティの一部のメンバーに非公開で配布したものであるが、今こそ公表すべきタイミングであると考えた。
試算の一部は古くなっているかもしれないが、私たちは、私たちの根拠とともに、この問題に対する貴重な洞察を提供できると信じている。我々は現在、AI政策に関する別の予測プロジェクトを進めており、近いうちに報告書を発表できるものと期待している。
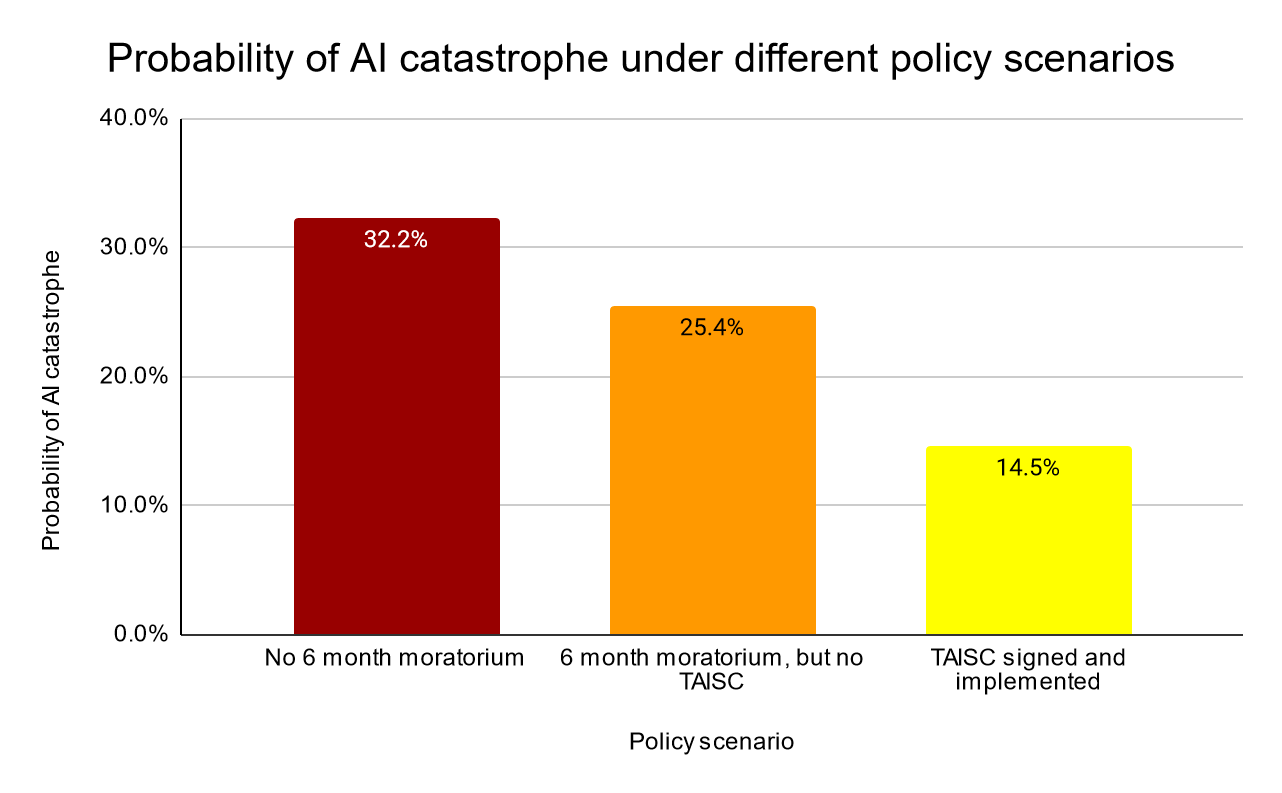
ここでは、我々の総計的な予測と結果を紹介する。我々の予測では、AIによって2200年までに人類の95%以上が減少することをAIカタストロフと定義した。
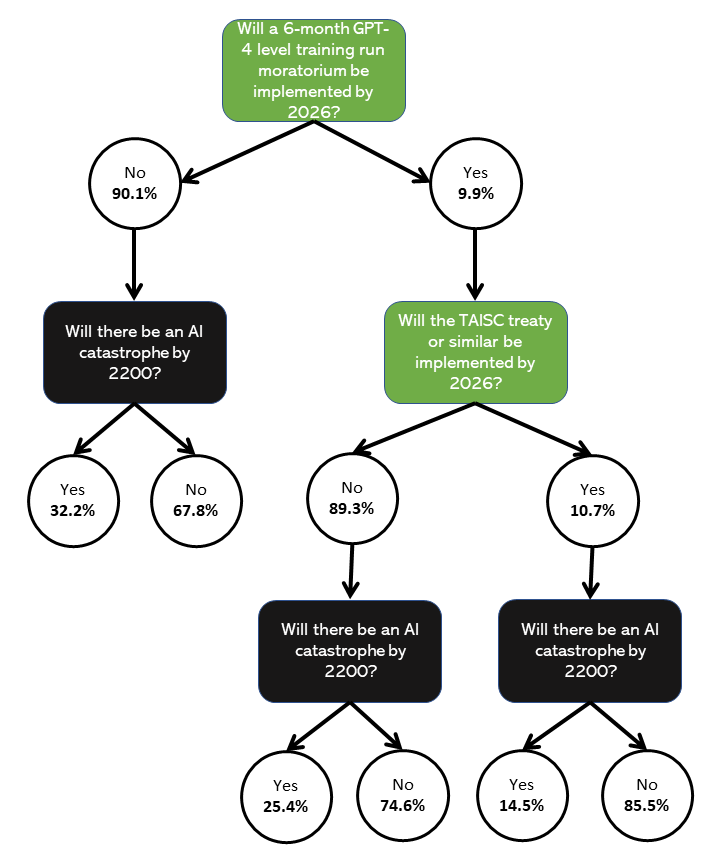
- P(AI catastrophe | NOT PAUSE) 2026年までに6ヵ月のモラトリアムがない場合のAI破局の確率 32.2%
- P(PAUSE) 2026年までに6ヵ月のモラトリアムが実施される確率 9.86%
- P(AI catastrophe | PAUSE AND NOT TAISC) 2026年までに6ヵ月間のモラトリアムが実施されるが、TAISC条約または類似の条約が実施されない場合のAI大災害の発生確率 25.4%
- P(TAISC|休止) 6ヵ月のモラトリアムを条件に、2026年までにTAISCまたは類似の取り決めが実施される確率 10.7%
- P(AI大惨事|TAISC) 2026年までにTAISCまたは類似の取り決めが実施された場合のAI キャタストロフの発生確率 14.5%
- P(AIカタストロフィ) 2200年までにAIが大災害に見舞われる確率の計算(すべてを考慮した場合) 30.5%
AIが大災害に見舞われる確率の最小見積もりは8%、最大見積もりは71%であった。確率の推定値を示すフローチャートは次ページを参照のこと。これらに基づいて、各政策シナリオにおけるAIの破局的リスクの予想削減率を計算することができる:
- 2026年までに6カ月間のモラトリアムが実施され、TAISCが実施されないシナリオにおけるAI災害リスクの減少率 21.2%
- 2026年までにTAISCが実施されるシナリオにおけるAI破局的リスクの減少率 54.9%
したがって、2026年までにTAISCまたはそれに類するものが実施される可能性は低い(~1%)と考えられるが、条約が実施されるシナリオでは、AIの大惨事の可能性は54.9%減少すると考えられる(30.5%から14.5%へと16%ポイント)。また、6ヵ月のモラトリアムがあったが2026年までにTAISCが実施されなかったシナリオでは、AIによる大災害の可能性は21.2%減少すると考えられる。
我々はまた、2200年までにAIによる大災害が起こるという条件の下で、AIによる大災害が起こる年の中央値の推定も行った。我々の予測の中央値は2050年であった。つまり、予測者の半数以上が、2200年までにAIによる大災害が起こるとすれば、それはおそらく今後27年以内に起こると考えている。
結果表で推定した確率をフローチャートで表した:
TAISC:概要
TAISC(Treaty on Artificial Intelligence Safety and Cooperation:人工知能の安全および協力に関する条約)は、高度なAIシステムがもたらす存亡の危機を軽減するための取り組みである。TAISCの規定は、政治的な実現可能性を維持し、AIの経済的・社会的利益を活用しつつ、AIリスクに対処し、安全なAI開発を促進するために最低限必要な政策枠組みを確立することを目的としている。
ここでは、TAISC条約の主要な条項の重要性を、その主要な目的である以下の事項の達成にどのように寄与するかに焦点を当てて説明する:
- AIシステムの安全性を維持する – これを達成するため、アライメント問題に大きな進展が見られるまで、AIシステムの能力に厳格な制限を設けることを提案する。
- 競争力学の抑制 – AIの安全な開発における主な課題のひとつは、民間のAI研究所間や、アメリカや中国のような大国間で起こりうる競争力学である。この力学は、組織や国がAIの急速な開発を追求するあまり、安全性のベストプラクティスを無視する危険な競争につながる可能性がある。
- アライメント問題の解決 – これは、AIシステムの目的と行動が人間の価値観や意図とアライメントされたものであることを保証する問題である。
- AIの有益な利用を促進する – 強力なAIシステムは、良い目的にも悪い目的にも利用される可能性があり、AIが全人類に利益をもたらすことが重要である。
グローバル・コンピュート・キャップ
大規模なトレーニング実行(累積10^23FLOP以上を使用)をグローバルに禁止し、大規模な計算クラスタ(GPT-3のトレーニングに使用される計算量である3*10^17FLOPのパフォーマンスでトレーニング実行が可能)を解体する規定は、AIモデルの能力を推定される安全な限界内に保つことを目的としている。
TAISCは2キャップシステムを提案しており、共同AI安全ラボ(JAISL)内のモデルは、GPT-4の訓練に使用される計算量である2.5*10^25 FLOPまでの計算量を使用して訓練することができ、このラボの外で開発されたモデルについては、通常のグローバルキャップである10^23 FLOPが適用される。
2キャップ制の主な利点は以下の2点である:
- JAISLの外で訓練されたモデルは、十分な安全性を確保するために最大レベルの安全プロトコルや専門知識を必要としない。
- ブレイクアウト能力: キャップは、許可されたモデルは数日以内に訓練できるように設計されているが、JAISLで許可されたモデル以上の規模の違法で潜在的に危険なモデルの訓練には数年かかるため、当局がこれを検知し対応する時間が与えられる。
コンピュート・キャップの利点は、規制対象として比較的容易であることだ。ハードウェアの所有権と使用量を追跡し、計算を検証するシステムを導入することができる。世界的にAIプロジェクトの規模を制限することで、これらの規定は協力を促し、競争を抑制する。なぜなら、許可された最も強力なモデルへのアクセスを望む国は、JAISLを通じて協力することが求められ、それによって競争力学を抑えることができるからだ。
民間団体が訓練可能なモデルの能力を制限し、政府がその上限を強制することで、そのような団体間の競争力学は排除されるはずである。さらに、世界的な計算能力の上限が設定されれば、アメリカや中国のようなライバル国は、互いの能力をより明確に把握できるようになり、相手が自分たちを追い越すかもしれないという不安の中で、ハードウェアや人材、その他のリソースを大量に増強する必要性を感じなくなるだろう。
AI安全共同研究所(JAISL)
CERNに触発されたジョイントAIセーフティラボラトリー(JAISL)は、AIの安全性、アライメント問題、安全なAIモデルの開発を真剣に前進させるための集団的イニシアチブを体現している。JAISLは、リソース、専門知識、知識をプールすることで、共同研究を促進し、安全なAI開発を支援し、署名者間の透明性と協力を促進し、大国間の競争力学を緩和する。
JAISLの主な目的は、アライメント問題の解決とAIの安全性研究という壮大なプロジェクトに向けて、人類の総力を結集することである。このAI安全性研究の中核的役割に加え、JAISLは、安全性と倫理的使用の最高水準に保持された、訓練に2.5*10^25 FLOP以下を必要とするAIモデルを開発、訓練、実行することにより、より高い計算能力を持つ安全なAIモデルのAPIへのアクセスを提供する重要な役割も担っている。
JAISLは、開発したより高度な計算安全モデルのAPIアクセスを条約加盟国に提供する。これは、各国が協力し条約に参加する強力なインセンティブとなる。また、「グローバル・コンピュート・キャップス」(Global Compute Caps)でも言及されているように、この分野における自国の能力に関係なく、各国がこれらのAPIへのアクセスを受けることで、自国の独立したAI開発リソース(人材、ハードウェアなど)を構築するための望ましくないインセンティブが減少する。
この安全なAPIアクセスを提供することで、JAISLは個々の国が危険な競争的AI開発に従事するインセンティブを低減する効果があるだけでなく、AI技術の責任ある利用を促進する効果もある。さらに、JAISLはAPIの価格設定をローカルに設定することを可能にし、AIの破壊的な経済効果を緩和するために収益を上げるなどの目的に使用することができる。
これらの目的に加え、JAISLは国内外の研究機関、学界、民間セクターと協力し、イノベーションを促進し、AIの安全対策の理解と実施を進めるとともに、研究者、政策立案者、その他の利害関係者の能力構築と研修プログラムを促進し、AIの安全性に関する世界的な理解を深め、責任あるAIの開発を促進する。
共同監督、情報収集、共有
TAISCは、協調的な監督、情報収集、共有の枠組みを確立し、関係者が協力して非遵守活動や不正行為者を特定し、対処できるようにする。この枠組みにより、潜在的な脅威に関する迅速な情報交換が可能となり、条約執行の全体的な有効性が高まる。このような規定は、オープンソースの最先端LLMが拡散するリスクを軽減するために、特に必要となる可能性がある。
国際AI安全協力委員会(IASC)の設立
IAEAにヒントを得たIASCの設立は、条約の遵守を監視し、AIの安全性研究を促進し、署名国間の協力を促進するための中央機関としての役割を果たす。この規定は、AI研究が安全基準と倫理基準にアライメントされるよう監視し、保証するために不可欠である。
IASCのもう一つの重要な役割は、JAISLを監督することである。さらに、JAISLと協議の上、IASCは、同じ計算量で学習させながら、より高い能力を持つモデルの開発を可能にするアルゴリズムの改良を考慮し、グローバル・コンピュート・キャップを長期的に削減することを任務としている。
TAISCの全文はこちらで見ることができる。TAISCは主にTolga Bilgeが設計し、Finn HamblyとJonathan Mannの助言を受けた。また、国際法でよく使われる言葉で条約を表現するために、ホセ・ハイメ・ヴィラロボスからもフィードバックと協力を得た。また、ネイト・ソアレス、マーカス・アンデルルジュン、デイヴィッド・ダルリンプル、イーライ・リフランドからも有益なフィードバックを得た。
予測の運用
定義
我々の予測プロジェクトでは、AI大災害を以下のように定義した: 「AIによって2200年までに人類の人口が95%以上減少すること」である。
この定義が他のカタストロフィの定義と異なる理由はいくつかある:
- 関連性: 私たちの定義は、明確で具体的なシナリオを提示しているため、政策立案者や一般市民にとってより適切である。
- 明確性: 具体的な結果に焦点を当てることで、我々の定義は予測プロセスを合理化すると同時に、”人類の潜在能力の完全な喪失 “や “AIが運営するディストピア “といった他の懸念事項の重要性も認めている。
重要なのは、この定義の解釈にはある程度の柔軟性を持たせたことである。例えば、ある予報士は、人間の心が機械にアップロードされる「ハッピー・アップロード」シナリオをカタストロフとみなさないことを選択した。
- 政策の一時停止(Policy PAUSE) これは、2026年までにFLIの公開書簡が実施されれば満たされると考えた。つまり、GPT-4よりも強力なAIシステムの訓練を6ヶ月間(またはそれ以上)休止することである。これは、AIラボが自主的に実施することも、政府が強制することも、あるいはその組み合わせによって実施することもできる。
- TAISC政策 2026年までに少なくとも米国と中国がTAISC条約またはそれにほぼ相当するものに署名するか、その他の方法で実施すれば、これは満たされると考えられた。
注
予測にあたっては、AIの大災害を妨げるようなAI以外の大災害が発生しないことを条件とした。そのような事態の候補としては、最悪のパンデミック(H5N1かもしれない)、NATOとロシアの大規模/全面的な核交換、カリントン現象規模の太陽嵐などが考えられる。我々はこれらのリスクを否定するつもりはないが、検討中の潜在的な政策の影響について可能な限り明確な見解を示したかった。
さらに、政策TAISCにはGPT-4より強力なAIシステムの訓練禁止が含まれており、これは政策PAUSEと同等かそれよりも強力であるため、我々の予測問題は単純化されていることに留意されたい。したがって、P(PAUSE | TAISC) = 1、つまり、政策TAISCが実施されれば、政策PAUSEも必然的に実施される。
根拠
ここでは、すべての予測者から提供された理論的根拠を統合し、グループ全体の推定値とともに、推定した各確率について2つの代替見解を示す。
p(pause) – 9.86%
2026年までに6ヶ月間の大回転モラトリアムが実施される確率。
P(PAUSE)を高くした理由:
GPT-4の改良、GPT-4 32kコンテキスト、GPT-5のリリース、その他のAIラボの開発などである。雇用の代替による経済効果も、主要な関係者にそのような休止の実施を検討するよう促すかもしれない。このようなことが実施されることを想像するのは難しくないという意見もあり、GPT-5が現在訓練されていないことについてのサム・アルトマンのコメントも、その考えを後押ししているかもしれない。
しかし、他の主要なアクターによる自発的な応酬が不確かなままであることは注目に値する。AIの安全性と潜在的なリスクに対する関心が高まっていることを考えれば、AIラボによる自主的な休止はまったくありえない話ではない。
P(PAUSE)を低くする理由:
規制はゆっくりと進む傾向があり、AI規制に関して発表されている声明は、すぐに一時停止が実施されることを示しているようには見えない。さらに、一時停止を求めるロビー活動を効果的に行える主要な関係者が気づいているかどうかは不明であり、一時停止を実施するためのロジスティクスは複雑である。
その可能性が低いのは、主に大規模なAI研究所がそのことに興味を持っていないように見えるからであり、執行が問題となるだろう。2014年から2017年にかけてのGOFの研究禁止は、たとえ政府主導であっても、研究分野での禁止を実施・執行する際に直面する課題の一例となっている。さらに、2026年以前に、強力なAIの訓練を一時停止させるような重大なAI事象が世界を脅かさない限り、実現する可能性は低いという意見もある。
P(AIの破局|NOT PAUSE) – 32.2%
2026年までに6ヶ月のモラトリアムが実施されなかった場合に、AIが破局を迎える確率。
P(AI catastrophe | NOT PAUSE)を高くした理由:
6カ月のモラトリアムが実施されなければ、AI破局のリスクは、人種間の力学を含む様々な要因によってより高くなる可能性があると考える予測者もいる。AI研究所や各国がますます強力なAIシステムを開発しようと競争する中、安全対策やアライメント研究に注力するインセンティブが低下する可能性がある。6ヶ月のモラトリアムがないことで、画期的な進歩を遂げようとする競争圧力が悪化し、重要な安全対策を見落として開発を急ぐ可能性があり、意図しない有害な結果を招く可能性が高まるかもしれない。
さらに、アライメント問題は非常に分離的で解決が困難であるため、6ヶ月のモラトリアムがない世界ではリスクが高くなるかもしれないという懸念もある。彼らは、AIの安全性研究において技術的な進歩があったことを認めているが、アライメント問題の複雑さや、価値観の誤特定、目標の誤汎化、道具的収束の初期兆候の可能性が、全体的なリスクを高めている。
6ヶ月のモラトリアムのような一時停止は、AIの大惨事の全体的な確率に大きな違いをもたらさないかもしれないと考える予測家もいる。短いスパンで何ができるか不明であり、その期間中に研究室がトレーニングの代わりに何にリソースを費やすか懸念されるからだ。まとめると、レースダイナミクス、アライメントされた課題、高度に競争的な環境における安全性の確保の難しさの組み合わせが、6ヶ月のモラトリアムがない世界におけるAIの大惨事の確率を高くしている。
P(AI catastrophe | NOT PAUSE)が低い根拠:
AnthropicやOpenAIのような組織で評価作業(ARC Evalsなど)が行われているのは心強い。AIが意図的にではなく、意図せずに大惨事を引き起こすことを懸念する予測者もおり、システムの能力が進歩するにつれて、システムが自然にエージェント化していく度合いには大きな不確実性がある。また、計算オーバーハングが生じる可能性を指摘する予測家もいる。
P(AI catastrophe | PAUSE AND NOT TAISC) – 25.4%
2026年までにモラトリアムが実施され、TAISC条約が実施されなかった場合にAIが大災害に見舞われる確率。
P(AI catastrophe | PAUSE AND NOT TAISC)を低くした理由:
6ヵ月のモラトリアムは十分ではないかもしれないが、AIリスクを大幅に低下させるような何か、おそらく最終的にはTAISCかそれに類するものにつながる可能性があると考える予測専門家もいる。さらに、6ヵ月の一時停止措置の実施は、人々がAIリスクをより真剣に受け止めているというシグナルとなるかもしれず、このような注目の高まりは、アライメントやガバナンスの問題への対処に役立つ可能性がある。
ある予測者は、この種の一時停止措置や規制によるリスク低減のほとんどは、AGIの開発が決して許可されないかもしれないというシグナルを意味するために生じるが、その可能性は依然として非常に低いと示唆した。
より高いP(AI災害|一時停止とTAISCなし)の根拠:
予測担当者の中には、手紙に書かれた政策を実施することの有効性に確信が持てず、特にそれが6ヶ月で終わるのであれば、リスクに対する針はあまり動かないかもしれないと考える者もいる。GPT-4より強力なトレーニングランを誰もやっていないことを確実に知ることができるのかという懸念がある。
さらに、6ヶ月の延長は、特にクランチ時の6ヶ月のフル稼働に必ずしも結びつかないため、あまり時間を稼げないかもしれない。リスクの変化は、パス依存性に関するいくつかの重い仮定と相まって、人々が今この問題を真剣に受け止めていることを示す合意に由来するものがほとんどかもしれない。長期的なリスクは、一般的に粘着性があり、国民の関心や適切なリーダーシップがあったとしても、根本的に解決するのが難しい問題に関係する。アライメント問題も、まだ解決する必要があるだろう。
P(TAISC|休止) – 10.7%
少なくとも6ヶ月間のモラトリアム(一時停止)が実施されることを条件として、2026年までにTAISC条約または類似の条約が米国、中国、そして潜在的にはその他の国によって署名される確率。
P(TAISC|PAUSE)を高くする理由:
もし6ヶ月のモラトリアムが実施されれば、TAISCかそれに類するものに到達する合理的な可能性があると主張する予測家もいる。政治が許せば、6ヶ月のモラトリアムを導く論理はTAISCのようなものにもつながるはずだからである。
6ヶ月のモラトリアムの実施は、世界がAIのリスクをより真剣に受け止めているというシグナルとなり、国際協力を促進し、TAISCのような条約への道を開くかもしれない。AIリスクに対処するための強固な枠組みを作ろうという注目と意欲の高まりが、TAISCの実施を成功に導く原動力になるかもしれない。
P(TAISC|PAUSE)低下の根拠:
最初の政策が実施されたにもかかわらず、特に現在の政治情勢において米中両国間でTAISCのような条約が結ばれることを想像するのは難しいと考える予測者もいる。両国の間に存在する緊張関係や、より広範な地政学的背景から、AIリスクを管理するための効果的な協定を結ぶのは望み薄のように思われる。
さらに、気候変動への国際的対応など歴史的な前例から、各国は拘束力のある条約よりも自発的なコミットメントに基づく協定の交渉に傾く可能性があることが示唆されており、TAISC条約やそれに類するものが制定される可能性は限られるかもしれない。
P(AI大災害|TAISC) – 14.5%
TAISC条約または類似の条約が2026年までに米国、中国、および潜在的にその他の国によって締結された場合に、AIが大災害に見舞われる確率。
P(AI catastrophe | TAISC)が低い根拠:
予測専門家は、TAISCのような条約が実施されれば、さまざまなメカニズムを通じてAIリスクを大幅に低減できると主張している。
TAISC条約は、人種間の力学に対処し、協力を促進し、以下のような方法でAIの安全な開発を促進する:
- 1. グローバルな計算上限を設定することで、AIモデルの能力を安全な範囲内に保つ。
- 2. 標準化されたAI安全プロトコルとベストプラクティスを加盟国に確立する。
- 3. AIのリスクに対処するための世界的な協調と協力を強化し、AIの安全性研究の専門知識を共有する。
- 4. AI安全性研究開発への投資と資源配分を増やす。
- 5. 共同監視、情報収集、共有を通じて、潜在的リスクの早期発見と予防を可能にする。
- 6. コンプライアンスに反する行為に対して行動を起こすことで、不正行為者に対する抑止力となる。
- 7. AIを取り巻く環境における新たなリスクや課題に対処するため、更新・改訂が可能な順応性のある枠組みを構築する。
- 8. AIに関連する脅威を軽減することを目的とした政策やイニシアティブに対する一般市民の認識や支持を高める。
これらの要因は、条約がAIの開発・導入により安全で協調的なアプローチを促すため、AIの大惨事が発生する確率が低くなることに寄与する。推定値が低くならない主な理由は、協定が破られたり、適切に施行されなかったりする可能性があるためだ。
しかし、アメリカと中国がこの条約に真剣に取り組めば、他の国もAIのリスク軽減に乗り出すというシグナルになるかもしれない。これは、世界がAIリスクをより真剣に受け止めることになり、正しい方向への一歩となるだろう。
より高いP(AI災害|TAISC)の根拠:
他の予測専門家は、条約が結ばれても、国際協定では容易に管理できない現実のリスクが残っていると主張している。条約は長続きしないかもしれないし、各国は調印後も実際には条約に従わないかもしれない。加えて、アライメント問題を解決することは依然として困難であるため、条約が締結されていても、高いレベルのAIリスクが残る可能性がある。
限界
我々の予測プロセスの主な限界は以下の通りである:
期間と範囲: 我々は2026年までのP(PAUSE)とP(TAISC|PAUSE)の推計に重点を置いたが、これは関連する時間間隔や実施可能な政策をすべて網羅していない可能性がある。より広範な時間枠と潜在的な政策介入を含むように分析を拡大することで、さらなる洞察が得られるかもしれない。2026年という日付は、より正確で実行可能な予測を提供するために選んだものであるが、これは最終的にTAISCと同様の一時停止や条約が結ばれる確率を過小評価するものであることに留意すべきである。
未解明の政策: 6ヵ月モラトリアムやTAISC以外の政策は、特にP(AIキャタストロフ|一時停止とTAISC以外)を推定する際に、予測担当者が必然的に考慮したであろうが、我々はこれらの効果を明示的かつ個別に調査し、それらについての確率推定値を直接作成したわけではない。代替政策の効果を調査し、その確率を個別に推定することで、より包括的な理解が得られる可能性がある。
因果効果と証拠効果: 一般に、条件付予測において因果的効果と証拠的効果と呼ばれるものを分離することは非常に困難である。これらの考察のいくつかは、我々の理論的根拠で説明されている。この問題は、P(PAUSE)とP(TAISC|PAUSE)の推定値を作成した主な動機であり、我々の予測を現実に立脚させ、我々が作成した他の確率推定値が現実的な可能性のある未来に適合していることを確認するためであった。
この問題の難しさの一例を示すために、明日TAISCが署名され、魔法によって批准されるという仮定の状況について予測し、そこから因果効果を真にとらえたいと思う人もいるかもしれない。しかしこの場合、条約締結国は現在と同様にこの条約を実施する意欲を失っているため、推定される効果は誤解を招くほど小さくなる可能性がある。
最も重要なのは、条約が実施されても誰もそれに従う意志がないという、まったく非現実的な状況であることだ。私たちのアプローチでは、少なくとも、これらのシナリオが生じうる最も現実的な方法で、これらの異なる政策シナリオにおけるAIの大惨事リスクの違いを予測したと言うことができる。これはまた、私たちの実績からすれば、こうした条件付きの質問については、今後も正確でよく較正された結果を期待できるということでもある。
改善すべき点
TAISCは、高度なAIシステムに関連する存立リスクの軽減を目的としたAI条約に不可欠な概念を導入しているが、これは出発点として意図されたものであり、終着点ではない。計算上限の数値から規制対象のニュアンスに至るまで、対処すべき固有の課題がある。TAISCは、将来的により包括的な合意を促し、政策的な議論を改善することを目的とした、最初の草案または青写真として機能することができる。
このような条約は、特定の分野での改善を必要とする:
- 計算基準値の選択: 計算量のしきい値の選択:TAISC for a Large Training RunとJAISLモデルの暫定的な数値は、それぞれGPT-3とGPT-4の訓練に使用された計算量に固定することで開発された。我々は、より合理的な数値は他の人が導き出すことができると考えている。
- 標準的なFLOPの定義: 標準的な FLOP の定義:浮動小数点演算(FP16 加算、FP32 加算など)により使用する計算量が異なるため、量子化 8 ビットも定義に含めることが望ましい。
- 別の規制対象: 本条約では計算を対象としているが、モデルのパラメータ数、トレーニングされたデータ、能力の評価、安全性とアライメントの評価など、真剣に検討すべき指標は他にもある。コンピューティングクラスターの場合、集約された帯域幅も考慮する必要がある。
- 規制対象の悪用可能性: また、モデルとは何か、1回のトレーニング実行とは何か、データ収集、トレーニング、推論の境界はどこにあるのか、その結果、モデルにはいくつのパラメータがあり、トレーニングにどれだけの計算が費やされたのか、といったことを静的に定義することには、基本的な困難があるかもしれない。モデルが特定の能力を持つかどうか、あるいは特定の用途に再利用できるかどうかを判断する手順もまた、利用可能であろう。この問題は、どのような条約においても考慮されるべきである。
- 実施の詳細: TAISCは加盟国による実施を要求し、その具体的な方法を例示しているが、どのように実施すべきかの詳細については、さらに検討する必要がある。Shavitの “What does it take to catch a Chinchilla?”(チンチラを捕まえるには何が必要か)には、ハイレベルの解決策が提案されている。
- ジョイントAIセーフティラボラトリー(JAISL)の詳細: JAISLの具体的な建設方法、さらには建設場所の詳細について検討する必要がある。利害の対立する人々に取り込まれないような機関を設計することが最優先されるべきである。
また、JAISLを2つのラボに分けることが最善かどうか真剣に検討すべきである。1つは、最も高性能な許容モデルへのアクセスを提供するラボであり、もう1つは、AIの安全性とアライメント研究に焦点を当てるラボである。
結論
高度なAIシステムがもたらす存亡の危機に対処するには、早急な対応と長期的な戦略的アプローチの両方が必要である。我々の専門家予測チームの洞察に基づく分析によると、強力なAIシステムの開発を一時停止することは、AIの安全対策を振り返り、再評価するための重要な機会となり得ることが明らかになった。
同時に、我々の予測チームは、AIの安全性と国家間の協力を促進する国際協定に大きな価値があると考えている。人工知能の安全性と協力に関する条約(TAISC)は、AIのリスクに対処し、グローバルなコンセンサスを醸成するための構造化されたアプローチを備えており、そのような協定の有用な青写真となりうる。
AIリスクの低減を目指した研究への粘り強い関与と一貫した投資が鍵となる。TAISCの指導原則の精神に則り、国際的な協力と安全をAI開発の中心に据えることで、人類の安全と福祉を損なうことなく、より安全で責任あるAIの恩恵の探求への道を開くことができるだろう。
国際社会全体で共有されるこのイニシアチブの責任には、国際条約をめぐる議論への積極的な関与と、既存の提案を洗練させ、新たな提案を普遍的に採用可能な規制に育てるための協調的な努力が必要である。AIが我々の安全を脅かすことなく、我々の未来を豊かにする、良い方向への変革の力となることを確実にするためには、AIリスクの低減に向けたこのような集団的努力が不可欠である。これらのリスクを認識し、積極的に対処することによってのみ、AIが人類の向上のために強力かつ安全なテクノロジーとして機能する未来を形作ることができるのだ。
Samotsvety Forecastingとは?
Samotsvety Forecastingは、ミーシャ・ヤグディン、ヌーニョ・センペール、イーライ・リフランドによって設立された専門家予測家グループである。このグループは様々な予測コンテストで常に優秀な成績を収めており、メンバーはINFER(旧Foretell)、Good Judgment Open、Metaculusなどのプラットフォームで顕著な成功を収めている。彼らの実績に関する詳細情報は、こちらを参照されたい。
予測競技は、予測者が将来の様々な出来事の可能性を予測しようとするものである。例えば、参加者は “2024年1月1日までに、世界のどこかで核兵器が爆発するか?”と問われるかもしれない。このようなコンペティションでは、予測者は自分の予測を表すために10%といったパーセンテージの確率を提示する。
これらの予測の質を評価するために、いくつかの重要な指標が用いられる:
- キャリブレーション:
- アライメント:予測された確率が、多くの予測にわたって実際の結果とどの程度アライメントされたかを反映する。
- 例えば、10%の予測は、約10%の確率で起こる結果に対応するはずである。
- 精度(Brier Score):
- 予測された確率と実際の結果との平均二乗差を測定する。
- スコアが低いほど精度が高いことを示す。
- 相対的精度(Relative Brier Score):
- ある予測者やモデルのパフォーマンスを、他の予測者やモデル、あるいは参照/ベースラインと比較する。
- 基本的に、精度が予測の良し悪しを示すのに対して、相対精度は他と比較して予測の良し悪しを示す。
このようなコンペティションで成功している予報者やチームは、これらの指標で常に良いスコアを達成している。サモツベティの予測は『ワイアード』でも取り上げられている。サモツベティは、人気ブログ「アストラルコデックス・テン」で次のように紹介されている: このチームは世界最高のスーパー・フォアキャスターのチームだ。彼らはCSET-Foretell予想大会で、とんでもない大差をつけて優勝した。予想大会の意義が、誰が信頼できるかを見極めることであるならば、科学は語り、答えは “彼ら”である』。
チームの実績
サモツベティ予想は、INFER(旧Foretell)で2020年、2021年、2022年に1位を獲得するなど、複数の予想大会でリーダーボードを独占している。
個人の実績
サモツベリー・フォーキャスティングのメンバーは、様々なリーダーボードで1位を獲得するなど、個人でも高い実績を残している。チームには、コンピューターサイエンス、経済学、人工知能、研究、金融、疫学、バイオセキュリティ、データサイエンス、哲学など多様な分野の専門家が所属している。メンバーの何人かはスーパー予測者の資格を持っている。
謝辞
Tolga Bilge、Jonathan Mann、Vidur Kapur、Jared Leibowich、Eli Lifland、Molly Hickman、Nuño Sempere、Alex Lyzhov、Greg Justiceの予測提供に感謝する。
ジョナサン・マン、イーライ・リフランド、フィン・ハンブリー、シメオン・カンポスには、このプロジェクトに多大な協力をいただいた。国際法においてより一般的に使用されているTAISC言語の導入に協力してくれたJosé Jaime Villalobosに感謝する。
[1] オッズの幾何平均を用いた理由は、Jaime Sevillaによるこの投稿に基づく。私たちの算術平均はそれほど大きな差はなかった。
A 30% Chance of AI Catastrophe: Samotsvety’s Forecasts on AI Risks and the Impact of a Strong AI Treaty
