Discrepancies between meta-analyses and subsequent large randomized, controlled trials
pubmed.ncbi.nlm.nih.gov/9262498/
概要
背景
メタアナリシスは、臨床戦略をサポートするエビデンスを提供するために広く使用されている。しかし、臨床的介入の有効性を評価するには、大規模な無作為化比較試験がゴールドスタンダードであると考えられている。
研究方法
4誌(New England Journal of Medicine、Lancet、Annals of Internal Medicine、Journal of the American Medical Association)に掲載された大規模な無作為化比較試験(1,000人以上の患者を対象)の結果と、同じテーマで以前に発表されたメタアナリシスの結果を比較した。主要および副次的なアウトカムについて、無作為化試験の結果が対応するメタアナリシスの結果と一致するかどうかを判断し、試験結果が従来の統計的有意水準(P<0.05)でポジティブ(治療によりアウトカムが改善したことを示す)またはネガティブ(治療をしてもしなくてもアウトカムが変わらないまたは悪化したことを示す)であるかどうかを判定した。
結果
同じ問題を扱った12件の大規模な無作為化対照試験と19件のメタアナリシスを確認した。合計40の主要および副次的なアウトカムについて,メタアナリシスと大規模臨床試験の間の一致は,わずかに公正であった(κ=0.35;95パーセント信頼区間,0.06~0.64)。メタアナリシスの陽性的中率は68%、陰性的中率は67%であった。しかし、無作為化試験とメタアナリシスの間の点推定値の差が統計的に有意であったのは、40件の比較のうちわずか5件(12%)であった。さらに、意見が分かれた各ケースでは、一方の方法では治療の統計的に有意な効果が認められたが、もう一方の方法では統計的に有意な効果は認められなかった。
結論
我々が調査した12の大規模ランダム化比較試験の結果は、同じテーマで過去に発表されたメタアナリシスによって35%の確率で正確に予測されなかった。
大規模な無作為化比較試験は,一般に,臨床介入の有効性を評価する際のゴールドスタンダードと考えられている。しかし,そのような試験が常に行われているわけではないため,臨床家は臨床戦略の選択をメタアナリシスに頼ることが多くなっている。メタアナリシスには本質的な弱点があると批判されている1-5。プールされた結果には、個々の研究のバイアスが含まれており、主に研究の選択とそれらの間の必然的な異質性のために、新たなバイアスの原因を体現している。
はじめに
メタアナリシスの長所と短所については多くのことが語られているが、いくつかの小規模試験のメタアナリシスの結果と大規模無作為化対照試験の結果を系統的に比較したデータは限られている。Villarら6は,Cochraneデータベースに登録されている周産期医療のさまざまな介入に関する30件のメタアナリシスをレビューした。彼らは、各メタアナリシスの結果から最大規模の試験を除外して再計算し、その結果を除外した大規模試験の結果と比較した。その結果、kappaは0.46~0.53,陽性適中率は50~67%であった。我々は、体系的にまとめられた一連の大規模ランダム化比較試験の結果を、以前に発表された関連するメタアナリシスの結果と比較した。
方法
データベース
New England Journal of Medicine,Lancet,Annals of Internal Medicine,Journal of the American Medical Associationを検索し,1991年1月1日から 1994年12月31日までに発表された大規模な無作為化比較試験(1,000人以上の患者を対象としたもの)をすべて収集した。すべての試験は、著者が指定した望ましいベネフィットを検出するのに十分な統計的検出力を有している必要があった。十分な検出力は,著者が論文の「方法」の項で報告した検出力の先験的な計算に基づいて定義された。次に,大規模な無作為化比較試験の前に発表された,類似したテーマのメタアナリシスを検索した。検索には,無作為化試験に記載されている参考文献と,言語制限のないコンピュータによるMedlineの検索を用いた。次に,各臨床試験とそれに対応する一連のメタアナリシスを比較し,研究対象の集団,治療的介入,少なくとも1つのアウトカムの類似性に関して,臨床試験と一致するメタアナリシスのみを選択した。主要なアウトカムと副次的なアウトカムを調査した。
大規模ランダム化比較試験とメタアナリシスの両方で検討された各結果について、従来の統計的有意水準(P<0.05)で、結果が正(治療により良い結果が得られたことを示す)か負(治療により同等または悪い結果が得られたことを示す)かを判断した。互いに独立した2人の研究者が、各試験とそれに対応するメタアナリシスをレビューした。不一致は、第3者の協力を得て、コンセンサスによって解決された。観察者間のばらつきの影響を定量化するために,感度分析を行った。統計計算は,コンセンサスで得られたデータを用いて行い,反対意見の研究者の意見に対応するデータを用いて繰り返し行った。
統計解析
2対2の表を用いて,大規模無作為化比較試験とそれに関連するメタ解析の間の一致度を,カッパ統計値とその95%信頼区間で表すとともに,感度,特異度,陽性予測値,陰性予測値を計算した。各ペアの点推定値は,比率または平均値の差を分散の総和の平方根で割った検定統計量を用いて比較した。
図1.大規模な無作為化対照試験の結果を、少なくとも1つの共通のアウトカムが調査された同一対象の1つ以上のメタアナリシスの結果と比較した研究群のオッズ比と95%信頼区間
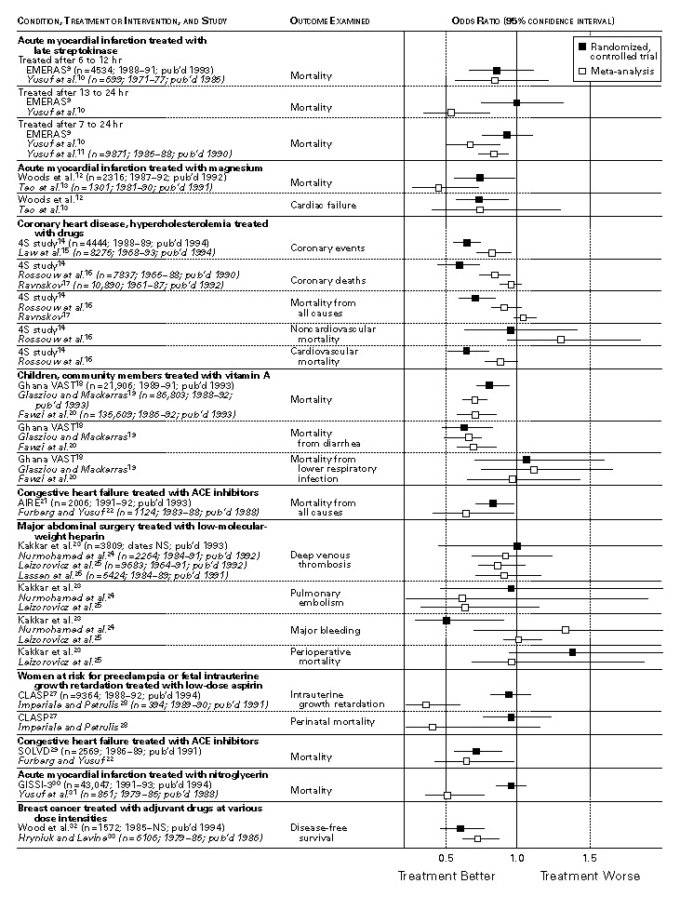
図2 大規模な無作為化対照試験の結果を、少なくとも1つの共通のアウトカムが調査された同一対象の1つ以上のメタアナリシスの結果と比較した研究群における治療効果およびオッズ比を変換した後の95%信頼区間
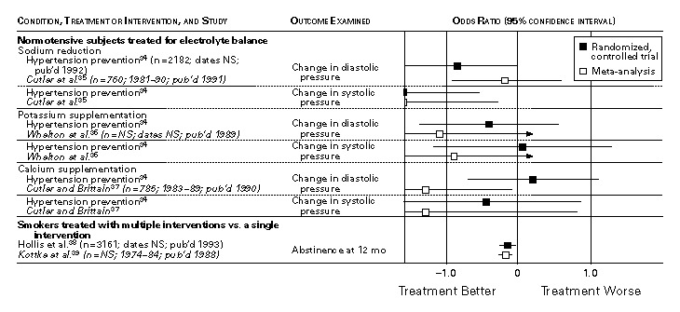 無作為化比較試験とメタアナリシスのオッズ比をグラフで表した。メタアナリシスの結果が二分法のオッズ比として示されていない場合は、固定効果のMantel-Haenszel法によりオッズ比とその95%信頼区間を算出した7。メタアナリシスで治療効果の大きさを表すオッズ比が算出できなかった場合は,対応する無作為化比較試験のオッズ比を,各群の割合を0と1の分布の平均値として扱うことで,効果の大きさに変換した8.図1は固定効果法で算出したオッズ比を,図2はオッズ比を変換して得た効果量を示している。P値が0.05未満の場合は統計的有意性があるとみなした。計算および統計的検定は,すべてSAS統計パッケージ(SAS Institute, Cary, N.C.)を用いて行った。
無作為化比較試験とメタアナリシスのオッズ比をグラフで表した。メタアナリシスの結果が二分法のオッズ比として示されていない場合は、固定効果のMantel-Haenszel法によりオッズ比とその95%信頼区間を算出した7。メタアナリシスで治療効果の大きさを表すオッズ比が算出できなかった場合は,対応する無作為化比較試験のオッズ比を,各群の割合を0と1の分布の平均値として扱うことで,効果の大きさに変換した8.図1は固定効果法で算出したオッズ比を,図2はオッズ比を変換して得た効果量を示している。P値が0.05未満の場合は統計的有意性があるとみなした。計算および統計的検定は,すべてSAS統計パッケージ(SAS Institute, Cary, N.C.)を用いて行った。
結果
12件の大規模な無作為化比較試験が確認され,そのうち19件のメタアナリシスが,研究対象の集団,治療介入,少なくとも1つの結果の点で一致した。主要なアウトカムと副次的なアウトカムの両方を考慮したため、合計40のアウトカムが一致し、分析に含まれた。
表1 無作為化比較試験とメタアナリシスが一致した40例の一致・不一致
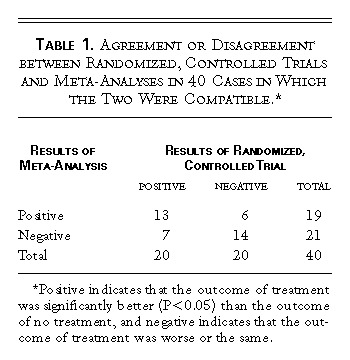
表2 メタアナリシスが大規模ランダム化比較試験の結果を予測する能力を測定する変数
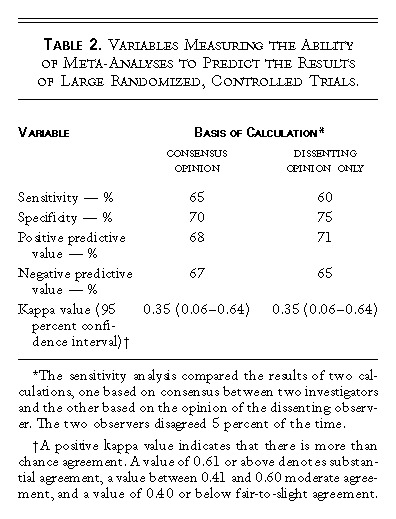
表1は,後続の大規模無作為化対照試験の結果を予測するものとしてのメタアナリシスの性能を評価する際の根拠となったデータである。メタアナリシスは,通常,診断テストを評価する役割を果たし,試験はゴールドスタンダードと考えられている。表2は,感度,特異度,陰性予測値,陽性予測値の結果を示したものである。コンセンサス・オピニオンの結果は,いずれも平均的な診断テストで通常得られる値に相当する範囲の値(65〜70%)であった。偶然性だけによる一致を超えた一致を測るカッパ統計値は,0.35(95%信頼区間,0.06〜0.64)でした。カッパ値が0.40以下であれば、公正で軽度の一致を示していると考えられる。また,表2には,感度分析の結果も示した。これは、研究者間のコンセンサスに基づいて計算した場合の結果と、反対意見を持つ研究者の意見に基づいて計算した場合の結果を比較したものである。
図1と図2はその結果をグラフ化したもので、各比較対象のクラスタに関する最も適切な情報が含まれている。統計的な有意性とは無関係に、40件の比較のうち32件(80%)で点推定値が図1では1.0の側に、図2では0の側にあることが示された。一方が統計的に有意な治療効果を示し、他方がそのような効果がないことを示したため、すべての不一致が発生した。無作為化臨床試験とメタアナリシスの間に統計的に有意な差があったのは、40件の比較のうち5件(12%)であった。
固定効果モデルを用いた4つのメタアナリシス10,28,31,37のうち5つのポジティブな結果の後に、ネガティブな無作為化臨床試験が行われた。これらのアウトカムのうち4件については、ランダム効果モデルを用いて統計解析をやり直すのに必要な情報があり、4件とも統計的に有意な結果が得られた。
以下の6つの臨床的事項に関しては、メタアナリシスと無作為化臨床試験の間に非常に良い一致が見られた。
- 心筋梗塞患者の全死亡率に対するマグネシウムの効果12,13,
- 冠動脈疾患患者の冠動脈イベントおよび心血管疾患による死亡率に対する高コレステロール血症治療の効果14-16,
- 発展途上国の子どもの全死亡率および下痢による死亡率に対するビタミンA補給の効果18-20。 18-20
- アンジオテンシン変換酵素阻害剤がうっ血性心不全患者の死亡率に及ぼす影響21,22
- 乳がん患者の無病生存率に対するアジュバント療法の効果32,33
- 禁煙における単独介入と比較した複数介入の価値 38,39 38,39
他のいくつかのケースでは、かなりの相違が見られた。
心筋梗塞患者の死亡率に対する遅発性血栓溶解療法(心筋梗塞の最初の症状が出てから少なくとも6時間後に行われる血栓溶解療法)9-11とニトログリセリンの効果については、メタアナリシスでは肯定的な結果が得られたが、その後に行われた大規模な無作為化比較試験の結果は1.0の肯定側であったが、統計的には有意ではなかった。これらの例では、無作為化比較試験にはメタ解析よりも多くの患者が含まれていたため、統計的検出力が問題になることはなかった。子癇前症のリスクがある女性に低用量アスピリンを投与して子宮内発育遅延を予防するかどうかという問題に関しては、わずか394人の患者を対象とした明らかに肯定的なメタアナリシス28に続いて、9364人の患者を対象とした非常に大規模な無作為化比較試験で否定的な結果が出た27。
大規模ランダム化比較試験の実施は、臨床医や研究者がメタ分析で結論が出ないと判断したときに決定された可能性があるため、対応する臨床試験で最初の患者がランダム化された時点で、そのメタ分析がすでに発表されていたかどうかを調べた。12件の臨床試験のうち4件9,21,30,38は、対応するメタアナリシスが発表された後に開始されたことが明らかであり、おそらく設計されたものと思われる。この4つの試験のうち、9,30の2つの試験(血栓溶解療法とニトログリセリンによる治療の利点を評価)では、メタ解析の結果とは異なる結果が得られた。つまり、否定的な無作為化比較試験では、肯定的なメタ解析の結果を確認することはできなかった。
考察
治療的介入の効果を評価するゴールドスタンダードとして、大規模なランダム化比較試験を用いることに異論を唱える人はほとんどいないだろう。私たちの系統的研究の過程で発見された1つを除くすべてのメタアナリシスは,臨床実践に影響を与える立場にある主要な査読付き雑誌に掲載されていた。
あるメタアナリシスが特定の無作為化比較試験に対応しているかどうかを判断するために用いた戦略は,方法論的な問題を提起するものである。研究が適格であるためには,研究対象の集団,治療的介入,および少なくとも1つの結果が類似していなければならない。このような類似性には判断が必要な場合もあり、観察者によってばらつきが生じる可能性がある。2人の研究者にそれぞれの一致の妥当性を独立して判断してもらうことで、ばらつきを定量化し、調整することができた。感度分析(表2)によると、コンセンサスに基づいて計算した場合も、反対意見を持つ調査官の意見に基づいて計算した場合も、我々の結果は基本的に同じであった。もうひとつの方法論的な問題は、結果を肯定的か否定的かの二分法で分類したことにある。この方法を選択した理由は、メタアナリシスの結果を臨床に応用すべきかどうかが関心のある結果だったからである。臨床判断は、ある治療法が効いて推奨されるか、効かなくて推奨されないかの二項対立になりがちである。
我々の分析によると、もしその後に無作為化比較試験が行われなかった場合、メタアナリシスは32%のケースで効果のない治療法を採用し(100%から正の予測値を引いた値)33%のケースで有用な治療法を拒否したことになる(100%から負の予測値を引いた値)。医学的な意思決定の観点から構築されたこれらの不一致の尺度は、統計的な不一致の度合いを過大評価する傾向があることを認識することが重要だ。このことは,無作為化臨床試験とメタアナリシスが統計的に有意で正反対の答えを出すような分岐点がなかったことからも明らかである。さらに、点推定値が「差がない」という線に対してどの位置にあっても、メタアナリシスと無作為化比較試験の結果の差が統計的に有意であったのは、40件の比較のうち5件(12%)に過ぎなかった。これは、5%のケースの分岐が偶然だけで予想されるため、大きな割合ではないと思われる。
我々の研究では、結果の分岐の46%は、肯定的なメタアナリシスの後に否定的な無作為化対照試験が行われてた。メタアナリシスで肯定的な結果が得られても,その後の試験では確認できない理由はいくつかある。Publication bias(出版バイアス)とは,研究者が肯定的な結果の研究を優先的に出版に付す傾向と,編集者がそれを受け入れる傾向のことを指す。未発表の研究を除外したり,探し出して掲載しなかったりしたメタアナリシスでは,偽陽性の結果が出る可能性が高くなる。また,英語以外の言語で書かれた論文を系統的に除外すると(「バベルの塔」バイアス40)、出版バイアスが増大する可能性がある。我々のサンプルでは、信頼区間を狭める固定効果モデルの使用は、統計的にポジティブなメタアナリシスの結果が、その後の無作為化試験で確認されなかったことを説明していないように思われる。というのも、ランダム効果モデルで再分析できる4つの研究はポジティブなままであり、再分析を行っても統計的に有意な結果が継続したからである。
残りの54%は、否定的なメタアナリシスの後に肯定的な無作為化比較試験が行われてた。メタアナリシスでは、このような変動は、選択された研究の特性の違いによるものではなく、ほとんどがランダムな誤差によるものであると想定されているため、メタアナリシスに含まれる試験の不均一性が、この種の乖離を部分的に説明している可能性がある。適切に行われたメタアナリシスでは,患者の組み入れ,主要な治療の実施,転帰イベントの確認に用いられた基準が,選択されたすべての試験で同様であることを保証するために,先験的に厳格な基準が決定されている。この厳格な基準によると、選択された試験のプロトコルは非常によく似ているが、それらを適用すると、通常、非常に異なる製品が得られる。比較可能な試験に登録された患者は、同じ基本的な集団に属しているかもしれないが、診断、併存疾患、重症度、年齢などの基準がわずかに異なるだけで、非常に異なる患者群が生まれる。また、治療介入を評価する目的でメタアナリシスに組み入れられた試験でも、投与量、発症までの時間、治療期間などの違いにより、大きな格差が生じることがある。また、併用療法の選択やその投与方法の自由度も結果に影響を与える。また,メタアナリシスの対象となる臨床試験は10年以上の期間をかけて行われることが多いため,時間の経過に伴う医療行為の変化が併用療法の重要な違いを説明することもある。
無作為化臨床試験との系統的な比較により、メタアナリシスの予測能力が低いことが明らかになっているが、臨床家はどのようにメタアナリシスを利用すべきであろうか。大規模でよくできた無作為化試験が実施されていれば、診療ガイドラインはその結果に強く影響されるべきであるということに、多くの人が同意するであろう。問題は、入手可能な唯一のエビデンスが、一連の小規模な無作為化比較試験から得られたものである場合に生じる。最もシンプルな解決策であり、現在最も普及しているのは、メタアナリシスの結果に頼ることである。我々の発見は、一連の試験に含まれるすべての情報を単一のオッズ比に要約することは、極めて複雑な問題を大幅に単純化しすぎる可能性があることを示しているようだ。メタアナリシスが人気なのは,査読者や読者の生活を単純化し,楽にしてくれることが一因となっているのかもしれない。しかし,単純化しすぎると,不適切な結論を導く可能性がある。
本研究の結果は、読者に対して、メタ解析の結果を示す点推定値や信頼区間を超えて、Cookらが提案したように41,対象となった研究を注意深く見て、その結果の一貫性を評価することを促しているように思われる。結果がほとんど無差線の同じ側にあれば、メタアナリシスはより信頼性の高いものとなる。また、Horwitz42の助言に従って、各試験を個別に評価することを考える人もいるであろう。このようなアプローチは確かに手間がかかるが、実際的な臨床家にとっては、多様な研究の中から治療効果を区別して恩恵を受けることができるという利点がある。
本報告書の作成にあたり、Jean-François Boivin博士には有益なご意見をいただき、Hélène Harnois氏とAnita Massicotte氏には事務的な支援をいただいた。
著者の所属
Hôtel-Dieu de Montréal病院研究センターおよびモントリオール大学医学部医学科(いずれもモントリオール市)出身。
転載のご依頼は、Research Center, Hôtel-Dieu de Montréal, 3850 St. Urbain St., Pavilion Marie de la Ferre, 2nd Fl., Montreal, QC H2W 1T8, CanadaのDr.
