
Contents
Critical Analysis of a Randomized Controlled Trial
Balkrishna D Nimavat,1 Kapil G Zirpe,2 and Sushma K Gurav3
要旨
エビデンスに基づいた医療の時代、医療従事者は多くの臨床試験や論文を目の当たりにするが、その中でも無作為化対照試験はエビデンスのレベルの高さから見ても、その縮図と言えるであろう。無作為化比較試験の知識をバランスよく身につけ、臨床の場で試験結果の解釈を誤らないようにすることは非常に重要である。無作為化対照試験を批判的に評価するためには様々な方法やステップがあるが、それらは解釈が複雑になりすぎている。無作為化比較試験の解析には、もっとシンプルで実用的なアプローチがあるはずだ。
この記事では、5つの見出しの下にいくつかの実践的なポイントをまとめてみたいと思う。”無作為化比較試験の重要な分析の5つの「R」は、正しい質問、正しい母集団、正しい研究デザイン、正しいデータ、正しい解釈を網羅している。この論文は、無作為化比較試験の分析は、統計的知見や結果だけに基づくものではなく、その中核となる質問、関連する母集団の選択、研究デザインの頑健性、アウトカムの正しい解釈を体系的に検討することが重要であるという洞察を与えてくれている。
キーワード
批判的分析、エビデンスに基づいた医療、無作為化対照試験
序論
“Statistics are like bikinis. What they reveal is suggestive, but what they conceal is vital.”
[Aaron Levenstein]
“統計はビキニのようなものだ 彼らが明らかにするものは示唆的であるが、彼らが隠すものは重要である。”
[アーロン・レーベンシュタイン]
知識を最新の状態に保つことは、エビデンスに基づいた医療の世界では極めて重要である。時には、医療法の観点からも、また、現在の最良の実践を改善するためにも、それは非常に重要なことである。このような背景から、毎日多くの論文や試験が様々な雑誌に掲載されている。研究デザインの中でも、無作為化比較試験(RCT)はエビデンスの強さの点で最高とされている。適切に計画され、精力的に実施されたRCTは、介入に関連したアウトカムの違いを見るための最良の研究デザインであるが、同時に、実施が不十分で偏ったRCTは読者を惑わせてしまう。RCTを読んで臨床実習を最適化することは理想的であるが、その結果や結論に独断的になる前に、それらのRCTの強い点と弱い点を理解することが重要だ。RCT の評価方法はいろいろあるが、今回は、5 つの見出しの下に、より理解しやすくするためのニーモニックな 5’Rs を用いて、ポイントを簡略化してみた(フローチャート 1)。
「RCTの批判的分析」の発表
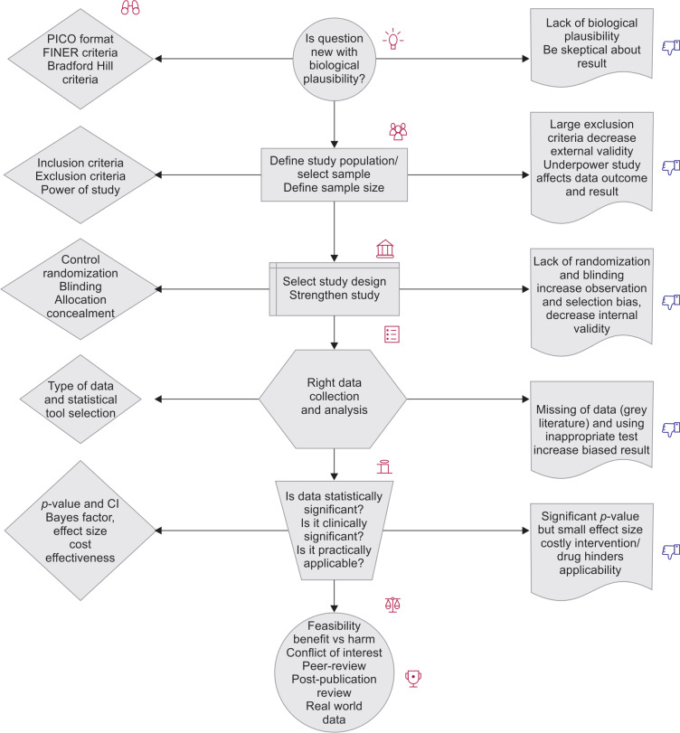
無作為化対照試験の批判的分析のためのステップ
正しい質問の定式化/正しい質問への対応
クロード・レヴィ=ストロースが言ったように、「科学者は正しい答えを出す人ではなく、正しい質問をする人だ」。
革新的であること、実践を変えること、知識を増幅させること、そして何よりも生物学的に妥当性があることなどの特徴を持っている問題を探すことが重要だ。
無作為化対照試験は新しい/重要な質問に対応しているか?この質問への回答は、現在の臨床実践や知識を向上させるのに役立つより多くの情報につながるのか?
話題のいずれかから生じる質問には、ほとんどの場合、バックグラウンド質問とフォアグラウンド質問の2つのタイプがある。RCTは、通常、より具体的に介入/薬剤とその効果/結果の関係を確立するためのフォアグラウンドな質問を対象とした実験計画である。フォアグラウンド研究の質問は、母集団、介入、対照、アウトカム(PICO フォーマット)のような関連情報を得るための 4 つの要素から構成されている。研究課題と研究デザインが関連する母集団に対して倫理的で実現可能かどうかは、FINERの基準で決定することができる1。
アウトカムとは、希望する母集団に対する介入の影響の有無を観察するために、研究中にモニターされる変数のことである。アウトカムとは、目的とする集団に対する介入の影響の有無を観察するために試験中にモニターされる変数である。最も一般的な臨床エンドポイントは死亡率、罹患率、QOLである。エンドポイントを選択する際には、その背景知識と定式化された問題との関連性を考慮して、適切なエンドポイントを選択することが重要だ(図 1)。
図1 エンドポイントの種類とその長所・短所
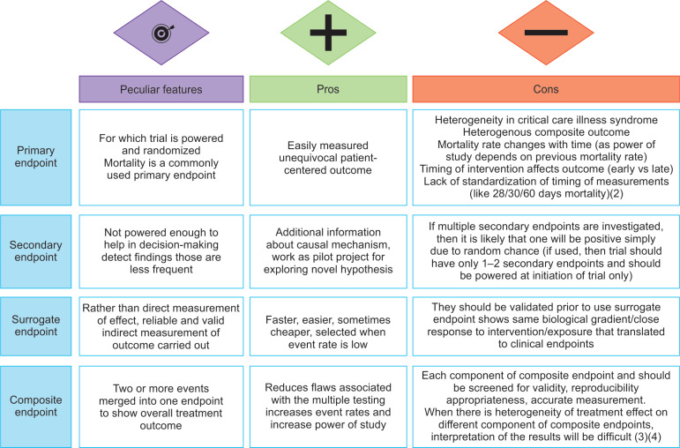
したがって、単一のエンドポイントが完璧なものではないことは明らかであるが、エンドポイントは臨床的な疑問、パワー、ランダム化の文脈の中でアクセスされるべきである。
原因と効果は生物学的妥当性を持っているか?
生物学的妥当性は、相関が因果関係を意味することを立証するために不可欠な要素の一つである。生物学的に妥当性のない単なる関連性や有意なp値を持つことは、死んだ馬を叩くようなものである(純粋に懲罰的)。つまり、統計的に有意なデータは意味がないか、生物学的に妥当性を欠いている場合は慎重に解釈すべきであり、統計的に有意性を与えることができないが、精力的に行われた研究で生物学的に妥当性が高いデータは、却下される前に再度評価し、議論すべきである5。
相関関係が因果関係と同等かどうかを判断するためには、多くの基準や方法がある。また、生物学的な妥当性に関する知識は動的であり、時間とともに進化していくものであることを理解することも重要である。本当の因果関係があっても、その時点での生物学的知識では説明がつかないことがある(表1)。
表1 要因は、健全な質問1,6を策定するのに役立つ
| PICOフォーマット | より細かい基準 | ブラッドフォードヒルの因果関係基準 |
|---|---|---|
| 人口 | 実行可能 | 連想の強さ(効果量) |
| 介入 | 面白い | 一貫性(再現性) |
| コントロール | 小説 | 特異性 |
| 結果 | 倫理的 | 一時性(影響前の原因) |
| 関連する | 生物学的勾配(用量勾配応答) | |
| 実験的証拠 | ||
| 生物学的妥当性 | ||
| コヒーレンス | ||
| 類推 |
正しい集団
対象母集団の定義/サンプルは本当に母集団を代表しているのか?
RCTは通常、母集団全体ではなく、集団(サンプル)を対象に実施される。試験では、選択されたサンプルが他の集団のベースライン特性を本当に表しているかどうかが重要だ。また、サンプルから母集団への推論的飛躍や一般化もそれほど単純ではなく、完全な証明にはならないことがほとんどである。
RCTにおける外部妥当性とは、研究結果が現実の集団にどの程度まで一般化できるかを示すものである。内部妥当性は、どれだけ精力的に試験が行われ、ロバストなデータが得られているかを示すものである。内部妥当性が低いと、その試験で得られた結果は、データの質が悪くなる可能性が高く、そのサンプルにバイアスがかかる可能性が高くなるため、その試験で得られた結果をしっかりと利用することができない。外部妥当性の限界とは、試験のサンプルや定義されたサンプルが母集団の残りの部分の真の代表ではないことを意味する。簡単に言えば、内部妥当性に疑問がある場合には、より大規模に適用することは無意味であり、外部妥当性が限定されている(大きな除外基準を持つ)試験の場合には、RCT の結論を他の母集団に適用することは慎重に行わなければならず、信頼性が低いということになる。外部妥当性は、包含基準と除外基準を変更することで改善されるが、内部妥当性は、より多くの変数を管理する(交絡因子を減らす)無作為化、盲検化、測定技術の改善、対照群/プラセボ群の追加などで改善される。
対象集団のサイズ/サンプルサイズは適切か?
もう一つの重要なステップは、統計的に有意な臨床差を与える適切なサンプルサイズを選択することである。サンプルサイズの推定は試験前にのみ行うべきであり、統計学的な誤差を防ぐために試験中にずれが生じてはならない。試験サイズは、許容可能な有意水準(α誤差)試験の力、期待される効果の大きさ、母集団のイベント率(有病率)代替仮説、母集団の標準偏差などの複数の要因に影響される。標本サイズの計算式もあるが、各要因と標本サイズとの関係を理解することの方が重要である8。
8 効果の大きさが大きい現象や関連性の場合には、サンプルサイズが小さくても目的は達成される。従来の考え方では、サンプルサイズが大きいと良いとされていたが、必ずしもそうとは限らず、サンプルサイズが大きいと臨床的に有意ではない差が浮き彫りになる。また、有病率の低い疾患(レアイベント)では、RCT(観察研究で目的を解決する)を行うことができない。
サンプルサイズの推定に用いられるツールは「研究の力」である。調査力とは、その研究においてⅡ型誤差を回避するために必要な研究集団がどれだけあるかを表している。調査力は、任意の標本内での測定の精度や分散、効果の大きさ、タイプIエラーの許容レベル、実施している統計的検定のタイプなどの可変的な要因に依存する。
正しい研究デザイン
実験計画は、それらが変数のより良いグリップを持っており、因果関係の仮説が確立することができるように、観察計画よりも優れていると考えている。実験的研究の設計は再び前実験的、準実験的、および真の実験的に分けられる。準実験的、真の実験的デザインは、グループの無作為化の有無によって区別される。無作為化対照試験は真の実験的デザインであり、内部妥当性が著しく高く、無作為化が存在することから、他のデザインよりも高いエビデンスの質を提供する。しかし、RCTには、複雑な研究デザイン、費用がかかること、倫理的に問題があること(介入や薬の使用が制限されること)時間がかかること、希少な疾患や病態への適用が難しいことなどの制約がある。
研究デザインを強化する/バイアス(選択バイアス、競合バイアス)を低減するための対策がとられているか?
インターベンショナルスタディ/RCTは、臨床病態に対する新しい治療法の有効性と安全性を観察するために設計されており、特にアウトカムが偶然に起こらないことが重要である。交絡因子やバイアスを減らすためには、対照群の選択、無作為化、盲検化、割り付けの隠蔽などの様々な戦略が有効である。対照群は、より信頼性の高い介入効果を導き出すための比較に用いられる。対照群には4つのタイプがある。(1)ヒストリカル、(2)プラセボ、(3)アクティブコントロール(標準的な治療が使用されている場合)、(4)用量反応型コントロール(介入群と比較して介入の用量/勾配が異なる場合)の4種類である。無作為化は選択バイアスと交絡バイアスを減らすのに役立つ。無作為化には、コンピュータで作成したものや、教科書に載っている乱数表を用いて行うことができる。無作為化の技術には、単純無作為化、ブロック無作為化、層別無作為化、クラスター無作為化などの異なるタイプがある。サンプル数が少ない場合、サンプル無作為化の信頼性が損なわれる。ブロック無作為化は、サンプルサイズが大きく、追跡期間が長い場合に適した方法である。また、ブロックサイズが研究者に開示されないことが重要であり、可能であれば、予測可能性を避けるために、ブロックサイズは時間とともに変化し、ランダムに分布するべきである。層別無作為化は、転帰に影響を及ぼすことが知られている特定の変数がある場合に使用される。クラスター無作為化では、個人ではなくグループが無作為化される。盲検化は、観察バイアスを減らすための方法である。研究は、オープンラベル化/非盲検または盲検とすることができる。盲検化には、参加者の盲検化、観察者/調査者の盲検化、データ分析者の盲検化などの異なるタイプがある。割り付けの隠蔽は無作為化を確保するため、選択バイアスを減少させる。割り振り隠しと盲検化の違いは、割り振り隠しは募集中に、盲検化は募集後に行うことである10。
正しいデータ/適切なツール/方法でデータを分析しているか?
“我々は、データを分析するために使用する抽象化とデータを混同しないように注意しなければならない。”
ウィリアム・ジェームズ
研究方法論では、研究の種類、データの収集と分析、使用したツール・方法、それらのツールを使用した合理性などを記載する必要がある。データを収集した後、次のステップは、どの統計的検定を使用するかを決定することである。適切な検定の選択は、いくつかのパラメータに依存する。(1) 研究の目的/目的(データを比較するのか、データ間の相関関係を確立するのか)(2) 標本の数(1つ、2つ、または複数)(3) データの種類(カテゴリカルなものと数値的なもの)(4) 変数の種類と数?(一変量、二変量、多変量)、(5)群間の関係(対になっている/依存している vs 対になっていない/依存していない)。これらの違いに基づいて、可能な組み合わせが生じる。表は、データを分析するために使用された異なる組み合わせと方法論的検定を示している(表2)。
表2 因子/質問はデータを分析するための統計ツールの選択に役立つ11,12
| 1.研究の目的/目的: | ||||
| A.データを比較する | ||||
| 2.サンプル数 | 3.ペアリング/ペアリング解除 | 4.データの種類と分布 | ||
| パラメトリックデータ(平均の比較など) | ノンパラメトリックデータ(中央値の比較など) | |||
| 1サンプル | – | 1サンプルのt検定(<30:N) | 1つのサンプルウィルコクソン符号順位検定 | |
| 1サンプルのz検定(≥30:N) | ||||
| 2サンプル | ペアリングを解除する | 不対のt検定 | ウィルコクソン順位和検定または | |
| マンホイットニーU検定 | ||||
| ペア | ペアT検定 | 関連サンプルウィルコクソン符号順位検定 | ||
| ≥3サンプル | ペアリングを解除する | 一元配置分散分析 | クラスカル・ウォリスH検定 | |
| ペア | 反復測定ANOVA | フリードマン検定 | ||
| B.比率を比較する | ||||
| 独立した/対になっていない | – | ピアソンのカイ二乗検定 | ||
| フィッシャーの直接確率検定 | ||||
| 依存/ペア | – | マクネマー検定(2グループ) | ||
| コクランQテスト(3グループ以上) | ||||
| C.結果変数の予測因子/変数間の相関 | ||||
| (回帰分析の種類) | ||||
| 従属変数の数 | 従属変数のタイプ | 独立変数の数 | 独立変数のタイプ | テスト |
| 1 | 継続的 | 1 | 継続的 | 単純な線形回帰 |
| カテゴリカル | 一元配置分散分析 | |||
| ≥2 | あらゆるタイプのデータ | 重回帰 | ||
| カテゴリカル | 1 | 継続的 | ロジスティック回帰 | |
| カテゴリカル | ピアソンのカイ2乗または尤度比 | |||
| ≥2 | あらゆるタイプのデータ | 多重ロジスティック回帰 | ||
| レア | いずれかの番号 | いかなるタイプ | ポアソンモデル | |
| D.変数間の関連度 | ||||
| パラメトリック法 | ノンパラメトリック | |||
| ピアソン相関 | スピアマンの順位相関 | |||
| 係数 | 係数 | |||
| D.生存データの分析/イベント分析までの時間 | ||||
| 1つのサンプル母集団 | カプランマイヤー検定 | |||
| 2つのサンプリング母集団 | 1つの機能/カテゴリ変数 | ログランクテスト | ||
| 2つのサンプリング母集団 | 2つの特徴/量的変数 | コックス比例ハザードモデル、回帰分析 | ||
RCTにおいては、サブグループ解析やポストホック解析を目にすることが多いが、これらの解析の限界を理解することは、読者にとって非常に重要である。サブグループ解析は通常、二次的な目的として考えられているが、個別化医療や標的治療の時代には、新薬や治療法の治療効果が研究集団間で同じではないことが十分に認識されている。サブグループ分析は、(1)特定のサブグループの安全性プロファイルを評価したい場合、(2)異なるサブグループの効果の一貫性を知りたい場合、(3)重要でない試験でサブグループの効果を検出したい場合に有用である14。サブグループ分析については、(1)複数回の試験を行うため偽陽性所見が多くなる可能性があること、(2)検出力が不十分な場合(サンプルサイズが小さいため)偽陰性になる可能性があること、の 2 つの点で批判されている。サブグループ分析に基づいて結論を出し、それを実践することは極めて困難である。しかし、サブグループ効果の事前確率が20%以上(少なくとも20%以上、できれば50%以上)であること、サブグループの数が少ない(2以下)こと、サブグループのベースライン特性が同じであること、サブグループの仮説検証が事前に決定されている場合に、臨床家がサブグループ分析の妥当性を検討するシナリオはほとんどない。15 ポストホック分析とは、「事前に特定されていない所見や回答についてデータを検討する行為で、研究終了後に分析する」と定義されているサブグループ分析の一種である。可能であれば、事前に指定されたサブグループ分析は、ポストホック分析と比較して信頼性が高いため、行うべきである13。
正しい解釈(データに意味を与えること
“聞くものはすべて意見であり 事実ではない “我々が見るものはすべて遠近法であり、真実ではない。”
[マルクス・アウレリウス]
このRCT結果は偶然の差/統計的に有意か?
p値は有意か?データ収集と分析の目的は、2つのグループ間に差があるかどうかを示すことである。この差は偶然によるものか、真の差によるものかのどちらかになる。偶然による差を除外するために、統計学では多くのツールが使用されている:p値はそのうちの1つである。フィッシャーのシステムでは,p値は帰無仮説に対する証拠の強さのための大まかな数値ガイドとして使用され,その値は0.05に任意に選択された。簡単に言えば、p値<0.05は実験を繰り返すべきであることを示唆しており、言葉の有意性は単に「注目に値する」ことを示しているに過ぎない。したがって、p値が有意になったら、話はそれで終わりではなく、もっともっと精力的に研究するべきなのである16。
p 値に関する誤解
16 p 値に関する最も一般的な誤解は以下の通りである。
- (1) p-値が大きいと違いがないことを意味し、
- (2) p-値が小さい方が常に有意であることを意味しているのか?
- (a) “証拠がないことは証拠がないことの証拠ではない” p値があらかじめ指定されたしきい値のアルファ誤差(大抵は0.05)を超えていれば、通常はH0が棄却されないと結論づけられる。しかし、それはH0が真であることを意味しない。より良い解釈は、H0を棄却するのに十分な証拠がないということである。同様に、「H0ではない」は、H0に何か問題があることを意味し、必ずしもHaが正しいとは限らない。
- (b) p 値は、
- (i)効果の大きさ(効果と効果の大きさを測定するための適切な指標)
- (ii)標本の大きさ(標本の大きさが大きいほど検出される可能性が高い)
- (iii)データの分布(標準偏差が大きいほど p 値が低い)などの要因に影響される18 。
複数検定は行われているか?
p値のもう一つの問題は、複数回の検定であり、そのうちのいくつか/最後の検定で<0.05のp値を示しているものはほとんどない。
“データを十分に拷問すれば、自然は常に告白するだろう” ロナルド・コアス] 1回の試行で1回の成功と複数回の試行で1回の成功は、統計学と確率の観点から異なる意味を持っている。説明されている複数回のテストの根本的なメカニズムは、「ファイルの引き出し問題」である。多重試行は、真理よりも「意図」と観察された発見の複製可能性の将来の可能性に関するものである。
誤発見率は除外されているか/多重検定のp値の解決策
良いと思われる悪いデータを選別するために使用されるツール。これは、5回の(独立した)試験でα=0.05/5=0.01を新しい閾値として使用し、5を掛けて観測されたp値を調整するというものである。 この調整の問題点は、偽陽性を検出する確率を下げるだけでなく、真の発見を減らすということである。誤発見率(FDR)は,有意な結果が得られたテストのみで誤発見の数を制御するもう1つの方法である.最適化されたFDRアプローチを用いて調整されたp値はq値として知られている。この現象を克服するための方法は他にもあり、中間分析のためのO’Brien-Flemingや経験的ベイズ法などがある17,18
p値の代替アプローチはあるのか/ベイズ法
p値の限界は、事前確率と代替仮説を考慮しないことである。ある研究から得られた証拠と先行研究から得られた証拠を組み合わせて結論を出す必要がある。この目的は,ベイズの定理・方法によって解決される.ベイズの因子は、帰無仮説と代替仮説の尤度比である。簡単に言えば、帰無仮説に対する真の証拠を見るために、最も強いベイズ因子とp値を比較する必要がある16 (表3)。
表3 ベイズ因子とp値の性質と違い16,19
| プロパティ | p値 | ベイズ因子 |
|---|---|---|
| 効果の大きさ | 番号 | はい |
| 対立仮説を検討する | 番号 | はい |
| データ | 観察された+仮説 | 観測データのみ |
| 計算 | 簡単 | 繁雑 |
| 区間推定 | 信頼区間 | 信頼区間 |
| 研究者の意図(停止または測定基準によって影響を受ける結果) | 影響を受ける値 | 影響を受けません |
p値は信頼区間で裏付けられているか?
信頼区間(CI)は、ある程度の不確実性を持った真の母集団値を含む可能性の高いサンプル観測から計算された値の範囲を記述している。信頼区間は、有意性についてのより多くの情報を与えることで、p値の問題点を克服するのに役立つ。これは,仮説検定よりもむしろ効果の大きさについてのアイデアを与える.CIの幅は,推定値の精度/信頼性についてのアイデアを与える.CIは単なる統計的なものではなく、効果の方向性と強さ、ひいては臨床的な関連性についての洞察を与えてくれる。サンプルサイズが大きければ(信頼性が高くなる)CIは狭くなる。分散が広ければ、結論の確実性は低くなり、信頼区間は広くなる。信頼区間は、ユーザが選択した信頼度にも影響され、標本の特性には依存しない。20,21 信頼区間のもう一つの有用性は、同等性/劣る/劣らないタイプの研究で、信頼区間はp値ではなくグループ間比較のツールとして使用される。
データはロバストか?
Fragility index(FI)は臨床試験の結果のロバスト性を測定する。簡単に言えば、FIが高ければ、試験の統計的再現性が高いということである。FIは、試験が統計的有意性を失うために、非イベント(主要エンドポイントを経験していない)からイベント(主要エンドポイントを経験している)に状態が変化しなければならない患者の最小数である。例えば、FIスコアが1であれば、試験結果を有意でないものにするためには、一次エンドポイントを経験しない患者が1人だけ必要であることを意味する。言い換えれば、臨床試験結果の統計的有意性がどれだけの事象に依存しているかを示す指標である。FIスコアが小さければ、臨床試験結果はより脆弱で統計的に頑健ではないことを示する。他の統計ツールと同様に、FIにも限界がある。(1) RCT にのみ適している、(2) 二項アウトカムに適している、(3) イベントまでの時間的バイナリーアウトカムには適していない、(4) RCT アウトカムをロバストと定義する特定の FI 値がなく、許容できると考えられる FI スコアのカットオフ値がない、(5) 研究における二次アウトカム指標を評価するための FI スコアの使用には制限がある、(6) 不明な理由で脱落する被験者が多い場合には信頼性がない、解釈が難しい、(7) FI は p 値と強く関連している、など制限がないわけではない。上記の欠点を考慮すると、効果の強さを測定するための単独のツールとしてFIを使用すべきではない。スコアが低い試験はより脆弱であり(これは通常、イベントの数が少ない、サンプルサイズが小さい、結果として研究力が低いことと関連している)FIスコアが高い試験は脆弱性が低く(これは通常、イベントの数が多い、サンプルサイズが大きい、結果として研究力が高いことと関連している)22-24。
これは統計的に有意な差/臨床的に有意なのか?
もう一つよくある誤解は、「統計的に有意であることは臨床的に有意であることと同等である」というものである。統計的に有意とは、データに真の差があることを意味するが、その差が臨床的に有意であるかどうかは、効果の大きさ(重要な差の最小値)有害性(リスクと便益)費用対効果/実現可能性、利害の対立/資金調達などの多くの要因に左右される25。
“25 「研究調査の主な成果は、効果の大きさの1つ以上の尺度であって、p値ではない。
ジェイコブ・コーエン
p-値は、効果が存在するかどうかについてのアイデアを与えるが、効果の大きさについてのアイデアは与えない。研究では,効果の大きさとp-値の両方に言及することが特に重要である.両方のパラメータは互いに代替的なものではなく、むしろ補完的なものである。有意性検定とは異なり、効果の大きさは標本サイズに依存しない26 。効果の大きさの指標は、研究対象の比較の種類によって計算できる(表 4)。
表4 共通の効果量指標26-28
| インデックス | 説明 | 効果の大きさ | コメント |
|---|---|---|---|
| グループ間 | |||
| コーエンのd | メタアナリシスで広く使用されています | 小/自明0.2 中0.5 大0.8 非常に大1.3 |
必要な効果量/研究の検出力に基づいてサンプルサイズを決定するのに役立ちます。 連続データの場合。 |
| 両方のグループの平均値と標準偏差を使用します。 | |||
| オッズ比(OR) | 2オッズの比率 | 小1.5 | バイナリ結果の場合。 |
| ケースコントロール研究の場合、効果量はORで示されます | ミディアム2 ラージ3 |
RR / ORが1の場合、リスクは両方のグループで同等であることを意味します。 | |
| 相対リスク(RR) | 2つの確率の比率 | 小2 中3 大4 |
|
| 治療に必要な数(NNT) | これは、絶対リスク削減(ARR)の逆数です。 | NNTは、バイナリ結果に使用できます。 | |
| 介入/薬物Bと比較して1つ多くの成功を収めるために介入/薬物Aで治療することを期待する被験者の数です。 | ベースライン死亡率の大きさを考慮していません | ||
| それは、その比較アームで、文脈に応じて解釈されるべきです。 | |||
| 介入によって行われた利益または害に基づいて、NNTは再びNNT-BまたはNNT-Hとしてラベル付けされます | |||
| 連想の尺度 | |||
| ピアソンのr相関 | 2つの変数XとYの間の線形相関を測定します | 小±0.2 中±0.5 大±0.8 |
2つの変数間の関連の強さに使用されます分析 値の範囲–1(完全に負の相関)から1(完全に正の相関) |
効果量の解釈は、両群(「対照群」と「実験群」)の値が正規分布し、同じ標準偏差を持つという仮定に依存する。相対リスクとオッズ比は、絶対リスクと信頼区間の文脈で解釈されるべきである。信頼区間付きの効果量の使用は、統計的有意性の検定と同じ情報を提供するが、標本サイズよりも効果の有意性に重きを置く。
最小限の重要な差。臨床的有意性において最も重要で困難な点は、どのような差が臨床的に重要であるかを決定することである。最小重要差の決定には、アンカーベース、分布ベース、エキスパートパネルアプローチの3つの方法がある25。
無作為化対照試験の結果は適用可能か?
新しい介入や治療法が発売された場合、その受容性や成功は臨床的な有効性だけでなく、それに伴う費用にも依存する。無作為化試験では、臓器不全、呼吸器や腎のサポート、死亡率、罹患率などの臨床的エンドポイントに焦点が当てられているが、現代の臨床試験では経済的転帰も含まれている。このような場合には、臨床結果が良好でコストが低い治療法が優勢であると考えられており、その場合には深い解析は必要ない。しかし、臨床成績が良くてもコストが高い新規治療法がある場合には、問題が発生する。このような場合、最も重要なことは、高いコストに見合うだけの治療成績の改善があるかどうかということである。したがって、費用対効果は、費用と有効性・結果のバランスをとり、利用可能な代替療法を比較するのに役立つ。
利害の衝突は金銭的なものか非金銭的なものか?
利害の衝突(COI)は、個人/組織のトピック/活動に矛盾する利害が出てきた場合に起こる。利益相反が存在する場合、研究者の行動とは無関係に、RCT の妥当性に疑問が生じる。利益相反は、治験責任医師、倫理委員会(EC)規制当局のレベルなど、異なるレベル・階層で発生する可能性がある。利益相反は、製薬会社などのスポンサー、受託研究機関、あるいは複数のレベルで発生する可能性がある。現在ではほとんどの試験が盲検化されているため、治験責任医師がデータを操作することは非常に困難である。しかし、データ管理チームによるデータ解析のレベルでは、意図せずに、あるいは故意にデータを改ざんすることは可能である。ほとんどの研究者はデータ解析者によって結果が改ざんされたことを知らないので、このレベルで確認することが重要である。簡単に言うと、利益相反は非金銭的なタイプと金銭的なタイプに分けることができる。その他の分類としては、ネガティブな利益相反とポジティブな利益相反がある。より一般的なのは、ポジティブな利益相反を気にすることであるが、ネガティブな利益相反も観察する価値がある。負の利益相反は、治験責任医師やスポンサーが、自分のライバルや利益のためだけに、潜在的に有用な治療や介入を故意に拒否したり、不正を行ったりした場合に起こる30。
また、利益相反は常に悪いことではないことを知っておくことも非常に重要であり、時には個人やスポンサーのせいではなく、問題の性質や核心的な問題のせいで起こることもある30,31。
無作為化対照試験にバイアスはあるか?
バイアスとは、個々の研究の結果やその合成結果における系統的な誤差と定義されている。Cochrane Risk of Bias Tool for randomized trialsでは、バイアスは6つの異なるレベル/領域で発生すると述べられている:割付順序の生成、割付順序の隠蔽、参加者の盲検化(単一盲検化)と医師の盲検化(二重盲検化)データ解析者の盲検化(三重盲検化)アトリションバイアス、出版バイアスである。金銭的な利益相反はこの中には含まれていないが、その背景には動機があることに注意が必要である31。
無作為化対照試験の査読はあるのか、ないのか?
論文の出版と信頼性に関するもう一つの重要なことは、査読が行われているかどうかである。査読とは、論文を出版する前に資格を持った人が論文を評価することである。査読は、論文に提案を加えることで論文の質を向上させることができるが、第二に、論文の質が低いものは却下される。評判の良い雑誌のほとんどは、査読について独自の方針を立てている。査読はバイアスのないものではない。時には、このプロセスの質は、選択された資格のある教員とその論文の好みに依存する。査読と同様に、出版後のレビューも特に重要であり、何百人もの専門家によって批判・分析されるため、無視してはならない32,33。
結論
一言で言えば、RCTの批判的分析とは、正しい質問、正しい母集団、正しい研究デザイン、正しいデータ、正しい解釈などの主要な領域を分析した上で、試験の長所と短所のバランスをとることである。また、これらの境界線は非常に単純化されており、多くの経路で相互につながっていることにも注意が必要だ。