Contents
Why Most Published Research Findings Are False
www.ncbi.nlm.nih.gov/pmc/articles/PMC1182327/
John P. A. IoannidisPLOS x
発行日 2005年8月30日

帰結
ほとんどの研究デザイン、ほとんどの分野において、ほとんどの研究結果は偽である。
主張されている研究結果は、多くの場合、一般的なバイアスを単に正確に測定したものである可能性がある
この状況を改善するには?
概要
現在発表されている研究結果のほとんどが虚偽であるという懸念が高まっている。ある研究主張が真実である確率は、研究の力や偏り、同じ問題に関する他の研究の数、そして重要なことに、各科学分野で調査された関係性のうち、真実の関係性と無関係の関係性の比率に依存していると考えられる。この枠組みでは、ある分野で実施された研究の規模が小さい場合、効果量が小さい場合、検証された関係の数が多く予備選択が少ない場合、デザイン、定義、結果、分析方法の柔軟性が高い場合、金銭的その他の利益や偏見が大きい場合、統計的有意性を追いかける科学分野に多くのチームが関与している場合に、研究結果が真実である可能性が低くなる。シミュレーションによると、ほとんどの研究デザインや設定において、研究主張が真であるよりも偽である可能性の方が高いことがわかっている。さらに、現在の多くの科学分野では、主張された研究結果は、一般的なバイアスを正確に測定したものに過ぎないことが多い。本論では、これらの問題が研究の実施と解釈に与える影響について述べている。
発表された研究結果は、後続のエビデンスによって反論されることがあり、その結果、混乱や失望を招くことがある。反論や論争は、臨床試験や伝統的な疫学研究[1-3]から最新の分子研究[4,5]まで、さまざまな研究デザインで見られる。現代の研究では、発表された研究主張の大半、あるいは大部分が偽の発見ではないかという懸念が高まっている[6-8]。しかし、これは驚くべきことではない。主張されている研究結果のほとんどが虚偽であることは証明できる。ここでは、この問題に影響を与える重要な要因とその傍証を検討する。
偽陽性発見の枠組みのモデル化
何人かの方法論学者は、研究発見の非再現性(確認の欠如)の割合が高いのは、形式的な統計的有意性(典型的にはp値が0.05未満)によって評価された1つの研究のみに基づいて決定的な研究結果を主張するという、便利だが根拠のない戦略の結果であると指摘している。[9-11]。研究はp値で表されたり要約されたりするのが最も適切ではないが、残念ながら医学研究論文はp値だけで解釈されるべきだという考え方が広まっている。ここでいう研究成果とは、正式な統計的有意性に達した関係性、例えば、効果的な介入、有益な予測因子、危険因子、関連性などと定義される。「ネガティブ」な研究も非常に有用である。「ネガティブ」という言葉は実際には誤用であり、その誤解は広まっている。しかし、ここでは無効な知見ではなく、研究者が存在すると主張する関係を対象とする。
主張されている研究結果のほとんどが虚偽であることが証明されている
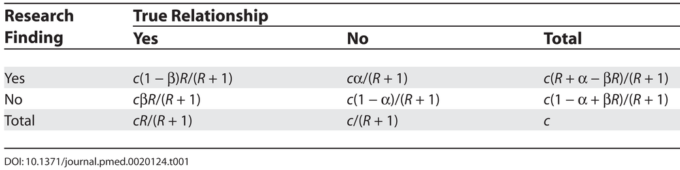
これまでに示されているように、ある研究結果が実際に真実である確率は、(研究を行う前の)事前の真実の確率、研究の統計的検出力、および統計的有意性のレベルに依存する。[10,11]。2×2の表を考えてみよう。この表では、ある科学分野における真の関係というゴールドスタンダードに対して研究結果を比較する。研究分野では、関係性の存在について、真の仮説も偽の仮説も立てることができる。ここで、その分野で検証された「真の関係」の数と「関係なし」の数の比率をRとする。Rはその分野の特徴であり、その分野が可能性の高い関係を対象としているか、あるいは何千、何百万もの仮説の中から1つまたは数個の真の関係だけを探しているかによって、大きく変わる。また、計算を簡単にするために、真の関係が(多くの仮説の中で)1つしかないか、既存のいくつかの真の関係のいずれかを見つけるのに近い力を持つ、外接的な分野を考えてみよう。ある関係が真であるという研究前の確率はR/(R + 1)である。真の関係を発見する研究の確率は、検出力1-β(Type IIエラー率の1マイナス)を反映している。実際には関係がないのに関係を主張する確率は、第一種エラー率αを反映している。c個の関係が現場で調査されていると仮定すると、2×2表の期待値は表1のようになる。形式的な統計的有意性を達成して研究結果を主張した後、それが真実であるという研究後の確率がPPV(positive predictive value)である。PPVは、Wacholderらが偽陽性報告確率と呼んでいるものの補完的な確率でもある[10]。2×2の表によると、PPV = (1 – β)R/(R – βR + α)となる。通常、大多数の研究者はa = 0.05に依存しているので、(1 – β)R > 0.05であれば、研究結果は偽よりも真である可能性が高いということになる。
表1 調査結果と真の関係性
あまり知られていないことであるが、偏りや、世界中の異なる調査チームによる独立したテストの繰り返しによって、この図式はさらに歪められ、研究結果が本当に真実である確率はさらに低くなる可能性がある。ここでは、これらの2つの要因を、同じような2×2の表を使ってモデル化してみる。
バイアス
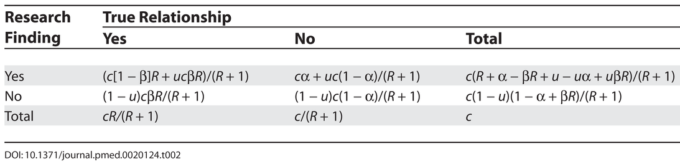
まず、バイアスとは、設計、データ、分析、発表などの様々な要因が組み合わさって、本来出るはずのない研究結果が出てしまうことと定義しておく。本来ならば「研究成果」ではないにもかかわらず、バイアスのために「研究成果」として発表・報告されてしまうプローブ分析の割合をuとする。バイアスは、研究デザイン、データ、分析、発表が完璧であるにもかかわらず、偶然に誤った発見をしてしまう偶然の変動性と混同してはならない。バイアスには、研究結果の分析や報告における操作が含まれる。選択的で歪んだ報告は、このようなバイアスの典型的な形態である。uは、真の関係が存在するかどうかに依存しないと考えることができる。どの関係が本当に正しいのかを知ることは通常不可能なので、これは不合理な仮定ではない。バイアスがある場合(表2)PPV = ([1 – β]R + uβR)/(R + α – βR + u – uα + uβR)となり、PPVは1 – β ≤ α、すなわちほとんどの状況で1 – β ≤ 0.05とならない限り、uの増加とともに減少する。このように、バイアスの増加に伴い、研究結果が真実である可能性はかなり減少する。このことは、パワーのレベルと研究前のオッズを変えて図1に示している。逆に、逆バイアスのために、真の研究結果が否定されることもある。例えば、測定誤差が大きいと関係性がノイズに埋もれてしまったり、[12]、研究者がデータを非効率的に使用したり、統計的に有意な関係性に気づかなかったり、有意な知見を「埋没」させる傾向のある利益相反があったりする。[13]。多様な研究分野において、このような逆バイアスがどのくらいの頻度で発生しているかについては、大規模な実証的証拠はない。しかし、おそらく逆バイアスはそれほど一般的ではないと言ってよいであろう。また、分子時代の技術的進歩により測定誤差が減少し、研究者がデータに対して高度な知識を持つようになったため、測定誤差やデータの非効率的な使用は、おそらくそれほど頻繁に起こる問題ではなくなってきている。いずれにしても、逆バイアスは、上記のバイアスと同じようにモデル化することができる。また、逆バイアスは、偶然によって真の関係を見逃してしまう可能性のある偶然変動と混同してはならない。
図1 PPV(ある研究結果が真実である確率)は、様々なレベルのバイアス(u)に対する研究前のオッズの関数として示されている
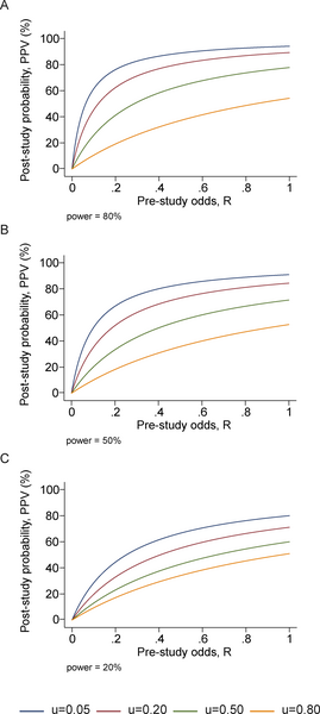
パネルは0.20,0.50,0.80の検出力に対応している。
表2 バイアスがかかっている場合の研究結果と真の関係性
複数の独立したチームによるテスト
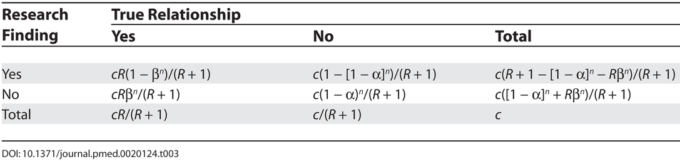
複数の独立したチームが同じ研究課題に取り組んでいる場合がある。研究活動のグローバル化に伴い、複数の研究チーム(多くの場合、数十チーム)が同一または類似の問題を調査することが事実上、規則化されている。しかし、残念なことに、これまでは1つのチームによる単独の発見に注目し、研究実験を単独で解釈するという考え方が主流であった分野もある。研究成果を主張する研究が少なくとも1つあり、それが一方的に注目されている質問が増えている。同じ質問に対して行われた複数の研究のうち、少なくとも1つの研究が統計的に有意な研究結果を主張する確率は、簡単に見積もることができる。独立した研究が、n 件で検出力が等しい場合、表 3に示す。2 × 2の表となり、PPV = R(1 – βn)/(R + 1 – [1 – α]n – Rβn)となる(バイアスは考慮しない)。独立した研究の数が増えると、1 – β < a、すなわち典型的には 1 – β < 0.05 でない限り、 PPV は減少する傾向にある。これは図2に異なるレベルの検出力と異なる研究前オッズについて示されている。異なる検出力のn個の研究では、βnの項はi = 1からnまでのβiの項の積に置き換えられるが、帰結は同様である。
図2 PPV(ある研究結果が真実である確率)の研究前オッズの関数として、様々な数の研究が実施された場合、n
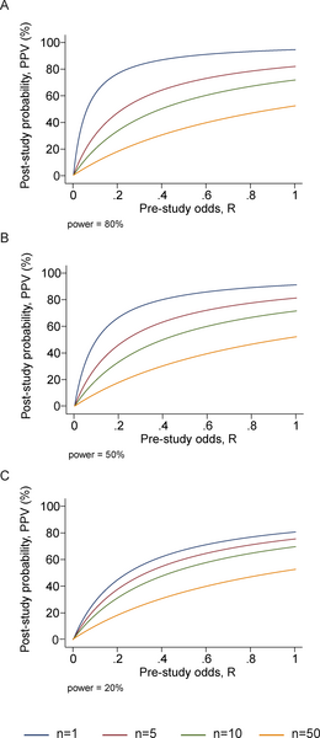
パネルは0.20,0.50,0.80の検出力に対応している。
表3 複数の研究が存在する場合の研究結果と真の関連性
帰結
実際の例をBox1に示する。上記の考察に基づいて、ある研究結果が実際に真である確率について、いくつかの興味深い傍証を導くことができる。
Box 1. 一例 研究前の低い確率での科学
ある研究チームが、10万個の遺伝子多型のどれかが統合失調症の感受性と関連しているかどうかを調べるために、全ゲノム関連研究を行ったとしよう。この病気の遺伝性の程度についてわかっていることに基づけば、テストされた遺伝子多型のうち、おそらく10個前後の遺伝子多型が本当に精神分裂病と関連していると予想するのが妥当であり、10個前後の多型については比較的似たようなオッズ比が得られ、それらのいずれかを同定する力もかなり似たようなものである。そうすると、R = 10/100,000 = 10-4となり、ある多型が統合失調症と関連する研究前の確率もR/(R + 1) = 10-4となる。また、α=0.05でオッズ比1.3の関連性を見出す検出力が60%であったとしよう。そうすると、p値が0.05のしきい値をかろうじて超えて統計的に有意な関連性が認められた場合、それが真実であるという研究後の確率は、研究前の確率に比べて約12倍になるが、それでも12×10-4にすぎない。
ここで、研究者がデザイン、分析、報告を操作して、より多くの関係がp = 0.05のしきい値を超えるようにしたとしよう。ただし、当初の研究計画に厳密に従ったデザインと分析、そして結果の完璧な包括的報告があれば、しきい値を超えることはなかったであろう。このような操作は、例えば、特定の患者または対照の偶然の包含または除外、事後的なサブグループ分析、当初は指定されていなかった遺伝的対照の調査、疾患または対照の定義の変更、および結果の選択的または歪んだ報告の様々な組み合わせによって行うことができる。市販されている「データマイニング」パッケージは、データの浚渫(しゅんせつ)によって統計的に有意な結果が得られることを誇りにしている。u=0.10のバイアスがある場合、ある研究結果が真実であるという研究後の確率は、わずか4.4×10-4である。さらに、偏りがない場合でも、独立した10の研究チームが世界中で同様の実験を行った場合、そのうちの1つが形式的に統計的に有意な関連性を見つけたとしても、その研究結果が真実である確率は1.5×10-4に過ぎず、このような大規模な研究が行われる前の確率よりもほとんど高くはない。
補論1:科学分野で実施された研究が小規模であればあるほど、研究結果が真である可能性は低くなる。
標本サイズが小さいということは検出力が小さいということであり、上記のすべての関数において、検出力が1 – β = 0.05に向かうにつれて、真の研究発見に対するPPVは減少する。したがって、他の要因が同じであれば、分子予測因子のほとんどの研究(サンプルサイズが100倍小さい)のような小規模な研究を行う科学分野よりも、循環器学のランダム化比較試験(数千人の被験者がランダム化される)[14]のような大規模な研究を行う科学分野の方が、研究結果が真である可能性が高い[15]。
補論2:科学分野では、効果量が小さければ小さいほど、研究結果が真実である可能性は低くなる。検出力も効果量に関係している。
そのため、喫煙ががんや心血管疾患に与える影響(相対リスク3~20)のように影響が大きい科学分野では、研究結果が真実である可能性が高く、多因子疾患の遺伝的危険因子(相対リスク1.1~1.5)のように影響が小さい科学分野では、研究結果が真実である可能性が低くなる[7]。現代の疫学は、より小さな効果量を目標とする必要性が高まっている[16]。その結果、真の研究結果の割合は減少すると予想される。同じ考え方で、ある科学分野で真の効果量が非常に小さい場合、その分野はほとんどどこにでもある偽陽性主張に悩まされる可能性が高い。例えば、複雑な疾患の真の遺伝的または栄養学的決定因子の大多数が相対リスク1.05未満である場合、遺伝疫学や栄養疫学はほとんどユートピア的な試みとなるであろう。
補論3:科学分野において、検証された関係の数が多ければ多いほど、また選択範囲が狭ければ狭いほど、研究結果が真である可能性は低くなる。
上に示したように、ある所見が真である研究後の確率(PPV)は、研究前の確率(R)に大きく依存する。したがって、仮説生成型の実験よりも、大規模な第III相ランダム化比較試験やそのメタアナリシスなどの確証的デザインにおいて、研究結果が真である可能性が高くなる。マイクロアレイやその他のハイスループットディスカバリー指向の研究[4,8,17]のように、収集され検証された情報が豊富であることから、非常に有益で創造的であると考えられる分野は、PPVが極めて低いはずだ。
補論4:科学分野のデザイン、定義、結果、分析方法の柔軟性が高ければ高いほど、研究結果が真実である可能性は低くなる。
ランダム化比較試験[18-20]やメタアナリシス[21,22]など、いくつかの研究デザインについては、その実施と報告を標準化する努力がなされてきた。共通の基準を守ることで、真の知見の割合が増える可能性が高い。同じことが結果にも当てはまる。多様な転帰が考案されている場合(例:統合失調症の転帰のための尺度)よりも、転帰が明確で普遍的に合意されている場合(例:死亡)の方が、真の所見がより一般的になる可能性がある[23]。同様に、一般的に合意され、定型化された分析手法(例:カプランマイヤープロットやログランク検定)[24]を用いる分野では、分析手法がまだ実験中であり(例:人工知能手法)、「最良の」結果のみが報告される分野よりも、真の知見の割合が多くなる可能性がある。とはいえ、最も厳格な研究計画であっても、バイアスは大きな問題であるようだ。例えば、報告された結果や分析を操作する選択的結果報告は、ランダム化試験でさえもよくある問題であるという強力な証拠がある[25]。単に選択的報告を廃止しても、この問題がなくなるわけではない。
補論5:科学分野での金銭的利害や偏見が大きければ大きいほど、研究結果が真実である可能性は低くなる。
利益相反や偏見はバイアスを増加させる可能性がある。利益相反は生物医学研究において非常に一般的であり[26]、一般的に報告が不十分で少ない[26,27]。偏見は必ずしも金銭的なルーツを持つとは限らない。ある分野の科学者が、純粋に科学理論への信念や自らの研究成果へのこだわりから偏見を持つこともある。一見独立しているように見える大学での研究の多くは、医師や研究者に昇進や終身在職の資格を与えるため以外の理由で行われている場合がある。このような非金銭的な対立は、報告された結果や解釈を歪めることにもつながる。権威ある研究者たちは、査読プロセスを通じて、自分たちの研究結果を否定するような研究結果の出現や普及を抑制し、その結果、自分たちの分野が誤ったドグマを永続させることを非難するかもしれない。専門家の意見に関する経験的証拠は、それが極めて信頼性に欠けることを示している[28]。
補論6:科学分野がホットであればあるほど(関与する科学チームが多ければ多いほど)、研究結果が真実である可能性は低くなる。
この一見逆説的な帰結は、上述のように、同じ分野に多くの研究者チームが関わると、孤立した研究結果のPPVが低下するからだ。このことは、広く注目されている分野で、大きな興奮の後に激しい失望に見舞われることがある理由を説明しているのかもしれない。多くのチームが同じ分野に取り組み、膨大な実験データが生み出されている以上、競争に打ち勝つにはタイミングが重要である。したがって、各チームは最も印象的な「ポジティブ」な結果を追求し、広めることを優先するかもしれない。「否定的」な結果は、他のチームが同じ問題に関して「肯定的」な関連性を発見した場合にのみ、普及させる魅力的なものになるかもしれない。その場合、権威あるジャーナルに掲載された主張に反論することが魅力的になるかもしれない。Proteus現象という用語は、極端な研究主張と極端に正反対の反論が急速に交互に現れるこの現象を表す造語である[29]。経験的な証拠によると、このような極端に正反対の一連の現象は、分子遺伝学では非常によく見られることである[29]。
これらの補説は、各要因を個別に検討しているが、これらの要因は互いに影響し合うことが多い。例えば、真の効果量が小さいと思われている分野の研究者は、真の効果量が大きいと思われている分野の研究者よりも、大規模な研究を行う可能性が高いかもしれない。あるいは、注目されている科学分野で偏見が蔓延し、研究結果の予測価値がさらに損なわれるかもしれない。偏見の強い利害関係者は、対立する結果を得て広める努力を頓挫させる障壁を作ることさえある。逆に、ある分野が注目されていたり、強い利害関係があったりすることで、より大規模な研究や研究水準の向上が促進され、研究結果の予測価値が高まることもある。あるいは、発見を重視した大規模な試験の結果、有意な関係が大量に得られ、研究者がそれを報告し、さらに調査するのに十分な量となり、データの浚渫や操作を控えるようになるかもしれない。
ほとんどの研究結果は、ほとんどの研究デザインとほとんどの分野で偽りである
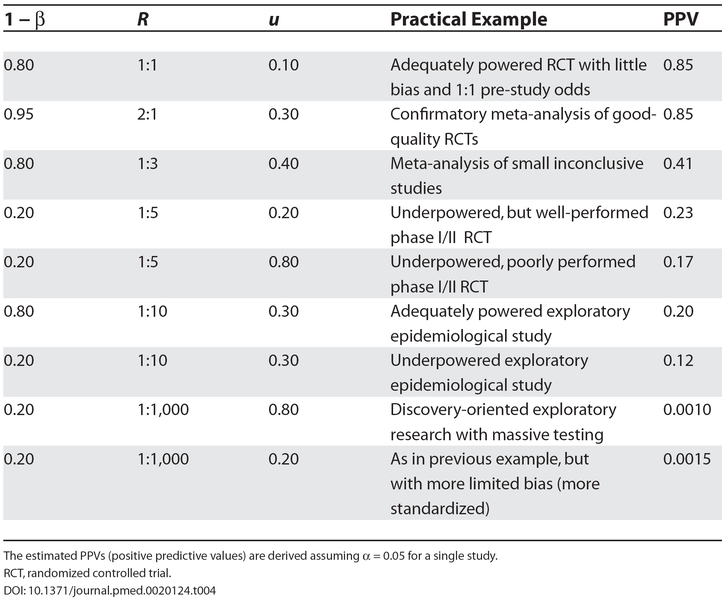
上記の枠組みでは、50%を超えるPPVを得ることは非常に困難である。表4は、特定の研究デザインや設定に特徴的な様々なタイプの状況について、検出力、真偽関係の比率、バイアスの影響について開発した式を用いてシミュレーションした結果を示している。介入が有効であるという試験前の確率が50%で開始された、十分に実施された動力付き無作為化対照試験から得られた知見は、最終的に約85%の確率で真となる。質の良い無作為化試験の確証的メタアナリシスでも、かなり似たようなパフォーマンスが期待される。潜在的なバイアスはおそらく増加するが、単一の無作為化試験と比較して、検出力と試験前のチャンスは高くなる。逆に、単一の研究の低い検出力を「補正」するためにプーリングを用いた、結論の出ていない研究からのメタ分析結果は、R≦1:3の場合,おそらく誤りである。パワー不足の初期段階の臨床試験から得られた研究結果は、約4回に1回、あるいはバイアスが存在する場合はさらに少ない頻度で真となるであろう。探索的な性質を持つ疫学研究は、特に力不足の場合にはさらに悪い結果となるが、力のある疫学研究であっても、R = 1:10であれば、5回に1回の確率でしか真とならないかもしれない。最後に、大規模な試験を行う発見志向の研究では、試験された関係が真の関係の1,000倍を超える場合(例えば、30,000個の遺伝子が試験され、そのうち30個が真の原因かもしれない)[30,31]、バイアスを最小化するために実験室および統計的手法、結果、およびその報告をかなり標準化したとしても、主張された各関係に対するPPVは極めて低い。
表4 パワー(1 – ß)、真偽関係の比率(R)、バイアス(u) 様々な組み合わせに対する研究結果のPPV
主張された研究結果は、多くの場合、一般的なバイアスを単に正確に測定したものである可能性がある
このように、現代の生物医学研究の大部分は、研究の前後で真の知見が得られる確率が非常に低い分野で行われている。仮に、ある研究分野では、真の発見が全くないとしよう。科学の歴史を振り返ると、過去には、少なくとも現在の理解では真の科学的情報が全く得られない分野で、科学的努力を無駄にしたことがよくある。このような「null field」では、バイアスがかかっていない状態では、観測されたすべての効果の大きさがnullの周辺で偶然に変化することが理想的である。観察された結果が偶然に期待されるものからどの程度逸脱しているかは、偏りがあるかどうかを純粋に測ることができる。
例えば、特定の腫瘍の発症リスクを決定する重要な栄養素や食事パターンが実際にはなかったと仮定してみよう。また、科学文献では60種類の栄養素が調査され、そのすべてがこの腫瘍の発症リスクに関連しており、摂取量の多い層と少ない層を比較した場合の相対リスクが1.2から1.4の範囲にあると主張しているとしよう。そうすると、主張されている効果の大きさは、単にこの科学文献の作成に関与した正味のバイアスを測定しているに過ぎないことになる。主張されている効果の大きさは、実際には正味のバイアスの最も正確な推定値なのである。さらに、「無効な分野」の間で、より強い効果を主張する分野(多くの場合、医学的または公衆衛生上の重要性を伴う)は、単に最悪のバイアスを維持してきた分野であるということになる。
PPVが非常に低い分野では、少数の真の関係はこの全体像をあまり歪めないであろう。たとえ少数の関係が真実であったとしても、観察された効果の分布の形は、その分野に関わるバイアスの明確な尺度となる。この概念は、科学的結果の見方を完全に覆すものである。従来、研究者は、大きくて有意性の高い効果を、重要な発見の兆候として興奮して見てた。しかし、現代のほとんどの研究分野では、大きすぎる効果や高すぎる有意な効果は、実際には大きなバイアスの兆候である可能性が高い。研究者は、自分たちのデータ、分析、結果のどこに問題があったのか、注意深く批判的に考える必要がある。
もちろん、どの分野の研究者であっても、自分がキャリアを積んできた分野全体が「無効な分野」であることを受け入れることには抵抗があるであろう。しかし、他の証拠や技術・実験の進歩により、最終的には科学分野が解体されてしまう可能性もある。ある分野の正味の偏りを測定することは、同じような分析方法や技術、対立が存在する他の分野では、どの程度の偏りがあるのかを知るためにも有効である。
どうすれば状況を改善できるだろうか?
ほとんどの研究結果が誤りであることは避けられないのだろうか、それとも状況を改善することはできるのだろうか?大きな問題は、どのような研究課題においても、何が真実なのかを100%確実に知ることは不可能だということである。この点で、純粋な「ゴールド」スタンダードは達成不可能である。しかし、研究後の確率を改善するアプローチはいくつかある。
より検出力のあるエビデンス、例えば大規模研究やバイアスの少ないメタアナリシスなどは、未知の「ゴールド」スタンダードに近づくため、役に立つかもしれない。しかし、大規模研究にもバイアスがある可能性があり、それを認識し、避けるべきである。さらに、現在の研究で提起されている何百万、何兆もの研究課題すべてについて、大規模なエビデンスを得ることは不可能である。大規模エビデンスは、研究前の確率がすでにかなり高く、有意な研究所見があれば試験後の確率がかなり確定的と考えられるような研究課題に的を絞るべきである。また、大規模なエビデンスは、狭い特定の質問ではなく、主要な概念を検証できる場合に特に有効である。否定的な発見があれば、特定の提案された主張だけでなく、分野全体、あるいはそのかなりの部分を否定することができる。特定の医薬品の販売促進など、偏狭な基準に基づいて大規模研究の成果を選択することは、ほとんど無駄な研究である。さらに、非常に大規模な研究では、実際にはヌルと有意に異なるわけではない些細な効果について、形式的に統計的に有意な差を見つける可能性が高くなる可能性があることに注意すべきである[32-34]。
第二に、ほとんどのリサーチクエスチョンが多くのチームによって取り組まれており、特定のチームの統計的に有意な発見を強調するのは誤解を招く。重要なのは、証拠の総合性である。研究基準の強化や偏見の抑制を通じてバイアスを減少させることも有効かもしれない。しかし、これには科学的メンタリティの変革が必要であり、その実現は難しいかもしれない。研究デザインによっては、ランダム化試験など、研究を前もって登録することで、取り組みがより成功する場合もある[35]。登録は、仮説生成型研究にとって難題となる。分野内のデータコレクションや研究者の何らかの登録やネットワーキングは、仮説を生み出す実験の一つ一つを登録するよりも実現可能かもしれない。いずれにせよ、他分野の研究の登録に大きな進展が見られないとしても、プロトコルの作成と遵守の原則は、ランダム化比較試験からもっと広く借用できるかもしれない。
最後に、統計的有意性を追い求めるのではなく、研究努力が作用するR値の範囲(研究前の確率)の理解を深めるべきである[10]。実験を行う前に、研究者は、自分たちが真でない関係ではなく、真である関係を検証している可能性はどの程度あるのかを考えるべきである。そうすれば、推測される高いR値を確認できることがある。以上のように、倫理的に許容される場合はいつでも、比較的確立されていると考えられる研究結果について、バイアスを最小限に抑えた大規模な研究を行い、実際に確認される頻度を確認すべきである。私は、確立された「古典」のいくつかは、このテストに不合格になるのではないかと思っている[36]。
とはいえ、ほとんどの新発見は、研究前のオッズが低いか非常に低い、仮説を生み出す研究から生まれ続けるだろう。その上で、一つの研究報告における統計的有意差検定は、その報告以外や関連分野全般でどれだけの検定が行われたかを知ることなく、部分的なイメージしか与えないことを認めるべきである。多重検定補正に関する統計学的文献は多数存在するにもかかわらず[37]、通常、報告された研究結果に先立って、報告著者や他の研究チームがどれだけデータを浚渫したかを読み解くことは不可能である。仮にこれを決定することが可能であったとしても、研究前の確率を知ることはできない。従って、関連する研究分野や研究デザインにおいて、調査された中でどれだけの関係が真であると予想されるかについて、おおよその仮定を立てることは避けられない。より広い分野から、孤立した研究プロジェクトでこの確率を推定するための指針が得られるかもしれない。また、隣接する他の分野で検出されたバイアスからの経験も、参考にするのに有用であろう。これらの仮定はかなり主観的なものであるにせよ、研究の主張を解釈し、その文脈を整理する上で非常に有用である。
