

Contents
B. Doleman1 – J. P. Williams1 – J. Lund1
Received: 2019年5月27日 / Accepted: 2019年6月17日
はじめに
物議を醸した論文「Why most published research findings are false」[1]が書かれてから約10年が経過した今、私たちは発表されたメタアナリシスに関してこの問題を再考する。この論文のタイトルを読むと、考え込んでしまう人(あるいは激しく反対する人)もいるかもしれないが、Ioannidisの論文の結果を単純に支持するのであれば、論理的な結論として、一次研究のメタ分析も同様に虚偽である可能性があるということになる。実際,この論文では,小規模で結論の出ていない研究(非常に一般的)のメタ分析はおそらく誤りであると主張されている[1]。しかし、メタアナリシスが証拠のヒエラルキーの頂点に君臨しているにもかかわらず、どうしてこのようなことが起こるのであろうか(レトロスペクティブで観察的な性質であるにもかかわらず)。まず、我々の主張を裏付ける証拠を検証し、次に著者の周術期メタアナリシスの経験から得られた、メタアナリシスが大規模臨床試験の結果を予測するのに適していない理由を説明する。
大規模ランダム化比較試験からの結果の予測因子としてのメタアナリシス
後述する理由から、大規模(十分な検出力と多重度調整)でバイアスの少ない無作為化比較試験(RCT)は、医療における介入の効果を評価するためのゴールドスタンダードと考えられる。このような質の高い試験の結果を、同じテーマに関する過去のメタアナリシスと比較し、ポジティブ予測値(PPV)やネガティブ予測値(NPV)などの従来の統計を用いて、ゴールドスタンダードRCTの結果をメタアナリシスがどの程度予測しているかを定量化することができる。
ある研究では,医療介入に関する12の大規模RCTと,同じ問題を扱った19のメタアナリシスを比較し,ポジティブ予測値が68%,ネガティブ予測値が67%であることを示した[2]。また、別の研究では、ポジティブ予測値は67%未満であった。より手術に特化した研究では、周術期の介入を含む研究で、18のRCT(最新のメタアナリシスと比較して)と57のエンドポイント(メタアナリシスでは22が有意で、RCTでは5が有意)が含まれており、ネガティブ予測値は86%と高かったものの、ポジティブ予測値は23%しかなかった[3]。また、これに対応する受信者動作特性曲線下面積は0.57(コイントスに似ている)であった[3]。
したがって,「正」のメタアナリシスがあったとしても,その後の大規模なRCTで「正」の所見が得られる確率は受け入れがたいほど低く,特に周術期介入の分野では,後続のRCTで正の結果が得られる可能性は低くなる(有病率にもよるが).メタアナリシスを真実の最後の言葉として信頼しているにもかかわらず、メタアナリシスは、コインを投げるように、その後の決定的なRCTでも同じ結果(「真の」答え)を予測する。このような結果に戸惑う人もいるかもしれない。ここでは、これらの不一致の理由として考えられるものを検討する。
異質性
異質性とは、対象とした研究の間にある特徴の違いのことで、対象・除外基準や研究実施方法の違いなどがある。統計的な異質性は、各研究の推定値が偶然に期待される以上に異なる場合に発生し、I2(偶然のばらつきではなく、研究間のばらつきの割合)などの統計で定量化することができる。この概念を理解するために、手術後の死亡率を評価する以下の例を考えてみよう。あるメタアナリシス(図1)には、同一の手術参加者を対象に、同一の外科医、同一の方法論で実施された2つの試験が含まれている。その結果、結果は類似しているので、「真の」結果はメタ分析で得られたものと類似していると確信できる。次に、2つ目の例を考えてみよう(図2)。このメタアナリシスの2つの試験は、どちらも同じ介入を対象としているが、異なる患者(Dole-man 2019では救急患者を含む)で実施され、異なる方法論(Dole-man 2019では非盲検評価者を使用)で実施されている。そのため、結果が異なることになり、「真の」効果がどこにあるのか、より不確かになる。
図1 統計的異質性の低い2つの試験の結果を示したフォレストプロット

信頼区間が重なっていることから、random effects解析では全体的に信頼区間が狭くなっていることがわかる(黒菱形)
図2 統計的異質性の高い2つの試験の結果を示すフォレストプロット

信頼区間の重なりがないため,random effects analysis全体の信頼区間が広いことがわかる(黒菱形)
Heterogeneityは、レビューの著者が、結果を集計するための統計モデルの選択に用いることが多い。しかし、モデルは特定のI2値ではなく、モデルの仮定に基づいて選択する必要がある。fixed eff ectモデルは、推定する基礎的なeffectを1つ想定している。例えば、研究者が自分の病院の同じ集団(年齢、性別、介入内容が似ている)を用いて、標準化された方法で2つのRCTを実施し、この2つの研究を対象にメタアナリシスを行った場合、fixed effectモデルが妥当であると考えられる(図1)。しかし,ほとんどのメタアナリシスには,異なる集団で行われた研究が含まれており,この仮定が満たされることはほとんどないと考えられる。
そこで、より適切なモデルとして、random effectsモデルがある。このモデルでは、真のeffect sizeが研究ごとに異なる可能性を想定している(図2)。しかし,このモデルでは,推定する基礎的なeffectが異なることを前提としているため,統計的な不均一性が計算に組み込まれ(不均一性が増えると不正確さが増す),random effectsモデルを用いると不正確さが生じる可能性がある(図1に対して図2の信頼区間が広くなる菱形の幅を参照)。
これにもかかわらず、random effectsモデルでは、(多くのフォレストプロットや多くのメタアナリシスでの高いI2値に見られるように)ヘテロジニアスを排除することはできない。異質性が観察されれば,介入がより効果的である可能性がある場所について,新たな仮説を生み出すことができるが,これはメタアナリシスの長所としてあまり認識されていない[4]。死亡率に対する手術の架空の例(図2)では,Doleman 2019には救急患者が含まれているため,このグループでは介入がより効果的である可能性がある。
出版バイアス
Publication biasとは、「ポジティブな」試験を優先的に発表することである。ポジティブな試験は、ネガティブな結果の試験に比べて、発表される可能性が高く、かつ早く発表される。例えば、外科系の研究者が、腹腔鏡手術の在院日数への影響についての研究を行ったとする。終了後、腹腔鏡手術群と開腹手術群の間に差がないという結果が出ました。そのため、研究者は論文を投稿せずに、ファイルしておく。あるいは、3つの雑誌に投稿し、結果が「興味深い」ものではないと判断されたため、連続してリジェクトされ、各雑誌の査読プロセスを経るのに数か月を要する。これにより、研究が発表されないか、研究が肯定的な結果であった場合よりも遅く発表されることになる。出版バイアスの可能性(正確には、研究のeffectの不正確さ)は、effectの推定値と標準誤差の関係を示す非対称なファネルプロットで観察することができ(一般的に、研究サイズが大きいほど標準誤差は小さくなる)陰性の研究はプロットの右端に欠けていることがわかる(図3)。
図3 出版バイアス(不正確な研究結果)の可能性を示したファネルプロットで,大きい研究が上に,小さい研究が下になっている
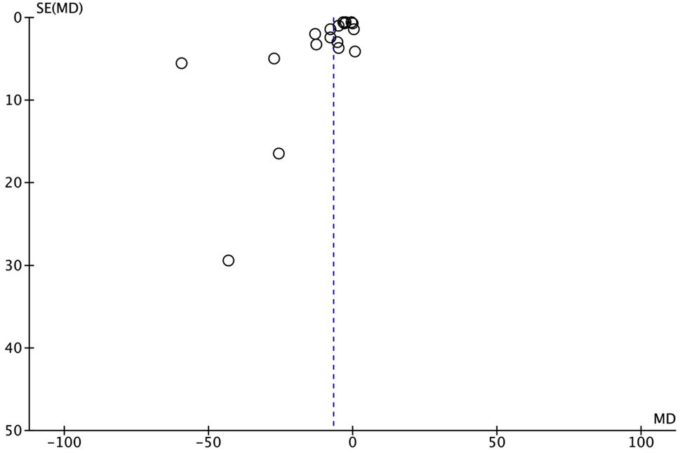
出版バイアスがなければ、小さな陰性研究がプロットの右下に存在し、逆ファネルのように見えるはずである。しかし、これらの研究が見当たらないことから、出版バイアスの可能性が示唆される。
出版バイアスの発生率は、50~80%と高い可能性がある[5]。出版バイアスの可能性を評価することは重要だが,レビューでは,臨床試験データベースや灰色文献検索から未発表のデータを検索して,出版バイアスを防止することが重要だ。しかし、徹底した検索戦略は、出版されたレビューの約20%にしか見られない。そのため、出版されたレビューの大半が出版バイアスの影響を受けやすい研究群に基づいている場合、これらのレビューから得られる結果は介入の「ポジティブ」な効果に偏ることになり、過去の研究で見られた劣悪なポジティブ予測値の一端を説明することになるかもしれない[2, 3]。同様に,出版バイアスの問題はレビュー自体にも及んでおり,レビューの著者はネガティブなレビューを投稿しないか,ジャーナルがネガティブなレビューを掲載しにくくなる可能性がある。
誤り
小規模なRCTのメタアナリシスを実施する利点の1つは、収集されたデータの検出力を向上させ、検出力不足の研究の中に「隠れていた」有益な介入を特定するのに役立つことである。パワー不足の小規模な研究に隠れていた有益性を特定した典型的な例は、早産におけるコルチコステロイドの使用であり、コクラン共同計画のロゴを形成しているフォレストプロットである。しかし、メタアナリシスを行ったからといって、そのようなパワーが得られるとは限らず、レビューがアンダーパワーのままになってしまうこともある(有意な差があるのに有意な差がないことを示す、あるいはタイプIIエラー)。
一次試験では、事後的に検出力を計算することができる。しかし、最近までメタアナリシスではそのような同等のものは一般的に使われなかった。逆に、ある領域で新しい試験が発表されると、再度メタアナリシスを行う機会があるが、複数の試験を行うと、解析にタイプIエラー(存在しないのに有意な差を示す)が生じる可能性がある。このようなリスクから、レビューにおけるタイプIエラーとタイプIIエラーの両方を減らすことができる試験逐次解析が開発された。
トライアルシーケンシャル解析では、エビデンス獲得の初期に、より高度な統計的有意性を要求することで、研究が追加されるごとにタイプIエラー率のコントロールを行う。さらに、一次試験における事後的な検出力の計算と同様に、特定の検出力(ユーザーが指定)を満たす結果を得るために必要な参加者数の計算にも役立つ。50件の麻酔科メタアナリシスのサンプルでは,適切な検出力(80%以上)を有していたのはわずか12%で,タイプIエラー率を維持していたのは32%であった(多重比較の調整後に統計的に有意であった)[6]。このような一般的なタイプIおよびタイプIIエラーは、上述の劣悪なポジティブ予測値およびネガティブ予測値の一因となるであろう[2, 3]。
バイアスのリスク
メタアナリシスは、それに含まれる試験と同じくらい優れている。試験の実施方法は、メタアナリシスの全体的な結果にバイアスをもたらす可能性がある[4]。不完全な盲検化などの試験実施の不備は,介入の効果を誇張する可能性がある[4]。盲検化の欠如は,被験者や観察者が介入の明らかな外部徴候に対して盲検化されていることを保証するために多大な想像力と努力を必要とする外科研究において,特に問題となる。盲検化が困難な場合や不可能な場合もあるが、それでも盲検化の欠如によるバイアスは軽減されず、誤った結論を導く可能性がある。
現在、メタアナリシスではバイアスリスクの評価が広く行われているが、バイアスリスクの高い試験を除外したり、質の低い試験の推定値を調整したりすること [4] は、必ずしも適切に行われているわけではない [7]。メタアナリシスの読者は、調査結果にどの程度の信頼性を置くかを決定する際に、この評価の有無を確認し、その結果または不在に注意する必要がある。解析におけるバイアスのリスクを減らすための解決策として、レビュー著者は、すべての領域でリスクが低いと評価された質の高い試験のみを含めることが挙げられる。これにより、組み入れられる研究の数は大幅に減るが(ほとんどの場合、一本も残らない!)結果に対する信頼性が高まり、メタアナリシスの予測能力が向上する可能性がある。
どうすれば大部分のメタアナリシスを真実にすることができるのか?
上述した多くの理由により,システマティックレビューから得られる高品質なエビデンスは,(コクラン・コラボレーション内であっても)当初考えられていたよりも低い可能性がある[8]。この記事で取り上げた解決策の可能性としては、(ジャーナルに掲載されるための要件の一部として)未発表の研究を徹底的に探し、欠落しているデータを提供するために研究の著者を粘り強く追求し、レビューによっては掲載に十分な質の高い研究が含まれていない可能性を考慮して、質の高い一次研究に対象を絞ることを含む検索計画を持つことが挙げられる。試験の逐次分析や異質性の調査は、将来の研究仮説を生み出したり、レビューに含まれる研究の結果がなぜ異なるのかを明らかにするのに役立つ。
出版バイアスは,ジャーナルが一次研究の出版スキームを保証することで,さらに減らすことができる.例えば,重要な臨床的疑問に答え,厳密な方法論を持ち,十分な検出力を持つ研究であれば,ジャーナルは被験者の募集前に研究を発表することに同意することができる.研究が完了すれば、結果の方向性に関わらず、その研究は出版される。これにより、優先順位の高い研究課題に資源を集中させることができる一方で、研究の完了と発表のための投稿の両方を奨励することができる。これらの変更は、上記の手段でポジティブ予測値が改善されるかどうかを実証的にテストすることができる。問題は、インパクトファクターの覇権とこだわりが克服されるまでは、ネガティブな(したがって引用されにくい)結果を出版する義務が生じることを恐れて、最も安全なジャーナル以外は、これに署名する可能性が低いということである。
ここからどうすればいいのか?
上記のような制限を受けない、質の高いRCT(特に個々の患者のデータ)のメタ分析は、異なる集団間での結果の一貫性を示し、検出力を高める可能性があるため、質の高いエビデンスを提供することは間違いない。残念ながら、このようなメタアナリシスは例外的なものである。しかし,小規模なRCTのメタアナリシスであっても,介入がより効果的である可能性がある場所を調査することで仮説を立てるのに役立つが[4],読者は健全な懐疑心を持って扱い,レビュー著者は結論を和らげるべきである。メタアナリシスの読者には,データの信頼性を確認することなく,単にフォレストプロットの総括的なダイアモンドを見たいという誘惑がある。正確な結論を導き出そうとするならば、この誘惑的な近道に抵抗しなければならず、すべての人がこのようなユビキタスなツールの正しい解釈について教育を受けるべきである。
メタアナリシスは、介入が潜在的に有益であると特定された場合、大規模なRCTの実施を促すこともある。メタアナリシスの結果が介入の決定的な証拠を提供しているとみなされることはまれで、むしろその分野で決定的なRCTの実施を促すべきである。最終的には、小規模でパワー不足のRCTにリソースを費やすのではなく、研究グループや臨床試験ネットワークは、研究課題に明確に答えるために十分なパワーを持ち、この記事で説明されているメタアナリシスの限界を避けるために、産業界のコントロールを受けない大規模な多施設試験を共同で行うことを目指すべきである。