
Contents
From Correlation to Causation: What Do We Need in the Historical Sciences?
pubmed.ncbi.nlm.nih.gov/27364751/
2016年6月30日
Received: 2015年8月23日 / Accepted: 2016年6月19日
概要
歴史科学の方法論の変化により、正当化できない憶測が科学的な結果として流布される危険性が高まっている。推測に基づく因果関係の仮定が、データの生成やデータ内の相関関係の確認に用いられているため、歴史科学の健全性が損なわれている。解決への一歩は、測定・観察されたデータから因果関係を推論するための仮定を、妥当なものと推測されるものとに区別することである。そのための一つの方法は、これらの仮定を、いわゆる「Bradford Hill Criteria」(BHC)のような、因果関係の側面についてよく知られたセットと比較することである。BHCは、因果関係のテストや因果関係の必要十分条件を提供するものではないが、さらなる調査のための根拠を示すものである。BHCを歴史科学のニーズと焦点を反映したものに改訂することで、調査方法の妥当性を評価することが可能になる。これが歴史科学ブラッドフォード・ヒル基準(HSBHC)となる。HSBHCの有効性を示すために、歴史科学の一つの分野である生物地理学への適用を行う。4つの方法を評価し、HSBHCがデータと因果関係のある生物地理学的プロセスとの間の仮定を検証するためにどのように使用できるかを示す。
キーワード
生物地理 データ 証拠 歴史科学 ブラッドフォード・ヒル 基準 系統学
1 はじめに
過去を研究する科学は、膨大なデータベースとコンピュータによる数値計算技術の出現により、その関係性を発見できるようになったことで、近年、大きく変化した。因果関係や歴史的な主張につながる推論を慎重に評価しなければ、これらの科学は、主張は相関関係にすぎず、単なる相関関係だけでは世界を説明するのには限界があるという非難を受けかねない。AがBと相関しているということ自体は、あまり興味深いことではない。相関関係に興味を持つのは、一方では相関関係を利用して、測定しやすいBからAの値を決定できるからであり、他方では、一方の変化に対する説明を求めて、他方の依存関係があると考えるからである。相関関係から、パラメータの値の変化を説明するのに使うような依存関係に移行する問題は、些細なことではない。私たちは直接、観測値の間に相関関係を見出するが、同じように観測値の間に因果関係を見出すことはできない。この問題は、新しいテストを実行する見込みがほとんどない歴史科学において特に顕著である(Wilkins and Ebach 2014)。ここでは、歴史科学の状況に焦点を当てる。
膨大な量のデータを扱う必要性は、ほとんどの科学分野では目新しいものであるが、John Snowが1854年にロンドンの路上で発生したコレラを調査して以来、疫学者はこの問題に取り組んできた。疫学者は、1854年にジョン・スノーがロンドンでコレラを調査して以来、この問題に取り組んできた。しかし、現在扱われているほとんどのケースでは、データセットが非常に膨大で、複雑で、多くの次元で異なっているため、データセットを視覚化できるように単純化するには、経験的に重要な仮定が必要になる(Tufte 1997, 2001)。以前は目で見て判断していたことも、今ではアルゴリズムに頼っている。ジョン・スノーは、ある水汲みポンプがコレラの発生源であるという理論を展開した後、ポンプの水へのアクセスを止めることで、コレラがそのポンプの水を摂取することに依存していることを示すことができるかどうかを調べたが、彼は単にポンプのハンドルを外しただけであった。因果関係があるとされるパラメータを操作することは、歴史科学においてはそれほど簡単ではない。歴史とは、ごくまれな例外を除いて、一回のサイコロ投げである。
2 疫学の教訓
ヒューム(1739)は、因果関係は観察できないと主張したが、説明の多くは因果関係の主張に依存している。私たちは、物事がどのようになっているかだけではなく、なぜそのようになっているのかを知りたいのだ。このことは、科学者にとっても、一般の人々にとっても同様の問題である。しかし、科学者が自らに課す基準は、一般市民のそれよりも高い。科学者が支持する因果関係の主張は、街中の家庭的な主張よりも強い正当性を必要とする。この問題は今に始まったことではなく、ヒュームの課題は早くから指摘されていたが、特に医学分野では、ある関係が本当に因果関係にあるのか、それとも単なる相関関係に過ぎないのかが、しばしば生死に関わる問題となる。相関関係から因果関係の理論に移行することは、なぜそのようなことが起こるのかを理解する上で非常に重要だ。疫学者は何十年も前から統計解析に取り組んでおり、どのような種類の相関関係が因果関係として正当に考えられるのかという疑問に最初に真剣に取り組んだ人物の一人である。著名な統計学者であり疫学者でもあるAustin Bradford Hill氏は、ある講演でこの問題を取り上げ、現在「Bradford Hill基準」として知られている一連の基準を提案した。この基準の目的は、潜在的に因果関係のある相関をそうでないものと区別するために、さらなる調査を必要とする関連性の側面を特定することであった。この基準は、因果関係の存在に対する正統的なテストや、因果関係の必要十分条件を提供するものではない。この基準は、どのような相関関係を調査する価値があるかを示すものである。限られた時間と資源の中では、すべての相関関係を調査することはできない。因果関係があると思われる結果が、因果関係よりも先に起こっているような相関関係を除外すれば、時間の節約になる。さらに問題なのは、そのような因果関係の主張を経験的に調査する方法である。疫学分野では、経験的な検証ができない複雑な因果関係の主張が多く見られる(Thapar and Rutter 2009; Russo 2009; Grimes and Schulz 2012)。因果関係のある仮説を検証することは、Snow氏がポンプのハンドルを外すような単純なことではない。
データのパターンには相関関係があり、ブラッドフォード・ヒルが「associations」と呼んだものである。これらの相関関係から、その相関関係を説明する因果関係の仮説に至るにはどうすればよいのであろうか。例えば、肥満と大きなベルトは相関関係にあるが、どちらかが他方を引き起こしているのであろうか。あるいは、これらの相関関係を説明する第三のもの、つまり共通の原因があるのであろうか、あるいは、これらの現象には因果関係がなく、これは偶然の相関関係なのであろうか。
疫学の分野では、喫煙と肺がんの相関関係を説明する際に、相関関係や「関連」に対する正しい因果関係のテーゼを特定することが典型的な例として挙げられる。喫煙と肺がんの関連性を主張することで、社会的、政治的、経済的、法的にどのような影響が出るかを考えると、歴史科学が精査されることはほとんどない。喫煙と肺がんの関連性を提唱したオースティン・ブラッドフォード・ヒル卿やリチャード・ドールのような疫学者にとって、彼らの主張はこのような精査に耐えなければならないであった(Doll and Hill 1950)。彼らの主張に反論したのは、ロナルド・A・フィッシャーをはじめとする非常に著名な統計学者たちであった(Stolley 1991)。ヒルは英国王立医学会の産業医学部門で行った会長講演で、2つの質問に答える形で基準(ブラッドフォード・ヒル基準)を紹介した。そもそも、病気や怪我と労働条件との関係をどのようにして検出するのか?職業上の物理的、化学的、心理的な危険、特に稀で容易に認識できない危険をどのように判断するのか?(Hill 1965)。言い換えれば、私たちが行うことと、その結果として生じる病気や怪我との間の関連性をどのようにして特定するのか?さらに、「因果関係の解釈として最も可能性が高いと判断する前に、その関連性のどのような側面を特に考慮すべきか」(Hill 1965: 295)。(Hill 1965: 295)である。Hillは9つの基準(表1)を提案し、それぞれが2つの観察された変数、すなわち行動とその結果としての影響(病気や怪我)の関連性を評価している。ヒルは、「…因果関係」の意味について哲学的な議論をするつもりはないし、その技術もない」と述べている(Hill 1965: 295)。私たちも同感である。この言葉の意味を知るための最良の方法は、因果関係の説明がどのように機能しているか、また、これらの説明を間違える可能性があることを知っている方法を見ることである。ここでは、因果関係を理解することを当然とし、因果関係を特定する方法を問う。疫学者が直面した、観測された相関関係の中から因果関係を特定するという課題は、歴史科学が直面した課題と全く同じである。歴史科学でも多重相関の問題に直面しており、因果関係の主張を独立して検証するには、疫学よりも歴史科学の方が状況が悪いと言える。これらの理由から、歴史科学、特に系統学や生物地理学における相関関係にブラッドフォード・ヒル基準を適用できるかどうかを確認することが重要であると考えている。
顕著な例としては、特に20世紀初頭から半ばにかけて、移行化石、つまり原始型と派生型の特徴が混在した種を主張していた古生物学者が挙げられる(Patterson 1982参照)。化石や生物の特定の構造が派生したものであるという考え方は、進化論を背景にすると同語反復になる。しかし、原始的な形態を識別できるという考え方、つまり、どの原始的な形態からどの特定の派生的な形態が変化したかを識別できるという考え方は、現在、生物学者や古生物学者によって部分的に否定されている(Williams and Ebach 2008)。例えば、ある分類群が別の分類群の祖先であるという主張は、広く議論されている。そのような知識は、生物の特徴だけでは決して判断できない。私たちが生物やその特徴、あるいはゲノムを調べるとき、祖先を直接測定するわけではない。その祖先を推論することはあっても、その推論はデータがすぐに言っていることを超えるものである。直接的に得られるデータは、分類群の祖先については沈黙したままである。しかし、祖先という概念は、系統学上、特性状態、つまりある特性の様々な現れ方を議論する際に広く採用されている。例えば、「eohippus」の4本の足指、「Mesohippus」の3本の足指、そして現代の馬の1本の足指は、すべて「Equine toes」という文字の表れ、あるいは文字状態である。eohippus」が「Mesohippus」に進化し、「Mesohippus」が「現代の馬」に直線的に進化したという主張は誤りであると考えられるが、それらの文字状態の変換は有効であると考えられる(MacFadden 2005)。つまり、EohippusがMesohippusの祖先であることはありえないとされているが、3本指のMesohippusの祖先が4本指の「Eohippus」を共有していたことはありえるとされているのである。ではなぜ、分類群間の変換はありえないとされ、そのキャラクターの変換はもっともらしいとされるのであろうか。その答えは、正当性の主張の仕方にある。
祖先という概念は、1920年代から 1930年代にかけて、近縁の分類群間の系統的な関係を示す証拠が、分類群の特性状態の中に存在すると考えたドイツの比較生物学者によって、早くから疑問視されていた(Naef 1919)。1930年代には、ヘッケルの「生物遺伝学的法則」はすでにボロボロになっており、発生学が系統学を再現しないことを示す多くの例があった。このことは、祖先に関する特別な知識を否定するものではなかったが、発生と進化の間に並列性があるという概念を否定するものであった(Nelson 1978参照)。しかし、広く受け入れられている、近縁種や類似した分類群を一連の幽霊系統によって時間的に結びつけるという方法は、形と時間の間の平行性を匂わせるものであった。初期の形態は「原始的」であり、後期の形態は「派生的」であるという議論であった。時間の違いによって両者を結びつけることは、古生物学者が提供できる唯一の「証拠」であった。他のいわゆる「証拠」は、4本指の馬が3本指の馬に、そして2本指の馬に進化したように、形の進行であった。これは、あたかも歴史的な勢いがあるかのように、想定される変化の方向性を強調するものであった。しかし、その後の体系的な分析により、この変化は人工的なものであり、「原始的な」形態が時間をかけて「派生的な」形態に進化したという仮定に基づいた人工的な系統であることが明らかになった。古生物学者は、時間を証拠として用いるのではなく、最優先の前提として、つまりデータを整合させるモデルとして用いた。このように、データが変形の仮説を支えていると仮定する方法は、クラッド学でも行われている。クラドグラムにマッピングされた文字状態が「反転」するという概念は、クラドロジーに特有のものである。反転とは、ヘビの手足の消失やノミの羽の消失など、特性状態の喪失を意味する。「喪失」は、「原始的な」文字状態が、派生した文字状態よりもクラドグラムの上位に見られる場合に確認される。この’「逆転」、すなわち0 ? 1 ? 0という逆転は、時間的な順序(バイオストラティグラフィ)の中で化石から「読み取られる」ゴースト系統と同様の進化的な変化として示される。この逆転は、キャラクターセットの「喪失」の「証拠」と見なされるが、進化の観点からはほとんど意味がない。まず第一に、手足や翼のような「喪失」のほとんどは、残存構造を残する。このことは、残存する文字状態は実際には派生的なものであり,0 ? 1 ? 反転を識別することは、古生物学者が幽霊の系統を識別するために使用するのと同じ戦術である。これらの2つの例は、系統学や生物地理学におけるより広範な問題を示しているに過ぎない。派生した文字状態の存在など、いくつかの仮定はもっともらしいのであるが(つまり、すべての文字状態は何かから派生している)どの文字状態が原始的なのかを特定することは非常に推測しやすいのである。問題なのは、ブラックボックス方式やモデリング方式を採用している科学者の多くが、自分たちが採用している方式に、非常に憶測に満ちた、あるいはありえない仮定が含まれていることに気付いていないことである。理想的なアプローチは、科学者が自分の仮説がどれだけ優れているか、特にこれらの仮説がどれだけデータに裏付けられているかを批判的に評価するために、系統学的および生物地理学的アプローチの推測性と非現実性を測定することである。データがどれだけモデルに適合しているか(つまり、「自分のデータがどれだけモデルに支持されているか」)という考え方が主流になっているため、多くの生物地理学者や系統学者は、自分のデータを因果関係のあるプロセスに結びつける方法を失っている。正しい姿勢は、「私のモデルがどれだけデータに支持されているか」である。後者の場合、疫学においてデータと因果関係のリンクを評価するのと同じように、既存の手法やモデルの前提条件を評価する方法が必要となる。
3 系統学と生物地理学における因果関係の主張の識別と評価
私たちがアクセスできる証拠は、私たちと同時代のものであることを覚えておくことが重要だ。過去は文字通り私たちのものではないが、過去の痕跡はある。このことは、私たちが興味を持ちそうな歴史的出来事の証拠にも当てはまるし、生物学的事例や人類の歴史にも同じように当てはまる。バトル・オブ・ブリテンに関する証拠はすべて私たちと同時代のものであり、これにはフィルム、記憶、構造物、書籍などが含まれる。バトル・オブ・ブリテンが行われたことを示す証拠として何を提示するかを考えてみよう。イギリスの田園地帯には、いまだに残骸となっている飛行機がある。慰霊碑もある。陸軍省の活動の記録がある。映画がある。連合国側と枢軸国側の両方の攻撃と損失を詳述した公式文書がある。生存者の記憶もある。何かが証拠として認められるためには、私たちと同時代のものでなければならない。これは、証拠があったことを示す証拠にも当てはまる。例えば、今は亡き生存者へのインタビューの現存する記録は、生存者の過去の記憶のエピソードの現存する証拠とみなされるべきである。生物学的な歴史についても同様である。ある歴史的な出来事について必要とされる証拠は、先に述べたような補助的な仮説に基づいて推論を行うための、現代の証拠でなければならない。
データセットに含まれるデータは、まず第一に、測定結果である。このようなデータは通常、裏付けや検証を行う理論から独立しているという重要な意味がある。いかなるデータも、それ自体ではその起源を証明することはできない。データを使用する際には、データが文字通り意味するものと、データと他の先行する理論的な約束事に基づいて行われる推論とを区別したい。例えば、ある恐竜(獣脚類)は、他の恐竜に比べて鳥類との共通点が多いことが、限られた数の文字を調べることで明らかになる。そのことはデータを見れば一目瞭然であり、その情報を様々な方法でプロットすることができる。繰り返しになるが、これは獣脚類と鳥類が、獣脚類と他の恐竜との間でより多くの特徴を共有しているということではなく、我々が測定した限られた特徴のセットにおいて、そのような関係が成り立っているということに過ぎない。常識的な判断への移行は、データからの推定であり、論理的に正しいことが保証されているわけではない。仮に、収集したデータを文字セットの重なりで分類する分岐図にプロットすることにしよう。この図は系統図のように見えるかもしれないが、現状では収集したデータを絵で表したものに過ぎない。データを分岐図としてプロットすることで、データを超えて分類群の因果関係を明らかにすることができるのかどうかという疑問があるが、これについては後述する。しかし、明らかなのは、獣脚類が鳥類の祖先であるという仮説に至るまでには、データから得られる直接的な情報を超えているということである。獣脚類と鳥類の祖先関係についての仮説を推論するには、鳥類と獣脚類の間に観察される特徴の共通性の説明について、多くの仮定が必要となる。
データの収集とその表現には多くの場合、理論が盛り込まれているが、必ずしも評価対象の理論に関連した方法ではない(Wilkins and Ebach 2014)。この明らかに正しい主張は、しばしば誤った主張と混同されるからである。つまり、データは本質的に理論を含んでいるので、理論に対する証拠としてデータを使用することはできず、したがってデータの使用には循環性がないとは言えない、というものである。この誤った主張は、データ収集の基盤となっている理論と、データが証拠として用いられる理論との区別に十分な注意を払っていないことに注意してほしい。この区別は、簡単な例で十分にわかる。1919年にエディントンが望遠鏡を使って、日食中の星の見かけの位置の変化を測定したとき、彼はアインシュタインの一般相対性理論による予測を検証していた。望遠鏡の理論は、ニュートンの理論を前提としているように見えるが、それは間違いだ。望遠鏡の理論は、アインシュタインの理論とニュートンの理論の両方を制限する、より一般的な理論を必要とする。そのため、データ収集の際に前提としている理論が、テストされる理論と常に一致しているとは言えないのである。
ある理論に対してデータがニュートラルであったとしても、そのデータを因果関係のある説明を含む別の理論に結びつけようとする際には、さらなる前提(明示的、暗黙的な仮説)が必要になる。この論文で我々が主に関心を持っているのは、因果関係へのリンクを作るためのこれらの補助的な仮定の使用である。このスキームを以下のように表現することができる (図 1)。
データ(人間が観察・測定したもの)þ前提条件
– 因果関係の主張 (人間による解釈)
このように考えると、3つの主張をすることができる。
図1 恐竜と爬虫類の非単生性を関係性で示す(竜脚類、(鳥類、獣脚類))
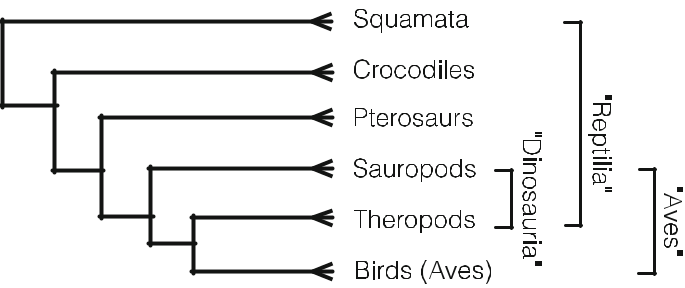
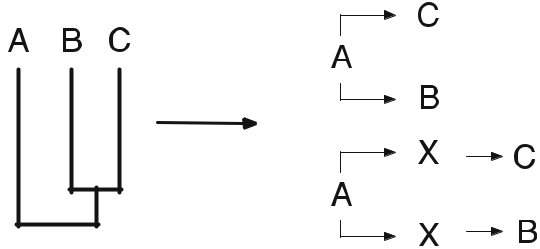
- データは様々な方法で表現することができる(=構造化データ)。例えば、非構造化データ、例えば形態的特徴とそれが属する分類のバイナリデータセットは、階層的な分岐図(構造化データ)で表現することができ、その図は単に共有された特徴を表している。構造化されていないデータと構造化された表現は、互いに変換され、同じ情報の別の表現となる。クラドグラム(図2)は、各分類群の特徴的な状態(図3)に基づいて、分類群間の地形的な関係を示している。
- 構造化されたデータは、歴史的な因果関係を示す点では、非構造化データと変わらない。
構造化されていないデータは、基本的には異なる分類群が持つ特性の比較であり、それだけでは、歴史的な因果関係の仮説を論理的に裏付けるものではない。例えば、特性状態の変換、すなわち系統学のような明確な仮説があるかもしれない。系統学的な主張に移行するには、構造化されたデータの特定の解釈につながる一連のさらなる仮説が必要となる。例えば、クラドグラムの地形的な関係は、系統樹に類似していると仮定することができる。この系統樹の仮定には、文字変換(クラドグラムの基底ノードには歴史的に原始的な文字状態が含まれ、入れ子になったノードには歴史的に派生した文字状態が含まれる)など、いくつかの明示的な仮説が含まれている場合がある。また、生物地理学的な仮定として、基本的な分類群は祖先の地域に近いところで発見されるという仮説もある。また、クラドグラムの分岐は、クラドジェネシスと同じであるという仮説もある。つまり、構造化されたデータは、仮定があるからこそ、そのような歴史的・因果的な仮説を導くことができるのである。これを踏まえて、私たちの論証スキームを修正することができる。
図2 a クラドグラム。分類群は末端のノードで発見され、ノードで文字状態を共有している。b クラドグラムはベン図として描くことができる。 c 末端の枝は系統ではないので、クラドグラムの親字形式である(A, (B, (C, D)) )の括弧に類似している。
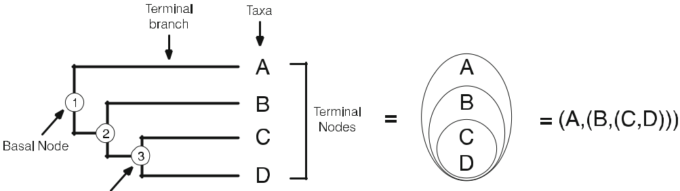
図3 非構造化マトリクスの文字状態は、文字ツリーの形で構造化データとして表現できる
因果関係仮説の推論は、このような前提条件に大きく依存する。
3.歴史科学では仮定はテストされない。
データセットから歴史的・因果的テーゼへと導く仮定の重要性を考えると、仮定をテストすることは、歴史的・因果的テーゼへの推論の正当性を評価する上で非常に重要である。歴史科学では、歴史上の出来事を目撃したり記録したりすることができないため、因果関係は隠されている。私たちが入手できるのは、痕跡、つまり関心のある出来事の現在の因果関係だけだ。例えば、大きな隕石の衝突、生きている恐竜、超大陸などを人間が観測した例はほとんどないと思う。私たちは、痕跡証拠や観察された因果関係のある出来事、例えば小さな隕石の衝突、鳥、テクノストラティグラフのテレーンなどからこれらを解釈する。おそらくこれが、例えば分類学や古生物学などの多くの歴史科学が、ほとんどが記述的なものであり、検証を拒む理由なのであろう。仮定は、構造化されたデータからさらなる重要性を推定するための方法である。例えば、分岐図は伝統的に、ノードが既知または未知の祖先化石分類群を表す実際の進化の木を表していると解釈されていた。この仮定に対する挑戦は、クラディスト改革という形で行われ、化石の祖先を知っていて特定するという概念に疑問を投げかけた(Williams and Ebach 2008参照)。例えば、初期のクラディストは、末端のノードで全ての分類群を同等に扱うことで古生物学的な仮定を否定した(Patterson 1982)。この2つの仮定の違いは、「祖先は知ることができる」対「祖先は知ることができず、識別することができない」という点である。前者は非常に推測的な仮定であるのに対し、後者は祖先を特定することの限界を認識しており、妥当性を保っている(つまり、実際の祖先を発見したことを知ることはできないかもしれない)。3つ目のアプローチである系統学的な仮定は、ノードが仮想的な祖先として機能するというものである。これは、初期のクラディストが仮定したように、分岐図はクラドジェネシスのみで進行した進化の過程を捉えているという系統学的な仮説を受け入れた場合、ノードが存在することが予想されるからである。
このように考えると、次の4つのタイプの仮定を区別することができる。
1. 適用不可能な仮定 構造化されたデータを事実の記述(例えば、説明や観察)としてのみ捉える仮定。適用できない仮定とは、データの限界を認識するだけで、構造化データから何が推測できるかについては何も仮定しないものである。例えば、BとCは、他のどの分類群よりもAに近縁であると述べることができる(図1)。しかし、「関係」という言葉が意味するのは、データから明らかになった歴史的な主張ではなく、分類群が3番目よりも多くの特性状態を共有しているということだけだ。
2.もっともらしい仮説とは、構造化されたデータから信頼性のある推測ができることについて、もっともらしい主張をする仮説のことである。もっともらしい仮定とは、構造データから推測できることの限界を認識し、それを超えて推測することはない。例えば、BとCは、他のどの分類群よりもAに近縁であると述べることができる(図1)。ここでは、その関係が歴史的なものであると推論することができる(つまり、BとCはAとは共有していない未知の共通の祖先を共有しているのです)。
3. 投機的仮定とは,構造化されたデータから推論できることを推測的に主張する仮説である。推測的仮説は、明示的仮説に基づいて認識された限界を超えて外挿する。例えば、BとCは、他のどの分類群よりもAに近縁であるとすることができる(図1)。ここでは、その関係が明確に祖先的なものであると推論することができる(例えば、分類群Cは分類群Aから派生した分類群Bから派生したものである)。
4. 「ありえない仮定」とは、ありえない、あるいは検証不可能なプロセスや出来事、物事に ついて知識を主張する仮説のことである。ありえない仮定は、元のデータが何を示しているかに関わらず、明示的な仮説を強制する。例えば、BとCは、他のどの分類群よりもAに近縁であると述べることができる(図1)。ここでは、その関係が既知のものであると述べることができる(例えば、分類群BとCは分類群Aから同じように派生したものである)。
4 ヒューマンエラー 単純にデータを間違えてしまった場合
私たちの仮定がもっともらしくても、データに問題がある場合はどうなるであろうか。ここでもデータの中立性を主張するが、持続可能なヒューマンエラーが原因で誤ったデータ(例:タイプミス、重複、誤認識など)が発生した場合でも、通常は情報量の多いデータがデータセットの大半を占める。例えば、Di Virgilio et al 2012)による地理空間の研究では、データの25%にヒューマンエラーに起因する情報量の少ないデータが含まれていることが確認された。この研究では、NSW Office of Environment and Heritage(OEH)のAtlas of NSW Wildlifeという大規模なデータセットを洗浄した。このデータセットには、「1788年から 2009年12月までにNSW州で目撃された動植物の地理的位置」が含まれている。この研究は、在来種の生物相の地理的断絶を見つけることを目的としているが、約20%のデータが誤っていることがわかった。誤ったデータや誤解を招くようなデータにフラグを立てるために採用された基準は、「既知の分類群に似ていると示されたレコード(すなわち、cf.またはaff.のフラグが付いたレコード)は、その同一性についての不確実性を避けるために削除された(…)。属がsp.やspp.のようにフラグが立てられている場合、[…]亜種や変種とされたレコードは削除された[…]。
Isoodon perameles sp.のように、「属種」ではなく2つの属名で1つのレコードが表示される場合は削除された。Di Virgilio er al)。 (2012, Appendix S1, p. 1). また、不正確な地理的座標を含む誤植も削除した。残念ながら、すべてのデータセットの分類学的不正確さを検査する仕組みを経済的に正当化することは困難であり、そのためにはそれらのデータポイントを独立して評価する必要がある。問題のあるデータは一般的に大規模データセットの約20%を占めるが、分析結果全体に影響を与える可能性があり、特にそのようなデータセットに基づいた推測を弱めたり、無くしたりする可能性がある。
構造化されていないデータは、問題のあるデータポイントが含まれているかどうかの問題については沈黙している。しかし、分析の前に仮説や仮定を立てた場合、結果を操作するために、元のデータセットに余分なデータを追加したり、元のデータを脇に置いたりすることがある。これは、データポイントの測定をやり直すのではなく、実際のデータポイントを評価する方法として、データがどのように見えるべきかという前もっての期待を伴うことに注意してほしい。これは憂慮すべきデータの循環的な操作である。
5 方法論への依存。前提条件がデータを操作する場合
非構造化データから構造化データへの移行方法のすべてが、論理的に良しとされるわけではない。前述したように、文字セットは元のデータセットと論理的に同等の方法で構造化データとして表現することができ、一方から他方への推論は論理的に些細なことである。非構造化データを構造化データに変換するために、数値計算法がよく使われる。優れた手法とは、仮想的な非構造化データセットの中に既知の地形的関係を見出すことができるものである。例えば、構造化されていないバイナリデータセットでは、1つのクラドグラムが見つかる(図3)。ここで、分類群名をその分類群が出現する領域に置き換えると、アレーグラムができる(図4)。しかし、エリアx、y、zの関係はどうなっているのであろうか?この問題を手で解いてみると、(z,(x, y))という関係がすぐにわかる。しかし、Brooks Parsimony Analysis (BPA, Wiley 1987)のような数値的手法を導入すると、明確な仮説やモデル(ノードが末端のエリアの祖先であること)と仮定(エリアグラムが空間上の進化の木と同等であること)を導入することになる。BPAでは、これらの仮説を解析前に呼び出すことで、下位のノードがエリアにコード化され、元のデータにはない新たな関係性を持つデータを導入する(図5)。
図4 分類名を地域名に置き換えると等値線ができる。アザグラムのノードには、キャラクターステータスや祖先に関する情報が含まれていないことに注意。

BPAのような数値計算法は、仮定駆動型の方法論の典型的な例である。つまり、構造化されていないデータに背景となる理論的な仮定を加え、その仮定によってノードが祖先の地域を表していると推測するのである。その結果、収集されたデータは、元のデータを代表するものではなく、祖先の地域に関する主張を裏付けるものとして解釈されることになる。これらの主張は、その根拠となる仮定と同様に推測の域を出ません。
5.1 セオリーとファッション。ある仮定が優先される場合
仮定が単なる推測である場合、その普及は証拠の変化よりもパンデミックや人気によるものが多いようである。例えば、クラドグラムはクラドジェネティックな事象しか描かれていないと解釈されているが、アナゲネシスも同様にもっともらしい説明となる(図6a)。いずれにしても、クラドグラムはクラドジェネティックなものでなければならないという前提が多くある。しかし、クラドゲナイズされた系統を構造化されたデータ、つまり経験的に測定されたデータに変換すると、クラドゲナイズされた系統は必ずしも元のクラドグラムを回復しないことがわかった(図6b)。これは、クラドグラムがクラドジェネシスの結果だけを表していると考えること自体が、経験的な根拠のない仮定であることを疑っているのである。
このように、データにはヒューマンエラーがつきものであり、不当な補助的な仮定に基づいて、その仮定に依存した結論を出してしまうことがある。誤字脱字や地理的なミスをアルゴリズムで定量化する方法はあるが、分析の前後に行われる推測性の高い補助的な仮定を定量化することは事実上不可能である。このような理由から、データと因果推論の間のリンクの質を評価しようとすると、現実的ではない。さらに、正当な仮定やリンクとそうでないものとを区別することは、多くの科学者にとって、すべての分析結果を等しく信頼するという選択肢がないことを意味する。
図 5 BPA は、 元のダイアグラムのすべてのノードを再コード化し (a)、 新しいデータを再実行して (b)、 元のデータセットとはほとんど、 あるいはまったく関係のない、 別の構造化されたデータセット (c) を作成する。例えば、aに存在する唯一の関係は(z, (x, y))であり、cには存在しない。実際、cの関係は元のデータセットには存在せず、元のデータではなく手法によって作成されたことになる。
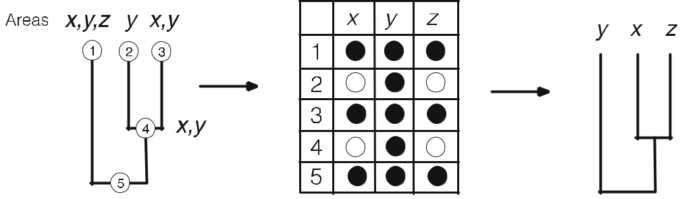
図6 クラドグラム(A, (B, C))には、5つの可能な系統が含まれており、そのうちのいくつかは矛盾している。a すべてのアナジェニックな系統と1つのクラドジェネティックな系統は、元のクラドグラムを回復している。なお、すべてのクラドジェネティックな系統樹は、元のクラドグラムを回復させるために、仮説的な祖先を必要とする。
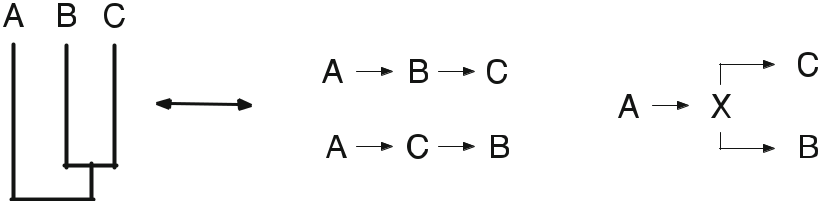
6 Hillの歴史科学の標準基準の改訂
1965年以来、Hillの基準は、医学科学、特に疫学の中での変化に適応するために、何度か変更(および挑戦)されていた(例えば、Phillips and Goodman 2004)。しかし、Howick et al 2009)によるHill’s Criteriaの最近の改訂により、より合理的な基準、すなわちRevised Bradford Hill Criteria(RBHC)が生まれ、ここではこれを使用することにした(比較のために表1を参照)。これらの基準は現在も一般的に使用されており、疫学における因果関係を見極めるための論理的構造に合致している(Broadbent 2011; Ho¨fler 2005)。しかし、歴史科学、特に系統学や生物地理学では、このような基準は作られていない。ここでは、歴史科学における様々な種類の相関関係を区別するのに有用な、これらの基準を再構築する方法を提案したいと思う。そのために、我々はHistorical Sciences Bradford Hill Criteria (HSBHC)を考案した。
ここで開発したHSBHCは、(Howick et al 2009)のRBHCを適応したものである。HSBHCの目的は、データの品質を評価し、系統学や生物地理学で見られる様々な種類の相関関係を調べることである。HSBHCは6つの基準からなり、特に系統学と生物地理学で使用するために開発されたもので(表1)以下の通りである。
直接的証拠(Direct Evidence)とは、(Howick er al 2009: 187)「2つの要素間の確率的な関連性を示す『直接』の証拠が、偽りではなく因果関係にあるかどうか」と定義されている。歴史科学の場合、この因果関係は、正確には歴史的シナリオと呼ばれている。歴史的シナリオの直接証拠は、異なるデータセットの相関関係や重複に基づいて蓄積される。直接的な証拠は、「選択バイアス」と「時間性」に分類される。
1. 選択バイアス
生物地理学や系統学におけるもっともらしい交絡因子とは、主に分析で考慮されていない主なデータや証拠であり、結果に直接影響を与える可能性のある要因である。例えば、多くの生物地理学的研究では、十分な検討をせずに、その場しのぎの、あるいは恣意的な地域を選んで分析を行っている(Sanmartı´n and Ronquist 2004; Parenti and Ebach 2013を参照)。多くの場合、エリアのサイズや形状を変更するだけで、まったく異なる結果が得られる可能性がある。例えば系統学では、解析に使用される遺伝子の種類に選択バイアスがかかる(Cox er al)。
2. 時間性
特に歴史的生物地理学において問題となる。現在の分布は過去の出来事の結果である(Ebach 1999)。そのため、現在生きている異なる分類群が、異なる時代に起こった異なる出来事の結果である可能性がある。単一の歴史的イベント(例えば、漸新世のニュージーランドの溺死 *30 Ma)をより大きな生物地理学的問題に対処するために使用することで、ニュージーランドの生物相の年齢についていくつかの議論が行われていた(Landis er al 2006; Waters 2008)。単一事象仮説は稀であるが、その妥当性を検証するための調査はほとんど行われていないのが一般的である(Ladiges and Cantrill 2007参照)。
3.介入と結果を結びつける因果関係を裏付ける機序的証拠
系統学や生物地理学では、文書化された観察可能なプロセスは稀である。その代わりに、利用可能なデータから間接的に裏付けられる推論が行われる。同じ特徴を持つ姉妹分類群は、共通の歴史的出来事(すなわち、共通の祖先;Hennig 1966)によって関連している可能性がある。しかし、異なる生物地理学的地域に生息する姉妹分類群は、分散の証拠とはならない。むしろ、分散は推測される一つのプロセスかもしれない。歴史科学では、証拠と推論がしばしば混同される。
並列的な証拠は、相関関係の独立した「テスト」であり、「一貫性」、「複製可能性」、「類似性」に分類される。
4. 一貫性
因果関係のある仮説が、現在知られていることと一致しているか、あるいは現在の知識と矛盾しているかという問題は、歴史科学において非常に重要である。例えば、ハリモグラとヤマアラシを密接に関連付ける分子系統分析は、この基準に違反する。しかし、新しく記載された分類群はそうではないかもしれない。また、化石の系統に基づく古生物地理学的再構築と古地磁気データに基づく古地理学的再構築が大きく異なる場合も同様である。
5. 再現性
歴史科学は、実験科学とは異なり、実験的な複製可能性よりも相関関係に基づいている。異なるデータセット間の相関関係(すなわち、パターンの集約)が再現性の類似性をもたらす。例えば、系統学では、異なる遺伝子の木の間のパターンを集約したものとなる。生物地理学では、古地理復元図と生物地理学的パターンとの間の相関関係(重なり具合)である。
6. 類似性
同じ分類群から得られた2つの異なるデータセットが同じ結果になるかどうかを意味する。例えば、同じ植物の分類群に対して、なぜ異なるデータセットが対立するのか(Cox er al 2014)。Cox et al 2014)の分析によると、Qiu et al 2006)によるオリジナルの入力データは、「主にタンパク質をコードする遺伝子の同義置換に存在する、変異圧による組成バイアスの補正が行われていない」ことが原因で危険にさらされていたが、(Cox et al 2014)によって(Karol et al 2010)のアミノ酸データセットと比較されるまで、その誤りに気づかなかったのである。
異なるデータセット間の類似性は、証拠間の妥当性の度合いを確立するために不可欠である。上記のケースでは、Qiu et al 2006)は、蘚苔類の単藻性を否定するために、Karol et al 2010)とは独立して今でも使用されている(Qiu et al 2012)参照)。これらの6つの基準を併用することで、データセットと結果の間の因果関係を推論する際に、どこに仮定が入っているかを見つけ、研究の質を評価することができる。
7 歴史科学における標準的な基準の導入
ここでは、生物地理学と系統学の2つの例を挙げ、データ(証拠)と因果関係のある説明の間の推論をテストするために、HSBHCをどのように実装することができるかを示する。ここでは、生物地理学と系統学の両方で一般的に使用されている、枝分かれした木構造を利用したモデルに焦点を当てる。
7.1 生物地理学的特性状態の再構築
生物地理学でよく使われる手法はDispersal-Extinction-Cladogenesis Model (DEC)であり、これは仮説的な系統の中で特性状態の再構築を行うものである(Ree er al 2005; Ree and Smith 2008)。このモデルでは、「系統の分散と離散的な地域での局所的な絶滅を、連続した時間における確率的なイベントとしてモデル化した、系統の地理的範囲の進化を推測するための尤度フレームワーク」を使用している(Ree er al)。 事実上、これは祖先領域の可能性を計算し、それを系統樹上に最適化することを意味し、その際、枝の長さは「分岐時間と、領域間の系統分散率および領域内の絶滅率のパラメータを得るために較正される」(Ree er al)。 Ree et al 2005)は、自分たちのアプローチがareagramsから離れていることを主張しているが、系統樹は依然として実装に不可欠である。
DECモデルでは、以下の4つの前提を置いている。
- 種の範囲は分散と絶滅の結果である。Ree and Smith (2008) は、地理的分散やバイカリアンスなど、他の実行可能な生物地理学的プロセスを同様に考えていない。
- 分岐する枝はクラドジェネティックなイベントを表し、アナジェニックな変化は系統的な節目で表される。
- 地域は定義されていない個別の地理的単位として扱われる。
- 地域間の分散ルートは既知であると仮定する(Sensu Darlington 1965)。
HSBHCの結果では、いくつかの関連性が因果関係があるとは考えられないことがわかった。選択バイアスの下では、DECモデルはエリアをその場しのぎで選択してしまうという問題がある。例えば,このモデルでは,2つの近縁種が広大な地域に広がっている場合,大陸を生存可能な地域として扱うことができる。また、このモデルは「時間性」の基準でも失敗している。枝の長さには時間性の証拠はなく、各枝に存在する文字状態の数に数値が割り当てられている。データには時間性についての記述がないため、時間性とこの数値との関連性は希薄である。DECモデルのメカニズム的証拠は、種子散布の指標となる種子の生理現象など、他の場所で得られた証拠に基づく既知の散布ルートに基づいている。問題は、分散が観察されることはほとんどなく、地理的に近接した地域に生息する分類群が分散ルートを共有していると仮定することは、単なる希望的観測に過ぎないということである。DECモデルでは、歴史的な出来事を実際の地質データからではなく、系統樹から直接解釈するため、一貫性を保つ余地がほとんどない。また、DECモデルは、他のデータと独立して比較することができないため、再現性がない。類似性についても同様で、同じ分類群の別のデータセットから同じ結果が得られるかどうかを独立して検証する方法がない。mDNA と核 DNA の系統樹は枝の長さが大きく異なるため、結果は必ずしも同じにはならないであろう。
7.2 HSBHCはモデルの検証に使われるべきか?
歴史科学におけるモデルの多くは、データに含まれる証拠だけでなく、補助的な仮定に基づいている。一連の仮定を分岐図に最適化しても、もっともらしい仮定としてHSBHCを通過することはない。例えば、枝の長さ(ノードでの文字状態の数)を考えてみよう。あるモデルでは、これを進化の速度として扱い、別のモデルでは、系統の分散の指標として扱うことができる。しかし、データには時間性や分散に関する情報がないため、これらのモデルには証拠がない。DECのような歴史的モデルは、事実上、仮定の上に成り立つ仮定なのである。では、HSBHCは何を根拠にしているのであろうか?
もし、DECのようなモデルが、(例えば、系統分岐の証拠としてではなく)特定の分野における仮説として純粋に扱われるのであれば、HSBHCは必要ないであろう。しかし、科学者が自分の仮定が証拠に裏打ちされていると主張する場合には、モデルの選択的な部分にHSBHCを使用することができる。例えば、DECでは、再現性と類似性という基準の中での妥当性は単に達成できない。これらの基準は、仮定に関連する証拠の主張を無効にし、DECモデルのこれらの部分は、純粋に仮説として扱うことができる。要するに、モデルが複雑であればあるほど、仮定はより推測的であり、ありえないものとなる。複雑なモデルは、非常に推測しやすい仮定の下でデータを外挿するように設計されている。一方、もっともらしい仮定を持つ単純なモデルは、HSBHCを通過する可能性が高くなる。
7.3 歴史的生物地理学におけるモデルの比較
比較的単純なものから複雑なものまで様々な理論やモデルの仮定を評価する上でのHSBHCの役割を確認するために、クラディズム生物地理学における3つの一般的な手法を比較してみる。Area Cladistics (Ebach 1999),BPA,Ancestral Area Analysis (Bremer 1992)である。それぞれの手法では、面積関係の基礎となる仮定として、等値線を用いている。これらの手法は、生物地理学的なプロセスや出来事に対する解釈が異なる。
地域クラッド学では、地理的な一致を見出すために、複数の等値線を用いて一般的な等値線を求める。エリア・クラディスティックは3つの前提を置いている。
- 地理的整合性は近縁種の結果である。
- 一般的なアザグラムをジオグラムと比較することで、エリア関係の年代を特定できる。
- 一般的なエラグラムは、より大きなエリアの有効性をテストするために使用することができる。
BPAは単一または複数のエリアグラムを使用してデータマトリックス(分類群対エリア)を構築し、その中でノードは仮想的な祖先として扱われる。結果として得られる一般的な等値線のノードは、そのノードにおける祖先の生物地理学的分布を示している。BPAの基本的な仮定は以下の通りである。
- ノードは仮想的な祖先を表す。
- データマトリックスは、エリア間の元の関係を維持する。
- 一致していることを周辺環境と解釈する。
- 一致しないデータは、他の生物地理学的プロセスとして解釈される。
Ancestral Area Analysis (AAA)は、断片化された祖先の領域にどの分類群が見られるかを決定するために、エリアグラムを使用する。この方法では、利益と損失のシステムを使って各エリアの価値を計算する。
AAAは以下のような仮定をしている。
- 複製された領域は、元の祖先の領域の断片化された領域である。
- 重複している部分の地図上での位置が祖先を決定する。
- も基底部に位置する部分は、祖先の部分である可能性が高い。
これらの仮定を比較すると(表2)BPAとAAAの両方がHSBHCの多くを失敗しているのに対し、エリア・クラディスティックはテストに合格している(最もありえない仮定をしていない)ことがわかる。その理由は、BPAとAAAの両方が、非常に非現実的な仮定をしているからである。つまり、エリアグラムのノードを実際の仮説的な祖先やエリアとして想定しているのである(Ebach 1999; Ebach er al)。 アリアグラムは単なる枝分かれした図であり、末端のノードに既に存在しているもの以外の情報はノードにはない。ノードが枝分かれした階層の中の分岐点以上のものであることを示唆する証拠はない。このような複雑なモデルが、ありえない主張をする可能性が高いのであれば、なぜこれほど人気があるのであろうか?
表2 BPA、AAA、Area Cladistics、DECの基礎となる仮定をHSBHCと比較した結果
原文参照
適用できない仮定は白、もっともらしい仮定は緑、推測できる仮定はオレンジ、ありえない仮定は赤で示している。
8 Keep it Simple Stupid: 歴史科学における複雑なモデルの問題点を指摘する
歴史科学では、因果関係のある歴史的説明をどのように推測するかという問題を明確に扱うことは非常に限られている。それにもかかわらず、歴史科学者たちは自分たちのデータについて推測的な主張をする。
ジャンプ分散は、人間のタイムスケールでは稀な出来事が地質学的なタイムスケールでは一般的であること、そして生物多様性は主にこれらの稀な偶然の出来事によって構成されているかもしれないことを思い出すのに役立つ」(Matzke 2014: http:// www.nimbios.org/press/FS_jump)。
”・・・このモデルと完全なデータセットを用いてベイズ推論を行うスクリプトを提供しており、哺乳類の祖先が桿体を持っていた可能性は50/50であることがわかった”(Ho¨hna er al)。
”stylasterid corals originated in deep waters is strongly supported by maximum-likelihood character state reconstructions” (Lindner er al 2008: 2)という仮説がある。
”・・・複数の分類群が深海から浅海に分散したことが知られており、その中にはスタイラスターイドコーラルも含まれている(Lindner er al 2008)” (Syme and Oakley 2012: 315)。
ビッグデータと複雑なモデルの出現により、これらの主張ははるかに推測に基づいたものになっている。
ニュージーランドとマダガスカルの古人類(Moas & Kiwis)の起源については、ネズミ科の鳥類のMRCA(Most Recent Common Ancestor)をはるかに超える飛翔能力を保持していることで、もっともらしい説明ができる」(Phillips er al 2009: 104)。
主張が物議を醸せば醸すほど、すぐに反論されてしまう。同じ号の『Molecular Phylogenetics and Evolution』に掲載された以下の矛盾した記述を考えてみよう。
”6つの核遺伝子を用いてPaedocyprisの系統関係を調べ、Cypriniformesの主要な系統に属する分類群を広く調査した結果、Paedocyprisは単系統のグループであり、すべてのCypriniformesの基本的な姉妹グループであり、以前に認識されていたCyprinidaeの種ではないことが明らかになった[…] Paedocyprisは新しいスーパーファミリー、Paedocypridoidea、およびファミリー、Paedocyprididaeに認識されている” (Mayden and Chen 2010: 152).
”ここで提示された結果に基づき、我々は彼ら[Mayden and Chen 2010]の改訂に同意せず、彼らの提案した変更を受け入れない[…]従って、我々はPaedocyprididae Mayden and Chen (2010)をDanioninaeと同義語にする。.”。(Tang er al 2010: 208)。
この分析と新しい家族名Paedocyprididaeは、反論と同じ号で両方とも却下された(57号、1号)-皮肉なことに、リチャード・メイデンは両方の論文を執筆している。上記の例は、大きな主張とそれに対する反論の時間が反比例していることを示している。
科学メディアにおいても、推測の域を出ない主張は、科学の価値を下げる可能性がある。2009年に「移行期」の化石Darwinius masillae(「Ida」と呼ばれる)が発見され(Franzen er al 2009)「The Link」と題されたプレスリリースに対するメディアの反応を考えてみよう。
”Ancient Human Ancestor ‘Ida’ Discovered” (Live Science, 19 May 2009).
Unveiled ‘Holy Grail’ Fossil gets Celebrity Treatment」(Live Science 2009年5月19日)。
Amid Media Circus, Scientists Doubt ‘Ida’ is Your Ancestor’ (Live Science, 20 May 2009).
歴史科学の分野では、データから外挿するような推測的な主張は、その分野を刺激的で画期的なものに見せることができる。だからこそ、人気があり、数も多いのだと思う。系統学や生物地理学のモデルは、科学者が最も多くの仮定を置く場所である。モデルの入れ替わりが激しいということは、それだけ暗示的なものが多いということである。1990年代以降、生物地理学は、系統学を含む他の多くの分野よりも多くのモデルとそれを実行する方法を生み出していた。上の引用文に示されているように、これらのモデルとそこから派生した推測に基づく主張は、生物地理学の信頼性を失いつつある。すでに生物地理学者たちは、統合された分野、つまり一連の手法の中で選択された限られた数のモデルのみを使用する分野を求めている(Riddle er al 2008; Wen er al 2013)。もっともらしい関連性だけを利用したモデルは、歴史科学が推測的な手法を採用することで進歩しなければならないかのように、あまりにも単純化されているように見えるかもしれない。しかし、推測的な仮定を用いた複雑なモデルは、より非現実的な主張を意味する。いずれにしても、歴史科学者たちは、データに結びついた単純な方法や単純な説明から離れつつある。生物地理学や系統学のモデルの多くは、膨大な量のデータと数学的な複雑さにより、ほとんどの歴史科学者の理解を超えている。私たちは、モデルの多くの関連性を検証する一つの方法として、HSBHCのようなものを使用することを示した。これだけでは十分ではない。HSBHCの使用は、さらなる集中的な調査の先駆けとなるものである。データ、そのデータを解釈するための仮定、そしてそれらがサポートしていると主張する因果プロセスの間の関連性を理解するための慎重なアプローチがなければ、歴史科学は統計的ブラックボックス、”garbage in, garbage out”アプローチに屈する危険性があり、推測される仮定がどこで研究に違いをもたらしているかを理解することさえできない。