
www.ncbi.nlm.nih.gov/labs/pmc/articles/PMC6548726/
オンラインで2019年5月22日公開
ルイス・G・ハルシー(Lewis G. Halsey)
概要
p値は長い間、生物学における統計解析の頭文字をとってきたが、その地位は脅かされている。pは現在、データについてかなり限定的な情報しか提供せず、誤解を招きやすいことが広く認識されている。多くの生物学者はpの弱点を認識しているが、それに対応してデータの分析方法をどのように変えればよいかについてはあまり明確ではない。
この記事では、p値を補強したり置き換えたりする、比較的簡単に適用できる4つの広範な統計的アプローチを紹介し、要約する。まず、p値にどの程度の自信があるか、再現試験で同様のp値が得られる可能性はどの程度か、統計的に有意な所見が実際には偽陽性である確率はどの程度か、といった情報でp値を補強することができる。
第二に、効果量に焦点を当て、その効果量が正確であることを定量的に確信することで、頻度論的統計が提供する情報を強化することができる。
第3に、帰無仮説と対立仮説の証拠の相対的なレベルについて情報を提供するために、p値をベイズ係数で補強または代替することができる。
このアプローチは、仮説に対する明確な証拠が得られるまでデータの収集を続けたい研究に特に適している。最後に、複数の変数を用いてモデルを構築して結果を予測する場合には、赤池情報量規準がp値の代わりとなり、どのモデルが最適かという定量的な情報を提供することができる。
願わくば、この簡単で強力な統計的オプションのガイドが、p値だけではデータを正当に評価できないと感じている生物学者が新しいアプローチを採用する際の助けになればと思う。
キーワード:AIC、ベイズ、信頼区間、効果量、統計解析
1. 序論
統計解析におけるp値の地位は、統計学者や他の科学者からの批判にもかかわらず、何十年もの間、揺るぎないものとなってた(例:[1-4])。しかし,近年,p値に対するこれまでの議論を覆したり,新たな批判を提起したりする論文が相次いで発表され,不安が高まっている(例:[5-11])。科学の再現性の危機においてp値が果たした役割に刺激されて、この批判はpの支配に対する反乱の瀬戸際まで来ている。
その結果、分析のパワーバキュームが形成され、様々な代替アプローチがそのスペースを埋めようとしている。p値を批判する論説では、統計解析の代替パラダイムを提案することが多いのだが、今や生物学の分野でもいくつかの選択肢が生まれている。新しい統計手法は、通常、p値に基づいた訓練とは逆の概念を含んでいる。それらは、データを調べるための根本的に異なる方法を表しており、証拠を生み出すための異なるアプローチ、異なるソフトウェアパッケージ、理解し正当化するための多くの新しい仮定を含んでいる。新しい手法を学ぶための急なカーブは、生物科学におけるp中心の統計解析に代わるこれらの手法の使用をさらに拡大することを妨げる可能性がある。
分析手法の拡大と多様化を目指す生物学者に明確な自信を与えるために、この記事では、p値中心の統計分析に代わるいくつかの扱いやすい手法をまとめている。その前に、p値の限界と、なぜそれだけでは苦労して得たデータを解釈するのに十分ではないのかについて、簡単に説明する。他の多くの著名な統計学者とともに、Jacob CohenとJohn Tukeyは、帰無仮説の有意性検定の基本的な概念に対する懸念を明確に述べている。p値は帰無仮説が真であることを前提としているため、我々が通常最も関心を持つ対立仮説についての情報を与えない。さらにこの問題は,p値が高く,帰無仮説を棄却しない場合,帰無仮説が真であると解釈することはできず,むしろ「未解決の評決」が残ることになる[2]。さらに,十分に大きなサンプルサイズがあれば,必然的に帰無仮説が棄却される。逆に言えば,p値に基づく統計結果は,仮説に関する情報と同様に,サンプルに関する情報でもあるのである[12,13]。
最近では、p値を実験の再現性の問題に結びつけることで、pに関するさらなる懸念が文書化された[5]。Cumming [7]とHalseyら[6]は,pは統計的検出力が高くても複製間で大きく変化する「気まぐれ」であることを示し,このことがpが極端に小さくない限り,p値の解釈を不可能にしていると主張した。Colquhoun [8,14]は,0.05以下の有意なp値は、帰無仮説に対する極めて弱い証拠であると主張している。なぜなら、有意な結果が偽陽性である可能性は3分の1だからである(別名、タイプ1エラー)。p値を「有意」か「有意でない」かの二分法で解釈することは、多くの理由で特にひどいことであるが、ここで最も重要なのは、このアプローチが失敗した実験の再現を助長するということである。研究は多くの場合、80%の統計的検出力を持つように設計されている。これは、データ中の効果が検出される確率が80%であることを意味する。Wasserstein & Lazar [9]の説明によると、80%の検出力を持つ2つの同一の研究がともにp ≤ 0.05を示す確率はせいぜい80% × 80% = 64%であり、一方がp ≤ 0.05を示し、他方が示さない確率は2 × 80% × 20% = 32%である。これらの論文や計算結果を総合すると,p値は帰無仮説に対する証拠の量としては一般的に非常に不正確であり,したがってpは研究対象となっている現象についてのゆるやかな第一段階の証拠を提供しているにすぎないと考えるべきであることがわかる[6,15,16]。
生物学者の間では,p値はデータに関する暫定的な証拠にすぎず,実際,この証拠が何を物語っているのかは誤解しやすいという認識が広まっているため,p値を明確にする,あるいはp値に取って代わることができる統計的な選択肢を広く理解することが重要だ。有意か無意かのプリズムを通してすべての統計分析を解釈するという教え込まれたアプローチから抜け出すのは難しいだろうが、データを調査するための他の方法、実際にはもっと直感的な方法があるという知識を得ることで、やる気を出すことができる。以下では、標準的な研究デザインを行っている生物学者が現在利用できる、シンプルで強力な統計的オプションについて、簡単に説明する。それぞれの統計的アプローチは、異なるレンズを使ってデータを調査する。つまり、根本的に異なる科学的疑問を投げかける。まずは、p値のパラダイムに最も影響を与えないオプション、すなわちpにその変動性に関する情報を付加することから始める。
2. p値:帰無仮説に対してどれだけの証拠があるか?
pは、データについての直感的でない情報を提供する。しかし、おそらくそれは、帰無仮説に対するデータの証拠を特徴づけるものと解釈するのが最も良いだろう[10,17]。そして、その限界にもかかわらず、p値には魅力的な性質がある。p値は、データを客観的に解釈することができる単一の数値である。さらに、間違いなくその解釈は文脈に依存しない。p値は、異なる種類の研究や統計的検定の間で比較することができる[18](ただし、[10]を参照)。Huber[19]は、p値に注目することは、遺伝子発現解析やゲノムワイド関連解析などの「ハイスループット生物学」で起こるような、複数の仮説のスクリーニングのための最初のステップとして適していると主張している。
しかし、p値は研究サンプル間でかなりのばらつきがあるため、そのばらつきは、p値を小数点以下数桁の単一の値として報告することで誤魔化されている。もし、単一の検定の分析の一部としてpを計算し続けたいのであれば、この統計の不確実性について読者に知らせるために、この変動性についての追加情報を提供すべきであると言えるだろう。これを実現する1つの方法は、効果量の信頼区間に似た値を提供することで、これは研究のp値の不確実性を特徴づけるもので、p値の予測区間と呼ばれている[7]。もう一つの選択肢は、将来の再現試験のp値の不確実性を特徴づける予測区間を計算することである。Lazzeroniら[18]は、両方のための簡単なオンライン計算機を提供している[18]。この計算機によると、例えば実験のp値が0.01の場合、95%の予測区間は5.7~6~0.54となる。明らかに、この実験シナリオでは、pが再現可能であるという確信が持てない。p値が0.0001の場合、95%予測区間は0-0.05となる。この2つ目のシナリオでは、将来の再現実験の95%予測区間は0-0.26となる。Vsevolozhskayaら[20]は、この方法で計算されたp周辺の予測区間は、下限と上限の両方で過小評価を返すと主張している。それにもかかわらず、どのように計算しても、予測区間の幅は、p値を非常に正確に報告された裸の単一の値として見ることに慣れている我々にとっては、驚くほど大きくなる。
研究の計画的な検出力を計算し、帰無仮説が真であると実験を行う前に信じていたレベルを定量化する準備ができていれば、有意なp値を得た場合に帰無仮説を誤って棄却していると推定される可能性でpを補強することができる。これは推定偽陽性(発見)リスクと呼ばれ、単純なベイズの枠組み(後述)から簡単に推定することができる([9]および[9]に添付されたAltmanのコメント)。
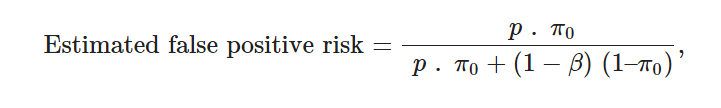
ここで、pは研究のp値、π0は事前の証拠に基づいて帰無仮説が真である確率、(1 – β)は研究の検出力である。
例えば、研究の検出力を80%に設定し、研究を実施する前に、摂動が効果をもたらす可能性は30%であると考え(したがって、π0 = 0.7)研究を実施した後、分析によってp = 0.05が得られた場合、推定偽陽性リスクは13%となる。つまり、この実験の多くの複製は、摂動の統計的に有意な効果を示するが、約13%の確率でそうすることに誤りがあるということである。しかし、前述のpの気まぐれさを考えると、この偽陽性リスクの推定値も同様に気まぐれになる可能性があることを覚えておくこと。この懸念は、スループットの高い研究の場合、上記の式のpをα(統計的検定の有意性の閾値)に置き換え、観察されたp値からπ0を推定することで回避することができる[9,21]。
ハイスループット研究を行っていない人や、実験的摂動の信憑性に関する先験的な期待値を主観的に定量化することを好まない人のために、計算を反転させて、有意なp値が偽陽性である特定のリスク(例えば5%)を生むために必要な事前期待値の計算をp値に付随させることができる([8];著者はこの目的のために使いやすいウェブ計算機を提供している: …fpr-calc.ucl.ac.uk/)。これは、有意なp-値が真の陽性である可能性を評価する別の方法を提供する。例えば、約70%の検出力�
3. 効果量と信頼区間:どの程度、どの程度正確か?
統計的に有意な結果は、我々が研究している現象について、ほとんど何も教えてくれない。データに「効果」がないという帰無仮説(これは、ある程度の精度で真実ではないことがすでにわかってた;[13])が棄却されたことだけである[22]。効果があるのかないのか」というp値の科学的な質問の代わりに、「母集団の効果の強さの推定値としてその値がどのくらい正確か」という質問と合わせて「サンプルでの効果はどのくらい強いか」と質問することで、かなり多くの情報が得られる。
これらの2つの質問に答えるためにデータを分析する最も簡単な方法は、サンプルの効果量とその推定値の95%信頼区間を計算することである[6,7,23-26]。幸いなことに、効果量は一般的に2群間の平均差や2つの変数間の相関の強さであるため、容易に計算したり、統計的出力から抽出することができる。また、信頼区間の定義は複雑だが、Cumming & Calin-Jageman [27]は、信頼区間を効果量の推定値の精度を示すものとして解釈するのが妥当であると説得力のある議論を展開している。
信頼区間とp値の計算は、同じ数学的枠組みを共有しているが[28,29]、このことは、効果量とその信頼区間にデータの解釈を集中させることが、帰無仮説を棄却するかどうかに解釈を集中させることとは根本的に異なるアプローチであるという事実を損なうものではない[11]。この2つの手順は、データに対して非常に異なる質問をし、異なる答えを導き出する[30]。例えば、ゾウリムシの直径に対する2つの異なる環境温度の影響についての研究では、効果量が20μm、p値が0.1であった。p値に基づいて解釈すると、最も支持された効果量は0ではなく20であるにもかかわらず、温度の「効果なし」と結論付けてしまう。効果量と信頼区間に基づいた解釈では、例えば次のようになる。我々の結果は、低温で飼育されているゾウリムシのサイズが平均して20µm大きいことを示唆しているが、-4~50µmのサイズの違いがあることも合理的に考えられる」。Amrhein er al)。 [11]が指摘するように、後者のアプローチは、推定された効果の大きさの不確実性を認めると同時に、p > 0.05の場合に効果がないという誤った主張や、過度に自信のある主張をしないことを保証する。また、信頼区間内のすべての値が生物学的に重要でない場合は、結果が重要な効果を示さないという声明を出すこともできる[11]。(これは、効果量と不確実性に着目することで、必要に応じてイエス/ノーの明確な解釈が可能になる例である。[31]も参照してほしい)。
効果量の推定に重点を置くアプローチは、通常、データの評価を支援するためにデータの視覚化に重点を置いている。これを達成するための強力なグラフ形式には、生データを示すメインパネルと、推定された効果量を説明するのに役立つサイドパネルが含まれる[32]。プロットの例(図S1)については、電子 このようなプロットは、直感的ではあるが、一般的に統計パッケージには含まれておらず、プログラミング言語でコーディングするのも容易ではない。しかし、Hoら[32]は最近、「ブートストラップ結合ESTimationによるデータ解析」(DABEST)を開発した。このソフトは、Matlab、Python、R用のバージョンがあり、またウェブページ(https://www.estimationstats.com/#/)でも利用できる。どのバージョンも、データを完全に解析できるグラフを作成するための、使いやすい暗記用の手順が用意されている。
科学的な研究は「答え」を見つけることを目的としており、推定された効果量とその信頼区間はこの目的の中心となる。少なくとも生物学においては、答えを見つけようとすると、必然的に複数の研究が必要となり、それらをまとめて分析するメタアナリシスが必要となる。効果量と信頼区間は、このプロセスに不可欠な情報であり(例えば[33])論文での徹底した報告が必要であることを示すもう一つの論拠となっている。一般的に,メタアナリシスから算出された効果量の信頼区間は,個々の研究の信頼区間よりもはるかに小さく[34],したがって,真の母集団レベルの効果量についてはるかに明確な画像が得られる(図1)。しかし,メタアナリシスは,研究者が提出しなかったり,ジャーナルが受け入れなかったりして,有意ではない結果が公表されない「ファイルドロワー現象」によって,大きく損なわれる可能性がある[36].幸いなことに,重要でない結果を報告することの価値と重要性について,科学助成機関,出版社,研究者の態度が変わり始めているが,この機運を継続する必要がある.
図1 大腸感染症に対する抗生物質の予防を、無治療の対照と比較した研究の標準および累積メタアナリシス
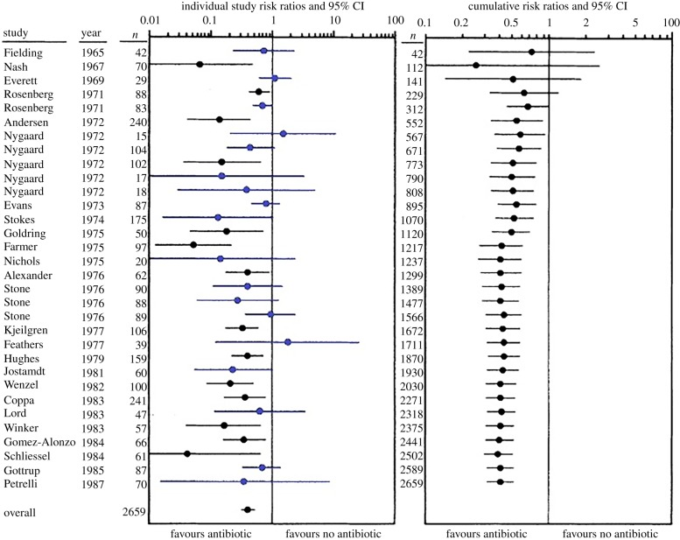
左側のパネルには、各研究の効果サイズと95%信頼区間が示されており、時系列で表示されている。リスク比(effect size)が1より小さい場合は予防薬が有効で、1より大きい場合は無治療が有効であることを示している。すべての研究から得られたプールされた結果が下部に表示されている。信頼区間が1と交差する研究(青色)は、統計的に有意ではない(予防薬の効果がない)と解釈され、そうでない(黒色)は、統計的に有意である(予防薬は投与する価値がある)と解釈されることに注意してほしい。これらの研究をp値だけで解釈すると、統計的有意性を報告した研究の約半数が大腸感染症治療における抗生物質の予防投与の価値を明らかにすることはできない。右図は、同じ研究の累積メタアナリシスである(nは累積サンプルサイズ)。これによると、結腸感染症の治療における抗生物質の予防投与の有効性は、1972年という早い時期にある程度確認されていた可能性があり、有効性の効果の大きさは、最終的な研究のかなり前に明確になってた。図(適応)および一部の説明文はIoannidis & Lau [35]から引用している。
4. ベイズ因子:ある仮説の証拠は他の仮説と比べてどうなのか?
p値が帰無仮説が真である可能性についての情報のみを提供するのとは対照的に,ベイズ因子は帰無仮説と対立仮説の両方を直接扱う。ベイズ因子は、データが帰無仮説と対立仮説のどちらで予測されるかについて、収集したデータの相対的な証拠を定量化するものである(大きさを示す効果)。例えば,ベイズ因子が5であれば,帰無仮説よりも対立仮説の方が証拠の強さが5倍大きいことを示し,ベイズ因子が1/5であれば,その逆であることを示す.
ベイズ因子は、ベイズ版の帰無仮説の有意性検定を行うための、シンプルで直感的な方法である。ベイズ因子が実際の生物学者にとって扱いやすいものになったのはごく最近のことで,現在では標準的な研究デザインの範囲で簡単に計算できるようになっている。多くのデザインのベイズ因子はウェブベースの計算機(例:http://pcl.missouri.edu/bayesfactor)で実行でき、BayesFactor() [38]というRの新しいパッケージとしても利用可能である。
ベイズアプローチの論争点は、実験が行われる前に研究されている効果に対するあなたの信念の強さ(対立仮説の事前分布)を指定する必要があることである[39]。したがって,「事前」のやや主観的な選択が分析の結果に影響する。Schönbrodtら[40]は、合理的な事前分布が使用されている場合、事前の影響は制限されているので、ベイズ統計に対するこの批判はしばしば誇張されていると主張している。現実的な事前確率の限定された範囲を使って分析を実行することにより、簡単な感度分析で事前の影響を評価することができる[41]。また、期待される効果の大きさに関する研究前の証拠がほとんどないという一般的な状況で使用できるデフォルトの事前分布もある。
とはいえ,ベイズ分析は帰無仮説の有意性検定よりも複雑で,事前確率の指定にはある程度の主観性が含まれることは間違いない。幸いなことに、他の情報がなくても、p値をベイズ因子の形式に変換するために適用できる、単一の単純な公式がある。この単純化されたベイズ因子は上界と呼ばれ,任意の合理的な事前分布において帰無仮説ではなく対立仮説が真である可能性が最も高いことを示している(BenjaminとBergerのコメントが[9]とGoodman[42]に添付されている)。
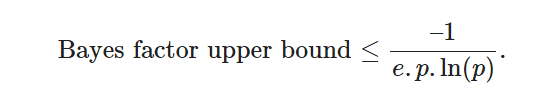
例えば、p値が0.07(「トレンド」と呼ばれることもある)のデータの場合、ベイズ因子上界は1.98であり、対立仮説は帰無仮説の最大2倍の可能性があると結論づけることができる。p値が0.01であれば、対立仮説が帰無仮説の最大8倍の可能性があることを示す。BenjaminとBergerは、このアプローチは、pに代わる解釈しやすいアプローチであり、ベイズ統計学の実践者と帰無仮説の有意性検定の実践者の両方を満足させるものであると主張している(BenjaminとBergerのコメントは[9]に付記)。
Schönbrodtら[40]は、ベイズ因子は、研究が十分なサンプルサイズを確保し、中止することができるときに通知するために使用することができると主張している。研究における効果的な停止ルールは、研究の再現性を高めつつ、時間的・金銭的コストをコントロールする上で非常に重要であり、特定の動物実験や侵入的なヒトの研究においては倫理的に重要である。被験者の使用を最小限に抑えつつ、実験の堅牢性と再現性を確保する必要がある(https://www.nc3rs.org.uk/the-3rs; [43])。議論の余地はあるが、停止ルールは現在よりもずっと多く使用されるべきであり、検出力分析よりも適切なサンプルサイズを目標とするためのはるかに効果的な方法である。しかし、よくある大きな間違いは、停止ルールにp値を導入することである。これまでに収集したデータから統計的に有意なp値が得られた場合に研究を停止する。これは、サンプルサイズをさらに大きくすれば、pもさらに小さくなるだろうという仮定に基づいている。単純なモデルでは、この考え方が誤ったものであることを示しており、したがって、非常に悪い習慣を助長している(図2)。p値に基づいて研究を行っている人にとっては、先験的な検出力分析によって決定されたサンプルサイズに達するまで研究を継続することがはるかに好ましい[45]。しかし、このアプローチは、我々が提供した関連する先験的な効果量の推定値に大きく影響され、事前に決定した数を超えてサンプルサイズを増やすという強い誘惑に陥る可能性がある。
図2 研究のデータを収集し、サンプルを新たに追加するたびに分析した場合のp値の変動を示したもの
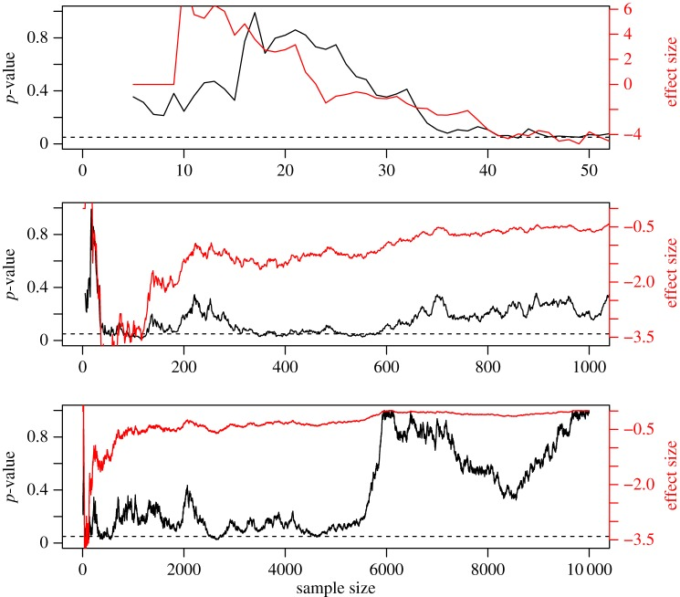
このため、有意なp値が得られるとすぐに実際の効果を反映していると勘違いして、研究を中止してしまうことがある。コンピュータは,2つの同一の無作為に分布した母集団(標準偏差=10)から無作為に抽出された標本をシミュレートするので,帰無仮説は真である.2つの母集団から5つのサンプルを抽出した後,Student’s t-testを行う.その後、各母集団からさらに1つのサンプルを採取するたびに、t-検定が再実行される。上段は最初の50サンプル、中段は最初の1,000サンプル、下段は10,000サンプルを抽出したときのp値の変化を、3つのパネル(黒線)で示している。p値はかなり変化しているが,これもp値の「気まぐれさ」を示している[6].各パネルの赤い線は,効果量(サンプル間の平均差)を表している.このような状況では,帰無に対する証拠がないことを反映して,p値は通常,高くなるはずですが,サンプルサイズが小さい場合,一時的に0.05(破線で示す)以下に容易に低下し,サンプルが抽出された集団が異なることを示唆します.このときにサンプリングを中止すると,pは現実を代表していないことになり,偽陽性を返すことになる。(このシミュレーションでは,サンプルサイズが非常に大きくなってもpは0にならないことに注意してほしい。なぜなら,サンプルサイズが大きくなると効果量は0になる傾向があり,したがって統計的検出力は系統的に増加しないからである(観測された検出力はpに反比例する;[44])。
ここでは、ベイズ因子の方がはるかに適切である。これは帰無性の証拠を提供し、十分に大きなサンプルではベイズ因子は0(帰無性が真)または無限大(代替案が真)に収束する。データのベイズ因子が10または1/10に達した場合、これはほぼ確実に真の状況を表しており、研究を中止することができる。例えば、ベイズ因子が1/7であれば、帰無仮説に対する中程度の証拠を示すことになる。さらに、データが十分に決定的でないと感じた場合には、サンプリングを継続する権利がある。このような決定はすべて、ベイズ因子の解釈には影響しない[40]。停止手順にp値ではなくベイズ因子を採用する最後の大きな動機は、長期的には、ベイズ因子の方がより少ないサンプルを使用すると同時に、解釈ミスの発生が少ないということである。それぞれの状況に最も適したプライヤーについては、まだ一般的なコンセンサスが得られておらず、扱いやすいベイズ因子の手順は、今のところいくつかの実験計画に対してのみ作成されている。しかし、これで安心してはいけない。ベイズ因子の代わりに、上述のベイズ因子上界を用いることができる。
5. 赤池情報量規準:研究対象の現象に対する最良の理解は何か?
研究が結果変数と複数の潜在的な説明変数の測定を含む場合、データの分散を説明するために構築できる多くの可能なモデルがある。モデル構築のステップワイズ手順では、低いpに関連する説明変数のみを保持することで、p値に焦点を当てることがよくある。pに関する一般的な懸念は別として、p値に基づいたモデル構築の具体的な批判には、タイプ1エラーのリスクが高まることが含まれる[47,48]。モデル評価の別のアプローチとして、赤池情報量規準(AIC)がある。AICは、統計ソフトウェアパッケージで簡単に計算でき、RではAIC()を使って計算できる[49]。AICは、モデルが現実をどれだけ忠実に表現しているか [50]、言い換えればその予測精度 [51]の推定値を提供する。AICの基本的な側面は、単純性と単純性の原則に基づいて、モデルの適合性とモデルの複雑さをトレードオフして、オーバーフィットを防ぐことである[52]。
例えば、AICが443(モデル1)445(モデル2)448(モデル3)の3つのモデルを作成したとする。相対的な品質の観点からあなたが好むモデルは、最小のAICを返すモデルだろう。しかし、他のモデルを必ずしも捨て去るべきではない。複数のモデルについて計算されたAICを使えば、データが与えられたときに、それらのモデルのそれぞれが提示されたすべてのモデルの中で最良であるという相対的な可能性、すなわち、それぞれのモデルに対する相対的な証拠を簡単に計算することができる。例えば、好ましいモデルの相対的な証拠は常に1で、今回の例では、2番目に良いモデルであるモデル2の相対的な証拠は0.37,モデル3は0.08である。最後に、任意のペアのモデル間の証拠比率を計算することができる。上記の例では、モデル2に対するモデル1の証拠は1/0.37=2.7,つまりモデル1の証拠は2.7倍強いということになる。このシナリオでは、モデル1が絶対的に最も低いAICを持っているが、生成されたものの中でモデル2ではなくモデル1が最適であるという証拠は強くなく、いくつかの説明変数がモデルの1つにしか存在しない場合、最も適切な対応は、両方のモデルに基づいて推論を行うことである[50]。AICアプローチは、pが小さければ帰無を棄却し、デフォルトで対立仮説を支持することを推奨するp値解釈とは対照的に、代替モデル、ひいては仮説について真剣に考えることを促する[53]。より広く言えば,AICパラダイムでは,ありえないと判断された仮説を削除し,残りの仮説を改良し,新しい仮説を追加することになり,Burnhamら[50]は,研究されている現象について迅速かつ深い学習を促進する科学的戦略であると主張している.
AICは数学的にはp値と関連しているが(これらは尤度比の異なる変換です;[29])前者の方が比較できるモデルの柔軟性がはるかに高くなっている。AICは、データを説明するために作成した複数のモデルの中から選択するための強力なオプションである。つまり、観測されたデータが複雑でよく理解されておらず、モデルが特に強力な予測力を持つとは期待していない場合に、測定した現象に対する最善の理解を表すモデルを選択することができる[54]。
AICの主な限界は、モデルの品質を絶対的ではなく相対的に評価することである。最良のモデルがデータに対しても良いモデルであると仮定する罠に陥りがちだが、実際にはそうであるかもしれないし、逆に最良のモデルがデータの分散を半分しか見ていない一方で、他の全てのモデルにはそれが見えていないかもしれない。最適なモデルの絶対的な質を定量化するには、前述のように効果量を計算する必要がある(モデルの場合は、通常R2が適している)。
6. 結論
優れた科学は、解釈に適した堅牢なデータを生み出す。データの統計的分析にはいくつかの幅広いアプローチがあり、それぞれが収集された変数に対して明確な疑問を投げかける。Popper[55]は、科学とは理論を改竄することであると主張した。科学に対するこのアプローチをとると、p値は帰無仮説に対する証拠を提供するので、統計分析の正当な中心となるかもしれない[10,17]。このパラダイムに基づき、pに予測区間や偽陽性リスクの推定値(pの信頼性に関する情報)を付加することで、p値の解釈を容易に高めることができる。しかし、p値は帰無仮説も対立仮説も検定していないので、実際に理論を反証するために使用することはできないという反論がある[56]。p値をベイズ係数に変換することで、この懸念を払拭し、一方の仮説に対する相対的な証拠を提供することができる。しかし、どのようなアプローチによる仮説検証も、データ中の効果、特にその大きさと正確さに注目することに取って代わられると多くの人が主張している。なぜなら、研究している現象の大きさの最良の推定値が最終的に知りたいことだからである。また、多変量解析を行う場合、特に研究対象の現象が十分に理解されていない場合には、複数の仮説を検討し、それらを徐々に改良していくことを奨励するAICが有効である。
これらの多様なアプローチがすべて相互に排他的ではないことを強調することが重要だ。例えば、多くの人は効果量推定値がほとんどの分析に不可欠な要素であると主張するだろう。実際、Goodmanら[57]は、帰無仮説を棄却するためには、低いp値と先験的に決定された最小値以上の効果量が関連性/重要であることを必要とする意思決定のためのハイブリッドの使用を推奨している。他の統計的アプローチを含めることでその解釈力を薄めながらも、統計的出力の一部としてp値を提示し続けることで、投稿が危険にさらされることはない。実際、このアプローチは、査読者や編集者が代替的な推論パラダイムの適用を受け入れ、さらには奨励するように促すための最良の方法だろう([43]のBox 2を参照)。どのような統計的手法を選択するにしても、データ収集の前に決定しておくことが重要だ。より多くの統計的選択肢を持つことで、刺激的な結果が得られるまで様々なアプローチを試す誘惑に駆られる可能性があるが、これには抵抗がある。
データのパターンを調査するためにどのような統計的パラダイムを採用するかにかかわらず、統計的検定からの出力は常に二次的な質問と考えるべきだと多くの人が推奨している。主に、可能であればデータのグラフプロットの解釈を優先し、統計分析は裏付けや確認のための情報として扱うべきであるという主張である[25,58-60]。統計解析の結果をサポートしていないように見えるプロットがあっても、それは解析によって可視化できないほど深いパターンが発見されたことを示すものとして、自動的に説明されるべきではない。
最後に、このレビューが、読者がp値に対する追加的・代替的な統計的選択肢について、少しでも情報を得て自信を持つ助けになればと思うが、ロナルド・フィッシャー卿が1938年の第1回インド統計会議で行った大統領演説の中で述べた適切な言葉を思い出す価値がある[61]:「実験が終わってから統計学者を呼ぶのは、死後の検査をしてもらうのと同じことかもしれない。良いデータセットがなければ、ここで述べたような統計ツールはどれも有効ではない。さらに、優れたデータセットであっても、1つの研究に過ぎず、1つの研究から得られる情報は限られていることを忘れてはならない。最終的には、生物学的世界の理解を深め、自信を持つためには、再現が鍵となる。」