
Contents
SHOULD THE RANDOMISTAS (CONTINUE TO) RULE?
マーティン・ラバリオン
ナショナル・ビューロー・オブ・エコノミック・リサーチ
マサチューセッツ・アベニュー1050
ケンブリッジ, MA 02138
2020年7月
概要
開発アプリケーションにおける無作為化比較試験(RCT)の人気上昇に伴い、このアプローチのメリットについての議論が続いている。この論文では、これらの問題を取り上げている。RCTを無条件に優先することは、主に3つの点で疑問があると主張している。
第一に、そのような優先順位のケースは、先験的な理由では不明確である。例えば、予算があるなら偏った観察研究であっても、コストのかかるRCTよりも真実に近づけることができる。
第二に、RCTに対する倫理的な反論は、提唱者によって適切に対処されていない。
第三に、RCTにこだわると、評価対象に選択バイアスがかかるため、政策決定に必要なエビデンスベースが歪んでしまう危険性がある。
今後は、一部の研究者の方法論的な好みではなく、差し迫った知識のギャップによって、質問とその回答方法を決定すべきである。ゴールドスタンダードとは、目の前の問題に最適な方法のことである。
1. はじめに
新世紀に入り、政策立案の改善を目的としたインパクト評価の途上国への適用が大幅に増加している。International Initiative for Impact Evaluation (3ie)は、このような評価のメタデータをまとめており、図1に示している2。2000年以降、発表された影響評価の年間件数は 2000年以前の19年間と比較して、30倍に増加していることがわかる3。
図1:開発途上国で発表されたインパクト評価の年間件数
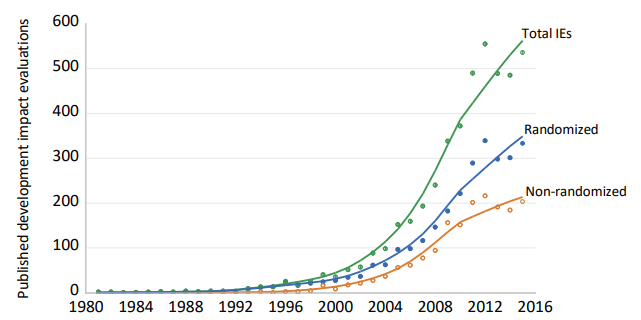
発表された開発インパクト評価
注:フィッテッドラインは最近接平滑化散布図。2000年以前の非ランダム化評価は過小評価されている可能性があるため、本文の脚注4を参照。一次データの出典。International Initiative for Impact Evaluation.
1つ目の方法は、あるプログラムへのアクセス(「治療」)をあるユニットに無作為に割り当て、他のユニットは対照として無作為に確保する。プログラムの効果を測定するために、この2つのサンプルの平均成果を比較する。これが無作為化比較試験(RCT)の最も単純なバージョンである。もう一つの方法は、無作為化を行わない方法である。これには、純粋に「観察研究」が含まれ、治療の割り当てがデータとして取られ、無作為ではなく意図的であると理解されている。第2のグループには、治療から得られるであろう利益に関する事前予測に基づくような、決定論的な割り当ても含まれる。政策決定に役立つ非RCTの中には、純粋に記述的なものもあれば、影響に関する信頼できる因果推論を引き出すことを目的として、データで観察可能なものに基づいて、治療前の治療ユニットと非治療ユニットの間の差異をコントロールしようとするものもある。
開発アプリケーションにおけるRCTの使用は1980年頃から始まったが、その約20年後にRCTの使用が急速に拡大した。2000年以降のインパクト評価の約60%が無作為化を用いている。最新の3ieカウントでは 2015年にこのツールを使用した論文は333本となっている5。この成長率は目を見張るものがある。図1のRCTの数に指数関数的な傾向を当てはめると(当てはまりは良好である)年間成長率は約20%となり、これは第二次世界大戦後の科学出版全体の成長率の2倍以上である6。
図1で明らかなように、RCTの増加の多くがRCTであるという事実は 2000年以前には予想できなかったであろう。政府などが開発の名のもとに行うことの多くは、RCTでは実現不可能だからである。また、研究のために、必要な人にはプログラムを提供せず、そうでない人にはプログラムを提供することへの懸念がよく聞かれることから、RCTは歴史的に人気がなかった。開発のためのRCTは、かつてはハードルが高かったのである。何かが変わったのである。なぜRCTはそんなに人気があるのであろうか?また、その人気は正当なものなのであろうか?
RCTを支持する人たちは「RCT主義者」(randomistas)と呼ばれている7 。彼らはRCTをインパクト評価の「ゴールドスタンダード」、つまり最も「科学的」または「厳密」なアプローチとして提唱し、ほとんど理論性がなく仮定のない、しかし信頼性の高い影響評価を提供することを約束している8 。この見解は著名な学術経済学者から出たもので、一般的な言説にも浸透しており、メディア、開発機関、ドナー、そして研究者とその雇用者の間で明らかな影響力を持っている9 。影響評価には多くの文脈(介入の種類、経済のセクター、国、コミュニティ、社会・民族グループ)があるが、ゴールドスタンダードの主張は通常、文脈とは無関係に行われる。
反発もあった。批評家たちは、特に次のような点を主張していた。RCTを用いた信頼性の高いインパクト推定に必要な仮定が、現実には成り立たないこと、RCTは倫理的に問題があること、RCTの「ブラックボックス」的な性質が、スケールアップや他の文脈で起こりうるインパクトについての学習を含む政策立案への有用性を制限していることなどである。また、あるコメンテーターはRCTに対する倫理的な批判を「ゴミ」と切り捨て(Fiennes, 2018)ある評論家はRCT革命を「狂気」(実際、ある時点では「狂気よりもはるかに悪い」)と呼ぶ(Pritchett, 2020, p.26)など、感情的に高まることもあった。
開発RCTの隆盛と継続的な議論を踏まえて、本稿は10年後にRavallion (2009a)で提起された質問、”Should the randomistas rule? “に立ち返る。RCT主義者が「支配」する意味は、彼らが主張する手法の階層にあり、それが彼らの知的権威と説得力の基盤となっている12。この論文では、目的によってはRCTの魅力を認める一方で、RCTを支持する公衆の声は、この研究ツールの限界を十分に理解した上でのものではないことを論じている。この論文の読者は、どちらかの専門家ではなく、経済学者やその他の社会科学者、寄付者、政策立案者とそのアドバイザー、学生や若い研究者など、より広いコミュニティを想定している。
本稿では、まず、手法の選択に関連するインパクト評価の理論の概要を説明する(セクション2.2)。続いて、開発研究におけるRCT主義者の影響力(セクション2.3)彼らが選んだ手法の倫理的妥当性に関する懸念(セクション2.4)そして彼らの研究と政策との関連性(セクション2.5)について論じている。2.6節で結論を述べている。
2. 影響評価の基礎
ここでは、明確に定義された集団の中の一部のユニット(「被治療者」)がプログラムを受け、一部のユニットが受けないという、割り当てられたプログラムに焦点を当てる。母集団から無作為に2つのサンプルを抽出し、1つはプログラムを受けた人、もう1つは受けなかった人とし、両者の関連する結果を測定するとする。13 平均的な結果の差が、その集団の真の平均的な影響に関する試験の推定値であり、平均治療効果(ATE)とも呼ばれる。この推定値は、測定誤差、サンプリングのばらつき、2つのグループ間のスピルオーバー効果(「汚染」)モニタリング効果、および/または、アウトカムと治療状況を共同で変化させる交絡変数から生じる系統的なバイアスにより、真の値とは異なる可能性がある。各試験のサンプルペアは異なる推定値を示し、時には高すぎたり低すぎたりするが、真の値を(もちろん)知らないので、どの程度かはわからない。すべての試験には何らかの誤差がある。
理想的なRCTは、上記の設定の特殊なケースで、試験の治療状況もランダムに割り当てられ(治療を受けたものと受けていないものの2つの集団からランダムなサンプルを抽出することに加えて)唯一のエラーはサンプリングのばらつきによるものである。この理想は、実際には、特に人間を対象とした場合には実現しないことがある。理想からの現実的な逸脱については後述するが、ここでは理想的なRCTを想定している。この特別なケースでは、サンプルサイズが大きくなるにつれて、試験の推定値は真の平均的な影響に近づいていく。これが、理想的なRCTが不偏であると言われる意味であり、すなわち、サンプリングエラーが期待値でゼロに追い込まれるということである。この性質を利用して、推定値の分散を推定することもできる。したがって、無作為処理と無作為抽出の両方を使用することで、RCTによる影響推定値の標準誤差を算出し、統計的信頼区間を設定することが容易になる14。
著名なRCT主義者は、「期待して」という修飾語を省いたり、実験誤差の存在に対するその意味を無視したりすることがある(Deaton and Cartwright, 2018が指摘している)。これらのRCT擁護者は、治療サンプルと対照サンプルの間の平均アウトカムの差はすべて介入に起因するとしている15 このよくある間違いは、些細な説明的な簡略化に過ぎないと考えられるかもしれない16 しかし、この簡略化は現在、世間の物語の多くに組み込まれている。専門家はともかく、開発コミュニティの多くの人々は、RCTにおける治療群と対照群の間の測定された差はすべて治療に起因するものだと考えている。「理想的なRCTであっても、未知の実験誤差がある」ということを否定しているからだ。
まれではあるが、参考になるケースとして、治療法がない場合がある。割り当ての他の効果(モニタリングによるものなど)がなければ、影響はゼロである。しかし、1つの試験におけるランダムな誤差は、RCTの平均的な影響をゼロではないものにする。例えば、デンマークで行われたRCTでは、860人の高齢者が無作為に、知らずに治療群と対照群に分けられ、実際の介入は18ヶ月間行われなかった(Vass, 2010)。その結果、期間終了時には死亡率に統計的に有意な差(prob.=0.003)が現れた。
これらの観察結果を踏まえて,方法の選択を考えてみよう。ある予算で、RCTと観察研究のどちらかを実施することができるとする。後者の場合、人々がプログラムを選択し、プログラムに参加した人と参加しなかった人から無作為にサンプルを採取する。私たちは、試験の推定値が真の値にどれだけ近いかによって、事前に方法をランク付けしたいと思う。推定値が真値を中心としたある一定の区間内にあれば、その推定値は「真値に近い」と言えるであろう。ここでは、各推定量の「内的妥当性」、つまり対象となる母集団に対する正確さに焦点を当てており、2.5節では「外的妥当性」について説明する)。
「ゴールドスタンダード」のランキングで最もよく耳にする理由は、理想的なRCTの不偏性である。経済学者は、バイアスの特定の原因、すなわち、パラメータ推定値の数学的期待値とその(未知の)真の値との間の差に多くの関心を寄せていた。すなわち、パラメータ推定値の数学的期待値とその(未知の)真の値との間の差である。(一部の文献では、これを「系統的バイアス」と呼び、潜在的に多数存在する試験固有の誤差の原因とは区別している17)。この狭い定義でも、観察研究が偏っている必要はない。RCTを含め、一般的には共変量の不均衡を調整している。治療状態が条件的に外生的である場合、すなわち共変量に条件付けられた誤差項と相関しない場合、バイアスは取り除かれる(ただし、これはRCTよりも明らかに強い仮定である)。この仮定は、コンテクスト(プログラムと利用可能なデータ)に応じて、受け入れられる場合とそうでない場合がある。対照変数が与えられたときに治療が異質であるかどうかは、それらの変数が治療を受ける決定要因を適切に反映しているかどうかにかかっており、それはそれぞれの設定で判断しなければならない。プログラム配置の経済的・社会的決定要因(特定の状況下で様々な利害関係者が直面する意思決定問題)を十分に理解することが、必要なデータを決定する上で役立つ。除外された交絡因子はしばしば残るが、観察された交絡因子を調整する際に大きな偏りが生じることはない。
測定されていない交絡因子が深刻な問題であるならば、治療を受けた結果の決定要因でもない治療状況の外因性変動の原因を見つけることができれば、バイアスを取り除くことができる。これが(操作変数( instrumental variable)である。有効な操作変数は、治療状況と相関していなければならず、治療とコントロール変数が与えられた場合のアウトカムとは無相関でなければならない。回帰においては、操作変数が誤差項と相関していないことが必要であり、これは 排外制約(exclusion restriction)と呼ばれている。この条件は、最終的には理論的な根拠に基づいて判断しなければならないが、特定の設定における治療状況を決定する要因を綿密に調査することは、潜在的な交絡因子だけでなく、理論的に妥当な操作変数を見つける上でも有益である。例えば、治療への割り当てが、適格性スコアがある重要な閾値を超えているかどうかに依存し、さらに割り当てにファジーさを加える他の要因もあるプログラムを考えてみよう。閾値が恣意的である限り(すなわち、平均的な反事実上の結果が閾値で変化しない限り)スコアがこの臨界値を上回るか下回るかは、理論的に妥当な操作変数である18。経済学者にはあまり馴染みがないが、治療と結果を結びつけるが交絡因子には依存しない中間変数があれば、測定されない交絡因子による観察研究のバイアスも排除できる19。
特定の環境下ではRCTの方がバイアスを取り除くのに優れているということに同意したとしても、それでランキングが決まるわけではない。主な理由は2つある。第一に、RCTを実施する上での制約から、対象となる母集団を適切に表現することができない場合がある。少なくとも、自由なメディアが存在する場合、政府は倫理的に問題のある研究を支援することに政治的なリスクを見出す可能性がある。RCTは政府と一緒に行われることもあるが、より良性の観察研究は受け入れられやすいことが多い。そのため、現地のパートナーを探しているアカデミックな無作為化研究者は、代わりに現地の非政府組織(NGO)と協力することに魅力を感じている。無作為化したいという願望は、(理想的な条件の下では)協力的な地元NGOの集住地域の人々のような、無作為に選択されていない部分集団に対する偏りのない影響推定値をもたらすかもしれない。さらに、準拠サブサンプルの選択プロセスは明確ではないかもしれない(実際、どのように選択されたかについて論文で言及されていない)。対象となる母集団から無作為に選ばれていないサブサンプルに対する不偏的な推定値から何が学べるのかは不明である。影響の不均一性を考慮すると、全人口からの無作為抽出サンプルに対する偏った観察研究の方が真実に近いかもしれない。
第二に、重要なのはバイアスだけではない。推定量を選択するための適切な決定ルール(および、より一般的な研究の設計)は、アプリケーションによって異なる。一般的な統計学の決定ルールは、平均二乗誤差(MSE)を最小化すること、つまり、推定値とその真の値の間の二乗偏差の期待値を最小化することである。統計学ではよく知られているように、MSEは推定量の二乗バイアスにその分散を加えたものである20。したがって、この決定ルールは、不偏の推定量が常に最良であることを教えてくれるものではない21。MSEは唯一の擁護できる決定ルールではない。例えば、試行が真値からある絶対的な距離内にある頻度を問うこともできるが、ここでのポイントは、不偏性がすべてではないということである。
ここでインパクト評価の経済学が効いてくる。サンプルサイズが大きいと、推定値の分散が小さくなる。多くの観察研究では、行政記録(「ビッグデータ」)や既存の調査など、既存のデータを使用する。RCTでは、通常、新しい特別な目的の調査が必要である。
そのため、一定の予算内であれば、RCTの方がサンプルサイズが小さく、分散が大きくなることが多いのである。また、非RCTで新たな調査が必要な場合も、結果は明確ではない。バイアスを減らすためには、より良いデータが必要である。長時間のアンケート調査では、与えられた予算内でサンプルサイズを小さくする必要があるであろう。しかし、RCTのデータ要件が異なるとは考えられず、RCTでは共変量のバランスを検証するためにベースラインデータが必要であることに留意すべきである22。RCTにおける(治療のための)追加的な無作為化はコストがかからないとは考えられず、共変量のバランスを保証するために再無作為化が必要になる可能性が高い(Morgan and Rubin, 2012)。24 世界銀行における評価のコスト比較では、RCTのコストが高いことが示唆されている(比較は粗いが)25 開発RCTでは、観察研究では見られない現場での実施の難しさに直面することがよくある。
このことが手法の選択にどのような意味を持つかを確認するために、各試験が2つの正規分布(RCT用と非RCT用)のいずれかから抽出されると仮定する。パラメータ(その平均と分散)は、選択した方法に依存する。RCTの試験結果の分布の平均は真の平均とみなされるが、non-RCTの場合はそうではない。それでも、バイアスがあるにもかかわらず、非RCTの分散は十分に低く、RCTよりも真実に近い試験の割合が高くなることが保証される。図2は、仮説的なケースを示しており、偏った観察研究であっても(偏っていない)RCTよりも真実に近い結果が得られることを示している26。真のインパクトはゼロであり、これはRCT試験が描画された分布の平均値である。非RCT試験は、平均が-0.5の分布から抽出されており、これが系統的バイアスとなる。もう1つの違いは,RCT試験は分散が2の分布から抽出されるのに対し,観察研究では1であることである。これは,ある予算に対して,非RCT試験では各試験のサンプルサイズを2倍にすることができると解釈できる。
図2:インパクト評価のための2つの仮想的なデザインによる平均インパクトの推定値の密度関数
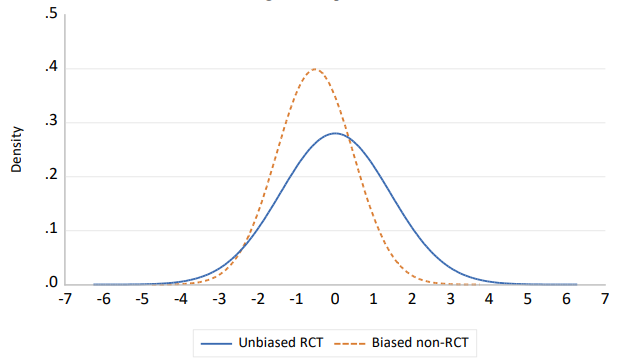
試験の推定値がより真実に近い傾向があるという点で、どちらの方法が優れているであろうか?
定義 図3は、試行法の割合を示している。ここでは、「より真実に近い」とは、区間(-0.5, 0.5)内のインパクト推定値であると定義する。その結果、RCTでは27%の試験でこの区間内の推定値が得られるが、非RCTでは34%の試験でそうなっている。代わりに、「より真実に近い」を区間(-1, 1)内の推定値と定義すると、RCT試験の52%がそうであるのに対し、観察研究では62%がそうである。この例では、すべての試験において、観察研究の方がより真実に近いということになる。
図3:より多くのサンプルでバイアスのかかっていないRCTとバイアスのかかった非RCTを比較して、真実に近いインパクト推定値を出した試験の割合
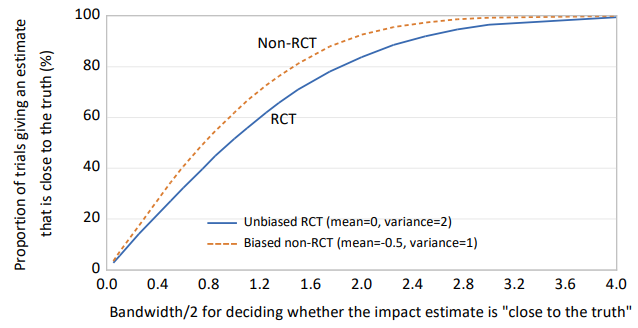
もちろん、これは多くの可能性のうちの1つに過ぎず、RCTの方が優れている例を容易に構築することができる。図2と図3は、偏りの少ないインパクト評価が真実に近づく必要がないことを示しているに過ぎない。これは未解決の問題であり、予算に余裕がある場合の試験の力に大きく依存している。重要な点は、ある予算のもとでは、RCTは信頼性の低い影響評価を行うことになり、偏った観察研究よりも真実から離れてしまう可能性を排除できないということである。私たちには、主張されている(無条件の)「ゴールドスタンダード」と呼ばれる手法の階層を理論的に正当化する理由がない。
RCTを擁護するとすれば、観察研究におけるバイアスの分布については現在ほとんど分かっていないが、(前述のように)RCTの不偏性には推定可能な分散が伴い、信頼区間の計算が容易になる。このことは、観察研究から得られる推定値の分布について、同じ設定でRCTから得られる推定値と比較するなど、より多くの研究が必要であることを示している28。しかしながら、(実行可能な場合は)RCTのみを行うことにこだわると、真実に近いことが多い観察研究を見送ることになるかもしれない。
背景を知ることで、より明確な結果が得られるかもしれない。舞台やプログラムをよく知っていて、関連する交絡因子(プログラムがどのように機能するかのモデル)を特定し、それらに関するデータを収集したり、測定可能な脱交絡因子を見つけたりすることができれば、観察だけで非常に信頼性の高い影響推定値を得ることができるかもしれない。一方で、関連する交絡因子のベースラインデータを収集する余地がほとんどなく、無作為化割り当ての単価がそれほど高くない(利用可能な予算で適度に大きなサンプルサイズが実現可能)場合、RCTは非常に魅力的である。ここで問題になっているのは、広く聞かれている「ゴールドスタンダード」という一般論である。
さらに進んで、真のモデルに関する不確実性を認識しながら、(例えば)MSEを最小化する意味で、どのようなデザインが最適であるかを問うことができる29。少なくとも一部のベースラインデータが連続共変量であり、モデルの不確実性に関するベイズプライアを持っていると仮定しよう。すると、Kasy (2016)の結果、すなわち、期待されるMSEを最小化する共変量に基づく治療状態の決定論的(非ランダム)割り当てが存在することをアピールすることができる30。その場合、共変量を考慮して割り当てをランダム化することによる利益はない(RCTにおいて観測値を考慮することによる効率的な利益はあるであろう)。つまり、RCTを強く好むことを正当化するためには、それ自体が目的である無作為化に何らかの本質的な価値を見出し、真の平均的影響に近づくためには正確性を捨てても構わないと考える必要がある。提唱者たちは、インパクトを推定する際の精度とは無関係に、そのような方法論的な好みに陥ることがある。例えば、(Banerjee et al 2018)は、RCTを好む人々の福祉に十分な重みを置く限り、RCTが依然として優位に立ち得ることを示している。
RCT主義者の影響は、実行可能な場合はRCTが好ましい統計ツールであるという(多くの人に聞かれる)信念に一部起因している。しかし、基礎となる理論を検証した結果、この信念には大きな疑問が生じた。これから見るように、RCT主義者の影響の他の原因も同様に疑わしいものである。
3. 開発研究におけるRCT主義者の影響
社会政策の文脈におけるRCTの使用の初期の例としては、1960年代に始まった米国の社会政策に関する様々な実験がある31。開発アプリケーションに関しては、3ieデータベースに1981年から 1999年の間に発表された133のRCTがある。このデータベースで最も古いRCTは、ニカラグアの学生の数学の成績を向上させるための教育介入(教科書とラジオレッスン)に関する世界銀行の研究プロジェクト、すなわちJamisonら(1981)のものである32。2000年以前のRCTの中では、1997年に始まったProgresa評価のためにメキシコ政府が行ったものが特に注目すべき例である。このRCTのデータから得られた(概ねポジティブな)文献上の結果は、今日の50カ国以上への条件付現金給付の拡大に影響を与えた33。
このように、新しいミレニアムの初めには、開発にRCTを適用するというアイデアに新しいものはなかった。変化したのは、そのアイデアが人気を博したことである。2000年以降、RCTの年間生産量ははるかに増えている(図1)。数多くの個人の学者やグループが貢献していたが、中でも際立っているのがAbdul Latif Jameel Poverty Action Lab(J-PAL)である34。これは2003年に設立され(Poverty Action Labとして)マサチューセッツ工科大学(MIT)の経済学部を拠点に活動していた。創設者はアビジット・バネルジー、エスター・デュフロ、センディル・ムラナサンの3人。この記事を書いている時点で、J-PALのウェブサイトには、84カ国で1,000件以上のRCTが完了、進行中であると報告されている。アカデミックな研究グループが、わずか15年でこれだけの成果を上げたことは、驚くべきことだと思う。J-PALのRCTに加えて、J-PALは実証的な開発経済学が広くRCTに重点を置くようになったことにも影響を与えている。確かに、J-PALの膨大なRCTの成果は、現在進行中のRCTの総数の過半数にも達していないだろうと思われる。
この取り組みは(J-PALを中心としながらもさらに進んで)アビジット・バネルジー、エスター・デュフロ、マイケル・クレーメルの3人に2019年スベリゲス・リクスバンク経済科学賞(アルフレッド・ノーベル記念)が授与されたことからもわかるように、この種の開発経済学の実証研究に新たな名声をもたらした。発表の見出しにあるように、この賞は “貧困を緩和するための実験的アプローチ “に対して授与された。
このセクションでは、まず、開発研究にRCT主義者が影響を与えた理由を考える。そして、その影響力が正当なものであったかどうかを問う。
なぜ無作為抽出者はこれほどの影響力を持っているのか?
因果関係を推測するためには、(実行可能な場合には)RCTが純粋な観察研究に勝るという見解を広めることが、明らかに影響力を持っている。J-PALのウェブサイトのランディングページには、次のように書かれている。「私たちの使命は、科学的根拠に基づいた政策を行うことで貧困を削減することである」。そのために、J-PALではRCTのみを行っている。厳密には、J-PALの研究者が観察研究を非科学的だと考えているわけではない(J-PALとは関係なく、J-PALに所属する多くの研究者が観察研究の手法を用いている)。しかし、この文脈では、「科学的根拠」や(J-PALのウェブサイトを含めてもう一つのお気に入りである)「厳密な根拠」という表現は、多くの読者の目にはRCTのコードと映っており、それは明らかに意図的なものである。その意味するところは、「ゴールドスタンダード」の主張よりもさらに強く、一部の支持者にとって、RCTは承認された方法のメニューのトップであるだけでなく、他のメニューには何もないのである。
RCTの魅力は、因果関係を特定する際に直面する課題を反映したものでもある。1990年代以降、経済学において同定問題への注目が高まっていることは喜ばしいことであるが35,このことが測定誤差などの他の重要な問題から注意を部分的にそらしているとの指摘もある(Gibson, 2019)。操作変数 推定量の妥当性については、より批判的な注目が集まっている。前述した有効な操作変数の条件のいずれかが満たされないと、推定値に偏りが生じることは容易に示すことができ、それは配置を外生的に扱うOrdinary Least Squares(OLS)の場合よりも可能性が高い。選抜された治療状況と相関のある外生変数を見つけることは、研究者にとって難しいことではなかった(ただし、適切なテストに合格する必要があった)。理論的な根拠に基づいて除外制限(操作変数は治療状況とコントロール変数が与えられた結果とは無関係である)を受け入れることは、はるかに困難であることが多かった。操作変数を容易に受け入れることができる場合もあったが、必ずしもそうではなかった。1990年代半ばから、セミナーの聴衆や査読者は、特定の論文の操作変数が内生変数とは独立したアウトカムへの影響を持ちうる理由を定期的に指摘していた。やがて、一部の経済学者は、無作為割当なしで因果関係を確立しようとするほとんどすべての試みを拒否し始めた。
治療オプションを割り当てられた人とそうでない人との間の平均アウトカムの差(これはIntent-to-Treat(ITT)パラメータと呼ばれる)を知りたいだけであれば、無作為化は操作変数推定値に関するこれらの懸念を払拭する。無作為化により、治療の割り当ては外生的であり、回帰誤差項とは相関しない。しかし、ITTはかなり限定的なパラメータとなる。政策が治療の選択肢の割り当てであることが多いため、「政策に関連する」と弁護されることもある。しかし、治療を提供された人の平均的な影響はゼロで、治療を受けた人の平均的な影響はプラスであったとしたら、あなたはどのように反応するであろうか?そのような発見があれば、政策立案者や市民はきっと興味を持つであろう。RCTから学ぶ際に、治療を採用する予定の人は、治療を受けた人の平均インパクトを知りたいと思うであろう。
人間を対象とした無作為に割り当てられた治療法の採用は決して確実ではなく、コンプライアンスは通常、内生的なものである。そのため、経済学的な問題が実際にはよく起こる。RCT主義者は解決策を持っている:無作為化割り当てを実際の治療の操作変数として使用するのである。明らかにtake-upには割り当てが必要なので、この操作変数は治療状況と相関している。ランダムなので、治療効果が母集団全体に共通している場合、操作変数は誤差項と(期待値で)相関しない。(影響が、研究者には知られていないが、各参加者には知られていて、参加者がそれに応じて反応するような形で変化する場合に起こりうる複雑な問題については、また議論する)。
これらの経済学的な議論以外にも 2000年代初頭から無作為化派の影響力が増していった要因がいくつかある。無作為化を行わない研究者はRCT主義者に批判され始め、彼らの論文は関連文献への引用において無視されるようになった。このような事態の一部は、公開されていないジャーナル論文に対する査読者のコメントという形で行われた。ジャーナルの編集者はこのような批評を受け入れる必要はないが、有力なRCT主義者は影響力を持ち、やがて経済学ジャーナルの編集者や編集委員会の中でかなりの地位を占めるようになったようである。時には、FinkelsteinとTaubman(2015)の研究のように、医療提供政策の評価に観察的手法やその他の非ランダムな手法がしばしば用いられていることに疑問を呈したように、批判も公的な形で行われた。そしてこの知見は、ニューヨーク・タイムズ紙で「Fewer Health System Studies use Top Method, Report Says」(Tavernise, 2015; my emphasis)という見出しで報じられ、「トップ」がRCTであることが明示的に捉えられている。ここでのメッセージは明確であるが、それが正しいかどうかはあまり明確ではない。公衆衛生の専門家の中には、健康システムに関する研究を犠牲にして、個々の治療に対する評価に注目が集まりすぎていると主張する人もいる36。
主要なRCT主義者は、自分たちが好む手法の使い方を他の人々に教えることにも成功した37。開発経済学者は、一部のNGOと同様に、すぐに対応できるようになった。彼らはまた、良いRCTを構成する基準を着実に高めていたが、RCTが他の手法に比べて批判的な精査を受けていないというHeckman and Smith (1995)の観察は、今日でも真実であると思われる。
また、J-PALの創設者たちが「エビデンスに基づいた政策立案で世界をより良くしたい」と公言していたことも、J-PALの影響力を高める要因となっている。これは、J-PALが当初から宣言していた動機である。RCTを数多く行うことで、何が有効で何が有効でないかを把握し、前者をスケールアップし、後者をスケールダウンすることができるという考え方だ(Banerjee, 2006)。臨床試験におけるRCTは、どの薬が平均的に最も効果があるかを調べるために使われるものと類似している(Favereau, 2016)。
一部のフォロワーは、有力なRCT主義者の熱意に明らかに惹かれている。この見方によって、「……実験倫理は、開発の精神を変える方法として提案されている」(Donovan, 2018, p.27)。RCT主義者たちは、「真の信者」を惹きつける認識論的な運動と捉えることもできる38。 RCTに対するこの運動の信仰は、信者たちに「静かな革命」を約束するものである(Banerjee and Duflo, 2011, p.265)。
支持者(寄付者を含む)は、RCTのシンプルさにも惹かれている。「より透明性が高く、説明しやすい」(Duflo, 2017, p.17)のだ。J-PALが設立された頃には、技術的にも高度化していた観察研究で好まれる手法よりも、経済学を専門としない人でもRCTを理解しやすいのである。
RCT主義者の影響力は正当なものか?
2.2節で述べたように、統計学の基礎は、(実行可能であれば)どんな状況であっても必ずRCTの方が信頼性が高く、そのために手法のヒエラルキーの最上位に位置するということを教えてはいない。これは科学というよりも信仰の問題である。非ランダムな割り当てを用いた方法を否定する声もあるが、これは明らかに、この方法で因果関係を特定する際に直面する課題に対する過剰反応である。
また、臨床試験の例えは説得力がない。介入策とコンテクストの両方に次元があることを考えると、開発において何が有効で何がそうでないかを把握するためにブラックボックスRCTを使用するというアイデアが実現可能であるかどうかは不明である。また、RCT の論拠には、介入に対する明確な経済的根拠や、なぜそれが有効なのか、あるいは有効でないのかを理解するための首尾一貫した構造が欠けていることがあまりにも多い(Heckman and Smith, 1995)。
開発無作為主義者が臨床試験をモデルとして指摘する一方で、医学研究者はより微妙な見方をしていた39。一方で、最近の文献の中には、因果関係のある観察的健康・医学研究におけるバイアスに関する過去の懸念が誇張されていたことを示唆するものがある。一方、最近の文献では、因果関係のある観察研究や医療研究におけるバイアスに関する過去の懸念が誇張されていたことが示唆されている。
しかし、これらの点を考慮した上で、医学的な背景が異なることを認識する必要がある。経済学者(およびその他の社会科学者)が扱うのは、社会的・経済的文脈の中にいる(個人やグループとしての)人々であり、彼らは臨床試験よりも大きな不均質性を示し、ほぼ確実に大きな主体性を持つことが予想される。私たちは、特定の環境について先験的にほとんど知らないことがある。
RCT主義者の主張の表面下には、より深い推論上の問題が潜んでいる。この問題は、双方の専門家には知られているが、より広く理解されていない。治療の影響には、ほぼ確実に観察されていない異質性がある。その原因は、個人の状況(介入の種類に関する過去の経験など)と、エージェントの努力(影響に関する信念を反映している)の両方を含む多くのものがある40。このような異質性は、「誰にとっての影響か?」という問題を提起する。この疑問に答えたのがAngristら(1996)で、操作変数推定量は被曝者の一部、すなわち無作為化割り当てによって治療状況を切り替えるように誘導された「コンプライヤー」の平均インパクトを与えていることを示した41。
治療を受けた人の平均的な影響を推定する場合、治療の影響における観察されていない異質性に対する行動的な反応がある場合には、選択的な取り込みに対処するための操作変数としての無作為化割付の有効性は疑問視される(Heckman and Vytlacil, 2005; Heckman er al)。 そして、異なる影響は、無作為化割り当ての選択的な取り込みと相互作用しながら、回帰誤差項に追いやられなければならない。治療に対するリターンが高いユニットは、それを採用する可能性が高くなる。そして、誤差項に現れた相互作用効果は、無作為化割り当てと相関していなければならない。排外制約は失敗である。もちろん、ITTのみを求める場合には、このことは問題にならない)。
社会プログラムの影響を特定することは、無作為化割り当ての有無にかかわらず、ほとんど容易ではない。個人レベルでのインパクトを高める潜在的な特性が、選択的コンプライアンスを伴うRCTでの反事実上のアウトカムにも重要であるとする。その場合、推定方法の選択は、どのようなインパクト・パラメータに関心があるか、評価するプログラムの種類、そのプログラムに対する行動反応に決定的に依存する(Ravallion, 2014に示されている)。治療への高いリターンをもたらす潜在的な要因が、より低い反事実上のアウトカムと関連している場合、内生的治療の「操作変数治療」は病気よりも悪い可能性がある。実際、選択的な取り込みにもかかわらず、OLS推定量が不偏になることさえある。重要な点は、実務者は、それぞれのアプリケーションにおいて、異質な影響に対する行動上の反応の可能性について注意深く考える必要があるということである。
実際のRCTのデザインは、同定を脅かす可能性もある。無作為化された割り当ては、村のような個人のクラスターにまたがって行われることがある。あるクラスターは治療を受け、あるクラスターは治療を受けない。選ばれた治療クラスタ内の人々は、自分の好きなように治療を受けることができる。この方法は、クラスター内で干渉が生じ、選択された治療クラスターの非参加者がプログラムの影響を受けるような場合に問題となる。例えば、Ravallion et al 2015)のクラスターRCTでは、インドの全国農村雇用保証法に基づく権利を人々に教えるために娯楽映画を使用した。村の中でチケットの割り当てを強制することは不可能で、映画は公共の場所、多くは村の開けた場所で上映されなければならなかった。そのため、映画を見ることができる場所は村全体でランダムに割り当てられ、人々は映画を見るかどうかを自由に選ぶことができた。映画を見ない人もったが、(もちろん)見た人と話すことができ、これが知識への影響の重要な経路となった。クラスター無作為化は、なぜ一部の人が映画を見たのかという行動モデルと組み合わせる必要があった(Alik-Lagrange and Ravallion, 2019)。そうすることで初めて、直接的な治療効果(映画を見ること)を間接的な効果(映画にアクセスできる村に住むこと)から分離することができた。この例では、クラスター内のスピルオーバー効果が排外制約に違反しているため、個人の受診率の操作変数としてクラスター割り当てを使用してもうまくいかない。
一般的なポイントは、無作為化割り当てを用いた平均因果影響のクリーンな同定についての主張に反して、実際には仮定とモデルが必要な場合が多いということである。無作為化を用いた研究の基礎となる行動の仮定が必ずしも明示されていないのは仕方のないことである(Keane, 2010)。対照的に、構造的アプローチでは、これが強制的に行われる。
いくつかの懸念事項は、その価値に比べて文献ではあまり注目されていない。例えば、モニタリングによって行動が変化するホーソン効果がある。例えば、自分が対照群であることを知っていれば、代替可能な治療法を求めようとするかもしれない。また、治療群の中には実験者を喜ばせようとする人もいるかもしれない43)。 経済学におけるRCTは、臨床試験のような二重盲検法を採用していないことが多いため、モニタリングに伴うバイアスが発生しやすく、開発用途ではより注意が必要である44。
4. 倫理的な異議を真摯に受け止める
倫理的な問題は、政策立案から決して遠いところにあるものではない。評価の倫理性を真剣に考慮しないことには2つの危険がある。第一に、道徳的に受け入れがたい評価が行われてしまう可能性がある。しかも、脆弱な人々や彼らの権利を保護する機関が弱い貧しい場所で行われることが多いかもしれない。第二に、社会的に価値のある評価が、政治的にリスクが高すぎるとして、主に利益を知らずに阻止されてしまうかもしれない。
RCTは、「無作為化者は『学習』のために研究参加者の幸福を犠牲にすることを厭わない」という理由で批判されていた(Ziliak and Teather-Posadas, 2016)45 批評家はしばしば、RCTでは治療を必要とする人が治療を受けられない一方で、必要のない治療を受ける人もいることを指摘する。また、貧しい国で行われるRCTでは、豊かな国で期待される(決して保証されているわけではないが)倫理的な精査が行われていないという批判も聞かれる46。危険性のある治療法の臨床試験にRCTを用いる場合、開発途上国の参加者が、治療を受けることになった場合に直面する健康上のリスクをほとんど認識していなかったという事例がよく知られている47。Baele(2013)は、開発RCT主義者がRCTの倫理性に十分な注意を払っていないと論じている。Glennerster and Powers (2016) は、RCT の批判者に対して慎重な倫理的擁護を行っている。
倫理的妥当性は、すべての評価にとって深刻な問題ではない。影響評価は、既存のプログラムの上に構築されることがあるが、その場合、プログラムの働きについては何も変わらない。この評価では、プログラムが利益を配分する方法をそのまま採用する。そのため、プログラムが倫理的に受け入れられると判断されれば、評価も同じように行われると考えられる。これを “倫理的にベナンな評価 “と呼んでいる。
他の影響評価では、プログラムの(既知または想定される)割り当てメカニズム(誰がプログラムを受け、誰が受けないか)を意図的に変更する。この場合、通常の規模で行われる介入が倫理的に受容可能であっても、評価が倫理的に受容可能であることを意味しない。これを “倫理的に争うことのできる評価 “と呼んでいる。実際のところ、主な例はRCTである。スケールアップしたプログラムでは無作為化割付を行うことはほとんどないため、RCTでは割付のメカニズムが異なり、影響の不均一性が考えられることから、ベネフィットに大きな差が生じる可能性がある。RCTは、実際のプログラムが問題なくても、倫理的に争われることがある。
良い目的が悪い手段を正当化することはないというのは、(経済学者にはあまり縁のない)かなり極端な立場であることは確かである。結果によってプロセスを部分的に判断することは、倫理的に正当化される。実際、道徳哲学では、結果がプロセスに勝ることが多いという長い間尊敬されてきた見解があり、その代表的な例が功利主義である。RCTを行うことは、新しい知識から期待される利益によって正当化されると考えられる限り、本質的に「非倫理的」ではない。しかし、結果的に得られる利益とプロセス上の懸念とを慎重に比較検討する必要がある。これは、実行可能で倫理的に問題のない観察研究が選択肢となる(多くの)場合に特に当てはまる。
倫理については、医療研究において多くの議論がなされていた。そこでは、等閑視の原則により、治療の効果を信じる決定的な先行事例があってはならないとされている48。評価者が倫理的妥当性を真剣に考慮するのであれば、開発RCTの中には、結果についてすでにある程度の確信があり、倫理的に問題のある研究を正当化するほど知識から得られる利益が大きくなりそうにない場合、受け入れられないものとして除外しなければならないであろう50。
開発や社会政策のためのRCTに等閑視の原則が適用されることはほとんどない。実際、その逆の傾向があるかもしれない。著名な慈善団体のファンダーが最近行った提案募集では、「非常に有望な事前のエビデンスに裏付けられ、アウトカムにかなりのインパクトをもたらす可能性が示唆されている。.」RCT提案を明確に優先していた。(Arnold Foundation, 2018, p.2)としている。RCTにはコストがかかり、限られたリソースでインパクトを与えたいという願望があることを考えると、一面ではファンダーの好みを理解することができる。この種のいくつかのex anteフィルターは理にかなっている。しかし、上記の例では、そのような介入を行うことはできない。しかし、上記の例では、ドナーの目的と倫理的懸念との間に緊張関係があることが指摘されている。「アウトカムへの影響が大きい」という事前の確信があるからこそ、必要な人から治療を差し控える(必要のない人には治療を無駄にする)ことに不安を感じるのである。また、このことは、何を評価するかを決定する資金調達プロセスに対する懸念を示している。セクション2.5ではこの話題に戻る。
RCTを倫理的に擁護する意見もある。1つの見解は、配給が必要な場合にはRCTが正当化されるというもので、全員をカバーするのに十分な資金がない場合には、無作為化割り当てが公正な解決策であると主張されている51。これは、情報が非常に乏しい場合に理にかなっている。開発アプリケーションの中には、インパクトを最大化するために参加者をどのように割り当てるのが最善か、事前にほとんどわからないものもある。しかし、代替的な割り当てが可能であり、誰が利益を得る可能性が高いかという事前情報がある場合には、その情報を利用し、少なくとも無条件に無作為化しない方が公平であることは確かである。
また、条件付き無作為化(「ブロック型」または「層別型」無作為化とも呼ばれる)の方法は、倫理的な懸念を解消することができると主張されている。ここでの考え方は、まず、得られる可能性の高い利益に関する事前の知識に基づいて対象となるタイプの参加者を選択し、その後、すべての参加者が対象となるわけではないことを考慮して、介入を無作為に割り振るというものである。例えば、トレーニングプログラムや、最大限の効果を得るためにスキルを必要とするプログラムを評価する場合、事前の教育や経験が効果を高めると(いくつかの証拠に裏付けられて)合理的に仮定し、それに基づいて評価をデザインすることになる。この方法は、影響の可能性に関する事前情報がある場合、純粋な無作為化よりも倫理的な利点がある。
しかし、これには問題がある。評価者が観察可能なものは、通常、現場で見られているものの一部に過ぎない。例えば、村のレベルでは、評価者が入手できる情報よりも多くの情報が存在することがある。しかし、誰の情報がこの問題を決めるのであろうか?誰が必要としていて、誰が必要としていないか、他の関係者がよく知っているのに、評価者が無知を訴えるのは、言い訳にしかならない。
また、奨励型のデザインは倫理的に問題が少ないとも言われている。これは、対象となる主要なサービスへのアクセスを誰も妨げず、代わりに何らかのインセンティブや情報へのアクセスを無作為化するというものである。これは、倫理的な問題を取り除くものではなく、主要な関心事であるサービスから別の空間に移すものである。倫理的妥当性は、利益を得ることができる一部の人々から奨励が意図的に差し控えられ、利益を得ることができない一部の人々に奨励が与えられている場合、依然として懸念として立ちはだかる。
例えば、(Bertrand et al 2007)のRCTを考えてみよう。一方の治療群では、インドのデリーで運転免許証をすぐに取得できた参加者に多額の金銭的報酬を与え、免許証担当者への賄賂を促進した。このRCTでは、賄賂を直接支払ったり、運転の仕方を確認できない人に免許を与えたりはしなかったが、これらは予測可能な結果であった。このRCTで期待されたのは、「インドでは汚職が発生し、実際に影響がある」という命題をきれいに検証できたことである。しかし、その主張の真偽について、事前に深刻な疑念があったとは思えない。
RCTは、倫理的な問題を解決するために設計することができる。52 生物医学的な環境とは対照的に、特定の開発アプリケーションにおいては、最良の選択肢についての合意はほとんどないかもしれない。しかし、「何もしない」またはプラセボ対照の一般的な使用が、ほとんどの開発用途において緊密な倫理的精査を通過することはなさそうである。通常、何らかの選択肢がある。(また、「何もしない」ことは、ほとんどの政策立案者にとって、特に関連性のある反事実ではないと思われる)。
もう一つの選択肢は適応型無作為化である。これは、各段階で観察された反応を伴う割り当ての順序がある場合に実行可能である。適応的無作為化は、影響に関する蓄積された証拠に照らして、途中で割り当てを変更する53。 成田(2018)は、社会実験のための興味深い市場的な適応的デザインを提案しており、影響に関する事前の知識が与えられた場合に、治療の機会に対する各参加者の支払意思を考慮する54。本稿執筆時点では、このアイデアは現場では実施されていないようである。
米国などでは、人間を対象とした研究を提案する際に、IRB(Institutional Review Board)を設置することが一般的になっている。ほとんどの研究機関には指定のIRBがある。IRBはほぼ自主規制である。時折の逸話を除いて、IRBのプロセスが開発RCTにどれほど効果的であったかについての体系的な評価はなされていないようである。ひとつ明らかなことは、IRBは、既存の知識に基づいて、倫理的に争うことのできる評価の期待される利益を評価することにもっと注意を払う必要があるということである。現在の知識の統合はその助けとなり、これらはより一般的になってきている55。
迫られれば、多くの無作為抽出者は上述の倫理的懸念を認めるが、論文の中でそれ以上の注意を払うことはほとんどない。彼らは、自分たちのRCTがそのような懸念を上回る利益を生み出すと(多くの場合、暗黙のうちに)仮定している。それが真実であるかどうかは、ほとんど明らかではなく、もっと注目されるべきである。
私たちはまた、研究の努力が知識のギャップにどれだけ合致しているかを問うべきである。差し迫った開発の課題と研究のための限られたリソースを考えると、この種の不均衡はさらなる倫理的懸念をもたらす。では、これらの問題を取り上げる。
5. 政策立案との関連性
優れた政策立案には、優れたエビデンス以外にも多くのものがあることは明らかだが、政策立案者はますますエビデンスに目を向けるようになり、自分たちの選択に情報を与え、政治的な議論を勝ち取ることを望んでいる。評価研究の政策との関連性は重要だ。
私の知る限り、これらすべてのRCTが開発政策に与える影響について、包括的かつ客観的な評価はまだなされていない。それにもかかわらず、RCTを用いた政策関連研究の例を挙げることができる。一例を挙げると、(Banerjee et al 2014)は、6カ国(Ethiopia、Ghana、Honduras、India、Pakistan、Peru)でRCTを用いて、最貧困層を対象とした資産や現金の移転と識字・技能訓練を組み合わせたBRACによる長年の貧困対策を評価している56。研究者たちは、BRACのアプローチを採用することで、最初の資産移転から約3年後、支給終了から 1年後に経済的利益が得られることを発見した。
包括的な評価を目的とするわけではないが、この議論では、文献を参考にしながら、開発政策に情報を提供するためのRCTのいくつかの限界を指摘する。
政策に関連するパラメータ
理想的な条件であっても、RCTは、政策立案者が関心を持つパラメータのかなり狭いサブセットを推定するのに適している。現実には、文脈や参加ユニットの特性に応じて、得をする人と損をする人の両方がいることが予想される(また、前述のように、これらの特性のいくつかは分析者にとって観測されないものであるが、それでも治療を受けるかどうかなどの行動の動機となる)。影響には分布がある。政策立案者は、人口のどの割合が利益を得て、どの割合が損失を被るのか、あるいはどのタイプの人々が利益を得て、どのタイプの人々が損失を被るのかを知りたいと思うかもしれない。このような政策に関連するパラメータを特定するには、通常、より多くのデータとより多くの構造計量法が必要となる。本格的な構造モデルは、関心のある問題を解決するために必須である必要はないが、(逆に)RCTが必要なものを提供することはほとんどない。
個々の影響について、単にその平均値よりも多くのことを確実に知る方法がある。例えば、(Heckman et al 2006)によって提案された局所器物変数推定法は、治療を受ける経験的確率のすべての値における限界治療効果(MTE)を特定することを目的としている。標準的なRCTとは異なり、「選択的試験」では、(コントロールではなく)治療に割り当てられる確率を、エージェントの支払い意思に基づいて決定することで、MTEを特定することができる(Chassang er al)。 そして、RCTで特定されるように、平均的なインパクトを得るために集計することができる。しかし、平均的なインパクトよりも多くのことを学ぶことができる。
調査では、反実例の質問を確実に行うことができる場合もある。これはMurgai et al 2016)で行われたもので、ワークフェアプログラムの参加者に、そうでなければ何を稼いでいると思うかを尋ねている(地元の労働市場に対する観察的なチェックを行っている)。そうすれば、インパクトの分布をより詳しく知ることができるが、(もちろん)調査回答には測定誤差があるので、ほぼ確実に何らかの平均化が必要となる。
政策立案者にとって関心の高いパフォーマンスの側面は、プログラムから誰が恩恵を受けるかということであり、それはプログラムの設計に含まれる割り当てメカニズムによって(部分的に)決定される。需要に応じてプログラムを利用する場合、プログラムを利用する人の特徴はどのようなものであろうか。また、配給制であれば、誰に配給されるのか?このような疑問は、プログラムを受ける人と受けない人の統計モデルから始まる、マッチングを用いた観察手法の重要なクラスの最初の段階で出てく57。もちろん、RCTであれば、予想されることであるが、割り当ては予測できない。
不完全コンプライアンスの場合は、前述の操作変数推定量の第一段階で知ることができる。実際、Heckman and Pinto (2019)が論じているように、無作為化割り当てのテイクアップが合理的選択の結果であることを認識すれば、それを利用して参加の決定要因の両方を研究し、より幅広いカジュアル・パラメータを特定することができる。例えば、古典的なRCTにおけるインセンティブを変化させ、明らかにされた選好の弱い公理を援用することで、Heckman and Pinto (2019)の結果は、貧困層および/または社会的に排除された人々によく見られる社会政策の低テイクアップの問題に適用できる。被験者による選択的なコンプライアンスを統計的に厄介なものと考えるのではなく、そこから学ぶことができるのである。
また、事前にインパクトを評価するためにRCTを使用し、その後、実際のプログラムを規模に応じて、観察的推定法を用いて別の評価を行うこともできる。これは期待できそうであるが、選択的な取り込みと不均一な影響を考慮すると、基本的には2つの異なるプログラムを評価したことになり、実際に政府が実施したのはそのうちの1つだけであることを理解する必要がある。どちらが政策立案者の関心事になるかは想像に難くない。2回目の評価は行われるのだろうか?ゴールド・スタンダード」の考え方であれば、そうはならないかもしれない。
政策の効果を知る上での問題の核心は、RCTが想像できる現実の政策とは異なり、かなり人工的に作られたものであるということである。
外部妥当性
政策立案者は、このような実験的な試みから、同じ介入策が他の環境でどのように機能するかを学びたいと思うのが当然である。これは外的妥当性の問題である。これは、モニタリング効果、一般均衡効果、サンプリングの問題、RCTで治療を提供する際の特別な配慮など、多くの理由で疑わしいものとなる(Duflo et al 2008)。
このような問題は、開発型RCTを記録した論文では無視されるか、あるいは表面的な処理しかされていないことが多い。(Peters et al 2018)は、8つの経済誌に掲載された54の開発RCT(2009~14)の大部分について、外部無効性の原因が取り上げられておらず、それに対処するための情報も提供されていないことを発見した。もし、ある介入に関する異なるRCTが合意する傾向があるならば、外部妥当性について自信を持つことができる。しかし、それはそうではない。Vivalt(2017)は、設定(さらには評価者の種類)を超えて、与えられたプログラムの影響推定値に見られるばらつきを文書化している。彼女の発見は、一般化に対して警告している。Vivaltも指摘しているように、文脈的要因の不十分な文書化は助けにならない。Pritchett and Sandefur (2015) は、あるコンテクストで行われた(おそらく)内部的に妥当なRCTが、別のコンテクストでのインパクトを予測するための観察研究よりも劣っている例を(マイクロクレジット制度について)示している。推定値のばらつきのすべてが真のインパクトの不均一性によるものではなく、7つのマイクロクレジットRCTの推定値では、ばらつきの60%がサンプリングのばらつきによるものであることがわかった(Meager, 2018)。実際には、政策立案者はサンプリングのばらつきと真のインパクトのばらつきを簡単に区別することはできないだろう。
NGOと協力してRCTを行うことの利点(セクション2.2)は、外部妥当性についての疑問も引き起こしている。その一例は、(Duflo et al 2015)によるケニアの学校教育に関するRCTに見られる。無作為に選ばれた学校に、短期契約で働く追加の教師を雇う資源が与えられた。契約教師がいる子どもたちは、通常の公務員教師がいる子どもたちよりも、テストの点数が有意に良いことがわかった。この実験は、地元のNGOが実施した。しかし、(Bold et al 2018)は、フォローアップRCTを用いて、これを大規模に再現しようとしたが、今度は政府が実施したアーム(NGOによるものも含む)を用った。これにより、テストスコアの向上をもたらしたのはNGOによる実施であり、教師のタイプではないことが明らかになった。(Duflo et al 2015)が発見した教師効果は消滅していたのである。
「ブラックボックス」と呼ばれる縮小形式の推定値は(RCTによるものであれ、そうでないものであれ)政策立案の多くの目的にとってあまり有益ではない。RCTからの学習は、特定の問題を引き起こす。RCTからスケールアップについてどのように学ぶことができるかを考えてみよう(これは確かに重要な目的だ)。RCTでは、潜在的な属性に基づいて、影響力の低い人々(プログラムがほとんど利益をもたらさない人々)と影響力の高い人々を無作為に混合する。スケールアップされたプログラムでは、プログラムに魅力を感じる影響力の高いタイプの人々がより多く参加することになるのはもっともなことである。
これは、Moffitt(2006)が指摘している、パイロットプログラムを拡大する際には、インプットやプログラム自体も含め、多くのことが変化しうるという、より一般的な指摘を反映している。資金提供者を惹きつけるために自分たちの価値を示そうとしているNGOは、通常の運営の典型的なものではない試験から得られるインパクトを示したいという動機を持っている。フィールドテストを行う若い研究者は、スケールアップしたバージョンを実施する政府関係者よりも大きな努力を払うかもしれない。外部妥当性は、実際には十分な注意が払われていないパイロットのデザインと実行に制約を与える。
外部妥当性を知るための一つの方法は、異なる文脈で評価を繰り返すことである。例えば、Galasso and Ravallion(2005)は、バングラデシュの「Food-for-Education」プログラムのパフォーマンスを、100の村ごとに観察手法を用いて調査し、その結果を村の特徴と関連づけた。パフォーマンスの違いは、村内の土地の不平等(不平等な村ほど貧困層への支援効果が低い)など、観察可能な村の特性から説明できる部分もあった。このような違いを考慮しなかったことは、過去の評価における重大な弱点とされている59。
影響評価のブラックボックスの中を見ることで、その外部的妥当性や政策的意味合いに有益な光を当てることができる。そのためには、本来の評価デザインとは異なる情報が必要になることがある。その例として、(Galasso et al 2004)によるProempleo RCTがある。賃金補助のためのバウチャーを、現在ワークフェアプログラムに参加している人々に無作為に割り当て、無作為化対照群を設けた。理論的には、賃金補助によって企業の労働コストが削減されるため、その労働者を雇用することがより魅力的になると考えられる。理論の予測と一致して、RCTでは雇用に有意な影響が見られた。しかし、その後、行政の記録と照合したところ、企業による賃金補助金の利用率が非常に低いことが判明した。つまり、Proempleoは理論が想定していた通りには機能しなかったのである。企業と労働者へのフォローアップの質的インタビューによると、バウチャーは労働者にとって、ほとんどの人が持っていない「紹介状」のような信憑性のある価値を持っていることがわかった(このRCTでは、無作為に割り当てられていることは秘密にされていた)。これは、RCTではわからず、補足的な観察データが必要であった。これは研究者が事前に予想していなかったことなので、事前の分析計画に厳密に従うと、プログラムがなぜ影響を与えたのかという、政策に関連する重要な側面を見逃してしまうことになる)。余分なデータは、仕事を得る方法についての情報提供の重要性を明らかにした。しかし、このRCTに基づいて賃金補助の規模を拡大することは、間違いだったであろう。
研究者の中には、より深い構造的パラメータに光を当てるために、(介入またはその配置の重要な決定要因のいずれかの)無作為化を利用している人もいる。例えば、Todd and Wolpin (2006)は、前述のメキシコのProgresaのRCTを用いて、この制度が提供する就学インセンティブに対する動的な行動反応をモデル化している。このような研究は、プログラムの影響を理解するのに役立ち、代替的な政策デザインのシミュレーションを容易にする。ToddとWolpinは、Progresaの補助金をより高いレベルの学校教育に切り替えることで、全体的な影響が高まることを示している。同様に、プログラムの根拠となる「変化の理論」の中の1つまたは複数の重要なリンクを検証するためにRCTを使用する余地がある。これは、理論に基づいたより野心的な実験の余地に関するHeckman(1992)とHeckman and Pinto(2019)の議論を反映している。
知識のギャップ
反貧困政策立案を支援するために、研究者は理想的には、政策の有効性について我々が知っていることと、政策立案者が知る必要のあることとの間のギャップを埋めるべきである。これは明らかに、私たちが期待するほどには実現していない。例えば、Kapur (2018) は、インド政府 (GOI) の元首席経済顧問へのインタビューを紹介している。「高価なRCTのうち、どれだけがインドの政策の針を動かしたのかと聞かれたGOIのチーフ・エコノミック・アドバイザーであるArvind Subramanianは、彼のテーブルに出てくる何十もの差し迫った政策上の質問に対処する上で役に立ったものを1つも見つけることができなかった」60。
なぜこのような知識のギャップがあるのであろうか。ランダムな要因もあるが、よりシステマティックな「知識市場の失敗」もある(Ravallion, 2009b)。一つの原因は、評価における外部性の存在である。進行中の開発プロジェクトにインパクト評価を導入することで、支出のスピードなど、その実施の一部の側面を改善できるという証拠がある(Legovini er al)2015)。しかし、評価によって得られた知識は、将来のプロジェクトにも利益をもたらし、(願わくば)過去の評価から得られた教訓を生かすことができる。現在のプロジェクトマネージャーは、自分のプロジェクトの評価にどれだけの費用をかけるかを決める際に、これらの外部利益を適切に考慮することは期待できない。評価の種類によっては、より革新的なもの(その種の最初のもの)など、より大きな外部性があることは明らかである。評価における外部性は、長期的な評価が少ないという開発アプリケーションで指摘されている「近視眼的バイアス」にも一役買っている(Ravallion, 2009b; Bouguen et al 2019)。
知識市場の失敗は、ジャーナル編集者の選択プロセスと、ドキュメントを含む著者の行動の両方に由来する出版バイアスにも起因する。経済学における実験の後続の再現実験では、あまり強くない効果が発見されることが多い62。また、先行研究の結果は十分に再現されたが、その過程で、元の論文では明らかではなかったデータ分析の疑わしい点に非常に敏感であることが判明したケースもある63。
出版プロセスのダイナミズムは、知識ギャップを持続させるさらなる原因となっている。文献には誤りがあり,それを修正するには時間がかかることがある.あるテーマに関する最初の論文は、その独創性が認められて、目立つように出版されることがある。それ以降の論文は、劣悪なジャーナルに追いやられたり、引用される回数が減ったり、あるいはまったく発表されないこともある。原著論文の著者は、そのトピックに関する知識のゲートキーパーとなる。そのゲートキーパーは、時には通じることもあるが、それでもかなりの影響力を持っている。しかし、最初の論文が正しいとは限らない。その上、経済学では複製の努力に対するインセンティブが弱いようである64(しかし、科学分野では複製の失敗はよくあることである。このように、インパクトの分布から最初に引き出されたものは、受け入れられている知識に永続的な歪んだ影響を与える可能性があるのである。
また、外部無効性は、知識の蓄積プロセスにも懸念を与える。最初の論文が特定の状況下では真実に近かったとしても、別の状況下では有効性が制限される可能性があるのである。テーマが政策の影響や、その影響に非常に関連した問題である場合、政策に関する知識はそれに応じて偏りがちになる。
これらは一般的な問題であり、RCTに限ったことではない。しかし、「ゴールドスタンダード」の手法である階層化は、これから見るように、事態を悪化させる可能性がある。
研究努力と政策課題のマッチング
知識の格差は、評価作業の調整ミスにも起因する。一つの側面は、開発評価者があまりにも多くの場合、代用性(fungibility)の範囲を無視していることである。援助を受ける側(政府系か否かを問わず)は、開発援助などの新たな資金に応じて、自らの努力を再配分することができる。援助者は暗黙のうちに別のものに資金を提供していることが多い。あまり知られていないことだが、ドナーや政府高官は、自らのインパクトを評価する観点から、間違ったものを評価している可能性がある。つまり、代用性の生えやすい環境下では、援助先が資金提供したプロジェクトを評価するのではなく、実際に資金提供されたプロジェクトを評価するのである。そうすると、評価の努力が開発の努力とずれてしまうのである。
これはRCTのせいではない。しかし、評価者側の方法論的な好みが強いと、ミスアライメントを助長してしまうことがある。開発の無作為化は、知識に対して出力効果と代替効果の両方をもたらした。少なくとも 2000年以降、非常に多くのRCTを目にするようになったという事実から、積極的なアウトプット効果が示唆されている(図1)。しかし、すでに述べたように、これらの開発RCTの内的・外的妥当性は完全には明らかになっていない。もし、これらの資源(資金や人的資本)が他の場所に投入されていたならば、我々は何を学んでいただろうかという反面教師を知らないのである。
代替効果は、使用された方法に関連している。例えば、世界銀行を例にとってみよう。3ieのデータベースの中で最も古いRCTは世銀によるものであるが 2000年代初頭まで、このツールはIEの数ある信頼できる選択肢の一つに過ぎないと考えられてた。それ以来、世銀内ではRCTを支持する動きが顕著になり、一部のオブザーバーからは称賛されている。例えば、Lancet誌の社説では、「世銀はついに科学を取り入れた」と宣言している(Lancet, 2004, p. 65 世銀の独立評価グループ(IEG)の報告によると 2007~10年に開始された影響評価のうち80%以上が無作為化を用いているが 2005~06年は57%、それ以前は19%にすぎなかった(World Bank, 2012)。
仮にそれらのRCTがすべて知識に対する正のアウトプット効果を持っていたと仮定しても、代替効果は逆方向に働く可能性が十分にある。代替効果には3つの側面がある。第一に、RCTを用いて因果関係を明らかにすることが強調されたために、記述的研究を含む他の経験的調査の方法から注意が逸れてしまった。RCT研究論文から得られる政策的教訓のいくつかは、介入を結果に結びつける現実世界のプロセスを(質的・量的手法を用いて)「厚く」記述することで得られたものかもしれない。
第二に、個別プログラムを重視するあまり、構造モデルを用いたシステミックな研究が疎かになっているのではないかという懸念がある。経済学の分野では、Keane (2010)などが、教育や研究において構造的な研究に注目が集まっていないことを指摘している。また、このことは公衆衛生に関する研究の具体的な問題としても提起されている(Rutter er al)。
第三に、開発政策のポートフォリオの影響を評価する上での問題は、無作為化が政策や設定の非ランダムなサブセットに対してのみ実行可能であるということである。その意味するところは、RCTだけに頼っていると、幅広い政策について推論する能力を失うということだ。一般化すると、無作為化は、参加者と非参加者が明確に識別され、期間が比較的短く、料金や税金を課す必要がなく、コストや利益が非参加者のグループに波及する余地が少ないプログラムに適している傾向がある。このようにRCTは、多くの人に利益が共有される公共財よりも、個々の世帯に割り当てやすい私的財の方が理にかなっている(Hammer, 2017)。例外もある(特定の地域公共財など)。しかし、一般的には、中・大規模なインフラプロジェクトの場所を無作為化することははるかに難しく、セクターや経済全体の改革を無作為化することは不可能と思われる。そのため、このツールは、各国の開発戦略の中核となる活動には限定的にしか使えない。
私的財を提供することの影響を評価するには、「政策」の経済的根拠が必要である。市場が私財を効率的に提供することで、影響評価の必要性がなくなるのではないか?特定の状況下で私有財の評価が必要とされる正当な理由があるかもしれないが、多くの場合、RCT主義者は単にランダム化の機会を追い求めているだけのようである。確かに、再分配の目標が言及されることもあるが、どちらかというとカジュアルな方法である。分配の影響(貧困など)が厳密に取り上げられることはほとんどなく、明確な成果として特定されることもない。要するに、公共の経済学が欠落しているということである。
RCTの使用にこだわることで、政策立案のための知識がどのように歪められているかを示す例として、発展途上国における森林破壊を考えてみよう。よくあるのは、森林を所有する世帯が、地球温暖化に寄与する外部コストを考慮せずに木を伐採するというシナリオである。これを解決する方法として、ピグー税が知られている。しかし、これをRCTとして実施するのは困難である。なぜなら、課税権はほとんどが政府にあり、政府は(当然ながら)抵抗を示すからだ。代わりに、(Jayachandran et al 2017)によるウガンダのRCTのように、木を切らないことを選択した人にランダムに支払いを行うことができる。この政策は、政府を通さずに、地元のNGOが実施することができる。ここには公共経済的な合理性があるが、RCTを使用することで、評価される政策オプションが制約される。また、課税政策はおそらく異なる影響を与えるであろう(支払い政策は、木のストックに特別な価値を与え、価格効果とは別に所得効果を生み出すからだ)。
もちろん、単一のツールですべてのアプリケーションをカバーすることはできない。ここで問題となるのは、今日、研究努力と政策課題との間に妥当なバランスが取れているかどうかである。RCT主義者が提唱する(疑わしい)手法の階層化は、そのバランスを取ることを難しくしている。実際、私有財であっても、無作為化割り当てという考え方は、特定のタイプの人々や場所に到達することを一般的に目指す多くの開発プログラムの目標に反している。開発のRCTで好まれる介入である貧困層への現金給付において、政府は無作為割当よりもうまくいくことを望んでいる。
前述のIEGの報告書には、世界銀行のインパクト評価がその事業のセクターに偏って割り当てられていることや、評価ポートフォリオが世界銀行のセクターや開発の優先順位に適合していないように見えることが記されている(World Bank, 2012)。私は証拠を見たわけではないが、プロジェクトの利益が得られる期間に応じて評価の労力が割り当てられることにも不均衡があるのではないかと考えている。世界銀行の開発プロジェクトでは、長期的な影響を主張しているにもかかわらず、長期的な評価はほとんど行われていない。私は、世界銀行で長期的な評価を実施することがいかに難しいかを個人的な経験から証言することができる66。 RCTを好むことは、開発の知識における近視眼的なバイアスを悪化させることになる。
これは世界銀行に限ったことではない。RCTの使用におけるセクターの偏りは、Cameron et al 2016)が、2,200件以上の発表されたインパクト評価(前述の3ieデータベース)を手法とセクター別にクロス集計した結果からも明らかである67。全体として、これらの評価の約3分の2はRCTを使用しているが、RCTは特定のセクターに集中している傾向がある。特に、教育(58%がRCTを使用)保健・栄養・人口(83%、保健だけで93%)情報通信技術(67%)水と衛生(72%)である。一方、農業・農村開発、経済政策、エネルギー、環境・防災、民間セクター開発、交通、都市開発では、観察研究が多く、RCTを用いた研究は3分の1以下であった。また、影響評価の実施状況は、人口を考慮しても、地域的にばらつきがある。RCTの実施地域は、研究者と地元のNGOとのつながりに影響される。
この偏りには需要と供給の両面がある。評価の供給側では、今日の現実は、因果関係を明確に特定できるという約束に魅了され、多くの経済学者やその他の社会的・政治的科学者が無作為化できるものを探していることである。無作為化が不可能な場合、彼らは別の質問をする。
需要側では、政府(および開発機関)は、何を評価するかをほぼ自由に選ぶことができる。ここでの1つの懸念は、彼らがどのようなエビデンスを必要としているかを常に知っているわけではないということである(Duflo, 2017)。また、政治も役割を果たしている。否定的な評価が政治的に不利になるリスクが少ないプログラムを選んだり、問題があっても政治的に受け入れられる結果になると確信できる正当な理由があるプログラムを選んだりすることになるかもしれない(再び倫理的な懸念が生じる)。その他の重要なプログラムは評価されない。リスクは明らかである。
これらの懸念に対処するには、研究者の方法論的好みに左右されない、より戦略的な評価課題が必要である。私たちは、RCTに対するより戦略的な取り組みを目にするようになった。これは歓迎すべきことであるが、その戦略は依然として学術研究者が主導し、彼らの利益に基づき、一つのツールに専念している。もし私たちが、開発政策のポートフォリオの影響について公平な推定値を得ることを本当に心配しているのであれば、何を評価するかを慎重に選択し(あるいは無作為に選択するかもしれない!)RCTを1つの選択肢として、選択されたプログラムに最適な方法を見つける方がきっと良いであろう。開発の全体的な影響を公平に評価するという目標を真剣に受け止めるならば、それが求められているのである。研究はその目標を達成するために役立つが、それが自動的に起こることはないであろう。
6. おわりに
私たちは、貧困対策やその他の開発課題に取り組む上で、実験文化への歓迎すべきシフトを目の当たりにしている。RCTは、この目的のためのツールのメニューに含まれている。しかし、RCTは、提唱者が与えた特別な地位に値するものではなく、研究者、開発機関、ドナー、そして開発コミュニティ全体に大きな影響を与えている。2つの評価デザインに自信を持ってランク付けするためには、どちらか一方が無作為化を使用しているという事実以上に、多くのことを知る必要がある。
RCTの人気は、RCTを頂点とする「ゴールドスタンダード」と呼ばれる手法の階層に支えられている。このヒエラルキーは綿密な調査に耐えるものではない。よく言われることであるが、RCTは、治療を受けたユニットとコントロールユニットの間で反事実上の結果を同一にするものではない。系統的なバイアスがないからといって、単発のRCTの実験誤差が、ランダムではない別の方法の誤差よりも小さいということにはならない。それを知ることはできない。どのようなアプリケーション(評価のための予算が与えられている)においても、実現可能な方法の中で、RCTの選択肢が真実に近づく必要はない。実際、観察研究のサンプルサイズが同じ設定のRCTよりも十分に大きければ、観察研究による試験は、たとえバイアスがかかっていたとしても、より頻繁に真実に近づくことができる。
理論に基づいた有用な観察研究やその他の非ランダム研究(決定論的な実験割り当てなど)には、まだ十分な余地がある。確かにモデルの不確実性はあるが、一般的にはRCT主義者が想定しているほどではない。さらに、RCTを実際に見てみると、測定ミス、選択的コンプライアンス、コンタミネーションの問題に直面している。そして、無作為化論者が避けることを約束した、観察研究で見られるような仮定をしなければ、このツールは貧困やそれに対処するための政策についての質問に答えることができないことが明らかになった。
また、RCTは、観察研究にはない倫理的な問題を抱えている。RCTに反対する倫理的なケースは、すでに知られていることを考慮した上で、新しい知識から期待される利益を評価しなければ、適切に判断することができない。審査委員会は、学習を目的として、必要とする人には意図的に介入を控え、そうでない人には意図的に介入を行うという事前のケースにもっと注意を払う必要がある。特定の状況下では、既存の知識の限界に基づいて適切なケースがあるかもしれないが、そのケースは信頼できる方法で行われる必要があり、単に当然のことと考えてはいけない。
RCTが「ゴールドスタンダード」として優れているという疑わしい主張は、開発政策立案に情報を提供するためのインパクト評価の利用に歪んだ影響を与えている。この偏りは、無作為化が実現可能なのは、政策の非ランダムな部分集合に限られるという事実に起因している。プログラムがコミュニティや経済全体に及ぶものであったり、治療を受けた人から受けていない人への波及効果がある場合には、RCTはほとんど役に立たず、欺瞞に満ちたものになる可能性もある。RCTは、かなり狭い範囲の開発政策にしか適しておらず、その場合でも政策立案者が問う多くの疑問を解決することはできない。RCTをインパクト評価のための最良の、あるいは唯一の科学的手法として提唱することは、貧困と戦うための知識ベースを歪めてしまう危険性がある。このリスクは、Ravallion (2009a)の主な懸念の一つであり、それ以降の経験がその懸念を強めている。
この10年間で大きな進展があったとはいえ、開発に関する評価研究が、現在直面している政策課題にうまく適合しているかどうかについては、疑問の余地がある。この論文では、より良い調整が必要であることを論じている。
- RCTを頂点とする手法の無条件の階層化という主張を捨て、「科学的」かつ「厳密な」証拠はRCTに限定されるものではないことを明確にすること。
- RCTから期待される利益について、問題となる倫理性と比較して、明確かつ十分に研究された事前の声明を要求すること。
- 構造的アプローチの基準と同様に、無作為化評価の基礎となる行動上の仮定を明示する。
- 因果関係の平均的な影響を超えて、政策的に関心のある他のパラメータを含め、介入を結果に結びつけるメカニズムをよりよく理解すること。
- RCTを、開発政策のポートフォリオに関連する知識のギャップに対処するためのツールキットの1つの要素に過ぎないと考える。