

Contents
www.nature.com/articles/d41586-019-00857-9

セミナーで講演者が、2つのグループの間に「統計的に有意ではない」という理由で「差がない」と主張するのを最後に聞いたのはいつであったか?
もし、あなたの経験が我々と同じなら、あなたが参加した最後の講演でこのようなことが起こった可能性が高いだろう。よくあることだが、プロットや表で実際に差があることが示された場合、聴衆の少なくとも誰かが当惑されたことを我々は願っている。
統計学の教育を受けていない人でもはっきりと分かるような差異を、どうして統計学は科学者に否定させるのだろうか?何世代にもわたって、研究者は、統計的に有意でない結果は帰無仮説(群間に差がない、あるいは測定結果に対して治療の効果がないという仮説)を「証明」するものではない、と警告されてきた1。また、統計的に有意な結果は、他の仮説を「証明」するものでもない。このような誤解は、誇張された主張によって文献を歪めてきたことは有名であり、また、あまり知られていないが、存在しない研究間の矛盾を主張することにつながってきた。
我々は、科学者がこのような誤解の餌食にならないよう、いくつかの提案をしている。
蔓延する問題
P値が0.05などの閾値より大きいからといって、あるいは信頼区間にゼロが含まれているからといって、「差がない」あるいは「関連がない」と結論付けてはならない。また、一方が統計的に有意な結果を示し、他方がそうでないからといって、2つの研究が矛盾していると結論づけるべきではない。このような誤りは、研究努力を無駄にし、政策決定に誤った情報を与えてしまう。
例えば、抗炎症剤の意図しない効果に関する一連の分析について考えてみよう2。その結果は統計的に有意ではなかったので、ある研究者は、抗炎症剤の投与と新たに発症した心房細動(最も一般的な心拍障害)とは「関連がない」と結論づけ、その結果は、統計的に有意な結果を得た先行研究の結果とは対照的なものであったとした。
さて、実際のデータを見てみよう。統計的に有意でない結果を説明した研究者は、リスク比を1.2とした(つまり、曝露された患者では、曝露されていない患者に比べてリスクが20%高いということである)。また、95%信頼区間は、3%というわずかなリスクの減少から48%というかなりのリスクの増加にまで及んでいた(P = 0.091、当社計算)。統計的に有意な先行研究の研究者たちは、全く同じリスク比1.2を発見した。その研究の方がより正確で、9%から33%のリスク増加の区間であった(P = 0.0003、私たちの計算による)。
区間推定値に重大なリスク増加が含まれているにもかかわらず、統計的に有意でない結果を「関連がない」と結論づけるのはおかしなことであり、これらの結果が、同一の観察効果を示した先の結果とは対照的であると主張するのも同様におかしな話である。しかし、これらの一般的な慣行は、統計的有意性の閾値への依存がいかに我々を惑わすかを示している(「誤った結論に注意」参照)。
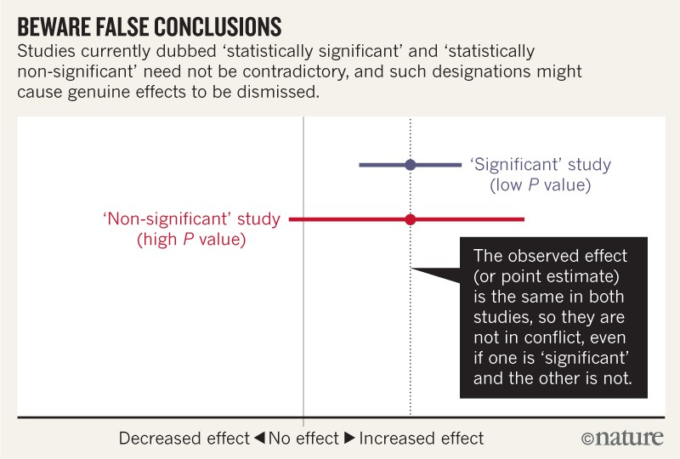
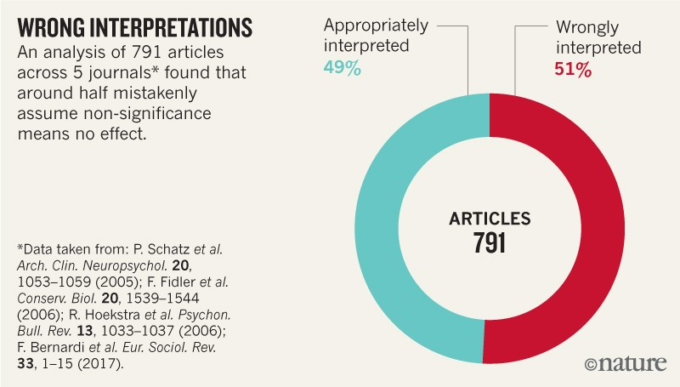
これらと類似の誤りは広く見られる。数百の論文を調査したところ、統計的に有意でない結果が、約半数で「差なし」または「効果なし」を示すと解釈されていることがわかった(「間違った解釈」および補足情報参照)。
2016年、アメリカ統計学会は、統計的有意性とP値の誤用に警告する声明をThe American Statisticianに発表した。同号には、このテーマに関する多くの解説も掲載された。今月、同誌の特集号は、こうした改革をさらに推し進めようとするものである。21世紀における統計的推論:「P < 0.05を超えた世界」に関する40以上の論文が掲載されている。編集者は、「『統計的に有意』とは言わないように」という注意を促して、この論文集を紹介している3。何十人もの署名者がいる別の記事4でも、著者と雑誌編集者にこれらの言葉を否定するよう求めている。
我々はこれに同意し、統計的有意性の概念全体を放棄するよう求めている。
我々だけではない。このコメントの草稿を読んで、我々のメッセージに賛同する人は署名してほしいと呼びかけたところ、最初の24時間以内に250人が署名してくれた。その1週間後には、800人以上の署名者が集まった。すべての署名者は、統計的モデリングに依存する分野で現在または過去に研究していることを示す学歴やその他の情報を確認した(署名者のリストと最終数は、補足情報を参照してほしい)。この中には、50カ国以上、南極大陸を除く全大陸の統計学者、臨床・医学研究者、生物学者、心理学者が含まれている。ある賛同者は、これを「統計的有意性の軽率な検定に対する外科的攻撃」、「より良い科学的実践を支持する声を登録する機会」と呼んでいる。
我々はP値の禁止を要求しているのではない。また、ある特殊な用途(例えば、製造工程がある品質管理基準を満たしているかどうかの判断など)において、P値を判断基準として使用することができないと言っているわけでもない。また、弱い証拠が突然信頼できるようになるような、何でもありの状況を提唱しているわけでもない。むしろ、数十年にわたる他の多くの人々と同様に、我々は、ある結果が科学的仮説を否定するのか支持するのかを決定するために、従来の二項対立的な方法でP値を使用することをやめるよう求めているのである5。
カテゴライズをやめる
「統計的に有意なもの」と「統計的に有意でないもの」に分けることで、人々はそのように割り当てられた項目がカテゴリー的に異なるものであると考えるようになる6-8。同じ問題は、頻度論的、ベイズ的、その他にかかわらず、二項対立を含む統計的代替案のもとでも発生する可能性が高い。
残念ながら、統計的有意性の閾値を超えれば、その結果が「本物」であることを示すのに十分であるという誤った信念が、科学者や雑誌編集者をそのような結果に偏らせ、それによって文献を歪めてしまっているの。統計的に有意な推定値は、大きさが上方に偏り、潜在的に大きな影響を与えるが、統計的に有意でない推定値は、大きさが下方に偏っている。その結果、有意性のために選ばれた推定値に焦点を当てた議論は、偏ったものになる。その上、統計的有意性に固執することで、研究者は、ある望ましい(あるいは単に発表できる)結果に対しては統計的有意性をもたらし、医薬品の潜在的副作用のような望ましくない結果に対しては統計的非有意性をもたらすデータや方法を選択し、それによって結論を無効化することを助長する。
試験の事前登録と、すべての解析結果の公表を約束することは、これらの問題を軽減するために多くのことを行うことができる。しかし、事前登録された試験の結果であっても、解析計画に必ず残される決定により、偏りが生じることがある9。これは、どんなに良い意図をもってしても起こることだ。
繰り返すが、我々はP値、信頼区間、その他の統計的尺度の禁止を提唱しているわけではなく、あくまでもカテゴリー的に扱うべきではないということだ。これには、統計的に有意か否かの二項対立や、ベイズ係数などの他の統計的尺度に基づく分類が含まれる。
このような「二項対立」を避ける理由の一つは、P値や信頼区間を含むすべての統計値は、当然ながら研究ごとに異なり、しばしば驚くほど異なるからである。実際、ランダムな変動だけで、P値は0.05の閾値の両端に収まるのをはるかに超えて、大きな格差が容易に生じる。例えば、研究者がある真の効果について2つの完全な再現研究を行い、それぞれが80%の検出力でP < 0.05を達成できたとしても、一方がP < 0.01、他方がP > 0.30であってもそれほど驚くことではないだろう。P値が小さくても大きくても、注意が必要である。
我々は、不確実性を受け入れることを学ばなければならない。そのための現実的な方法の一つは、信頼区間を「両立性区間」と改名し、過信を避けるように解釈することだ。具体的には,著者は,区間内のすべての値,特に観察された効果(または点推定値)と限界値の実際的な意味を説明することを推奨する.その際、区間を計算するために使用された統計的仮定を考えると、区間の限界の間のすべての値は、データと合理的に適合していることを思い出すべきである7,10. したがって、区間内のある特定の値(ヌル値など)を「示されている」として特別視することは、意味がないのである。
我々は、プレゼンテーション、研究論文、レビュー、教育資料において、このような無意味な「ヌルの証明」や非関連性の主張を見るのは、正直言ってうんざりしている。帰無値を含む区間には、実用上重要性の高い非帰無値の値も含まれることが多い。つまり、区間内のすべての値が実用上重要でないと判断した場合、「我々の結果は重要な効果がないことと最も適合している」というような言い方ができるかもしれない。
互換性区間について話すときは、4つのことを心に留めておくこと。第一に、区間は、仮定が与えられた場合に、データに最も適合する値を与えるからと言って、その外の値が適合しないわけではなく、単に適合度が低いだけである。実際、区間のすぐ外側の値は、区間のすぐ内側の値と実質的な差はない。したがって、区間がすべての可能な値を示していると主張するのは誤りである。
第二に、仮定のもとでは、区間内のすべての値が等しくデータに適合するわけではない。点推定値が最も適合性が高く、その付近の値は限界付近の値よりも適合性が高い。これが,著者が大きなP値や広い区間を持つ場合でも,その区間の限界値を議論するだけでなく,点推定値を議論するように促す理由である.例えば、上記の著者はこう書くことができただろう。以前の研究と同様に、我々の結果は、抗炎症薬を投与された患者において、新たに心房細動を発症するリスクが20%増加することを示唆している。それにもかかわらず、リスク差は3%の減少、つまり小さな負の関連から48%の増加、つまりかなりの正の関連まであり、我々の仮定を考慮すれば、我々のデータとも合理的に適合するものである』。点推定値を解釈し、その不確実性を認めつつ、「差はない」という誤った宣言をせず、過信した主張をしないようにすることだ。
第三に、0.05の閾値と同様に、区間を計算するために使われるデフォルトの95%は、それ自体が恣意的な慣習である。これは、計算された区間自体が真の値を含む可能性が95%あるという誤った考えと、これが確信に満ちた決定の根拠であるという漠然とした感覚に基づいている。用途によっては、異なる水準が正当化されることもある。また、抗炎症薬の例のように、区間推定が課す二項対立が科学的基準として扱われる場合、統計的有意性の問題を永続させる可能性がある。
最後に、そして最も重要なことは、謙虚になることだ。互換性評価は、区間を計算するために使用した統計的仮定の正しさにかかっている。実際には、これらの仮定はせいぜいかなりの不確実性に左右される程度である7,8,10。これらの仮定をできるだけ明確にし、例えば、データをプロットしたり、代替モデルを当てはめたりして、可能なものはテストし、すべての結果を報告する。
統計が示すものが何であれ、結果の理由を示唆するのは構わないが、好みの説明だけでなく、さまざまな可能性のある説明について議論すること。推論は科学的であるべきで、それは単に統計的なものをはるかに超えるものである。背景となる証拠、研究デザイン、データの質、基礎となるメカニズムの理解といった要素は、P値や区間といった統計的尺度よりも重要であることが多いのである。
統計的有意性を削除することに対して最もよく耳にする反論は、イエスかノーかの判断をするために必要であるというものである。しかし、規制、政策、ビジネス環境においてしばしば必要とされる選択においては、すべての潜在的な結果のコスト、便益、可能性に基づく決定の方が、統計的有意性だけに基づく決定よりも常に優れている。さらに、ある研究アイデアをさらに追求するかどうかの決定には、P値とその後の研究の結果の可能性との間に単純な関連性はないのである。
統計的有意性の削除はどのように行われるのだろうか?我々は、方法論のセクションやデータ集計がより詳細で微妙なものになることを望んでいる。例えば、区間の下限と上限を明示的に説明するなどして、著者は推定値とその不確実性を強調することになるだろう。また、有意性検定に依存しない。P値が報告される場合は、統計的有意性を示す星や文字などの装飾をつけず、二項対立の不等式(P < 0.05 or P > 0.05)ではなく、常識的な精度(例えば、P = 0.021 or P = 0.13)で示されるようになる。結果を解釈するか発表するかの決定は、統計的な閾値に基づいて行われることはない。人々は統計ソフトに費やす時間を減らし、考えることにもっと時間を費やすようになるだろう。
統計的有意差を廃止し、信頼区間を互換性区間として使用するようにという我々の呼びかけは万能ではない。多くの悪習を排除することはできても、新しい悪習を導入する可能性は十分にある。したがって、統計的乱用がないか文献を監視することは、科学界にとって継続的な優先事項であるべきである。しかし、カテゴリー分けを根絶することは、過信的な主張、「差がない」という不当な宣言、オリジナルと再現研究の結果が高度に適合している場合の「再現の失敗」という不合理な発言を阻止するのに役立つだろう。統計的有意性の誤用は、科学界と科学的助言に依存する人々に多くの損害を与えてきた。P値、区間、その他の統計的尺度はすべてその役割を担っているが、統計的有意性についてはそろそろやめるべきだろう。