
Sample size calculation
Prashant Kadam、Supriya Bhalerao1
はじめに
臨床試験を計画する上で重要なことの一つに、サンプルサイズの算出がある。どのような研究においても,人口全体を対象とすることは,当然ながら現実的ではない。そこで,母集団の中から,数(サイズ)は少ないが,母集団を十分に代表する参加者を選び,得られた結果から母集団に関する真の推論ができるようにする。この個人の集合は「サンプル」と呼ばれる。
統計学の文脈では、”母集団 “は人々の完全な集合(例えば、インド人)と定義され、”対象集団 “は、介入を研究したい特定の臨床的および人口統計学的特徴を持つ個人のサブセット(例えば、男性、年齢45~60歳、血圧が収縮期140mmHg、拡張期90mmHg)であり、”サンプル “は対象集団のさらにサブセットであり、研究に含めたいと考えている。したがって、「サンプル」とは、全体を代表する部分、断片、セグメントのことである。
サンプルの属性
- 選ばれた母集団の中のすべての人に、サンプルに含まれる機会が平等に与えられるべきである。
- 理想的には、ある参加者の選択が他の参加者の選択の機会に影響を与えるべきではない(したがって、私たちはサンプルを無作為に選択しようとする – したがって、無作為抽出はサンプルやそのサイズを説明するものではなく、サンプルの選択方法を説明するものであることに注意することが重要だ)。
今回のテーマであるサンプルサイズとは、簡単に言えば、サンプルに含まれる参加者の数のことである。臨床研究を開始する前にサンプルサイズを定義することで、結果の解釈に偏りが生じないようにするための、統計学上の基本的な原則である。研究に参加する被験者が非常に少ない場合、このサンプルは対象となる母集団のサイズを表さないため、結果を母集団に一般化することはできない。さらに、試験群間の差を検出できない可能性もあり、その研究は非倫理的なものとなる。
一方、必要以上に多くの対象者を調査すると、より多くの人が介入のリスクにさらされることになり、研究は非倫理的なものとなり、研究者の時間を含む貴重な資源を浪費することにもなる。
したがって,適切なサンプルサイズの算出は,あらゆる臨床研究において極めて重要であり,倫理的・科学的に妥当な結果を得るために必要な最適な被験者数を算出するプロセスでもある。この記事では、サンプルサイズを算出するための原理と方法について説明する。
一般的に、あらゆる研究のサンプルサイズは以下に依存する:[1]。
- 許容できる有意水準
- 研究の検出力
- 期待される効果の大きさ
- 母集団における基礎的な事象の割合
- 母集団における標準偏差
また、最終的なサンプルサイズを算出する際に考慮すべき要素としては、予想される脱落率、不均等な配分比率、研究の目的とデザインなどがある[2]。
有意差のレベル
誰もが知っている「p」の値。これは「有意水準」のことで、研究を開始する前にこの「p」の許容値を設定する。例えば、「p<0.05を有意と認める」というのは、その結果が偶然に観察されたものであり、私たちの介入によるものではない確率が5%であることを受け入れる準備ができているということである。言い換えれば、実際には差がないのに、100回のうち5回は差が検出されても構わない(つまり、「偽陽性」の結果が出ても構わない)ということである。従来、p値が5%(p=0.05)または1%(p=0.01)の場合、つまり5%(または1%)の確率で有意な効果があると誤って報告されることを受け入れてた。
パワー
時には、全く逆に、実際には差があるのに差を検出できないという別のタイプの誤りを犯すことがある。これは、上述した、実際には差がないのに偽陽性の差を検出してしまうタイプIエラーに対して、偽陰性の差を検出してしまうタイプIIエラーと呼ばれる。帰無仮説を正確に受け入れたり棄却したりするのに十分な検出力を持つ研究にするためには、どの程度の偽陰性率を受け入れられるかを決めなければならない。
この偽陰性率は、誤って陰性と報告された陽性例の割合であり、統計学ではβという文字で呼ばれる。研究の「検出力」は、(1 -β)に等しく、実際には差があるのに差を検出できない確率である。研究の検出力は,Type IIエラーを犯す可能性が低くなるほど大きくなる。
通常、ほとんどの研究では検出力を80%としている。これは、5回に1回(つまり20%)は実際の差を見逃すことを許容していることになる。重要な研究や大規模な研究では、「偽陰性」の可能性を10%に抑えるために、検出力を90%に設定することもある。
期待される効果量
「効果の大きさ」の概念は、日常的な例から理解することができる。あるダイエットプログラムによる平均的な体重減少が20kgで、別のダイエットプログラムによる平均的な体重減少が10kgであれば、絶対的な効果の大きさは10kgとなる。同様に、ある教育活動によって、試験の点数が10%向上したと主張することもできる。ここで、10kgと10%は、主張する効果の大きさを示す指標である。
統計学では、対照群の変数の値と被験薬群の値との差を効果量という。この差は、絶対的な差や相対的な差で表すことができ、例えば、上記の体重減少の例では、対照群の体重減少が10kg、試験群の体重減少が20kgであれば、絶対的な効果量は10kg、試験介入による相対的な減少量は10/20,つまり50%となる。
以前に報告された研究や前臨床研究に基づいて、効果の大きさを推定することができる。ここで重要なのは、試験群間の効果量が大きければ、研究に必要なサンプルサイズは小さくなり、試験群間の効果量が小さければ、必要なサンプルサイズは大きくなるということである。観察研究の場合、例えば、喫煙と肺がんの関連性を見つけたい場合、先行研究で効果量が大きいことがわかっているので、この効果を証明するためには、より小さなサンプルが必要になる。一方、喫煙と脳腫瘍の関連性を調べようとした場合、「効果」が不明であったり、小さかったりするため、関連性を検出するために必要なサンプルサイズは大きくなる。
集団における基礎的事象率
サンプルサイズを計算する際には、調査対象となる疾患の母集団における基本的なイベントレート(有病率)が非常に重要になる。これは、有意性や検出力のレベルとは異なり、慣習的に選択されるものではない。むしろ、過去に報告された研究から推定される。時には、試験開始後に全体のイベントレートが予想外に低いことが判明し、統計的に注意しながらサンプルサイズを調整しなければならないこともある。
標準偏差(SDまたはσ)
標準偏差とは、データの分散性やばらつきを表す指標である。調査員はサンプルサイズを計算する際に、調査対象となる測定値のばらつきを予測する必要がある。母集団がより均質で、そのために分散や標準偏差が小さい場合に、より小さなサンプルを必要とする理由は容易に理解できる。体重に対する介入の効果を研究していて、体重が45kgから 100kgの範囲の集団を考えているとする。当然、このグループの標準偏差は大きく、介入の違いを検出するためには、より大きなサンプルサイズが必要となる。さもなければ、2つのグループ間の差は、分散のために2つのグループ間の固有の差によってマスクされてしまう。一方、体重が80kgから 100kgの集団からサンプルを採取した場合は、当然、よりタイトで均質なグループが得られるため、標準偏差が小さくなり、その結果、サンプルサイズが小さくなる。
サンプルサイズの計算
サンプルサイズの計算には、データの種類や研究デザインによっていくつかの方法がある。サンプルサイズは以下の式で算出される。
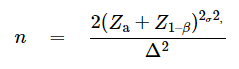
ここで、nは必要なサンプルサイズである。Za
Zαについては、Zは以下のような定数(受け入れられたα誤差や片側効果か両側効果かに応じて慣習的に設定される)である。
| α-error | 5% | 1% | 0.1% |
| 2-sided | 1.96 | 2.5758 | 3.2905 |
| 1-sided | 1.65 | 2.33 |
Z1-,βの場合、Zは以下のように研究の検出力に応じて慣習的に設定される定数である。
| Power | 80% | 85% | 90% | 95% |
| Value | 0.8416 | 1.0364 | 1.2816 | 1.6449 |
上述の式において、σは標準偏差(推定値)Δは必要とされる2つの介入の効果の差(推定効果量)である。
これにより、対照臨床試験における各アームのサンプル数が求められる。
例
今号のJournalには、片頭痛患者におけるアーユルヴェーダ治療法AyTPの効果を、オープン非対照試験デザインで記述した論文が掲載されている[3]。もし誰かが、アーユルヴェーダの介入の効果を、VASで測定した頭痛の標準治療と比較する無作為化対照試験デザインを用いてこの結果を確認したいと考えた場合、どのようにサンプルサイズを計画すればよいであろうか?
上述したように、以下の値が必要である。Zα、Z1-β、σ、標準偏差(推定値)Δ、2つの介入の効果の差。ここでは、p<0.05を許容範囲とし、80%の検出力を持つ研究を仮定する。上記の表を使用して、以下の値を得る。Zαは、1.96である(この場合、結果が双方向である可能性があるため、両側検定を使用する)。Z1-β、は0.8416である。標準偏差は(発表された論文のデータに基づいて)約0.7となる。Δについては、アーユルヴェーダ療法で35%の効果が得られたと論文に記載されている。以前、スマトリプタン50mgで頭痛が50%改善することが報告されている[4]。したがって、効果量は15%(すなわち0.15)となる。
新しい研究のサンプルサイズは
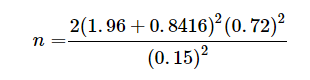
=362/アームとなる。
10%の脱落率で計算すると、2つの治療法の間に差があるかどうかをある程度確信を持って言えるようにするには、各アームにつき約400人の患者を完了する必要がある。
計算されたサンプルサイズの限界
上記の公式を使って計算されたサンプルサイズは、いくつかの慣習(Type IとIIのエラー)といくつかの仮定(効果量と標準偏差)に基づいている。
サンプルサイズは、常に研究を開始する前に計算する必要があり、可能な限り研究期間中に変更してはいけない。
また、サンプルサイズの計算は、管理上の問題やコストなど、いくつかの現実的な問題にも影響される。