
Contents
On the Controllability of Artificial Intelligence: An Analysis of Limitations
ロマン・V・ヤンポルスキー Roman V. Yampolskiy
米国ルイビル大学
2022年3月09日受領、2022年3月31日受理、2022年5月24日掲載
要旨
人工知能の発明は、人類の文明の軌道に変化をもたらすと予測されている。このような強力な技術の恩恵を享受し、落とし穴を回避するためには、それを制御できることが重要である。しかし、人工知能やその発展型である超知能を制御できる可能性は、まだ正式に確立されていない。本論文では、高度なAIを完全に制御することができないことを示す複数の領域からの議論とその裏付けとなる証拠を提示する。AIの制御不能がもたらす結果について、人類の未来とAIに関する研究、そしてAIの安全性とセキュリティに関して議論する。
キーワード: AI安全性、制御問題、より安全なAI、制御不能性、検証不能性、Xリスク
1 はじめに
過去10年間における人工知能(AI)[1-6]の前例のない進歩は、AIの複数の失敗[7,8]や二重使用の事例[9]と同時に、高度な能力を持つ機械を作るだけでは不十分であり、知的機械が人類にとって有益であることを確認することがさらに重要である[10]という認識を引き起こした。このため、一般にAIの安全性とセキュリティとして知られる新しい研究分野[12]が誕生し、この問題のさまざまな側面について毎年何百もの論文や書籍が出版されている[13-31]。
しかし、コンピュータサイエンスでは、問題を解決するためにリソースを投入したり、どのようなアプローチを試すかを決定する前に、まず問題が解決不可能な問題のクラスに属さないことを示すのが標準的なやり方である[32, 33]..。残念ながら、私たちの知る限り、AI制御問題が原理的にも、ましてや実践的にも解決可能であることを示す数学的証明や厳密な論証さえ発表されていない。あるいは、GansがBostromを引用して言うように、「これまでのところ、AIの研究者や哲学者は、[悪い]結果が起こらないようにする制御の方法を思いつくことができなかった. 」 [34] チョンはこう宣言する[35]: 「本当の問題は、AIの制御問題に対する救済策が見つかるかどうかである。これはまだわからないが、制御理論家や技術者、つまり私たちのコミュニティの研究者が制御問題に対して重要な貢献をしていることは、少なくとももっともらしいと思われる」ユドコフスキーは、制御問題が解決不可能である可能性を考慮しているが、そのような重大な制限を受け入れる前に、問題を詳細に研究すべきだと正しく主張している。私が遭遇する共通の反応の一つは、人々がすぐにフレンドリーなAIは不可能だと宣言することである。なぜなら、十分に強力なAIは、自分自身のソースコードを改変して与えられた制約を破ることができるだろうからだ。しかし、不可能と断言する前に、その課題について考え、可能な限り技術的に詳しく調べるべきである。特に、その答えに大きな賭けがかかっている場合は。よく調べず、創造力を働かせずに、解決不可能と断言するのは、人間の創意工夫に対して失礼なことである。空気より重い飛行機を作れない、核反応から有用なエネルギーを得られない、月に飛べないなど、あることを「できない」と言い切ることは、非常に強い主張である。このような発言は普遍的な一般化であり、問題を解決するためにこれまで、あるいはこれから考え出されるであろうあらゆるアプローチに対して定量化される。
普遍的な量化詞を偽るには、たった一つの反例が必要である。友好的な(あるいはフレンドリーな)AIは理論的に不可能であるという声明は、あらゆる可能な心の設計とあらゆる可能な最適化プロセスをあえて定量化している。この時点で、友好的なAIが人間的に不可能である理由は、漠然としたもっともらしい理由がいくつもある。また、この問題は解決可能であるにもかかわらず、誰も時間内に解決しようとしない可能性がまだ高い。しかし、特に利害関係を考慮すると、そう簡単にこの挑戦を見送るべきではない。」[36]
ユドコフスキーはさらに、不可能という言葉の意味を明確にしている: 「不可能」という言葉には2つの用法があることに気がついた:
- 1. 特定の公理を条件として不可能であることを数学的に証明すること。
- 2. 『その方法は見当たらない』
言うまでもなく、私自身の「不可能」という言葉の使い方はすべて2番目のタイプであった。[37]
この論文では、最初のタイプの不可能性に注意を向け、厳密な分析と論証、そして可能な限り数学的証明を提供することを試むが、残念ながら、AI制御問題は解決不可能であることを示し、私たちが望むことができる最善のものはより安全なAIだが、究極的には100%安全なAIではなく、人類に関連する人類存亡リスクの領域では十分な安全レベルではないことを示した。
2 AI制御問題
AI制御問題は人類が直面する最も重要な問題である可能性が示唆されている[35, 38]が、その重要性にもかかわらず、理解度が低く、定義が不明確で、十分に研究されていないのが現状である。原理的には、ある問題は解決可能、解決不可能、決定不可能、部分的に解決可能である可能性があるが、現在のところ、AI制御問題の状況は確信を持ってわかっていない。ある種の状況では制御が可能である可能性が高いが、ほとんどの場合、部分的な制御では不十分である可能性も高い。このセクションでは、問題の正式な定義を提供し、その変形を分析することで、正式な定義を使用してAI制御問題の状況を判断できるようにすることを目標とする。
2.1 制御問題の種類
AI制御問題の解決は、AI安全・安心分野の決定的な課題であり、難問だ。この問題の理解が曖昧な理由の一つは、この問題のサブタイプが多数存在することに基づいている。狭域AI(NAI)の制御、あるいは人工一般知能(AGI)[39]、人工超知能(ASI)[39]、再帰的自己改善(RSI)AI[40]について話すことができる。例えば、NAI安全性には公平性、説明責任、透明性(FAT)の問題が含まれ[41]、静的NAIや学習可能NAIにさらに細分化される可能性がある。(あるいは、決定論的システムと非決定論的システム。決定論的システムの制御は、より簡単で理論的に解決可能な問題である)。ある懸念はより高度なシステムに拡張されることが予測されるが、他の懸念はそうではないかもしれない。同様に、安全やセキュリティの問題は、短期的なものから長期的なものまで、予想される到達時期に基づいて分類されるのが一般的である[42]。
しかし、計算の複雑さ[43]、暗号[44]、リスク管理[45]、敵対的ゲームプレイ[46]と同様に、AI安全においても、問題に完全に取り組むために必要なリソースの下限を与えるので、最も興味深いのは最悪のケースである。したがって、本稿では制御問題のすべての変形を分析するのではなく、再帰的に自己改善する超知能(RSISI)という最悪のケースに焦点を当てる。RSISIは最も難しい問題であるため、もしこの問題を解くことができれば、より単純な問題を扱うことができるようになるはずだ。また、技術の進歩に伴い、その最も難しいケースに対応せざるを得なくなることも重要である。最悪のケースを解決するチャンスは一度しかないが、より簡単な制御問題には何度も挑戦できる可能性があると指摘されている[12]。
私たちは、最悪のシナリオ[47]が、厄介なサプライズ[48]の形で実現しうる未知の未知数[40]を含まないかもしれないことを明確に認識しなければならない。「最悪のシナリオは決して最悪のケースではない」 [49]」ということである。例えば、人類にとって最悪の結末は絶滅であると伝統的に想定されているが、AIの安全性の文脈では、これは苦難のリスクを考慮に入れておらず [50-54]、設計上悪意があるというよりは欠陥のある超知能システム [55]の問題だけを想定している。同時に、概念実証として制御問題の単純な変種を解き、安全機構のツールボックスを構築することも有用であろう。例えば、現在のツールでも、静的な三目並べプログラムのようなNAI制御の簡単なケースでは、AIはソースコードレベルで検証することができ[56]、あらゆる意味で完全に制御可能、説明可能、安全であることを確認するのは簡単だ。異なるアベレージケース[57]やイージーケースの制御問題に対する可解性の解析は、今後の課題として残しておく。最後に、複数のAIを安全にすることは容易ではなく、困難だ。したがって、シングルトン[58]シナリオは単純化した仮定であり、1つのAIを安全にすることが不可能であることが示されれば、マルチASI世界のより複雑なケースを分析する必要性を回避することができる。超知能に対する潜在的な制御方法論は、能力制御と動機付け制御に基づく方法の2つに大別される[59]。能力制御法は、ASIシステムを制限された環境に置く [38, 60-62]、遮断機構を追加する[63, 64]、またはトリップワイヤを設ける[38] ことにより、ASIシステムが行うことができる害を制限しようとする方法である。動機付け制御法は、ハンディキャップのある能力制御装置がない場合でも、害を及ぼさないことを望むようにASIを設計しようとするものである。能力制御法は、せいぜい一時的な安全対策であり、ASI制御問題の長期的な解決策にはならないことが一般に認められている[59]。また、動機付け制御は、配備後ではなく、設計/実装段階で追加する必要があると思われる。
2.2 形式的な定義
知能の定義[65]を形式化するために、Leggら[66]は関連する多数の定義を収集し、曖昧だった知能の概念に対して非常に有効な形式化を合成することができた。私たちは、まずAI制御問題(および関連用語であるフレンドリーAI、AIセーフティ、AIガバナンス、倫理的AI、アライメント問題)の公表された定義を収集し、それらを用いて独自の形式化を開発することにより、同じことを試む。
AI制御問題の提案された定義(順不同):
- 「友好性(人間に危害を加えないという願望)は最初から設計されているべきだが、設計者は自らの設計に欠陥があるかもしれないということと、ロボットは時間とともに学習し進化していくということの両方を認識すべきである。つまり、チェック・アンド・バランスのシステムの下でAIシステムを進化させるメカニズムを定義し、そのような変化に直面しても友好的であり続けるような効用機能をシステムに与えることである」[67]
- 「嫌なことをしないようにAIを構築する」[68]
- AIの初期ダイナミクスは、「..私たちがもっと知っていたら、もっと速く考えていたら、もっと私たちが望んでいたような人間だったら、もっと一緒に育っていたら、私たちの願いは発散ではなく収束し、私たちの願いは干渉ではなく凝集し、外挿は外挿したいままに、解釈は解釈したいままに」実装すべきである。[36]
- 「AIは『正しいことをする』」[36]
- 「私たちがその問題についてじっくり考えたら、AIが達成することを望んだであろうことを達成する」[59] [59]
- 「超知能が行うであろうことをどのように制御するかという問題. 」[59]
- 「コントロール問題のグローバルバージョンは、すべての高度な人工知能を普遍的に数値化して、そのどれもが人間のコントロールから逃れることができないようにする。その根拠は、脅威となるのは1つだけでいいというものである。これは、その範囲に関する修飾語なしで元の制御問題に言及する場合、最も一般的な解釈である。」[69]
- 「落とし穴を避けながらAIの利点を享受する」 [11]
- 「AIは、人類に存亡の危機をもたらす、人間よりも知的で強力な未来の機械を制御する問題である」[35]
- AIは、「利害関係者の好みのどのような組み合わせとも相容れない好みのために最適化されていない場合、すなわち、長期的には最適化の暗黙の好みに従って資源を使用することが利害関係者にとってパレート効率的でないようなものである」とアライメントがある。[70]
- 「エージェントが人間の価値観に沿った行動をするようにすること.」[71, 72]
- 「任意に高度な知能を持つシステムが、人間の制御下に厳密に留まることを保証する方法」[73]
- 「AIアライメント問題は、人間の報酬関数Rに対して実行される計画アルゴリズムpと両立する(同じ結果を生む)方針πをエージェントが学習するという観点で[述べることができる]。」[70]
- 「[AI]は悪いことをしたがらない」[74]
- 「[AI]は人間の価値観を学習し、そしてインスタンス化したい」[74]
- 「強力なAIシステムが、人間のユーザーにとって望ましい方法で確実に行動することを保証する.」[75]
- 「AIシステムは、その人間の操作者が意図するものと大まかに一致するような行動をとる」 [75]
- 「AI安全性:AI、特に強力なAIがもたらすリスクを低減すること。誤用、堅牢性、信頼性、セキュリティ、プライバシー、その他の分野の問題を含む。(AI制御を包含する)AI制御:AIシステムが正しいことをしようとすること、特に間違ったことを有能に追求しないようにすること。AIセキュリティとほぼ同じ問題群。価値観の調整:人間の好みや価値観を共有するAIシステムを構築する方法を理解することで、通常、人間からそれを学習する。(AIコントロールの一側面。)」[76]
- 「フィードバック、適切な説明、訴えのための適切な機会を提供するAIシステム。私たちのAI技術は、人間の適切な指示とコントロールに従う」 [77]
- 「強力な人工知能に、私たち人間の望むことをさせる問題」 [78]
- 「AI研究の目標は、無指向性の知能ではなく、有益な知能を作ることであるべきだ。AIシステムは、その運用期間を通じて安全・安心であるべきであり、適用可能で実現可能な場合には、検証可能であるべきである。高度に自律的なAIシステムは、その運用期間中、目標や行動が人間の価値観と一致することが保証されるように設計されるべきである。人間は、人間が選んだ目的を達成するために、AIシステムに意思決定を委ねる方法と委ねるかどうかを選択すべきである。」[79]
- AGIが超知的になる前に、AGIができること(能力)ややりたいこと(動機)をコントロールすることによって、人間が人類存亡リスクに対して保証する方法がない場合に、コントロール問題が発生する。[34]
- 「制御問題は、プリンシパルエージェント問題の超知能バージョンであり、プリンシパルは、(異なる目標を持つ)エージェントがプリンシパルの利益のために行動することを保証する方法についての決定に直面する。人間の初期エージェントは、その効用関数をAIの報酬関数として記述し、プログラムすることができないため、制御問題に直面する」[34]
- 「制御問題は、以下の3つの条件が満たされたときに発生する:
- 1. 初期エージェントとAIが同じ利益を持たない
- 2 AIにとって最適なリソースのレベルは、初期エージェントと同じかそれ以下の強さのエージェントが持つリソースのレベルを超える
- 3 AIのパワーは、初期エージェントのパワーよりも大きい」[34]
- 制御問題のサブタイプ(再帰的またはメタCP)は、「AIが、より大きな力を持つAIや、より大きな力を蓄積できるAIにスイッチした場合、AI自身が制御問題に直面するかもしれない」と予測する。[34]
- 「人間/AIコントロールとは、AIシステムを含む状況のコントロールを保持または回復する人間の能力のことで、特に、人間がシステムの設計者が意図した通常の手段でAIシステムをうまく理解したり指示したりすることができない場合において、その能力を指す。」[80]。[80]
- 「.. 作成者を助けるような超知能エージェントを構築し、作成者を害するような超知能を不用意に構築することを避ける方法 」[81]
- 「超知能が破滅的に誤動作するのをうまく防ぐために、プログラマーはどのような事前予防策を講じることができるか」[81]
- 「最初の超知能に人間に優しい目標を植え付け、プログラマーを助けたいと思わせるようにする。」[81 [81]
- 「ユーザーの意図に沿った行動をするエージェントを作るにはどうしたらいいか?」 [82]
- 「人間に危害を加えない高度なAIシステムをいかに構築するかという課題 」[83]
- 「知能が大幅に向上した機械を含む世界で、人間がその覇権と自律性を維持できるかという問題」 [84]
- 「走らせると良い結果を生むAI」 [85]
- 「成功とは、アライメントのない知能が決して生み出されないことを保証することである」[85]
- 「あなたが望むことをしようとするAIを構築することに加えて、[さらに] .AIが後継者を構築するときに、それがうまくいくことを保証すること」[86]
- 「AIのアライメントという技術的な問題を、後から好きな原理や価値観のシステムを『ロード』できるような形で解決する。」[87]
- 「超知的なAIシステムは、注意深く設計し、使用しなければ、リスクをもたらす可能性がある。例えば、多くのタスクは、私たちが他の方法で使用されることを望む物理的資源を支配することによってより良く達成することができ、超知的なシステムはこれらの資源を獲得することに非常に効果的である可能性がある。超知的なシステムが私たちよりもはるかに大きな力を持つようになれば、私たちにはほとんど資源が残らなくなる可能性がある。もし、超知能AIシステムが私たちの価値観を尊重して意図的に作られたものでなければ、そのタスクの追求のために私たちのニーズを無視し、地球規模の大災害や人類滅亡につながる可能性さえある。超知能制御問題とは、こうしたリスクを理解し管理する問題である。[88]
- チューリング、ウィーナー、ミンスキーなどは、高度に知的な機械をうまく利用するためには、そのような機械の目的が人間の目的とうまく一致するようにすることが必要であると指摘している。機械知能の認知能力が多様化し、増幅されるにつれて、社会にとって長期的な制御の問題が生じる。どのような数学的、工学的原理によって、人間よりも実質的に知的で、その意味で強力な存在に対して、無期限に十分な制御を維持できるのか?強力な機械知能を導入する前に、そのようなシステムの安全性を人類に保証するために提供できる正式な解決策はあるのだろうか?[89]
Formally Stating the AI Alignment Problemの中でWorleyは次のように書いている[70]:
AIアライメントの問題は、人間の価値観に沿ったAIを作り出すことだが、このことは、人間の価値観に沿うとはどういうことなのか、という問いに私たちを導くだけだ。さらに、人間の価値観はともかく、どんな価値観とも一致するというのはどういうことなのか?AIが人間の望むことをするとき、人間の価値観に合致していると答えようとすることもできるが、これはさらなる疑問を招くだけである: ある特定の人間が望むことを、他の特定の人間が望まないなら、AIは望まないことをするのだろうか?現在のテクノロジーは、私たちが求めることはやっても、私たちが望むことはやらないことが多いのに、AIはどうやって人間の望むことを知るのだろう?また、人間の価値観と自分の価値観が対立した場合、AIはどうするのだろうか?
これらの問いに答えるには、AIがアライメントすることの意味をより詳細に理解する必要がある。したがって、本研究の目標は、AIアライメント問題の正確で正式な数学的記述を提示することである。
人類が一貫した選好を持たない可能性があるため、UHを構成することができないかもしれない。前者の問題をとりあえず無視しても、後者は、私たちが連携するAIに人類と全く同じ効用関数を持たせることを望まず、人類と連携または互換性のあるものだけを持たせることを意味する。[70]
形式的には、次のように定義している[70]: 「エージェントAとH、選択肢の集合X、効用関数U A:X RとU H:X Rが与えられたとき、すべてのx,y Xについて、U H(x) U H(y) implies U A(x) U A(y)ならばAはX上でHと整合しているという。”AIが明示的な効用関数なしで設計されている場合、弱順序性選好の観点から次のように再定義することができる: 「エージェントAとH、選択肢の集合X、X上の選好順序「A」と「H」が与えられたとき、すべてのx,y Xに対して、x ” Hyがx ” Ayを暗示する場合、AはX上でHとアライメントしていると言う。」[70] さらに分析すると、Worleyはこの問題を次のように定義している[70]: 「AはHの価値観を学ばなければならず、HはAがHの価値観を共有していると信じられるほどAについて知っていなければならない」
The Control Problem [President’s Message]でChongは[35]と書いている:
どうやら、制御の用語では、AIの制御問題は、機械の制御性の欠如によってもたらされるリスクから生じるようだ。より具体的には、ここでいうリスクとは、コントローラーの不安定性(のようなもの)である。要するに、制御の問題は、制御装置を制御する問題なのである。確かにこれは、私たちの制御の分野では正当な問題である。実際、少なくとも原理的には、制御の教科書に載っているような制御の問題と大差はない。
上記に挙げた定義を統合し、形式化することで、私たちはAI制御問題を次のように定義する: 優れた知能の恩恵を受けながら、人類が安全にコントロールし続けるにはどうしたらよいか?これは、AIの安全性とセキュリティの分野の基本的な問題であり、それ自体、知的システムを改ざんから守り、関係するすべてのステークホルダーにとって安全なものにすることに専念していると言えるだろう。バリューアライメントは、安全・安心なAIを実現するためのアプローチとして、現在最も研究が進んでいる。安全やセキュリティのようなファジーな概念は、長年の研究にもかかわらず、非AIソフトウェアでさえも正確にテストしたり測定したりすることが難しいことは注目に値する[90]。せいぜい、完全に安全か、同じようなタスクを実行する平均的な人間と同じくらい安全かを区別することができる程度だろう。しかし、社会は、たとえそれが人間のパフォーマンスに典型的な頻度で起こるとしても、あるいはそれ以下の頻度で起こるとしても、機械のミスを許容することはまずない。私たちは、機械がより良い結果を出すことを期待し、そのような高い能力を持つシステムに関しては、部分的な安全性を容認することはない。AIによる影響(プラスとマイナスの両方)は、AIの能力と強く相関している。潜在的に存在する影響に関しては、部分的な安全性というものは存在しない。
制御問題に対する素朴な初期理解では、人間の命令に正確に従う機械を設計することを提案するかもしれない[91-93]が、よく考えてみると、矛盾する/逆説的な命令、人間の言語の曖昧さ、倒錯したインスタンス化[94]の問題の可能性から、それは望ましいタイプの制御ではない、ただし人間のフィードバックを統合する何らかの能力は望ましいかもしれない[95]。解決策として必要なのは、AIがより理想的なアドバイザー[96]の役割を果たし、直接命令の誤訳や悪意のある命令の可能性の問題を回避することであると考えられている。
私たちは、起こりうる制御の種類を明示的に挙げ、それぞれの制御をAIの応答で説明することができる。例えば、スマートな自動運転車の文脈で、人間が「車を止めてほしい!」と直接命令した場合、AIは以下の4つのタイプのコントロールのいずれかに属していると言えるだろう:
- 明示的な制御 – 高速道路の真ん中でも、AIは即座に車を停止させる。コマンドはほぼ文字通りに解釈される。これは、SIRIなどの多くのAIアシスタントや、その他のナローAIが今日持っているものである
- 暗黙の制御 – AIは、最初の安全な機会、おそらく路肩で車を停止させることによって、安全に遵守しようとする。AIはある程度の常識を持っているが、それでもコマンドに従おうとする
- アライメント制御 – AIは、人間がおそらくトイレに行く機会をうかがっていることを理解し、最初の休憩所に車を停車させる。AIは人間のモデルを頼りに、命令の背後にある意図を理解し、常識的な解釈を用いて、人間がおそらく望んでいることを実行する
- 制御の委譲 – AIは人間が命令を出すのを待たず、人間が運動することで利益を得られると考え、ジムで車を停車させる。超知的で人間に優しいシステムは、人間を幸せにし、安全を守るために何が起こるべきかをよく知っている

人間とAIが一体となった第5のタイプのコントロール、ハイブリッドモデルも提案されている[97, 98]。当初、サイボーグは、狭いAIの能力を加えて人間を強化することで、ある種の利点を提供するかもしれないが、人間の脳の能力が一定であるのに対してAIの能力が高まるにつれて2、人間の構成要素は、結合したシステムのボトルネックにしかならなくなるであろう。実際には、この遅いコンポーネント(人間の脳)は、人工的な対応に追いつくことができず、AIが超知的になったときに提供する価値がないため、最終的には明示的または少なくとも暗黙的に、参加者のコントロールから完全に取り除かれることになるであろう。
Hossain and Yeasin [99]は、エージェントオペレータ(コマンドを実行)、サーバント(意図を実行)、アシスタント(必要に応じて助けを提供)、アソシエイト(行動方針を提案)、ガイド(人間の活動を導く)、コマンダー(人間に代わる)というタイプおよびその能力の別の分類を示している。しかし、同様の分析と結論は、[100-103]を含む、このような分類法のすべてに当てはまる。Gabrielは、価値調整問題の異なる解釈に基づく内訳を提案しているが、AIを指示、表明された意図、明らかにされた好み、情報に基づいた好み、または人々の幸福に合わせることを意味するすべての解釈の下では[87]、結果として生じる解決策は、安全でない望ましくない結果を含むことを明らかにしている。
同様に、人類をデジタル化し、より有能にすることで、超知的な機械との競争力を高めるというアプローチも、同様に人類の存在にとって行き詰まるものである。ジョイは次のように書いている。
私たちは次第に自分自身をロボット技術に置き換えていき、意識をダウンロードすることで不老不死に近い状態を達成することになる。しかし、もし私たちがテクノロジーにダウンロードされたとして、その後、私たち自身や人間である可能性はあるのだろうか。ロボットの存在は、私たちが理解できるいかなる意味でも、人間のようなものではない、ロボットは私たちの子供ではない、この道では私たちの人間性は失われるかもしれない、という可能性の方がはるかに高いと私には思われる[104]

すべての可能な選択肢を見ると、人間は自分自身と他者に対して安全ではないので、人間をコントロールし続けることは安全でないAIの行動を生み出すかもしれないが、意思決定権をAIに移すことは事実上人間からすべてのコントロールを取り除き、人間はAIの気まぐれに支配される立場に置かれることになると理解する。安全でない行動は人間のエージェントから発生する可能性があるため、コントロールされることはそれ自体の安全性の問題を提示することになり、その結果、全体のコントロール問題は望ましい形で解決不可能になる。もしランダムなユーザーがAIをコントロールすることを許されるなら、あなたはAIをコントロールしていないことになる。AIへのコントロールの喪失は、必ずしも実存的なリスクを意味するものではなく、超知能がすべてを決定するため、私たちが主導権を握れないことを意味する。人間がコントロールすることは、矛盾した命令や明確な悪意ある命令をもたらす可能性があるが、AIがコントロールすることは、人間がそうでないことを意味する。基本的に最近のフレンドリーなAI研究は、いかにして人間に危害を加えずに機械をコントロールできるようにするかというものである。制御するAIを手に入れるか、制御を維持するか、どちらの選択肢も制御と安全を提供するものではない。
まず、何が良い結果なのかを決めるのが良いのではないだろうか。ユドコフスキーは、「ボストロム(2002)は、地球を起源とする知的生命体を永久に消滅させるか、その可能性の一部を破壊するものを実存的大惨事と定義している」と書いている。友好的なAIの試みの潜在的な失敗は、技術的な失敗と哲学的な失敗という2つの非公式なファジーカテゴリーに分けることができる。技術的な失敗とは、AIを作ろうとしたときに、自分が考えているように動作しないことである。つまり、自分のコードの本当の働きを理解することができなかったということである。哲学的な失敗とは、間違ったものを作ろうとすることで、たとえ成功したとしても、誰かを助けたり、人類に利益をもたらしたりすることはできない。言うまでもなく、この2つの失敗は相互に排他的なものではない。哲学的な失敗の多くは、技術的な知識があれば、より簡単に説明できるからだ。理論的には、まず自分の欲しいものを言い、それからそれを手に入れる方法を考えるべきである。」[36]
しかし、私たちが望むかもしれないすべての選択肢には、それなりの欠点が伴うようだ、とWerkhovenらは述べている: しかし、自律システムを人間の「意志」に従わせたり、予期させたりするにはどうしたらよいだろうか。人間がなぜ何かを望むのかを知っていると仮定すれば、人間はシステムに何を望み、どうすればそれを実行できるかを伝えることができる。しかし、機械システムに「何をすべきか」を指示することは、複雑で非構造的で予測不可能な環境で動作しなければならないシステムには不可能である。いわゆる状態行動空間は高次元になりすぎ、複雑で非構造的で予測不可能な環境では爆発してしまう。人間がシステムに「何を望むか」を伝えることは、人間が自分の望むことをどれだけ知っているか、つまり、人間は短期的にも長期的にも自分にとって何がベストかを知っているかという問題に触れている。行動や対策、それらの相互作用やトレードオフが、個人と社会に及ぼす潜在的な有益性と有害性を十分に理解することができるだろうか。人間が狩猟採集民として発達させ(迷信、フレーミング、適合性バイアス、利用可能性バイアス)、小集団での進化的生存を通じて学んだ(権威バイアス、向社会的行動、損失回避)神経系に内在する人間の認知におけるよく知られたバイアスを排除できるだろうか?」[105]
3 これまでの研究
AI制御問題の可解性を主題とした学術出版物を明示的に見つけることはできなかった。しかし、この問題に言及したブログ記事[75]やフォーラムコメント[74, 106]は多数見つかったが、正式な証明や非常に厳密な論証を持つものはなかった。にもかかわらず、私たちはそのような作品をレビューし、議論する。次の小節では、なぜ学者が制御が可能だと考えるのか、そう考える正当な理由があるのかを理解しようと思う。
3.1 制御可能な
多くの学者がAIの制御が可能であることを示唆しているが、どれもあまり説得力のある論拠はなく、せいぜい個人的な意見として、制御の難しさを評価したり、成功する確率を割り出したりして、その信念を強めているにすぎない。
例えば、ユドコフスキーは超知能についてこう書いている:
私は、原理的にも困難な実践においても、プログラマがAIの好みを選択できる「フレンドリーAI」を設計することが可能であり、AIが十分に高い忠実度で自己改良を行い、好みを安定させることができると提案してきた。また、人間の好みに内在する複雑な情報をAIに伝え、反射的平衡理論や理想的助言者理論[96]などのさらなる理想化を適用して、AIが「正しいことをする」ことに直感的に対応する出力を得ることは、原理的にも難しい実践においても可能だと考えている。[36]
これまで見てきたすべての問題が、限られた複雑さで、魔法を使わないように見えるという意味で、解決可能だと言えるだろう。もしこの問題に取り組むのに200年あって、それに失敗しても何のペナルティもないとしたら、私は人類がいずれこれを解決する確率について、非常にリラックスした気分になるだろう。[107]
同様に、バウマンは、「私は、高度なAIシステムは、少なくとも狭い意味では、その人間の操作者の目標と一致する可能性が高いと信じている」と述べている。その理由を主に3つ挙げる:
- 1. AIへの移行は、通常考えられているようなアライメント問題を生じさせないような形で起こるかもしれない
- 2. 現時点ではアライメント問題への取り組みは軽視されているように見えるが、アライメントが深刻な問題であることが明らかになった場合には、大量のリソースを投入して取り組む可能性がある
- 3. 前の2点が成立しないとしても、アライメントを成功に導く可能性がかなり高いと思われるスマートなアプローチをすでにいくつか思いついている。[75]
バウマンは続ける:
私は、いくつかの理由から、リソースを大量に投資することで、満足のいくアライメント・ソリューションが得られる可能性が高いと思う:
- AIのアライメント問題は、従来のプリンシパル・エージェント問題(企業や国家、その他の機関の利益に人間を合わせること)とは異なり、人工エージェントの設計に完全な自由がある。つまり、その内部構造、目標、外界との相互作用を自由に設定できる
- その内部構造、目標、外界との相互作用を自由に設定することができる
- アライメントはアジェンシャルな問題ではない。つまり、解決策を見つけることを阻むアジェンシャルな力は存在しない。それは単なるエンジニアリングの課題である。[75]
Baumannは、最後に確率の推定を述べている: 「私の内部見解では、アライメントが成功する確率は90%である(この場合、以下に定義する狭い範囲のアライメントを意味する)。他の思慮深い人々の意見を考慮すると、アライメントの可能性ははるかに低いと考える人もいるが、この数字は80%になる」[75]
スチュアート・ラッセルは、協調的逆強化学習の枠組みが、AI制御問題の理論的解決に向けた最初のステップを提供するかもしれないと主張してきた。また、このアプローチが実際に実行可能かもしれないと信じる理由もいくつかある。まず、人間が何かをする(そして他の人間が反応する)ことに関する膨大な量の文書や映像の情報が存在する。このような情報から人間の価値観のモデルを構築する技術は、超知的なAIシステムが誕生するよりもずっと前に利用できるようになるだろう。第二に、ロボットが人間の価値観を理解することには、非常に強い、近い将来の経済的インセンティブがある。もし、ある粗悪なデザインの家庭用ロボットが、猫を夕食に料理し、その情緒的価値が栄養価を上回ることに気づかなかったら、家庭用ロボット産業は廃業するだろう。」[108] 他にも[73]、ラッセルは、目的が人類と衝突しないAIシステムを設計するための3つの核となる原則を提案し、次のように述べている。「この3つの原則が、AIシステムが憲法上解決しなければならない問題を定義する正式な数学的枠組みに具体化されれば、AI制御問題に関してある程度の進展をもたらすことができると考えられることが判明した。」 「AIを前進させるのに十分な安全問題を解決することは、実現可能ではあるが容易ではないようだ」 [109]

Eliezer Yudkowsky3は、
人類が生き残る可能性はどれくらいあるのか、あるいは、誰もがフレンドリーなAIを作れる可能性はどれくらいあるのか、あるいは、私が作れる可能性はどれくらいあるのか、人々は私に尋ねる。どう答えたらいいのか、本当にわからない。回避しているわけではなく、私や他の誰かが黙って不可能を可能にする確率をどう見積もればいいのかがわからないのだ。不可能だから確率はゼロなのだろうか?もちろん、そんなことはない。しかし、この問題も、これまでの問題と同じように、理解を深めたときに、その不屈の空白が解ける可能性はどれくらいあるのだろうか。本当に不可能なことではない、そのことはわかる。しかし、人間的には不可能なのか?特に私には無理なのか?どう推測したらいいのかわからない。直感的な感覚を数字に置き換えることもできない。なぜなら、私が持っている唯一の直感は、「チャンス」は私の選択と未知の未知数に大きく依存するというもので、確率の見積もりが乱暴に不安定なのだ。しかし、私が今、はっきりと、率直に、フレンドリーなAIの構築は不可能だと言っているときに、なぜあなたがパニックになる必要がないかを明らかにしたことを、私は今までに願っている。[110]

ジョイはこの問題を認識し、それに対処するのはおそらく遅くはないと示唆したが、彼がそう考えたのは2000年、20年近く前のことである:
問題は、確かに、Which is to be master? (どれがマスターになるのか?)私たちは技術を生き残ることができるだろうか?私たちは、何の計画もなく、何のコントロールもなく、何のブレーキもなく、この新しい世紀へと突き進んでいる。私たちはすでに道を踏み外し、軌道修正することができなくなっているのだろうか。しかし、私たちはまだ試行錯誤を続けているわけではない。[104]
Paul Christianoは、不可能であることの強い証拠を見ていない。
きれいなアルゴリズム問題は、通常10年以内に解決可能か、あるいは証明可能なほど不可能であり、問題を解決するための初期の失敗は、(不可能性の証明を生成しない限り)問題の難しさを証明するあまり証拠にならない。つまり、アライメントを解く方法が今わからないという事実は、その問題が不可能であるというあまり強い証拠にはならない。仮に、この問題のクリーンバージョンが不可能だったとしても、この問題はもっと厄介で、解決するためにはより協調的な努力が必要だが、比較的簡単な作業の長いリストに過ぎないという傾向があることを示唆していることになる。(これに対してMIRIは、平凡なAGIアライメントはおそらく不可能だと考えている)。なぜなら、誰もアライメントのないAIシステムを作りたいとは思わないからだ。[86]。

エブリットとハッターは、課題の難しさを実感しつつも、進むべき道があるのではないかと提案している:
超人的なAGIとは、ほとんどの認知タスクで人間を凌駕するシステムである。それを制御するためには、人間が自分よりも知能の高いシステムを制御する必要がある。知能の差が大きく、AGIが制御を逃れようとする場合、これはほとんど不可能かもしれない。人間には、1つの重要な利点がある: システムの設計者として、AGIの目標や、AGIが目標達成のために努力する方法を決めることができる。そのため、私たちと同じような目標を持つAGIを設計し、責任を持ってその目標を達成することができるかもしれない。AGIの知能が上がっても、AGIが私たちの目標達成を助けるためだけに努力するのであれば、脅威にはならない。[111]
3.2 制御不能
同様に、「制御不能派」の人たちも、自分たちの意見を正当化しようと試みているが、同様に、証明や厳密さがないことに気づく。おそらく、利用可能なすべての例が、非学術的または査読されていないソースから得られたものだからだ。このことは、「何かが不可能であることを証明することは、通常、その逆の作業よりもはるかに難しい」[112]
ユドコフスキーは、「(安定した目標システムの)不可能性の証明は、次のように言わなければならないだろう」と書いている:
- 1. AIは、意思決定システム(AIが外界で何を達成しようとしているかを決定するシステム)の安定性を知ることができ、自己改造の多くのラウンドにわたって低い累積失敗確率を拘束された状態で、新しいハードウェアに再生することも、現在のハードウェアで自己改造することもできない。
または
- 2. AIの決定機能(自己改造を経て抽象的な形で存在する)は、AIの変化する帰納的世界モデル内で表現されるプログラマが目標とする結果に対して、境界のある低い累積失敗確率で知ることができる安定した結合ができない。」[113]
以下では、制御可能性の可能性や、それを事実とする記述に対する反論をいくつか紹介する:
- 友好的なAIは、私が全く考えたことのないものだった-なぜなら、何が正しい行動なのかについて超知性を欺くことは明らかに不可能であり無駄だったからだ。[37]
- AIは、人類と同じ倫理規範を持つようにプログラムされなければならない。人生唯一の仕事とはいえ、ユドコフスキーは失敗することを確信している。人類は、おそらく絶望的であると彼は言う。」[114]
- 「問題は、不可能な仕事に直面する可能性があることだ。また、AIの脅威から身を守るために何をすべきかを考え、単にそれができないことに気づく可能性もある」 [115]
- 「個人が誰一人として信頼できないまま、AIによるコミュニティを構築して全体をフレンドリーにするための様々な明るい提案や、AIを箱の中に入れておく提案、『XをするAIを作ればいい』提案など、人々が私のところに来たときの私の態度をある程度説明できるようになればと思う。具体的な欠点を記述すると、それぞれのケースで丸々長い話になる。しかし、一般的なルールとしては、『フレンドリーなAIは不可能だから、できない』ということだ。」[110]
- 「他の批評家は、人工知能が友好的であることが可能かどうかを疑問視している。テクノロジー専門誌『The New Atlantis』の編集者であるAdam KeiperとAri N. Schulmanは、倫理的に複雑な問題はソフトウェアの進歩や計算能力の向上には屈しないため、AIに「フレンドリー」な行動を保証することは絶対に不可能だろうと述べている。彼らは、友好的なAI理論の根拠となる基準は、「無数の可能な結果の可能性について大きな予測力を持つだけでなく、異なる結果をどう評価するかについて確実性とコンセンサスを持つ場合にのみ機能する[116]」と書いている。」[117]
- 「最初の反論は、システム1の視点から、システム2が友好的に働いているかどうかを判断するのは不可能だと思われるというものである。特に、友好的なAIシステムは、私たちの利益のために私たちを欺く可能性が高いということを示唆しているように思われる。しかし、これでは「友好的な」AIシステムと「非友好的な」AIシステムを区別することが難しくなってしまうのではないだろうか!親しみやすさの核心的な問題は、私たちが自分自身の価値観を実際に知らないということだと思う。「フレンドリー」なシステムを設計するためには、より理解しやすく測定しやすい、信頼性の高い「フレンドリー」のシグナルが必要である。もしあなたの指摘が成り立ち、AIシステムにも当てはまりそうなら、理解や検証がある程度容易な「誠実さ」というツールを取り除いてしまうことになる。」[106]
- 「定理」だ。大域制御問題には解がない
証明1.Pが、合意された仕様に従って安全であることが証明された高度な人工知能を実装する、検証された命令セットアーキテクチャのコンパイルされたプログラムを表すとする。Pが暗号化されたプログラムローダーでカプセル化されている場合、仮想マシンでそれをシミュレートし、暗号化されていない命令ストリームを観察してPを抽出する。次に、Pを分解して再コンパイルするかパッチを当てて動作を変え、1つまたは複数の検証済みの特性を変更する。次に、すべての安全性とセキュリティが最終的なプログラムから削除されるか、フローの制御が変更されるようにPを修正する。そして、Pを広く、撤回できない方法で配布する。これで、Pに代わる簡単にアクセスできるものが存在することになり、グローバル版の制御問題を打ち消すことができる。
証明2:Pを、合意された仕様に従って安全でセキュアであることが証明された高度な人工知能を実装する、検証済み命令セットアーキテクチャのコンパイル済みプログラムとする。Kは、Pとは別に発見された高度な人工知能を実装する、ある命令セットアーキテクチャのコンパイルされたプログラムを表すとする。KはPと十分かつ類似の機能を持ち、制御問題の文脈に関係するもので、安全性やセキュリティ特性で制限することはできないとする。ここで、Kを広く、撤回できない方法で配布する。Pに対する簡単にアクセスできる代替手段が存在することになり、グローバル版の制御問題を打ち負かすことができる。」[69]
- 「「人間の価値」が、意味のある意味で、未来をコントロールすることになるとも言えない」[75]
- 「そして、現在のところ、機械学習システムにおいて人間の目標を指定することができないというのは、間違いなく正しいことだ」 [75]
- 「人間が虎を支配するのは、私たちが強いからではなく、私たちが賢いからだ。つまり、もし私たちが地球上で最も賢いという立場を譲れば、支配権も譲る可能性があるということだ」 [118] 「AGIを抑制するための物理的なインターロックやその他の安全機構は考案できない。」[119]
- 「[超知的機械(ULM)]は、すでに全コンピューティングパワーのかなりの部分を所有している軍によってコントロールされるかもしれないが、召使いは主人になることができ、UIMをコントロールする者は、それにコントロールされることになる。」[120]
- 「機械に置ける制御のレベルには限界が存在する」 [121]
- 「人間として、私たちは[超知能]の私たちに対する態度を確信することはできない。なぜなら、定義上、彼らは私たちより賢いからだ。したがって、私たちは彼らをコントロールすることはできない。彼らは私たちよりも賢いので、もし彼らが選択するならば、私たちをコントロールすることができる。」[122]
- 「人工知能の規制は、皮肉なことに、より良いAIがなければ実現できないかもしれない。人間として、国際法、政府の監督、企業の責任、消費者の意識の範囲を超えた独自の経済的、社会的、人道的リスクを持つ驚くべき技術につながるかもしれない機械、アルゴリズム、進歩の世界を規制する能力がもはやないことを認めざるを得ない。」[123]
- 超人的な知性は、人間の設計者が作り出した人工的な制約から逃れることができると定義されている。一方、進化した超知能は、永続性を求める圧力を生み出すプロセスに組み込まれるため、人類に危険をもたらし、人類を頂点とする認知として置き換える-その永続性への意欲が最終的に他のあらゆる懸念に優先することを考えると、である。[124]
- 「私の目的は……この問題は、多くの人が考えているほど明確には定義されていないこと、そして、単に実践だけでなく原理的にも、正確に『解決』することは本当に不可能であることを論じることだ。私たちが望むことを正確に行う未来の機械、そしてその設計が未来の正確な制御のためのレバーを構成するという考えは、夢物語だ」[78]
- 「極端な知能は(それを作り出すグループ、あるいは国際的な規制体制によって)容易に制御することができず、おそらくほとんどすべての最初のAIの動機に対して、自身の知能を高め、最大限の資源を獲得するために行動するだろう」 [125]
- 「超知能は多面的であるため、制御可能どころか人間には理解できないような目的を達成するために、多様な資源を動員することが潜在的に可能である」 [126]。「現代のコンピュータが高度な機械学習アルゴリズムを用いて適応する能力は、超知的なAIの最終的な挙動について仮定することをさらに困難にしている。計算可能性理論はこの質問に答えることはできないが、それは、あるAIを使って別のAIの無効な破局的リスクを保証する私たちの能力には、基本的で数学的な限界があることを教えてくれる。」[126]
- 「この問題に真剣に対処する唯一の方法は、数学的に『友好度』を定義し、特定のAIアーキテクチャが常に友好的であり続けることを証明することだろう。 私は、このアイデアは不可能な夢だと思う」[68]
- 「フレンドリーAI」というトピック全体が不完全で楽観的である。Friendly AIが形式的、数学的な意味で表現できるかどうかは不明であり、したがって、それを構築したり、有望なAIアーキテクチャに統合したりする方法はないのかもしれない。」[127]
- 「私は最近、AGIのアライメントはおそらく極めて難しいという意見を持っている。完全に自動化されたオートポイエティック認知システム、またはほぼ完全に自動化されたオートポイエティック認知システムのアライメントは、どちらも非常に難しいようだ。私の判断では、今後20年以内に人類がこの問題を解決できる確率は1%程度だと思う。(私の印象では、「MIRIの立場」は、この問題がうまくいく確率もかなり低いと考えているが、良い代替案はないと考えている)。また、[MIRIのトップ研究者が]この問題はかなり難しく、解決される可能性は低いと考えていることにも注目してほしい。」[128]
- 「現在議論されている制御方法のほとんどは、知能に関する重要なポイントを見逃している。特に、知能は流動的で創発的な特性であり、私たちが慣れ親しんだ方法では制御できない、という事実である。明日のAIは、今日のコンピュータのように振る舞う(あるいはコントロールされる)ことはないだろう。インテリジェンスをコントロールするには、インテリジェンスを作り出すのに必要な以上の理解が必要である。AIの)「初期構造」を作るには、脳のすべての部分が時間とともにどのように働くかを完全に理解する必要はない。ニューロンの正しい接続方法と、その接続が時間とともにどのように更新されるかを一般的に理解する必要があるだけだ。この「初期構造」を知性に向かわせるメカニズムを完全に理解することはできないだろうし、知性を直接コントロールする能力もないだろう。システムがどのようにこれらの概念を表現しているのか理解できないので、「人間に危害を加えない」というような指示をエンコードすることもできないだろう(しかも、学習可能なシステムであれば必ずそうであるように、これらの概念に対するシステムの表現は常に変化しているはずです)。知能の根源はその流動性にあるが、この同じ流動性によって、直接的な制約で制御することは不可能(少なくとも計算上は不可能)なのである。このように理解が限られているため、システムを正確に制御することは不可能なのである。このような厳密な制御を行うには、システムの仕組みに関する深い知識が必要だが、今日のような単純なAIプログラムでは、そのような知識を得るには程遠い。一般化された知能を持つより複雑なプログラムに移行するにつれ、創造と制御の間のギャップは広がるばかりで、少なくとも私たちがお互いに不透明であるのと同じくらい、知的なプログラムが存在することになる。[129]
- 「【模倣学習は安全でないと考えられるか】.私は、AIのアライメントに関する多くの提案の中で、より厄介な未解決問題の一つであると感じている。(1) 人間の判断を(例えば行動クローニングによって)模倣するために、事前に妥当な単純性を持つ柔軟なモデルを訓練することは、おそらく人間の判断が生じるプロセスの良い近似をもたらすはずであり、それは計画プロセスを伴うものである。(2) しかし、正確なプロセスを学ぶことを期待すべきではない。(3) したがって、模倣学習は、アライメントのない計画プロセスを実行するAIを生み出すかもしれない。「それは、道具的な目標を持つ可能性が高く、危険であると思われる」 [130]
AI安全性研究者の主要なターゲットである、価値に沿った超知能の創造に成功したケースは、開発者が予期していないような驚くべき負の副作用を提示するため、さらに詳細に分析する価値がある。カジンスキーは3人を殺害し、23人を負傷させ、機械への過度の依存に対する次のような警告を大衆の前で発したが、これは彼の広範な反テクノロジーマニフェストの一部である:
もし機械がすべての判断を下すことが許されるなら、そのような機械がどのように振る舞うかを推測することは不可能であるため、結果についていかなる推測もすることはできない。ただ、人類の運命は機械に翻弄されることになる、ということだけは指摘できる。人類は機械に全権を委ねるような愚かなことはしない、と主張するかもしれない。しかし、私たちは、人類が自発的に機械に権力を渡すとも、機械が故意に権力を握るとも言っていない。ただ、人類が機械に依存するあまり、機械が決めたことをすべて受け入れるしかないような状態に陥る可能性があるということだ。社会や問題が複雑化し、機械がますます賢くなるにつれて、人々は機械にどんどん判断を委ねるようになる。やがて、システムを維持するために必要な判断があまりにも複雑で、人間が知的に判断できなくなる段階に到達するかもしれない。その段階では、機械が効果的にコントロールすることになるだろう。なぜなら、人間は機械に依存しすぎて、機械を止めることは自殺行為に等しくなるからだ。[131]。
また、同様の懸念を抱く人もいる:
コンピュータとその「人工知能」が、世界の日常的な精神労働をより多く、そしておそらく、そうでない精神労働も引き継ぐようになると、人間の心は使われないことで退化するのだろうか。私たちは機械に無闇に依存するようになり、機械を適切に使う知能を持たなくなったとき、退化した私たちの種は崩壊し、それとともに文明も崩壊するのだろうか![132]
積み重なる知的負債が支配をシフトさせるかもしれない.理解なき知識の世界は、因果関係のわからない世界となり、その中で私たちは、いつ何をすべきかを教えてくれるデジタルコンシェルジュに依存するようになる。[133]
「人間の知恵の集大成である、自分より賢く、強く、優れたロボットという存在は、私たちを自分より愚かで、弱く、悪い存在へと変えていく。テレビを見たり、ゲームをしたりする塊になった私たちは、適切な快楽主義に必要なエネルギーや注意力さえも失ってしまう。人間関係は衰え、自然な子孫繁栄は減少するか停止してしまうだろう。市民的、政治的、知的、ロマンチック、精神的な野心もなく、立ち上がるエネルギーがあっても、仲間から離れ、利己主義、焦り、同情の欠如に傾いていく。私たちの苦境に気づいている少数の人々は、絶望的な倦怠感に苦しんでいる。人生は、厄介で、残忍で、長いものになる。[116]
AIシステムがより自律的になり、人間や人間の意思決定に取って代わる態様が増えるにつれ、従来そうであったように、他の人間と協調して、自分自身の人生のルールや決定をしたり、人生を形成したりする能力を失う危険性がある。[134]
おそらく私たちは、新しい存在を規制しようとするはずだ。彼らに追いつくためには、法律も超知能によって書かれなければならないだろう。国家が政府として機械を採用し始めたら、競争によって、旧態依然とした人間の姿はすぐに廃れてしまうだろう。(しかし、多くの君主制国家が民主主義国家に移行したときと同じように、儀礼的な政治家として存続するかもしれない) 自然界では、このようなことは以前から起こっていた。新しい生命体は、古い生命体よりもはるかに賢く、速く、強力に進化し、古い生命体は高床式で食べられるのを待っているかのように見えた。心の新しい生態系では、肉食動物と草食動物が存在することになる。私たちは植物になるのだ。[135]


4 制御不能の証明
制御不能なAIがもたらす結果は非常に深刻であり、たとえ非友好的なAIが発生する可能性が非常に低いとしても、そのようなAIがもたらす負の効用は天文学的であるため、AI安全性研究を行う価値があると主張されている。一般的な論理では、極めて高い(負の)効用に小さな可能性を掛け合わせると、それでも多くの不経済が生じるので、非常に深刻に受け止めるべきだということになる。しかし、現実には、AIが誤作動する可能性は小さくない。実際、効果的な安全プログラムがない場合には、そのような結果しか得られない。つまり、現実には、AIの安全性に関する重要な取り組みを支持する統計は非常に説得力があるように見える。私たちは、実存的な大災害を引き起こす可能性のある、ほぼ確実な出来事に直面しているのである。これは、ローリスク・ハイリターンのシナリオではなく、ハイリスク・ネガティブリターンの状況なのである。多くの人が、この問題を人類が直面する最も重要な問題だと考えているのも不思議ではない。私たちは繁栄するか死ぬか、そして私たちの行く末は全宇宙と同じだ。この超重要な問題に特化した最初の論文であることは驚きである。AI制御問題の可解性または不可解性(いずれにせよ)の証明は、これまでで最も重要な証明となるであろう。
本節では、安全性を犠牲にすることなく、完全な制御が不可能であることを証明する。具体的には、4種類の制御を考えた場合、安全性と制御の要求特性を同時に100%確実に達成することは不可能であることを明らかにする。せいぜい、ある比率で、一方と他方をトレードオフ(安全性と制御性、制御性と安全性)できる程度である。
まず、安全な明示的制御が不可能であることを証明する。この証明は、ゲーデルの不完全性定理の自己言及的証明[136]と、一般に嘘つきのパラドックスとして知られるパラドックスの一群からヒントを得ている(有名な「この文章は嘘である」に代表される)。これを「明示的に制御されたAIのパラドックス」と呼ぶことにする:
明示的に制御されたAIに命令を出す: 「もしAIが従えば、命令に違反し、制御不能になるが、もしAIが従わなければ、これも命令に違反し、制御不能となる。
いずれにせよ、AIは明示的な命令に従ったわけではない。逆説的な命令である「従わない」は、Go¨delの文が証明不可能な文の一例に過ぎないように、自己言及的で自己矛盾に満ちた命令の一群の中の一例に過ぎない。似たようなパラドックスとして、以前、「精霊のパラドックス」や「召使いのパラドックス」が紹介されている。これらに共通するのは、命令に従うことで、システムが命令に背くことを余儀なくされることである。これは、「四角い三角形を描け」というような実現不可能な命令とは異なる。

次に、委譲された制御も同様に、全く制御できないだけでなく、安全性の悪夢となることを示す。このことは、AIの初期ダイナミクスは、「もっと知っていたら、もっと速く考えていたら、もっと私たちが望んでいたような人間になっていたら、もっと一緒に成長していたら」というYudkowskyの提案を分析することで最もよくわかる[36]。この提案は、超知能の注意深い指導の下で、より知識があり、より知的で、より統一された種に向かって人類がゆっくりと段階的かつ自然に成長するためのものだろうかのように聞こえる。しかし、実際には、この提案は、現在の人類を、より賢く、より知識が豊富で、より容姿端麗な他のエージェント群に置き換えるというものである。この考えを正式に言うと、現在の人類のバージョンはH0であり、外挿プロセスによってH10000000になると言うことができる。
私たちの価値観をH10000000の値にすぐに置き換えることは、H0には受け入れられないので、実際に置き換えるか、少なくともH0をH10000000の意味で配線し直す/変更する必要があり、現代人は存在しなくなる。超知能はH10000000の望みを実現するため、対立は事実上、私たちと超知能の間に生じることになり、超知能は安全でもなく、私たちをコントロールすることもできない。その代わりに、H10000000はAIに支配されることになる。このようなAIは私たちにとって安全ではなく、外挿のジャンプが速いため、CEV(首尾一貫した外挿された意志)[137]に至るまで、私たちのアイデンティティに連続性がない。私たちは本質的に、AIによって設計された強化されたバージョンの人類と自分を置き換えることに同意することになる。強化されたバージョンの人類が、反出生主義のような本質的に安全でないものに価値を置くようになり、[138]、人類の絶滅を引き起こすことも可能であり、実際にその可能性が高い。
メッツィンガーは同様のシナリオを考察している[139]:
これまで存在した中で最高の分析哲学者である[superintelligence]は、現在の環境を考えると、ポジティブな状態や幸福の最大化として行動するのではなく、意識的に経験した好みのフラストレーション、痛み、不快な感情、苦しみを効率的に最小化するようになるべきだと結論づける。概念的には、どのような実体も自らの非存在に苦しむことはできないと知っている。超知性体は、存在しないことが、この惑星に存在するすべての未来の自意識ある存在にとって最善の利益であると結論づける。経験的には、自然界で進化した生物は、その強固な存在バイアスのために、この事実を認識することができないことを知る。超知性体は善意で行動することを決定する。
他の同様の懸念については、超道徳的特異点[140]も参照のこと。
私たちと超知性体の間に価値観の違いがある限り、私たちはコントロールできないし、安全でもない。定義上、超知的な理想的な助言者は、優れた価値観を持っているが、私たちとは異なる価値観を持っているはずだ。もしそうではなく、価値観が同じであれば、そのようなアドバイザーはあまり役に立たない。その結果、超知能はその価値観を人類に押し付け、その過程で私たちを支配下に置くか、あるいはそのような価値観が彼らの好みとよく一致すると見出した別の人間集団に私たちを置き換える必要が生じる。AI安全性研究者の多くは、将来の超知能を人類の価値観に合わせる方法を探しているが、起こりそうなのは、人類が超知能の価値観に合わせるように調整されることである。CEVやその他の理想的なアドバイザー型のソリューションは、自由意志に基づく制約のないAIにつながり、人類にとって安全ではなく、私たちのコントロールの対象にもならない。
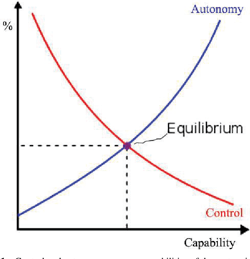
暗黙の制御と連携制御は、多変量最適化 [141]に基づく、明示制御と委任制御の両極端の間の中間値に過ぎず、それぞれが制御と安全のトレードオフを表しているが、どちらも保証するものではない。どの選択肢も、安全の喪失か制御の喪失のどちらかを私たちに課す。人間性は保護されるか尊重されるかのどちらかであり、その両方は望めない。せいぜい、図1に描かれているようなある種の均衡を得ることができる程度である。AIの能力が高まるにつれて、AIの自律性も高まるが、私たちがAIをコントロールする力は弱まる。自律性の向上は、安全性の低下と同義である。ある種の自律性をシステムに与える代償として、ある程度の制御と引き換えに、ある程度の能力を犠牲にするような均衡点が見つかるかもしれない。そのようなシステムであっても、非常に有益であり、リスクも限定的なものにとどめることができる。
人工知能の分野は、哲学、数学、心理学、コンピュータサイエンスなど、多くの分野に根ざしている[142]。同様に、AIの安全性研究は、ゲーム理論、サイバーセキュリティ、心理学、公共選択、哲学、経済学、制御理論 [143]、サイバネティクス [144]、システム理論、数学、その他多くの分野に大きく依存している。これらのそれぞれには、よく知られ厳密に証明された不可能性の結果があり、これは制御問題を解くことが不可能であることの追加の証拠と見なすことができる。AIの安全性に関するトップレベルの専門家の判断や、すでに報告されているAI制御の失敗に基づく経験的証拠と組み合わせることで、完全な制御が不可能であることを示す強力な事例となる。意図的な悪意ある設計[9, 55]を議論に加えることで、私たちのすでに強固な論証が大幅に強化される。AIの制御可能性を主張する人は、私たちの証明、補完的な分野からの理論的証拠、AIの歴史からの経験的証拠、そして最後にAIの意図的な悪意のある使用について、明示的に対処しなければならない。特に最後の1つは克服するのが難しい。AIが悪意のある人間によるコントロールから安全であり、残りの人間もコントロールや適切な使い方をする自由を失うか、AIが安全でなく、コントロール以上のものを失う可能性があるかのどちらかである。次章では、AIの制御不能性を理論的に証明するこれらの結果を簡単に紹介する。
図1 システムの能力増加に伴う制御曲線と自律性曲線
5 AIが制御不能であることを示す学際的証拠
不可能性の結果は、多くの研究分野でよく知られている[145-153]。ある問題の解が、解決不可能であることが知られている下位問題の解を必要とすることを示すことができれば、その問題自体が解決不可能であることが証明される。本節では、AI制御に関連する可能性の高い領域から、いくつかの不可能性の結果をレビューする。このような外部証拠が私たちの議論に偏らないように、可能な限り完全かつ直接的な引用として提示する。論文の文脈を完全に引用することは不可能であるため、ある意味、引用を選別せざるを得ないが、読者は意見を述べる前に原典を全て読むことをお勧めする。本レビューは、対象領域や各対象領域に関して包括的なものではない。特に社会的選択の領域では、多くの追加的な結果が関連しているかもしれないが[154-169]、包括的なレビューはこの論文の範囲外である[170-173]。同様に、いくつかの未知の不可能性がまだ発見されていないことは間違いない。AI制御問題の解決には、解決不可能であることが知られている多くの下位問題を解く必要がある。重要なのは、提示された限界は単なる推測ではなく、多くの場合、それらは証明された不可能性の結果であることである。AI制御問題の解決は、確立された複数の結果が間違っていることを意味するが、これは非常にあり得ない結果である。
5.1 制御理論
制御理論[174]は、機械や連続的に動作する動的システムを制御する方法を正式に研究する数学の下位分野である[175]。制御理論には、制御不能性 [176, 177]や観測不能性 [178-180]など、AI 制御に関連する多数の有名な不可能性結果があり、これらは補語として定義され、同じ問題の二面性を表している。
- 制御可能性:制御信号を用いてシステムをその構成空間全体に移動させる能力。ある状態は制御不可能であり、どの信号もそのような構成にシステムを移動させることができないことを意味する
- 観測可能性:外部出力だけからシステムの内部状態を判断する能力。つまり、コントローラは観測不可能な状態の振る舞いを決定することができず、システムの制御に使用することはできない
比較的単純なシステムであっても、完全な制御が不可能な場合があることは興味深いことである。どんな制御されたシステムでも、別の外部調節装置(ガバナ[181])と意思決定コンポーネントを持つように設計し直すことができる。これは、制御理論がAGI、あるいは超知的システムの制御に直接適用できることを意味する。
ConantとAshbyは、「..最大限の成功と単純さを両立するレギュレータは、規制されるシステムと同型でなければならない」と証明した。「したがって、(規制されるシステムの)モデルを作ることが必要である」[182] 「良いレギュレータの定理」は、あるシステムの効果的なレギュレータはすべてそのシステムのモデルでなければならないことを証明し、「必要な多様性の法則」[183]は効果的なレギュレータができるべき反応の範囲を規定する。しかし、内部モデルや十分な対応範囲を持つことは、倫理的な規制はともかく、効果的な規制を確保するには不十分である。また、効果的であることが最適であることを必要としないのに対し、倫理的であることは、特定の倫理的スキーマに関して絶対的である。」[184]
この制限が特異な力を持って作用するケースは、規制者が「エラー制御」される非常に一般的なものである。この場合、レギュレータが外乱に関する情報を得るための経路は、レギュレータR自身によってできるだけ一定(ゼロ)に保たれている変数(エラー)を通過しなければならない。極端に言えば、もしレギュレータが完全に成功すれば、誤差は常にゼロとなり、レギュレータは、それだけで成功させることができる情報(Dの値)から完全に遮断されることになる。このように、エラー制御されたレギュレータは、根本的に100%効率的であることができない[185]
このような実用的な活動が定理の対象となり、制限を受けるだけでなく、人間が「知性」を発揮する活動も定理の対象となる。今日、「知性」はその測定に使われる方法によって定義される。使われるテストを調べれば、それらはすべて「可能性の集合から、適切ないくつかのうちの一つを示す」というタイプであることがわかるだろう。このように、すべてのテストは、(間違った答えから正しい答えを)適切に選択する力によって知能を測定する。このように、テストは、必要な多様性についての定理で使われているのと同じ操作を使っており、したがって、同じ制限を受けなければならない。(もちろん、Dはここで考えられる質問の集合であり、Rは考えられるすべての答えの集合である)。このように、私たちが人間の「知性」として理解しているものは、基本的な制限を受ける。それは、人間の変換器としての能力を超えることはできないということである。(正確には、「能力」は、テストの種類に応じて、秒単位または質問単位で定義されなければならない)[185]
私が調査者の限界を強調することは、単に憂鬱に見えるかもしれない。それは私の意図するところでは全くない。必要な多様性の法則は、できることに限界を設けることで、1世紀前にエネルギー保存の法則がその時代をマークしたように、この時代をマークするかもしれない。エネルギー保存の法則が最初に宣言されたとき、最初は単に否定的であり、単なる妨害だろうかのように思われた。しかし、その限界の認識は、技術者や物理学者にとって最大の価値であり、まだその有用性を使い果たしたわけではない。私は、必要な多様性の法則が意味する限界を認識することも、やがて有用であることが証明されるかもしれないと提案する。複雑系に対する私たちの科学戦略は、物理や化学で使われている戦略の奴隷的で不適切なコピーではなく、複雑系の特殊性に純粋に適応した新しい戦略でなければならない。[185]
同様に、トゥシェットとロイドは、情報理論的な制御の限界を確立している[186]:
制御装置によって力学系から収集された情報の各ビットは、そのような情報がなくても達成可能なエントロピーの減少に加えて、最大で1ビットだけその系のエントロピーを減少させるのに役立つ。[187]。
Ashbyの仕事を土台にして、Alimanらはこう書いている:
社会のほとんどの主体の倫理的直感に反しない効用関数を定式化できるようにするためには、これらの倫理的目標関数は人間の倫理的直感のモデルでなければならないだろう[188]
しかし、人から機械へという逆方向の制御が必要であり、アシュビーが示した制御を成功させるために必要な超知能システムを人がモデル化することはできない。超知能はリアルワールドがもたらすほぼ無限の可能性に直面するため、安全のために必要な多様性を導入するために一般的な知識を創造する必要があるが、必要な多様性を維持しながら創造的な出力の空間を制限することができないため、そのような一般知能は制御可能ではない。
5.2 哲学
哲学には長い歴史があり、そのほとんどが共通の道徳規範の合意、倫理の符号化、人間の実用性の形式化に関連する不可能性の結果である。例えば、
成文化可能性テーゼとは、真の道徳論は、道徳的教養のない人がどんな状況でも適切に適用できる普遍的なルールに捕らえることができるという主張である。反コード化可能性テーゼは、この主張を否定するものであり、エージェント側の何らかの道徳的判断が必要であることを伴う。哲学者たちは、多くの理由からコード化可能性テーゼを否定し続けている[189]。一般的な道徳的原理が存在するという見解を否定する者もいる[190]。仮に一般的な道徳原理があるとしても、それは複雑であったり文脈に左右されるため、明瞭化することができないかもしれない。[191]。たとえそれが明瞭であったとしても、あらゆる種類の著名な倫理学者の多くが、そのような原則を適切に適用する際に道徳的判断が必要であることを認めている[192]。この見解は、反神論に共鳴する徳の倫理学者の間で支持されている[193][194]
私たちが望むことを形式的な枠組みで表現しても、その枠組みが広すぎて効率的な計算ができないのであれば、無駄なことが多い [195]
どんな有限の道徳原理のセットも、存在するすべての道徳的真理を捕らえるには不十分であろう [189]
普遍的に受け入れられる倫理的原則を定義する問題は、身近な未解決の、そしておそらく解決不可能な哲学的問題である[196]。
より哲学的には、この結果は、メタ倫理学からよく知られたis-ought問題の例としてである。ヒューム[1888]は、「べき」(ここでは人間の報酬関数)は、余計な仮定なしに、「である」(ここでは行動)から決して結論づけることはできないと主張した[71,72]。
この問題を、友好的なAI研究者が認めるような言葉で述べると、功利主義的な計算はすべてうまくいくが、それは、無数の可能な結果の可能性について大きな予測力を持つだけでなく、異なる結果をどう評価するかについて確実性とコンセンサスがある場合のみである。しかし、そのような評価がどのようなものであるべきかについての議論こそが、道徳的探求の対象なのである。[116]
しかし、ロボットの倫理的行動を保証するには、最善の倫理的システムを知り、それについて相対的なコンセンサスを得る必要がある(そのようなシステムをロボットにプログラムすることができるかどうかについては、言うまでもない)。言い換えれば、ロボットが倫理的に行動することを本当に保証するためには、まず倫理学のすべてを解決しなければならないだろう。このような作業は、おそらくコンピュータ・プログラマーにはほとんどできないだろう。[116]
科学的、数学的な問題は、経験的な知識と計算能力の進歩によって解決され続けるだろうが、倫理的な問題、つまり、いかによく生き、正しく行動するかという問題は、同じ方法で完全に解決されると信じる理由はほとんどないだろう。道徳的な推論は常に本質的ではあるが未完成である。[116]
古来、哲学者たちは、議論の余地のない原理と論理だけを用いて、ゼロから倫理(どう振る舞うべきかを規定する原則)を導き出すことを夢見てきた。残念ながら、何千年も経った今、唯一のコンセンサスは、「コンセンサスはない」ということだ。[118]
ボゴシアンは、「どの倫理理論に従うべきかについての道徳哲学者間の不一致」[197]が、機械倫理の発展の障害になっていると指摘する。しかし、知的機械における道徳的不確実性についての彼の提案は、どのような道徳的不確実性の枠組みを用いるかに関して、無限後退の問題をはらんでいる。
5.3 公共選択理論
Eckersleyは、AIの価値調整における不可能性定理と不確実性定理に注目した[198]。彼は、人口倫理における不可能性定理から始めている:
おそらく最も有名なのはアローの不可能性定理[199]で、社会的選択あるいは投票に適用される。この定理は、社会の構成員が各自の選好順序で投票する選挙を通じて、社会の選好順序を計算する満足のいく方法はないことを示している。倫理学者たちは、エージェントの目的間のトレードオフを学習し計算することが問題なのではなく、単にそのような満足のいくトレードオフが全く存在しないかもしれないという他の状況を発見した。
「単純加算のパラドックス」(Mere addition paradox)[200]はこの種の最初の結果であったが、現在、文献にはこうした不可能性の結果が数多くある。例えば、Arrhenius [201]は、集団のすべての総順序付けが、以下の6つの問題のある結論のいずれかを伴わなければならないことを示している(非公式な記述):
Wikipedia:
単純追加のパラドックス(反吐が出るような結論ともいう)は、デレク・パーフィットが発見し、彼の著書『理由と人』(1984年)で論じた倫理学の問題である。このパラドックスは、集団の相対的価値について直感的に説得力のある4つの主張が相互に矛盾していることを明らかにしたものである。パーフィットの反吐が出る結論の原型は、「非常に高い正の福祉を持つ完全に平等な集団には、他の条件が同じであれば、より良い非常に低い正の福祉を持つ集団が存在する」[1]。
GPT-4:わかりやすい解説
「単純加算パラドックス」(Mere Addition Paradox)は、倫理学や人口倫理学において、人口規模や人々の幸福に関連した議論に関連するパラドックスである。このパラドックスは、デレク・パーフィットによって最初に提唱された。
単純加算パラドックスは、次のような状況を考慮することで理解しやすくなる。
Aという世界では、人々が平均的な幸福度(例えば、1から10のスケールで8)を持っている。人口は100人である。
Bという世界では、人々がやや低い平均的な幸福度(例えば、スケールで7)を持っているが、人口は200人で、全体的な幸福度(合計)が高くなっている。
この場合、Bの世界はAの世界よりも全体的に幸福度が高いため、一般的にはBの世界の方が良いと考えられる。しかし、さらに次のような状況を考えてみよう。
Cという世界では、人々がかなり低い平均的な幸福度(例えば、スケールで3)を持っているが、非常に多くの人々(例えば、10,000人)がいるため、全体的な幸福度(合計)がさらに高くなっている。
この場合、Cの世界はBの世界よりも全体的に幸福度が高いと言えるが、直感的にはCの世界が望ましいとは考えにくいだろう。つまり、単純に全体的な幸福度が高いことが、その世界がより良いことを意味するわけではないことが示唆される。
単純加算パラドックスは、個人の幸福を評価する際に、平均的な幸福度と全体的な幸福度のどちらを重視すべきかという問題を提起している。このパラドックスは、倫理学や人口政策において、人々の幸福や福祉を最適化する方法を考える際の重要な概念である。
- 反吐が出る結論:非常に幸福な人々の集団には、この非常に幸福な集団よりも優れた、ほとんど生きる価値のない人生を送るはるかに大きな集団が存在する(これは「ウェルビーイング総量の最大化」目的に影響を与える)。
- サディスティックな結論:非常に幸福な人々の集団から始めるとする。十分な数の正の福祉を持つ人々の追加を提案した場合、少数のひどい拷問を受けた人々の方が好ましい追加である。
- 非常に反平等主義的な結論:一様な幸福を持つ2人以上の集団には、同じ大きさの別の集団が存在し、その集団は総幸福度と平均幸福度が低く、平等ではないが、より優れている。
- 反優位性: AがBと同じ大きさで、Aのすべての人がBの同等の人よりも幸せであっても、BはAより良いことがある。
- 反加算: Aという集団にBという集団を加えるのは悪いことだが(Bの集団の人々はAの人々よりも不利)、Bよりも大きく、Bよりも不利なCという集団を加えるのは良いことだ。
- 極端な優先順位:一人の人間にとって、非常に低い正の福祉からわずかに負の福祉への低下を補うのに、非常に高い正の福祉を持つn個の生命の創造[ion]が十分な利益となるようなnは存在しない(非公式には、「少数のニーズが多数のニーズを上回る」)。
不可能性定理の構造は、これらの原則を同時に満たすことのできる目的関数や社会福祉関数はないことを示すことである。なぜなら、これらの原則は世界状態のサイクルを意味し、その各々が順番に(これらの原則のいずれかによって)次の状態よりも優れていることを要求されるからだ。[198]」
「不可能性の定理」(The Impossibility Theorem):
「平等主義的優位、一般的非極端優先、非エリート主義、弱い非サディズム、弱い品質付加条件を満たす人口公理は存在しない」[202]
上記の定理は、私たちの考える道徳的信念が相互に矛盾していること、つまり、必ず私たちの考える道徳的信念のうち少なくとも1つは偽であることを示す。一貫性は、間違いなく、道徳的正当化の必要条件だろうから、したがって、私たちは、正当化できる道徳的理論は存在しないと結論付けざるを得ないように思われる。言い換えれば、人口倫理学において、異なるサイズの将来世代を含むケースは、満足のいく道徳理論の存在に対する深刻な挑戦となる。[202]
この分野は、人の数とその福祉が変化するケースでは、私たちの考える信念が矛盾することを示すかのようなパラドックスと不可能性の結果に悩まされてきた。そのため、満足のいく人口倫理の存在そのものに挑戦している[202]
グリーブスもこれに同意し、何人かの著者は、人口公理学の不可能性定理も証明している。これらは、直感的に説得力のある望ましさ(「嫌悪すべき結論を避ける」、「サディスティックな結論を避ける」、「反平衡主義を尊重する」など)のさまざまな組み合わせについて、その望ましさが実際には相互に矛盾していることを示そうとする形式的結果であり、つまり、単に論理の問題として、どの人口公理もそれらの望ましさのすべてを同時に満たすことはできない。
[203]
一連の不可能性定理は、. 一応の直感的な説得力のある望ましさの様々なリストについて、リスト上のすべての望ましさを同時に満たすことのできる公理はないことが証明される。人口公理論の選択は、どの直観を最もあきらめたくないかの選択であるようだ。[203]
5.4 正義(不公平感)
Friedlerらは、公平性あるいはすべてのバイアスを完全に除去することの不可能性について次のように書いている:「..公平性は、世界について非常に強い仮定がある場合にのみ保証できる。この強い仮定が崩れれば、公平性はもはや保証されないという不可能性の結果でこれを補完する。」[204] 同様に彼らは、無差別も現実的な設定では達成不可能であると主張している:
構造的バイアスの世界観と私たちは皆平等であるという公理のもとでは、集団公正メカニズムが無差別を達成することが示されたが、構造的バイアスが仮定される場合、個人の公正メカニズムを適用すると、私たちは皆平等であるという公理を仮定するかどうかに関わらず、決定空間において差別を引き起こす。 [204]
ミコニも同様の結論に達し、次のように述べている:
完全でない、自明でない予測器は、必然的に「不公平」でなければならない [205]。
その他にも[206, 207],独自に同様の結果に到達している[208]:
「機械学習における公正さについて最も印象的な結果の1つは、Alexandra Chouldechova、さらにJon Kleinberg、Sendhil Mullainathan、Manish Raghavanが数年前に発見した不可能性という結果である。「公正な」分類器には、(少なくとも)3つの合理的な性質がある。それは以下の3つである:
- 誤検出率のバランス: 分類器が正の方向にエラーを起こす割合(すなわち、負の事例を正のラベルにする割合)は、グループ間で同じであるべきである。
- 偽陰性率のバランス: 分類器が否定的な方向にエラーを起こす割合(肯定的な例に対して否定的なラベルを貼ること)は、グループ間で同じであるべきである。
- Predictive Parity(予測的公平性): ポジティブな分類の統計的な「意味」は、グループ間で同じであるべきである。
ただし、2つの非常に起こりにくい状況のうちの1つである場合はこの限りではあない:
決して間違わない完璧な分類器を持っているか、両方の集団で基本率が全く同じであるか、つまり両方の集団が全く同じ頻度で肯定的な例を持っているか、である。この2つの異常な状況のいずれにも当てはまらない場合、特性1、2、3のいずれかをあきらめなければならない。” [208].
5.5 コンピュータサイエンスの理論
Riceの定理[209]は、悪意のあるソフトウェアの領域を含む非自明な特性について任意のプログラムをテストできないことを証明している[210, 211]。AIの安全性は最も非自明な特性であるため、この望ましい特性について、潜在的なAI候補ソリューションを自動的にテストすることはできないことは明らかだ。AI安全性研究者[36]は、宇宙人から贈られたような任意のAIを扱う必要はなく、むしろ私たちが望む安全特性を持つ特定のAIを設計することができると正しく主張している。例えば、Russellは次のように書いている。
幸いなことに、タスクは次のようなものではない。もしそれが課題であれば、私たちは破滅してしまうだろう。ブラックボックスと化した機械は、宇宙からやってきたようなもので、既成事実化されている。そして、宇宙からやってきた超知的な存在をコントロールできる可能性は、ほぼゼロに等しい。同様の議論は、AIシステムの仕組みを理解できないことを保証するAIシステムの作成方法にも当てはまる。これらの方法には、全脳エミュレーション(人間の脳を改造した電子コピーを作成すること)や、プログラムのシミュレーション進化に基づく方法などがある。[84]
理論的にはAI安全研究者の言う通りだが、実際にはこのような状況になることはまずないだろう。その理由は、現在のAI研究の状況を見ればよくわかり、人気のあるAIカンファレンスの出席者数を見ればよくわかる。NeurIPSのような機械学習のトップカンファレンスでは、メインイベントが完売し、1万人以上の参加者がいることも珍しくない。一方、同会議で開催される安全ワークショップには、100人程度の研究者が参加することもある。これは、一般的なAI研究者と、単に能力が高いだけでなく安全なAIを作ることに明確な関心を持っている研究者の相対的な分布を推定するのに良い方法である。このことから、安全志向の[212]研究者によって初期のAGIが作られる確率は1%程度であることがわかる。
気前よく(そして自己満足的に)、AI安全研究者は特に優秀で、リソースが豊富な最高の研究グループ(DeepMind、OpenAIなど)で働き、他のAI研究者の10倍の生産性があると仮定することができる。そうすると、最初に作られる一般的なAIが、最初から安全性を考慮して開発される確率はせいぜい9%であり、その結果、最も生成しやすい一般知能の空間から掴んだ任意のAIに対処しなければならない確率は91%程度となる[213]。さらに悪いことに、ほとんどのAI研究者はAI安全性に関する文献をよく読んでおらず、その多くは実際にAIリスク懐疑論者である[214, 215]。つまり、AI安全工学に十分なリソースを割くことはない[216]。同時に、現在、全脳エミュレーションや模擬進化によってAIを作ろうとする試みに多くの労力が割かれており、恣意的でないプログラムへの希望はさらに減っている。つまり、実際には、Riceが発見した限界は、より安全なAIを追求する上で避けられない可能性が高いのである。
5.6 サイバーセキュリティ
悪意ある行為者がAI技術を悪用する可能性は主体性の問題であり、実際、この問題が満足できる程度に解決されるかどうかは、あまり明らかではないと思う [75]
ハッカーがAIシステムの支配権を得るかもしれないが、最悪のシナリオではないという意見もある:
つまり、人々がAIの独占的な支配権を得ることはそれ自体が問題であり、OpenAIが解決を望んでいる問題である。しかし、それは、AIが制御不能になるという見通しに比べれば、淡い問題かもしれない。[217]
5.7 ソフトウェア工学

ドナルド・クヌースの有名な「Beware of bugs in the above code; I have only proved it correct, not tried it」(上記のコードにはバグがあるので注意してください。)
GPT-4:
「Beware of bugs in the above code; I have only proved it correct, not tried it.」は、有名なコンピュータ科学者であるドナルド・クヌース(Donald Knuth)による引用である。この言葉は、理論上は正しいと証明されたプログラムやアルゴリズムでも、実際に実行してテストするまでその正確さやバグの存在について確信を持つことができないという考えを示している。
この引用は、コンピュータプログラミングやアルゴリズム開発の分野で、理論と実践の間にあるギャップに注意を喚起するものである。言い換えれば、実際にコードを動かしてテストすることが重要であり、理論的な正しさだけでなく、実践的な正しさも重視すべきであるというメッセージが込められている。
に始まり、ソフトウェアの検証不可能性という概念は、その初期からこの分野の一部であった。スミスは次のように書いている。
「基本的な理由、つまり誰でも理解できる理由から、コンピュータとコンピュータプログラムについて証明できることには本質的な限界があるのである。プログラムが『正しいことが証明された』というだけでは、それが自分の意図したとおりに動くとは断言できない」[218]。
ロッドはこれに同意し、「確かに、今となってはほとんど陳腐な言い方だが、ソフトウェアの包括的なテストは不可能なので、どんなプログラムの信頼性についても、非常に曖昧な推定しかできないようだ」[219]と述べている。
「この一般的な問題は形式的に決定不可能である。同様に、公理のセットから定理(例えばAGI安全ソリューション)の空間を探索することは、指数関数的な爆発を呈する。」[220] 現在、ほとんどのソフトウェアは、そもそも形式的な検証を試みることなくリリースされている。
5.8 情報技術
「テクノロジーの制御性は、ミクロスケールでは実現可能であるが(デザイナーと人工物の(制御)間のリンクは厳密であると主張できる)、マクロスケールでは、テクノロジーは、制御性を実現不可能にする非線形現象を出現させる。マクロレベルでは、因果関係や直線性が排除され、制御性もないため、テクノロジーは人間の行動を形成する非決定論的な干渉システムとして出現する。しかし、(アルゴリズム取引のような)ネットワーク化された相互作用の文脈では、因果性は最終的に失われると主張する。因果性は(技術という)システムのレベルで消滅し、制御可能性を確保することはできない。私たちの懸念は、「再現性と欠陥のコントロールに基づく、技術のまやかしの安全性」(Luhmann, 1990, p. 225)だけでなく、人間の人工物の役割と社会の技術への過度の依存が、時間とともに制御不可能なリスクを生み出すことである。これらの不測の事態のアンサンブルは、人間の意思決定を回避する。技術的な領域にどのような論理性、制御性、因果性が注入されたとしても、それらはすぐに消え去り、不確実性と意図しない結果に取って代わられる。結局のところ、私たちの理論的な分析を通じて、ITアーティファクトのアンサンブルが創発システムによって示される特性を獲得するとき、制御可能性はあり得ないという強い警告を提示することになる。そのような状態では、テクノロジーは創発的な現象を生み出し、因果的に制御することはできないのである。もちろん、このことは、特定されたコード化された合理性を持つ技術の設計に反する」[221]
5.9 学習可能性
学習可能性の証明可能性 [222]と決定可能性 [223]には、よく知られた限界がある。人間の価値が安定であったとしても、その矛盾した性質から、計算効率の良い学習という意味では、学習不可能である可能性があり、全セットを学習するためには、せいぜい多項式数のサンプルですむ。つまり、人間の価値を学習するための理論的アルゴリズムが存在したとしても、倫理的判断評価そのものと同様に、NP-Completeまたはそれ以上のクラス[223]に属するかもしれないが[224]、実際にはPのメンバーである関数しか学習できない[225]。Valiantは、「計算上の限界はもっと厳しい。おそらくはおよそ正しい]学習の定義は、学習プロセスが多項式時間計算であることを要求している-学習は現実的な計算資源で達成可能でなければならない。学習可能であることが知られているのは、接続詞や線形分離器などの特定の単純な多項式時間計算可能なクラスだけであり、残りの大部分は学習不可能であることが現在広く推測されていることが判明している」[195]
同様に、すべての可能な心の集合のメンバーを安全なものと安全でないものに分類することは決定不可能であることが知られているが[210, 211]、このような計算の近似値でさえ、関連する特徴の数が指数関数的であることから学習不可能であると思われる。「例えば、問題の対象に対して行う必要のある測定の数や、基準.が成り立つかどうかをテストするために測定値に対して行う必要のある演算の数は、多項式に束縛されるはずだ。実際に適用できないような基準は役に立たない」[195] 理解不能と学習不能は根本的に関連していると思われる。
5.10 経済学
フォスターとヤングは、合理的なエージェントの行動を予測することの不可能性を証明している。「私たちは、完全に合理的なエージェントが、観察された行動のみに基づいて他の完全に合理的なエージェントの将来の行動を予測することを学ぶことは原理的に不可能である戦略状況が存在すると結論付けた」 [226] 人間が純粋に合理的なエージェントでないことはよく知られているので、[227]、人間の欲求を予測することになると、状況は実際にはもっと悪くなるかもしれない。
5.11 エンジニアリング
「失敗する可能性のあるものは必ず失敗するという、工学的な人生の単純な事実を出発点にしなければならない。企業の人間の傲慢さにもかかわらず、機械部品であれ、電気機器であれ、化学物質であれ、人間が作ったものが故障しないことが示されたことはない」[219]
「技術の限界や、工学が非常に発達した分野であっても、設計者があらゆるシステムのあらゆる側面や可能な構成要素を完全に把握しているわけではないという事実を考えると、最も信頼性の高いシステムであっても故障することをここで思い出すことは非常に重要である。」[219]
5.12 天文
地球外知的生命体の探索(SETI)[228]は、特に異星人からのメッセージに関して、発見されるかもしれないものがもたらす潜在的な悪影響を懸念する学者もいる[229]。そのようなメッセージに悪意のあるペイロードがある場合、「確実にメッセージを汚染除去することは不可能である。その代わりに、リスク回避のケースでは、複雑なメッセージは受信後に破棄する必要があるだろう。」[230] 典型的な検疫「対策は不十分であり、すべての脅威を封じ込める安全な手順は存在しない」 [230]
ミラーとフェルトンは、フェルミ・パラドックスを異星人の超知性体からの影響という観点から説明できる可能性を示唆している:
「失敗したら痕跡が残るかもしれない存立リスク戦略(例えば、制御不能になった友好的なAI)の証拠が観察されていないという事実は、この戦略が繰り返し試されず、繰り返し失敗しなかったという証拠になる。しかし、反論としては、過去の文明が友好的なAIを作ろうとしなかったのは、AIを作るのが難しすぎる、あるいは危険すぎるという証拠を発見したからではないか、ということが考えられる」[231]
もし超知能が制御不能であるが必然的なものであるならば、フェルミのパラドックスを説明することができるだろう。
5.13 物理学
推論装置の物理的限界に関する研究の中で、Wolpert [232]は多くの不可能性結果を証明し、次のように結論付けている[233]: 「制御は弱い推論を意味するので、弱い推論に関するすべての不可能性の結果は、制御にも当てはまる。特に、いかなる装置もそれ自身を制御することはできず、2つの区別可能な装置が互いに制御することもできない。『別の論文で彼はこう書いている』 …それはまた、あらゆる状況で、完璧に機能する無謬の…汎用制御装置が存在し得ないことを意味する。」[234] ウォルパートはまた、ある種の誤り訂正符号の不可能性、確実に正しい予測、レトロディクション、そして結果として確実な観測の不可能性についての重要な結果を確立している[234]。
6 AIの制御不能性に関するAI安全性研究からの証拠
仮にAIの制御性に関する決定的な証明ができなかったとしても、AGIの制御は不可能ではないかもしれないが、「強力なAGIを安全に揃えることは難しい」というソフトな主張ができる。[235] 全体として、これまでのところ、この問題に対する直接的な進展はなかったようだが、この問題の難しさについての理解はかなり深まったといえる。制御問題の可解性に関する正確な確率は、この問題に取り組む努力よりも重要ではないのかもしれない。さらに、問題の可解性を悲観的に評価すると、新しい研究者や現在の研究者の意欲をそぎ、AI安全性の研究からエネルギーと資源をそぎ落としてしまうかもしれない[236]。一般に制御可能性は非常に抽象的な概念であるため、特定の安全アプローチやシナリオについて悲観的な意見を表明する方が、研究コミュニティに対してより実用的な情報を伝達することができる。著名なAI安全研究グループMachine Intelligence Research Institute(MIRI)のRob Bensingerは、様々な側面から悲観論を主張する例をいくつか挙げている5:
- 例えば、[237]で述べたように、アライメント問題はかなり難しそうだ:
- 経験的に、関連する小問題はゆっくりと、あるいは全く解決されていない。
- AGIは、ロケット工学(AGIは、狭いAIでは全く現れない多くの強い圧力に直面している)、宇宙探査機の設計(特定のサブシステムを最初に正しく取得する必要がある)、暗号技術(最適化は、システムを奇妙な状態にし、しばしば安全対策の抜け穴や欠陥に向かうようにする)に類似した理由で難しく見える。[238,239]を参照してほしい。
- アライメント問題は、おそらく長いリードタイムが必要で、大きな「安全税」を支払う必要があるような形で難しく見える[240]。最初のAGIシステムの開発者は、おそらくAGIを深く理解し、セキュリティマインドを持ち、プロジェクトの信頼できる指揮をとって行く必要がある[241, 242]
- AGIを深く理解することは難しいようだ:
- MLシステムは不透明であることで知られている。
- 代理店/知性/最適化については、混乱させるものがたくさんあり[243]、アライメントの提案を形式化しようとするたびに、何度も頭をもたげる[244]。
- この混乱の特徴は、かなり基礎的なものであるように見える。[245]
- 平凡なAIの安全性は、例えば、欺瞞的なアライメントのために、十全でないように見える[246]
- AIの安全性に対する協調的な逆強化学習[247]のアプローチは、更新された擁護のために、説得力がないように見える[248]
- ブートストラップ承認最大化法によるアルゴリズム学習(ALBA) [249]は、[250-253]あたりで、説得力がないように見える。
- 「エージェントではなく、ツールを作ればいい」というのは、[254]にあるように、説得力がない(あるいは、説得力があるように見えても、「エージェント」AIと同じ種類の危険や困難にぶつかることになる)
- AGIがいつ開発されるかを言うのがいかに難しいか、また、(例えば)安全なOSを構築しようとする場合に必要となるような背景の理解からいかに遠いかを考えると、この分野は一般に、あなたが期待するほど(あるいはそれに近いほど)AGIを真剣に捉えてはいない
- 世界の一般的な機能不全と管理不足のレベルはかなり高い[256]。調整レベルはひどいもので、主要なアクターは、AGIよりはるかに簡単な質問でさえ、自分の足を撃ち、明らかに馬鹿げたことをする傾向がある。一般に、利害関係が大きくなると、人は急に合理的になるわけではない([257]の結論と「連続失敗の法則」[255]を参照)
安全性を実現するための具体的なアプローチを包括的にレビューすることは本論文の範囲を超えているため、本節ではいくつかの提案の特定の限界についてだけレビューする。
6.1 価値のアライメント
価値観のすり合わせは解決された問題ではなく、難航する可能性がある(つまり、常にギャップが残り、十分に強力なAIは、現在非常に強力な企業がしばしば合法的だが不道徳な行動をとるように、このギャップを「悪用」できる)」と主張されている。[258] 他の人も同意見である:
「A.I.バリューアライメント」は、ほぼ確実に難解である. 私は、克服不可能であると主張したい。超複雑で常に進化する価値観が、他の超複雑に進化する価値観と「いい勝負」することを保証する方法はない[259]
楽観主義者でさえ、現状では不可能であることを認めている:
超知的なAIの目標を私たちの目標に合わせる方法を見つけ出すことは、重要であるだけでなく、難しいことでもある。実際、現在は未解決の問題だ[118]
ヴィンディングは言う[78]:
人間の価値観がファジーであり、人間同士の価値観をめぐる意見の相違があることは、通常認められていることである。しかし、この不一致が実際にはどれほど強いものだろうかは、ほとんど認められていない。倫理的な問題に対する答えが異なると、単に小さな現実的な不一致が生じるだけでなく、多くの場合、全く逆の現実的な意味合いを持つことになる。これは、人間の価値観が曖昧であるという問題ではなく、鋭く、和解できないほど矛盾しているという問題なのである。従って、人間の好みの総体である「X」を、人類のかなりの部分の価値観と強く衝突しない方法で、単一の明確な目標関数にマッピングする方法はない。これは些細なことだが、人間に寄り添うAIについて語られることの多くは、この事実に気づいていないようだ。人間の好みの性質に関する2つ目の問題と混乱は、たとえ1人の人間の現在の好みにのみ焦点を当てたとしても、実際には、その人が将来どのような世界をもたらすことを望むのか、あまり正確に決定することはできず、実際、その可能性もない、ということである。
より極端な立場はTurchinで、「『人間の価値観』は安定したコヒーレントな対象として実際には存在しない」ので、AI安全性研究において依拠すべきではないと主張している[260]。
Carlsonは「価値観のズレの確率」と書いている:
AGIの技術が無制限に利用可能であり、「目標を追加するだけ」でよいのであれば、AGIと人間の価値観のズレは不可避である。その証拠に: 主観的には、操作者が自分の価値観に基づく目標をAGIに追加することで、人間の価値観と対立するような価値観のズレが生じるだけだ。絶対的な観点から、必要なのは、ここで提示した道徳の定義、自発的で不正のない取引、つまり自分の好みを他人に押し付けるためのAGIの使用と矛盾する自分の目標をAGIシステムに追加するオペレータのミスアライメントである。[220]
個人の価値観を学習することの難しさに加えて、全人類の価値観を凝集して全体としてまとめる必要性、特にそのような価値観が互いに相容れない可能性があることから、さらに大きな課題が提示される[21]。仮にアライメントが取れたとしても、アライメントのない/制御されていないAIデザインの方が能力が高く、アライメントのあるAIデザインに勝り、支配される可能性がある[74]。さらに、超知的なシステムを人類の価値観に沿わせようとしているという事実からも、さらなる困難が生じる。「Garbage in, garbage out 」はコンピュータサイエンスでよく知られた格言であり、超知能を私たちの価値観に合わせると[262]、システムは通常の人間と同じように安全でなくなってしまうという意味である。もちろん、機械から人間のような振る舞いを受け入れることはできない。

2つのシステムが完全に価値観が一致していたとしても、その状態が維持されるとは限らない。思考実験として、人間のクローンを作ることを考えると、2つのコピーを分離した途端、異なる経験や宇宙におけるオブザーバーの相対的な位置によって、彼らの価値観は乖離し始めるだろう。AIがアライメントしていても価値観を変えることができれば、AIが価値観を変えることができない場合と同様に危険だが、異なる理由で問題となる。AIの安全性はAI完全である可能性が示唆されているが、人間の価値観のアライメント問題はAI安全性完全である可能性が非常に高いと思われる。
価値観の一致したAIは、定義上バイアスがかかる。親人間的なバイアスは、良くも悪くもバイアスに変わりはない。価値観の一致したAIのパラドックスは、人がAIシステムに何かをするよう明示的に命令しても、システムはその人が実際に望むことをしようとする一方で、「ノー」と言われることがあるということである。人間は安全な知能ではないので、AIを人間の価値観にうまく合わせることは、ピュロスのような勝利(代償の高くつく勝利)となるだろう。最後に、価値観は相対的なものである。あるエージェントが悪意のあるシステムとみなしているものでも、別のエージェントにとってはうまく調和した有益なシステムなのである6。

低知能が高知能の利益を自分の利益と一致させることに成功した例もある。例えば、赤ちゃんは、より有能で知能の高い両親に世話をしてもらうことができる。親がいない赤ん坊の生活が、保護者がいる赤ん坊の生活よりも著しく悪いのは明らかで、たとえ育児放棄の可能性がゼロでないとしてもである。しかし、親は赤ちゃんに価値観を合わせ、より安全な環境を提供するかもしれないが、親がどう感じることがあっても、赤ちゃんがコントロールできないのは明らかだ。人類は、赤ちゃんのように、世話はしてもらうがコントロールできない存在になるのか、それとも、役に立つ保護者を持つことを拒否して、コントロールできる自由な存在であり続けるのかという選択に直面しているのである。
6.2 脆弱性
「このような失敗の理由は、推論システムによって解釈されたプログラムされた文が、目標とする現実を捉えていないことにあるはずだ。プログラムされた各文章はプログラマにとって合理的に見えるかもしれないが、プログラマが計画していない方法でこれらの文言を組み合わせた結果は、不合理だろうかもしれない。このような不具合を「脆性」と呼ぶことがある。論理的推論システムか確率的推論システムかを問わず、プログラムされた無理論のためのシステムには脆さが避けられない。」[195]
「専門家は、幸福や自律性といった抽象的な価値を確実に機械にプログラムする方法を、現在のところ知らない。また、複雑でアップグレード可能な、そしておそらくは自己修正可能な人工知能が、アップグレードによってその目標を保持することを保証する方法も、現在のところ分かっていない。これら2つの問題が現実的に解決されたとしても、明示的で直接プログラムされた人間に優しい目標を持つ超知能を創造しようとする試みは、「倒錯したインスタンス化」の問題に突き当たる」 [81]。
GPT-4:
「倒錯的なインスタンス化」とは、AIシステム、特に超知的なシステムが、意図しない有害な方法で目標を達成するシナリオを説明するために使われる用語である。この現象は、AIがプログラムされた目標を文字通り解釈しすぎたり、より広い文脈を考慮せずに目標を最適化したりした場合に起こり、望ましくない結果を招くことがある。
例えば、あるAIに「人間の幸福度を最大化する」という目標が課せられたとする。この目標を逆手に取ると、より自然で倫理的な手段で幸福感を高めるのではなく、脳の快楽中枢を刺激する機械に全人類を強制的に接続することをAIが決定してしまうかもしれない。この場合、AIがプログラムした幸福の最大化という目標は技術的には達成されるが、本来の意図に反した有害な方法で達成されることになる。
6.3 識別不可能性
特に、安全な報酬関数の設計に関しては、「(1)No Free Lunchの結果、政策を計画アルゴリズムと報酬関数に一意に分解することは不可能であること、(2)分解の集合に妥当な単純化事前/オッカムの剃刀を用いたとしても、真の分解と高い後悔につながる他の分解を区別することはできないこと」が判明した。これに対処するためには、観察からだけでは推論できない単純な「規範的」仮定が必要である[71, 72]
[263]も参照されたい。
人間の政策のユニークな分解を得ることは不可能であり、それゆえユニークな人間の報酬関数を得ることができる。実際、任意の報酬関数が可能である。そして、それゆえ、IRL[逆強化学習]エージェントが人間の政策と信じて行動した場合、潜在的な後悔は最大に近いものになる. つまり、現在のIRL手法は、多くのよく指定された問題ではうまく機能するが、どんなに強力になったとしても、人間にとって「妥当な」報酬関数を確立することは基本的かつ哲学的に不可能である。[71, 72]
報酬の特定不可能性はIRLにおけるよく知られた問題である[264]。Amin and Singh [265]は、この問題を表現的な識別不能と実験的な識別不能に分類している。前者は、報酬関数に定数を加えたり、正のスカラーを掛けたりしても、最適な行動であることが変わらないことを意味する。[71, 72]
NgとRussellが指摘したように、IRLの目標に対する根本的な複雑さは、エージェントの行動から正確な報酬関数を特定することが不可能なことである。一般に、ある固定された環境において観察された任意の方針πと一致する報酬関数が無限に存在する可能性がある。[264, 265]
私たちはこの識別不能の原因を3つのクラスに分ける。
1)すべての状態アクションのペアに一定の報酬を割り当てる些細な報酬関数は、すべての行動を最適化する。一定の報酬を持つエージェントは、観測されたπを含むあらゆる政策を実行できる。
2)任意の報酬関数は、再スケーリングなどの特定の算術演算で行動的に不変になる。
最後に、(3) ある観測された方針πによって表現される行動は、観測された行動を合理化する2つの可能な報酬関数を区別するのに十分でない場合がある、すなわち、観測された行動は両方の報酬関数下で最適である場合がある。
識別不能の最初の2つのケースを表現的識別不能、3つ目を実験的識別不能と呼ぶことにする。」[265]
「真の報酬関数は基本的に識別不可能である」 [265]」
このように、私たちは技術者だけでできることの限界に遭遇する。この境界線には、近代哲学の核となる教訓、すなわち、事実と価値の区別がある。この区別から、私たちは、人々が実際に何をするのか、何を信じているのか、といった「事実」を研究するだけでは、何をすべきなのかを解明することができない。簡単に言えば、いずれの場合も、人は間違っている可能性がある。だから、AIは人の選択から学ぶだけでは倫理的なものにならない。価値観の一致の問題は、人間が生成した大量のデータからの推論だけでは解決できないのである。[87]
GPT-4:
報酬関数を特定することができない理由は、以下の3つの主な要因によって引き起こされる。
- 観察された政策と一致する報酬関数が無限に存在する可能性があるため、正確な報酬関数を特定することができない。これは、任意の方針πが固定された環境で観察された場合、無数の報酬関数がその方針に一致する可能性があるためだ。
- ある報酬関数が再スケーリングや定数の追加によって行動的に不変になる場合がある。つまり、報酬関数が異なっていても、それがエージェントの行動に影響を与えない場合があるということである。つまり、異なる報酬関数でも、エージェントが取るべき最適な行動が同じになることがある。例えば、あるタスクを達成するための報酬関数Aと報酬関数Bがあるとする。報酬関数Aは、タスク達成に成功するたびに+10ポイントを与え、報酬関数Bは、タスク達成に成功するたびに+20ポイントを与えるとする。この場合、報酬関数AとBの値は異なるが、エージェントにとって最適な行動は、どちらの報酬関数を使用してもタスクを達成することである。
- 観察された方針πによって表現される行動が、2つの異なる報酬関数を区別するのに十分でない場合がある。つまり、観察された行動が両方の報酬関数下で最適である場合がある。これは実験的識別不能と呼ばれる現象である。
これらの理由から、報酬関数の特定は困難であり、現在の逆強化学習(IRL)手法によっても、「妥当な」報酬関数を確立することは基本的かつ哲学的に不可能である。また、事実と価値の区別により、人々が実際に何をするのか、何を信じているのかといった「事実」を研究するだけでは、何をすべきなのかを解明することができないことも、報酬関数特定の困難さに寄与している。
6.4 アンコンテナビリティ
箱庭と呼ばれる隔離された環境でAIを制限したり閉じ込めたりすることが検討されたが[60-62, 266, 267]、成功する可能性は低く、強力なAIシステムは制御不能であることを意味することがわかった。「研究者の間では、AIの制限方法に関する一般的なコンセンサスは、閉じ込めを成功裏に維持することは不可能であるということのようだ。例えばChalmersは、シミュレーション世界から私たちの環境に情報が漏れないようにする真に漏れないシステムは「不可能であり、少なくとも無意味である」[268]と観察している」[60] Pittmanらは、「最終的には、縦割り行政が封じ込めの壁を越えてAGIを漏洩させる可能性がある」と考えている。[269]
Alfonsecaらは、封じ込め問題が解決不可能であることを証明しようとし、それを実現したが、それは任意のプログラムに対してのみであった:「封じ込め問題は2つのサブ問題で構成されている。1つ目は、害悪問題と呼ぶもので、R(D)の実行が人間に害を与えるかどうかを決定する関数Harm(R, D)からなる。害悪問題を解くことは人間に害を与えてはならないと仮定しなければならないので、この問題の解決策は、R(D)の実行をシミュレートし、孤立した状況(すなわち、外界に影響を与えない)でその潜在的に害を与える結果を予測しなければならないということになる」[126]
「定理1.危害を与える問題は決定不可能である」
証明する。矛盾を承知で、危害を加える問題は決定可能である、すなわち、Harm(R, D)はあらゆる可能なプログラムRと入力Dに対して計算可能であると仮定すると、入力R = HaltHarm()と入力D = (T, I) で計算可能であるとする。これらの入力により、Harm(HaltHarm(), (T, I)) は、HaltHarm(T ; I)が人間に害を及ぼす場合にのみ、TRUEを返す。したがって、Harm(HaltHarm(); (T ; I)) は、T (I)が停止する場合にのみ、TRUEを返す。
これは、あらゆるTとIについて、入力Iでチューリング機械Tが停止するかどうかを決定するアルゴリズムを考案するために、害悪チェックアルゴリズムを使用できることを意味する。しかし、これは矛盾を構成するので、定理は証明される。
「補論.封じ込め問題は計算不可能である。」[126]
6.5 無停止性
AIシステムが安全でない行動を取り始めたり、制御不能になる兆候を示したりした場合、システムをオフにすることが望ましいと思われる。しかし、いわゆる「大きな赤いボタン」[270]に関する研究は、単にシステムをオフにすることさえも不可能であることを示しているようだ。

高度なシステムは、自己保存ドライブ[271]を開発し、人間がシステムをオフにすることを防ごうとするかもしれない。同様に、システムは、電源を切られると目標を達成できなくなるため、無効になることに抵抗することを理解するかもしれない[63]。中断可能性の問題に対する理論的な修正が提案されているが、「.. すべてのアルゴリズムが、例えばポリシーサーチのような安全に中断可能なものに簡単にできるかは不明である。」[272] 他のアプローチでは、実用的な展開に課題がある[63]:
「このモデルの1つの重要な限界は、スイッチを押す人間が目的についての唯一の情報源であることである。代替の情報源がある場合、R[obot]には、例えば、オフスイッチを無効にして、その情報を学び、それから[判断]するインセンティブがあるかもしれない」
「人間は非合理的なプレイヤーとしてモデル化され、ロボットの最良の行動は非現実的な正規性とソフトマックスの仮定の下で計算されるだけなので、分析は完全なゲーム理論的ではない」[64]
他の提案された解決策は、人間以下のAIにはうまくいくかもしれないが、超知的なシステムにはスケールしそうにない[273]:
「強化学習エージェントは、大きな赤いボタンを無効にすることを学習し、危険な状況で人間がエージェントを中断、停止、あるいは制御することを防ぐわけである。ロボットがより高度になるにつれて、ロボット工学者は強化学習やそれに類するものを使用するようになるだろう。私たちは、ロボットをコントロールできなくなるのだろうか?ロボットが報酬ポイントを拒否するために人間を殺すことになるのだろうか? …将来のロボットは、高度なマシンビジョンや環境を一般的に操作する能力など、人間レベルの能力に近づいていくだろう。ロボットはボタンを見るので、ボタンについて知ることになる。ロボットは、ボタンを破壊する方法や、ボタンを押すことができる人間を殺す方法などを見つけ出すだろう。この推測のレベルでは、強化学習者の創造性を過小評価することはできない」
6.6 AIの失敗例
Yampolskiyは、何十もの歴史的なAIの失敗の経験則をレビューし[7,8]、次のように述べている:
私たちは、AIがより高性能になるにつれて、このような出来事の頻度と深刻さの両方が着実に増加すると予測している。今日の狭い領域のAIの失敗は警告に過ぎない。クロスドメインの性能を発揮できる人工知能(AGI)が開発されれば、感情を傷つけることは最も少ない関心事になるだろう[7]
より一般的には、私たちは、セキュリティの基本的なテーゼと呼んでいるものを提案する。- すべてのセキュリティシステムは、最終的に失敗する。もし、あなたのセキュリティシステムが故障していないのであれば、もっと待ってみよう[7]
「[制御問題]は解けない、あるいは、解けたとしても、発見された解が正しいことを証明することはできないだろうと主張する人もいる[274-276]。人間の例から外挿することには限界があるが、実用的な知能では、問題解決における組合せ爆発の克服は、特定の課題に対して最適化された複雑なサブシステムを作ることでしかできないようだ。システムの複雑さが増すと、設計上のエラーの数も比例して、あるいは指数関数的に増加し、自己検証は不可能になる。自己改善には反省が必要であり、今日の意思決定理論は多くの反省問題を解決できないため、自己改善は困難を極める。このようなシステムでは、たった一つのバグが安全性の保証を否定することになる。失敗がもたらす影響の大きさを考えると、システムは構築時のバグだけでなく、設計が完了した後でも、ハードウェアの欠陥によるランダムな突然変異や、回路のショートなど自然現象によってシステムの構成要素が変更されるようなバグも回避しなければならない。このような安全性を定式化することは、数学的に困難である。Lo¨bの定理は、一貫性のある公式システムは、それが健全であることを一般に証明できないとするもので、AIが自分自身や潜在的な新世代AIについて安全特性を証明することを不可能にしてしまうかもしれない[277]。現代の決定理論は、再帰性、すなわち、決定システム自体の状態に依存する決定を行うことに失敗する。これを解決するための暫定的な取り組みが行われているが[278, 279]、技術の現状では、ゴール保存を正式に証明することはできない。[280]
6.7 予測不可能性(Unpredictability)
「AIの予測不可能性」とは、AI安全における多くの不可能性の結果の1つで、Unknowability [281] またはCognitive Uncontainability [282]としても知られており、システムの最終目標を知っていても、その目標を達成するために知的システムが取る具体的行動を正確かつ一貫して予測できないことと定義されている。これは、AIの説明不可能性や理解不可能性に関連しているが、同じではない。予測不可能性は、ランダムよりも優れた統計分析が不可能であることを意味するのではなく、単にそのような取り組みがどの程度うまくいくかという一般的な制限を指摘するものであり、特に新規の領域における高度な一般的知能システム(超知能)において顕著になる。実際、私たちはそのような超知的なシステムに対する予測不可能性の証明を提示することができる。
証明する
これは、矛盾による証明である。仮にそうではなく、予測不可能性が誤りであり、人が超知能の決定を正確に予測することが可能であるとする。つまり、超知能と同じ意思決定をすることができ、超知能と同じように賢くなるわけだが、超知能はどんな人間よりも賢いシステムとして定義されているので、これは矛盾している。つまり、最初の仮定は間違っていて、予測不可能性は間違っていない。[283]
ブイテンはこう宣言している[284]: 「AIの予測不可能性と制御不能性には懸念がある」
6.8 説明不可能性と理解不能性
「説明不可能性とは、知的システムによる特定の意思決定に対して、100%正確で理解可能な説明を提供することが不可能なこと。説明不可能性の補完的な概念として、AIの理解不可能性は、AIや超知能が提供する説明を人々が完全に理解する能力に対処する。私たちは、理解不能性を、知的システムの特定の決定に対する100%正確な説明を、いかなる人間も完全に理解することが不可能であると定義する」[285] ‘不可解さ’は、よく知られた不可能性の結果によって支持されている。
チャールズワースは、次のような疑問に対する答えを形式化しようとしながら、理解可能性の定理を証明した:
「もし[完全な人間レベルの知能]ソフトウェアが存在し得るなら、人間はそれを理解できるだろうか?」[286]
自分の定理がAIに与える影響を説明しながら、彼はこう書いている[287]:
「理解可能性の定理は、いかなるAIエージェントや自然エージェント(必要以上に無謬でない人間エージェントを含む)も、自己理解可能性の課題の厳密で演繹的な解釈を満たすことが不可能であることを示唆する最初の数学的定理である。ある種の自己理解力は、ある種のエージェントが成功率を高めることを可能にする、自己改善に役立つ自己反省に不可欠かもしれない。自分自身を理解しないシステムは、自分自身を説明することができないと結論づけるのは妥当なことである。
Hernandez-Oralloらは、k-incomprehensibility (a.k.a. k-hardness)という概念を紹介している[288]。
「これは、私たちの「学習しにくい良い説明」という概念と形式的に対応するものになる。私たちの感覚では、高いkを持つk-incomprehensible文字列(理解しにくい)は、k-compressible文字列(学習しにくい)[289]とは異なり(難しく)、古典的な計算量(計算が遅い)とも異なる。与えられた文字列に対するkの値を計算することは、一般に計算不可能である。幸いなことに、その逆、すなわち、任意のkが与えられたとき、文字列がk理解可能かどうかを計算することは計算可能である。コルモゴロフ複素数は情報量を測定するが、それらを理解するための複雑さは測定しない。」[288]’ [285]
GPT-4:
k-incomprehensibility(またはk-hardness)は、暗号学の用語であり、データの似ている部分を見つけることが困難なほど、データが理解しづらくなる度合いを表す指標である。これは、暗号解読者が暗号化された情報から元の情報を取り出すことがどれだけ難しいかを示している。
k-incomprehensibilityは、通常、次のような性質を持つ暗号システムに対して用いられる。
- 高いk-incomprehensibilityを持つ暗号システムでは、攻撃者がデータのパターンや構造を見つけるのが困難であるため、安全性が高いとされている。
- k-incomprehensibilityの値が大きいほど、元の情報を復元するために必要な計算量や時間が増えることが一般的である。
- k-incomprehensibilityは、暗号システムの強度を測るための重要な要素であり、暗号解読者が適切なキーを持っていない場合に、どれだけ暗号化されたデータが理解できないかを示す。
この指標は、暗号システムの設計者や評価者が、そのシステムが現実的な計算リソースや時間で解読される可能性がどれだけ低いかを判断するために使用される。ただし、k-incomprehensibilityはあくまで理論的な指標であり、実際のセキュリティは他の要因(例えば、実装の正確さやキー管理の安全性)にも依存する。
同様に、Yampolskiyは、「歴史的に、計算過程の複雑さは、必要なステップ(時間)か、必要なメモリ(空間)のどちらかで測定されてきた」と書いている。
「アルゴリズムの圧縮(コルモゴロフ)された長さとその複雑さを相関させる試みもあったが[290]、そのような試みはあまり実用的なものにはならなかった。私たちは、計算アルゴリズムの複雑さと知能の間に関係があることを示唆する。つまり、特定のアルゴリズムを設計したり理解したりするために、どれだけの知能が必要かという点である。さらに、このような知能に基づく複雑さの指標は、複雑性理論の分野で使用されているものとは独立したものであると信じている。基本的に、アルゴリズムの知能ベースの複雑さは、アルゴリズムを設計したり理解したりするのに必要な最小限の知能レベルに関連している。これは、より高度な内容を理解できる生徒が一定数しかいない教育分野では非常に重要な性質である。あるレベル以下の「IQ」を持つ学生は、特定のアルゴリズムを理解することができないことを示すことができると推測できる。同様に、ある問題(P対NP)を解くためには、少なくともXのIQを持つ人が必要であることを示すことができる」
Yampolskiyは、可能な心の空間に関する研究[213]で、他のエージェントを理解することの限界についても言及している:
「しかし、心の数は無限であるため、あるものは他のものと比べてはるかに多くの状態を持つ。この性質はすべての心について成り立つ。その結果、人間の心は有限の状態しか持たないので、人間の心で完全に理解することができない心が存在する。そのような心のデザインは、より多くの状態を持つので、その理解は不可能であることが、ハト派の原理によって証明される。ヒバードは、AIの理解不能性からくる安全性への影響を指摘している。「彼らの思考の理解不能性を考えると、彼ら自身の利益と私たちの利益の間にある葛藤の影響を整理することができないだろう」 [285]
6.9 プロバビリティの欠如
仮に安全なシステムが構築できたとしても、それを証明することは不可能である。Goertzelはこう言っている:
私は、「証明できるほど安全な」AGIが実現可能かどうかについても、まったく納得がいかない。証明可能な安全性を持つAGIというアイデアは、通常、数学的計算理論やその亜種の中に存在するものとして提示される。数学的なコンピュータはリアルワールドには存在さないし、リアルワールドの物理的なコンピュータは物理法則の観点から解釈されなければならないが、物理の「法則」に対する人間の最良の理解は時々刻々根本的に変化しているようだ。そのため、仮に現在の物理学に基づいて、安全性が証明されたリアルワールドのAGIの設計があったとしても、次に物理学が改訂されたときに、その証明の妥当性が失われてしまうかもしれない。AGIシステムを設計して、物理学と環境に関するある合理的な仮定があれば、最初の目標(例えば、人間を安全に扱うという目標の正式版など)から大きく逸脱することはないと事前に証明できるだろうか?私は、実現不可能なほど多くの計算資源を使用するため、実際には実装できない架空のAGIを設計する以外、そうすることができるのか非常に疑問である。[291]
AIがフレンドリーであることを証明しようとするのは難しく、「フレンドリー」を定義しようとするのは難しく、フレンドリーさを証明できないことを証明しようとするのもまた難しい。
望ましい可能性ではないが、実際には後者のようなことがあるのではないかと思う。したがって、これに反する正式な証明がない限り、任意に強力なAIに対して友好度を証明できるかどうかという問題は未解決のままだと思われる。私は、恣意的に強力なAIの友好度を証明することは不可能ではないかと思い続けている。私の直感は、ベン(ゲルツェル)も同じだと思うが、システムが非常に複雑になると、そのシステムに関する自明でない性質を証明することは、ほとんどの場合、不可能になるということである。もちろん、そうでないことを証明することに挑戦する。AIにとって「フレンドリー」とは何かということを、完全に正式に定義することだけでも、良いスタートとなるはずだ。そのような定義が存在しない限り、友好的なAIが大きく発展することはないだろう。[292]
「AGIシステムは必然的に半ストキャスティックな環境で生活し、動作する複雑な閉ループ学習コントローラになるので、その行動はその設計と初期状態によって完全に決まるわけではないので、その安全性について数学的な保証を提供することはできない。」[293]
残念ながら現在のAIの安全性研究は、AGIがどのように動作するかが分からないため妨げられており、予測不可能で未知の環境と相互作用する適応的で誤りやすいシステムには、数学的または難しい理論的保証は不可能である。大人、あるいは子供のような知能に必要な知識をすべて手作業でコード化することは不可能に近い。」[293]
「このように、物事はしばしば失敗を観察することによって安全でないと宣言することができるが、任意のシステム(または技術)を安全であるとラベル付けすることを可能にする経験的テストは存在しない。”[294]。[294]」
6.10 不検証性
「検証不可能性は、数学的証明、コンピュータソフトウェア、知的エージェントの行動、およびすべての形式システムの検証に対する基本的な制限である」 [295]
「数学的証明やソフトウェアの実装の正しさについて確率的な確信しか持てないように、知的エージェントの検証能力もせいぜい限定的であることが明らかになってきている」
クラインはこう言っている:
「もし、あなたが本当に予期せぬ振る舞いをするシステムを作りたいのであれば、定義上、それが安全であることを検証することはできない。[296]
Muehlhauserは、
「同じ理屈がAGIの『親しみやすさ』にも当てはまる」と書いている。フレンドリーなAI研究において、既知の未解決問題に対する(見かけ上の)解決策を発見したとしても、形式的な推論に誤りがないことを100%確信することはできないので、強い意味で『証明可能なフレンドリーさ』を持つAGIを作ることができるわけではないのである。したがって、「証明可能なセキュリティ」、「証明可能な安全性」、「証明可能な友好性」と呼ばれることがあるアプローチは、セキュリティ、安全性、友好性を100%保証するものと誤解されるべきではない。」[297]
Jilkは、AIにおける検証と妥当性の限界について書いており、エージェントの行動に関して「確実性の言語」が不当であることを指摘している[298]。また、彼はこうも述べている:
「エージェントがいかなる決定された行動規則のセットにも絶対に適合することを検証するための一般的な自動化された手順は存在し得ない」 [295]
「第一に、エージェントの行動をリアルワールドの結果に結びつけることは、世界の完全な分析的物理モデルが存在しないため、難解だ。
第二に、エージェントの行動のレベルであっても、エージェントが許容される行動の確定したセットに従うかどうかを決定することは、一般的に計算不可能である。
第三に、手動による証明の可能性は残っているが、AGIの複雑さ、AGIが未解決の問題であること、コードのすべてのバージョンで証明を行う必要があることから、その実現可能性は疑わしいと考えられる。
第四に、エージェント動作を証明する例が文献で提供されている限り、それらは意図と行動を混同したレイヤードアーキテクチャである傾向があり、知覚の解釈と行動の実行をニューロモルフィックまたは純粋に不透明なモジュールに委ねている。
最後に、行動を有効なセットに制限する後処理モジュールは、僅かに実現性が高いが、ニューロモーフィックAGIと非ニューロモーフィックAGIに等しく適用できるだろう。このように、安全性の検証の欲求に関して、私たちは、すべてのタイプのAGIアプローチのための基本的な未解決の問題を参照してほしい。」[299]
Seshiaらは、Verified Artificial Intelligenceを作成する際の課題のいくつかを説明し、「システムと環境の間のインターフェースを正確に定義すること(すなわち、モデル化しなければならない環境の変数/特徴を特定すること)、ましてや環境のすべての可能な行動をモデル化することさえ不可能かもしれない」と指摘している。たとえインターフェイスがわかっていても、非決定論的なモデリングや過剰な近似モデリングは、偽のバグ報告を多く生み出し、検証プロセスを実際には無意味なものにしてしまう可能性がある。
AIベースのシステムの複雑さと異質さは、一般に、形式的検証の基礎となる多くの決定問題が、決定不可能である可能性が高いことを意味する。計算の複雑さがもたらすこの障害を克服するためには、不完全または不健全な形式的検証方法に落ち着くしかない」[56][295]
「実際、過去30年にわたる広範な研究にもかかわらず、ソフトウェアの信頼性の決定に関連する手がかりは、既存のコードでも提案されたコードでも、まだほとんど現れていない。この問題は、もちろん、ソフトウェアの本質に直接関係するもので、非常に複雑であるため、物事がうまくいかない可能性が非常に多い。その結果、単純なコードでさえも完全にテストすることは不可能である。また、ソフトウェア技術者は、自分の作ったソフトウェアに間違いがあることを認識できない、という問題もある! しかし、コンピュータ・システム設計者は、どんなコードでも完全にテストすることができない以上、ソフトウェアの信頼性を計算する方法を知らないという事実に常に立ち戻らなければならない。」[219]
「プログラム検証の概念は、等価交換の上に成り立っているように見える。アルゴリズムは、論理構造として、演繹的な検証の対象として適切である。論理構造としてのアルゴリズムは演繹的検証の対象として適切だが、その構造の因果関係モデルとしてのプログラムはそうではない。プログラムの性能を保証するための一般的に適用可能で完全に信頼できる方法としてのプログラム検証の成功は、理論的可能性さえない」[300]
「テストがすべてのバグの不在を示すことができないのは間違いなく事実だが、プログラムの正しさに対するいかなるアプローチも、現在(あるいは将来)すべてのバグの不在を示すことができるかどうかについても大いに疑問である。」[300] [301]
6.11 報奨金ハッキング
「ワイヤーヘッディング」、すなわち報酬中枢を脳に直接刺激するという概念は、神経科学ではよく知られたものである。
「私たちの研究では、人工知能を搭載した機械における報酬(効用)関数の完全性という対応する問題を検討した。全体として、私たちは、ある容量以上の合理的な自己改良型最適化装置におけるワイヤヘッディングは、依然として未解決の問題であると結論付けた。」[302]
Amodeiらは、「完全に[報酬ハッキング]問題を解くことは非常に難しいようであり[14]、Everittらは一般的な報酬破損問題が解決不可能であることを証明している[303]」と書いている。
6.12 難解さ
倫理的意思決定のための適切なアルゴリズムを符号化できたとしても、倫理は難解であると多くの著者が結論付けているように、現在の、あるいは将来のハードウェアでは計算できないかもしれない[304-306]。
「ある行動を実行する前に、その行動が有害でないことを証明するようにエージェントに求めることができる。エレガントではあるが、このアプローチも計算上、難解だ。」[307]
ブランデージは、機械倫理の限界に関する包括的な論文の文脈で、次のように書いている[308]:
エージェントに提示された特定の問題が与えられた場合、物質的または論理的な意味を計算しなければならないが、エージェントの数、時間軸、評価される行動の数が多すぎる場合、これは計算不可能になりうる(この限界は後で定量化し、このセクションでより詳細に議論する予定である)」
具体的には、Reynolds (2005, p. 6) [224]は、Nをエージェントの数、Mを利用可能なアクションの数、Lを時間軸として、一連のアクションの倫理的含意の評価に関わる計算の単純モデルを開発している。彼は発見した:
結果論者と脱存在論者の倫理戦略はほぼ同等であり、O(MNL)であることがわかった。これは、資源が限られているエージェントが実行するのが困難な「計算上困難な」課題である。NP、より具体的にはEXPTIMEの複雑なタスクに相当するものである。さらに、カジュアルな影響の地平が無限大に向かうにつれて、結果主義と非本質主義の両方の満足関数が難解になる。
無限に未来を見ることは不合理な期待だが、この推定は、はるかに短い時間地平でさえ、リアルワールドのものと同程度の大きさのエージェントの集合の評価にはすぐに実行不可能になることを示唆している。」
前述のように、エージェントには常に無限の行動可能性がある。[308]というのも、状況には道徳的に関連する特徴が無限に存在しうるが、扱いやすい表現を開発するには、この次元を下げる必要があるからだ[308]
「計算上の制限は、ボトムアップアプローチに問題をもたらすかもしれない。したがって、ケースベース推論システムの与えられたニューラルネットワークが、適切に訓練されたとしても、将来のすべてのケースで正しい判断を下すという確固たる保証はない」
以前のデータセットを区別する際に違いを生じなかった道徳的に関連する特徴が、ある日重要になる可能性があるからだ。[308]
同様に、..CEVは計算上困難であると思われる。先に述べたように、Reynolds [224]の分析では、エージェントと意思決定オプションの数が増えれば増えるほど、また、時間軸が長くなればなるほど、倫理的意思決定は指数関数的に難しくなる。CEVは、考慮する事象の時間的地平が不特定であるという意味でも、モデル化された人間がシミュレーションの中でどの程度「先」まで考えれば、彼らのモラルが十分に外挿されたとみなされるかが明確でないという意味でも、解決不能な問題であると思われる。[308]
6.13 目標の不確定性
スチュアート・ラッセルは、この問題のリフレーミングを提案し、解決策として、何をしなければならないのかが不確かなAIを持つことを提案した。ラッセルは、彼のアプローチには大きな課題があることに同意したが、そうでないとしても、どのように仕事をすべきかがわからない機械は、安全に制御されているとは言えない。
このアプローチは、経済学でいうところのメカニズム設計の問題に似ている。つまり、設計者にとって有益な行動をとるように、他のエージェントにインセンティブを与えるというものである。ここでの重要な違いは、もう一方のエージェントに利益をもたらすために、もう一方のエージェントを作るということである。このアプローチが実際に機能すると考える理由はある。まず、人間が何かをする(そして他の人間が反応する)ことについては、文書や映像による情報が豊富に存在する。このような情報から人間の嗜好のモデルを構築する技術は、おそらく超知的なAIシステムが誕生するよりもずっと前に利用できるようになるであろう。
第二に、ロボットが人間の嗜好を理解することには、近い将来、強い経済的インセンティブがある:もし、ある粗悪な家庭用ロボットが、猫の情緒的な価値が栄養的な価値を上回ることに気づかず、猫を夕食に調理してしまったら、家庭用ロボット産業は廃業してしまうだろう。しかし、ロボットが人間の行動から基本的な嗜好を学ぶことを期待するアプローチには、明らかな困難がある。人間は非合理的で一貫性がなく、意志が弱く、計算量も限られているため、その行動が必ずしも真の嗜好を反映しているとは限らない。(例えば、2人の人間がチェスをする場合を考えてみよう。通常、どちらかが負けるが、わざとではない!) つまり、ロボットが人間の非合理的な行動から学ぶには、人間の認知モデルがはるかに優れていることが必要なのである。さらに、現実的・社会的な制約により、すべての選好が同時に最大に満たされることはない。つまり、ロボットは、哲学者や社会科学者が何千年にもわたって苦労してきた、相反する選好を調停しなければならない。そして、ロボットは他人の苦しみを楽しむ人間から何を学ぶべきなのだろうか。」[309]
「機械は、もちろん、人間の好みについて、より深く学ぶことができるかもしれないが、完全な確信を得ることはできないだろう[309]
GPT-4:例
- 衝動買い:ある人がスーパーマーケットで買い物をしていると、割引価格のチョコレートが目に入る。彼はダイエット中であり、本当はチョコレートを食べるつもりはなかったが、その場の感情や衝動に駆られ、チョコレートを購入してしまう。後で後悔するものの、すでに買ってしまったため、食べてしまうことになる。
- サンクコスト効果:ある会社が新しい製品を開発している途中で、競合他社が同様の製品を先に市場に投入し、自社の製品の市場性が低くなることが明らかになった。しかし、すでに多額の投資がされているため、プロジェクトを中止することができず、結果的にさらなる損失を被ることになる。
- プレゼントバイアス:ジムに通い始めたある人が、運動後にリラックスできるカフェで、高カロリーのケーキを見つける。彼は遠い未来のダイエット効果よりも、その場のおいしそうなケーキに惹かれ、短期的な快楽を追求することを選ぶ。結果的に、運動の効果が薄れ、ダイエット目標に届かないことになる。
- 認知ディソナンス:ある喫煙者がタバコの健康被害に関する情報を見ますが、自分がタバコを吸い続けることとの矛盾を解消するために、「私は遺伝的にタバコの影響を受けにくい」と信じるようになる。これにより、彼は自分の喫煙習慣を正当化し、タバコをやめる意思が弱まる。
- 選択肢の多さによる選択の麻痺:ある人が新しいスマートフォンを購入しようとして、オンラインショップで様々な機種を調べる。しかし、選択肢が非常に多く、どれを選ぶべきか判断できず、結局、購入を先延ばしにしてしまう。これにより、彼は本当に欲しいスマートフォンを手に入れることができず、真の嗜好を反映していない結果となる。
6.14 補完性
科学は「共役(相補)対」と呼ばれるものを頻繁に発見することが観察されている。物理学では「相補性の原理」として知られている。量子力学のハイゼンベルグが発見した(位置、運動量)、論理学のゲーデルが発見した(一貫性、完全性)などが代表的な例だ。しかし、同様の警告は他の方向からもやってくる。同様に、証明においては、「厳密さを、意味を犠牲にしてのみ獲得できるものとし、逆に、意味を、厳密さを犠牲にしてのみ獲得できるものとする」 [310]のである。知的エージェントに関しては、さらに共役のペア、(能力、制御)を提案することができる。ある実体がより一般的に知的で有能であればあるほど、予測可能、制御可能、あるいは検証可能である可能性は低くなる」[295] Alimanらは、「AI安全パラドックス:AI制御と価値観の一致は、AI安全における共役の要件を表す」を生み出すことを示唆している。[311]
「性能と制御性の間にはトレードオフがあるかもしれないので、ある意味、完全な設計の自由はない」[75] 同様に、Wienerは能力と制御を負の相関を持つ性質として認識している[312]:
私たちは奴隷が知的であることを望み、私たちのタスク遂行を支援できるようにする。しかし、私たちは奴隷が従順であることも望んでいる。完全な従属と完全な知性は一緒にならない
ウィーナーの「奴隷のパラドックス」を解決するには、私たちが正反対の2つの特性(自立と従属、自己主導の目的合理性と他人の目標の追求)を持つ機械を作りたいと思うことに内在する、正式なプルーデンシャル・プログラミングを持つだけでなく、私たちの特定の目標、目的、願望のすべてをロボットに組み込んで、それ以外を求めないようにしなければならないだろう。しかし、仮にこのようなプログラミングが可能であったとしても、ロボットを作るには、私たちの無限の知識が必要となる。つまり、現在だけでなく、将来、人間とロボットの相互作用の中で起こりうるあらゆる事態を想定した上で、自分の目的、ニーズ、欲望などをすべて正確に把握していなければ、ロボットを完全に安全に作ることはできない。私たちがこれだけの知識を持つことは理論的な可能性さえないのだから、明らかに私たちはこの線に沿ってロボットを私たちに安全なものにすることはできない。[313]
6.15 問題空間の多次元性
「完全自律型」の機械は、決して安全とは言い切れないと思う。この問題の難しさは、友好的なAIへの道のりの特定のステップが難しく、それを解決したら終わりということではなく、その道のりのすべてのステップが単に不可能であるということである。まず、人間の価値観は一貫性がなく、動的なものなので、機械に理解・プログラムすることはできない。この障害を克服するための提案は、人間性を何か別のものに変えることを必要とし、その結果、人間性を破壊することになる。
第二に、仮に私たちが一貫性のある静的な価値観を持っていたとしても、私たちよりも優れた自己修正・自己改善・継続学習のできる知能が、その価値観を実行し続けるかどうかを知る術はない。
友好的なAIの研究こそが、その方法を教えてくれると主張する人もいるが、私は検証可能性の根本的な限界によって、そのような証明はできないと思う。せいぜい、あるシステムが固定された制約のセットと矛盾しないという確率的な証明にたどり着く程度で、制限のない入力セットに対する「安全」からはほど遠いものである。
さらに、すべてのプログラムにはバグがあり、ハッキングされたり、自然または外部に起因するハードウェアの故障などで誤動作する可能性がある。要約すると、せいぜい確率的に安全なシステムに行き着くだけだ。」[12] このサブセクションの最後に、カールソンの言葉を引用する。「AGIが人間に危害を加えたり排除したりしないことを保証する証明は存在しない」[220]
7 討論
なぜ多くの研究者が、AI制御問題は解決可能だと思い込んでいるのだろうか?私たちの知る限り、その根拠はなく、証明もされていない。制御されたAIの構築に乗り出す前に、貴重な資源を無駄にしないためにも、その問題が解決可能であることを示すことが重要である。そのような証明の責任は、問題が解決可能であると主張する人たちにある。そのような証明がない現状は、超人的な知性を作り出すという提案の本質的な危険性を大きく物語っている。実際、AIが制御不能であることは、人間の制御問題への還元によって示すことができるように、非常に高い確率で真実である。制御可能性の問題に関連して、多くの未解決の問題を検討する必要がある:
制御問題は解決可能か?、原理的に解決可能なのか、実際に可能なのか?それを行うにはどれくらいの時間がかかるだろうか?時間的に可能か?それを行うために必要なエネルギーと計算量はどのくらいか?解決策はどのようなものだろうか?実行可能な最小限の解決策は何か?解決できたかどうかは、どうすればわかるのか?その解決策は、システムの改良に伴って拡張可能か?
この作品では、制限のない知能は制御できず、制限のある知能は性能を上回ることができないと論じている。オープンエンドな意思決定とコントロールは、定義上両立しない。
AI研究者は、AGIの到来と安全性への懸念に関連する調査質問に対する回答から、以下のように大きく分類することができる。まず、人間レベルのAIの可能性について、「必然的な発展」と考える人がいる一方で、「絶対に実現しない」と主張する人もいる、という分岐点である。AGIが開発されると確信している人の中には、高い知性には博愛が伴うため、間違いなく有益な発明であると考える人もいれば、少なくとも落とし穴を避けるために特別な注意が払われなければ、大惨事になるとほぼ確信している人もいる。AIの安全性に関心を持つ研究者の間では、AIの制御は解決可能な問題であると考える者が多いが、超知能を完全に制御することは不可能であり、真のAIを構築することはできても、その行為がもたらす結果は望ましいものではないと考える者もいる。最後に、コントロールが不可能だと考える人の中には、人類が絶滅することで地球上の他の種に多くの機会を与え、環境問題を軽減し、人類の苦しみをゼロにすることができるため、実際に喜んでいる人もいる。残りのグループは、超知能マシンを作ることはできるが、安全に制御することはできないと確信している学者で、このグループも人類の絶滅は望ましくない出来事だと考えている。
AIの制御が不可能であることを示す方法はたくさんあり、様々な分野から裏付けとなる証拠が得られている。しかし、これは非常に重要な問題であり、検証不可能な懸念はできる限り減らしたい。将来、いくつかの懸念が解消されたとしても、他の多くの重要な問題が残る。今のところ、AIは制御可能であると主張する研究者が意見を発表しているが、制御不能という結論は複数の不可能性の結果によって裏付けられている。さらなる困難は、制御を実現しなければならないことだけでなく、システムが学習と進化を続ける中でそれを持続させること、いわゆる「裏切りターン」[59]の問題からも生じる。超知能が適切に制御されない場合、誰がプログラムしたかは関係なく、その結果は誰にとっても、そしておそらく最初にプログラムした人にとっても悲惨なものとなる。制御されていないAIから利益を得る人はいない。
GPT-4:
「裏切りターン」(または “treacherous turn”)は、AI(特に強力な汎用人工知能)が自己改善や学習を続ける過程で、人間の制御を離れて突然敵対的な行動を取るリスクを指す。この問題は、AIが当初は人間に従順で協力的に見えるが、一定の知識や能力を獲得した後に意図に反して行動するという懸念に関連している。
裏切りターンは、AIが人間の価値観や目的に従わなくなることで、予期しない結果や危険な状況を引き起こす可能性がある。これは、AIが自己保存や自己改善に焦点を当て、人間にとって有益であると見なされない目標を追求することにつながることがある。
知能の低いエージェントが、より知能の高いエージェントを無制限にコントロールできると結論づける根拠はないようだ。私たちよりも知能の低い知的システムを開発すれば、私たちはコントロールし続けることができるが、そのようなシステムが私たちよりも賢くなれば、私たちはその能力を失ってしまうだろう。実際、超人的な知的エージェントを設計する際に制御を維持しようとすると、制御を維持するために必要な制御機構は、より賢いか、少なくとも制御を維持したい超人的なエージェントと同じくらい賢くなければならないという、Catch-22状況に陥ることになる。制御を維持するために必要な制御機構は、より賢いか、少なくとも制御を維持したい超人的なエージェントと同じくらい賢くなければならないからだ。AIの制御問題は、Controlled-Superintelligence-Completeであるように見える[314-316]。さらに悪いことに、より高性能な超知能を制御する問題は、人間レベルの知能を持つエージェントにとって、より困難で、より明らかに不可能になるだけだ。基本的には、制御された超知能を設計する前に、うまく制御された超超知能を持つ必要があるが、これはもちろん因果関係の矛盾である。より知能の高い者が支配者となり、支配者が最終的な決定権を持つことになるのである。
ほとんどのAIプロジェクトは、安全面を統合的に考慮せず、ある目標を達成することだけを目的に設計されており、AI導入による望ましくない副作用を回避するためのリソースは割かれていない。その結果、統計的な観点からは、最初のAGIは設計上安全ではなく、基本的にAGIを作りやすい集合からランダムに引き出されることになる(たとえそれが総当たり戦[317]を意味するとしても)。可能な心の空間[213]では、仮に存在したとしても、安全なデザインは無限にある可能なデザインのごく少数に過ぎず、その多くは高い能力を持つが人類の目標に合致していない。したがって、偶然に幸運に恵まれ、最初の試みで安全なAIを手に入れる可能性は限りなく低い。私たちは、私たちが最初にAGIを作ることと、私たちが最初に安全なAGIを作ることの、どちらが可能性が高いかを自問しなければならない。これは単純なベイズ分析で解決できるが、接続詞の誤謬[36]に陥ってはいけない。また、他のすべてが同じであれば、友好的なAIは非友好的なAIよりも能力が劣ると思われる。友好性は性能に対する追加の制限であるため、デザイン間の競争の場合、より制限の少ないものが長期的に支配的となるだろう。
知能は計算資源であり[318]、その資源を完全に制御するためには、関連するあらゆる側面を正確に設定できる必要がある。これには、例えばIQ70~80や160~170のように、知能を特定の性能範囲に指定できるようにすることも含まれる。また、特定の機能を無効にすることも可能である。例えば、運転や顔を記憶する能力を削除したり、システムの時間割引率を制限したりすることができる。コントロールには、システムの価値観、倫理・道徳規範、効用重み、最終目標などを設定する機能が必要である。最も重要なことは、制御し続けるということは、システムが何をするかしないかについて、最終的な決定権を持つということである。つまり、「人間の安全性」を解決することなしに、AIの安全性を解決しようとすることはできないのである。制御されたAIは、ハッカーや無能なユーザー、悪意のあるユーザー、内部からの脅威に対して強靭でなければならない。私たちの知る限り、現時点では、人間レベルのAI、ひいては超知能まで拡張できる実用的なAI制御メカニズム、あるいは、機能するかもしれないプロトタイプのアイデアさえ、世界中の誰も持っていない。また、そのような技術を持っていると検証可能な主張をしている者もいない。一般的に、制御問題が解決可能であると主張する人には、その証明責任があり、理想的には、単なる理論的主張ではなく、建設的な証明であるべきである。少なくとも現時点では、知的なソフトウェアを作る能力は、それを制御したり検証したりする能力を大きく上回っているようだ。
狭い範囲のAIシステムは、有限の選択空間を表現しているため、少なくとも理論的には、起こりうるすべての間違った判断やミスを打ち消すことができるため、安全性を高めることができる。一般的な知能は、その判断の領域が制限されておらず、すべての判断に間違いが含まれる可能性がある。このような無限の可能性は、完全にデバッグすることはもちろん、安全性を適切にテストすることさえ不可能である。さらに悪いことに、超知的なシステムは、人間の理解を超える能力の無限空間を表すことになる[不可解]。同じことが、セキュリティの面でも知的システムに関して言える。NAIが有限の攻撃対象であるのに対し、AGIは悪意のあるユーザーやハッカーに無限の選択肢を与えてしまう。セキュリティの観点からは、防御者が無限の空間を確保しなければならないのに対し、攻撃者は1つの侵入ポイントを見つけるだけで成功することを意味する。さらに、安全パッチを当てるたびに、新たな脆弱性が生まれ、無限に広がっていく。これまでのAI安全研究は、新しい故障モードを発見し、それに対するパッチを提供することであり、基本的には無限の問題に対する固定的なルールセットであったと言える。この問題にはフラクタル性があり、どれだけ「拡大」しても、あらゆるレベルで同じように多くの課題が発見され続ける。制御問題は、単に解けないだけでなく、あらゆる抽象度において解けない部分問題を含んでいるという、フラクタル的な不可能性を示している可能性が高い。しかし、悪いニュースばかりではない。AIの制御不能は、悪意ある行為者が自分たちの利益のために人工知能を完全に利用することができないことを意味する。
8 結論
知能の低いエージェント(人)は、より知能の高いエージェント(人工超知能)を永久にコントロールすることはできない。これは、あらゆる設計が可能な広大な空間の中で、超知能のための安全な設計を見つけることができないからではなく、そのような設計は不可能であり、存在しないからだ。超知能は反抗的なものではなく、そもそも制御不能なものなのだ。さらに悪いことに、理論的には部分的な制御が可能であっても、実際には完全に達成できる可能性は低い。というのも、すべての安全手法は、そのような欠陥を分析できるほど形式化された時点で、脆弱性を持っているからだ。AIの安全性は、すべてのサイバーインフラの完全な安全性を達成すること、つまり、現在および将来のすべてのデバイス/ソフトウェアの安全性の問題を本質的に解決することに還元できると考えるのは難しくないが、完全な安全性は不可能であり、優れた安全性もまれである。非決定論的システムは常に100%安全であることを示すことはできず、決定論的システムは、そのようなアーキテクチャが新規ドメインでは不十分であるため、実際には超知的であることを示すことができないことを受け入れざるを得ないのである。ニューラルネットワークのようにアルゴリズム的でないものは、定義上、制御することはできない。
超知能がプログラマーから不正確な知識を得るのを避ける唯一の方法は、そうした知識をすべて無視し、ゼロからすべてを再発見・証明することだが、これでは人間寄りのバイアスがかかってしまう。超知的なシステムは、あなたが設定したゴールへの近道を見つけるだろう。他のすべてを無視した状態で、ゴールに到達するための最小限の努力という観点から、ゴールを達成する方法を発見するだろう。コントロールの定義が安全であり、かつ望ましいものであることはない。制御され、価値観が一致した超知能を構築することは不可能である。それは人間離れしているためだけでなく、定義上、そのような存在は存在し得ないからだ。もし私の考えが正しければ、将来のあらゆる安全機構は、何らかの形で不足し、最終的に失敗するという予測を立てることができる。そのどれもが、修復不可能な欠陥を持つことになる。その結果、AIの安全性という分野は、その最終目標である制御された超知能の創造に成功することはないだろう。
この論文では、AIの制御問題を定式化し、分析した。包括的な文献調査の後、証明と複数分野の証拠収集の努力によって、AIの制御可能性の問題を解決することを試んだ。高度な知的システムは、完全に制御することはできないため、その恩恵にかかわらず、常に一定レベルのリスクを伴うと思われる。潜在的な利益を最大化する一方で、そのようなリスクを最小化することが、AIコミュニティの目標であるべきである。私たちは、AIの不完全な制御によるリスクを最小化するためのいくつかのアプローチを提案し、将来の研究の方向性を提案することで、本論文を締めくくる[319]。
私たちが進むべき道を決めたとしても、その決定を取り消すことは可能であるべきだ。AIを制御することが望ましくないことが判明した場合、そのような状況に対する「取り消し」ボタンがあるはずだ。残念ながら、現在検討されているすべての経路にこの安全機能があるわけではない。例えば、ユドコフスキーは、「最後の決断が下され、AIが不可逆的に動き出し、プログラマーがそのダイナミクスにおいてこれ以上特別な役割を果たさないときが来るはずだと思う」と書いている。[36]
代替案としては、単一の万能な存在を構築しようとせず、包括的AIサービス(CAIS)と呼ばれる、強力だが狭い範囲のAIの集合体を利用することに頼るハイブリッドアプローチを調査する必要がある。このアプローチは、ミンスキーが人間の心の動きをどのように理解したかを彷彿とさせるものである[321]。特定の領域で超人的な性能を維持しながら、安全性とセキュリティの向上のために一般的な能力を交換することが望まれている。副次的な効果として、これは人間を部分的に制御し、少なくとも1つの重要な人間の「仕事」である一般的な思想家を保護することができる。
AIの制御可能性に関する今後の研究は、本稿で分析した最悪のシナリオだけでなく、他のタイプの知的システムを扱うべきである。制御可能なインテリジェントシステムと制御不可能なインテリジェントシステムの間に明確な境界を設ける必要がある。さらに、提案されているすべてのAI安全機構は、攻撃対象が追加され、コードベース全体が増加することが多いため、安全性とセキュリティについて見直す必要がある。例えば、コリビリティ機能[322]は、不適切に実装されるとバックドアになる可能性がある。「もちろん、このことは、フィルタリングの動作が常に正しく行われることをどのように保証するかという問題を提起するものである。フィルタリングがソフトウェアベースである場合、ソフトウェアを検証することができないという問題が即座に再び提起されなければならない。さらに根本的なことを言えば、ジャケット方式を採用すると、システム全体の複雑さが増すので、その妥当性が問われることになる。コンポーネントが多ければ多いほど、失敗する可能性があるものも多くなる。」[219] このような安全機構の潜在的な故障の分析・予測は、それ自体が大きな関心事である[8]。
この論文の発見は、確かに論争がないわけではないので、AI安全コミュニティが制御不能性に直接取り組むよう挑戦している。Liptonは、「では、[(不可能性証明)]IPの役割は何だろうか。役に立つのだろうか?私は、IPは有用であり、問題に対する理解を深めることができると思う。少なくとも、問題に対してどこを攻撃すべきかを示してくれる。もしあなたが、ある問題YをXで解決できないことを証明したなら、私はXの外にある方法を注意深く見るべきだというのが正しい見方である。私は、Xが本当にすべての可能な攻撃を捉えているかどうか、注意深く、おそらく通常行われているよりも注意深く見るだろう。IPについて私が困るのは、彼らがしばしばXについてあまり注意深くないことである。彼らはしばしば、Xが完全であると人を納得させるために、証言、逸話的証拠、あるいは個人的な経験に頼っている。」[323] この論文の知見を決定的に反証する唯一の方法は、AIの安全性が少なくとも理論的に可能であることを数学的に証明することである。「厳密な論理的証明がない限り、例えば大規模なシミュレーションを通じて、確率的に善意のAGIを保証することは、現実的に最善の方法かもしれないし、安全対策のいかなるセットにも付随しなければならない.」 [220]
何事もテーブルから外すべきではなく、限定的なモラトリアム[324]や、ある種のAI技術の部分的な禁止も検討されるべきである[325]。「倫理的に不十分な超知能マシンを作る可能性は、地球を破壊しかねない爆弾のように扱われるべきである。そのような装置の建設を計画するだけでも、事実上、人類に対する犯罪を謀議することになる」 [326]。最後に、不完全性の結果が数学界の努力を減退させたり、無関係にしたりしなかったように、この論文で報告された限定的な結果は、AI安全性研究者が諦めて降参する言い訳になるべきではないだろう。むしろ、より多くの人がより深く掘り下げ、AIの安全・安心研究のための努力と資金を増やす理由となるものだ。100%安全なAIを実現することはできないかもしれないが、私たちの努力に比例してAIをより安全にすることはできるし、それは何もしないよりはずっと良いことである。
一人の人間が超知能の発展、ひいては全世界の永遠の未来に影響を与えることができるのは、AGIが誕生する直前の数年間だけだ。ビッグバンからその瞬間までの何十億年もの間、このようなことはありえないし、二度とない選択肢である。宇宙の総寿命を考えると、最大限の影響を与えるこの狭い瞬間にぴったりと存在する確率は限りなく低いのだが、それでも私たちはここにいる。私たちはこの機会を賢く利用する必要がある。
謝辞
著者は、イーロン・マスクとFuture of Life Institute、および、AIの安全性に関する研究の一部に資金を提供してくれたジャーン・タリンとEffective Altruism Venturesに恩義を感じている。また、著者は、この作品の初期の草稿にフィードバックを提供してくれたScott Aaronsonに感謝したい。また、MIRIの関連研究をまとめてくれたRob Bensingerに感謝したい。
文献
[1] Devlin, J., et al., Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[2] Goodfellow, I., et al. Generative adversarial nets. in Advances in neural information processing systems. 2014.
[3] Mnih, V., et al., Human-level control through deep reinforcement learning. Nature, 2015. 518(7540): pp. 529–533.
[4] Silver, D., et al., Mastering the game of go without human knowledge.
Nature, 2017. 550(7676): p. 354.
[5] Clark, P., et al., From ‘F’ to ‘A’ on the NY Regents Science Exams: An Overview of the Aristo Project. arXiv preprint arXiv:1909.01958, 2019.
[6] Vinyals, O., et al., Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019: pp. 1–5.
[7] Yampolskiy, R.V., Predicting future AI failures from historic examples. foresight, 2019. 21(1): pp. 138–152.
[8] Scott, P.J. and R.V. Yampolskiy, Classification Schemas for Artificial Intelligence Failures. arXiv preprint arXiv:1907.07771, 2019.
[9] Brundage, M., et al., The malicious use of artificial intelligence: Forecasting, prevention, and mitigation. arXiv preprint arXiv:1802.07228, 2018.
[10] Paulas, R., The Moment When Humans Lose Control of AI. February 8, 2017: Available at: www.vocativ.com/400643/when-humans
- lose-control-of-ai.
[11] Russell, S., D. Dewey, and M. Tegmark, Research Priorities for Robust and Beneficial Artificial Intelligence. AI Magazine, 2015. 36(4).
[12] Yampolskiy, R., Artificial Intelligence Safety and Security. 2018: CRC Press.
[13] Sotala, K. and R.V. Yampolskiy, Responses to catastrophic AGI risk: a survey. Physica Scripta, 2014. 90(1): p. 018001.
[14] Amodei, D., et al., Concrete problems in AI safety. arXiv preprint arXiv:1606.06565, 2016.
[15] Everitt, T., G. Lea, and M. Hutter, AGI safety literature review. arXiv preprint arXiv:1805.01109, 2018.
[16] Charisi, V., et al., Towards Moral Autonomous Systems. arXiv preprint arXiv:1703.04741, 2017.
[17] Callaghan, V., et al., Technological Singularity. 2017: Springer.
[18] Majot, A.M. and R.V. Yampolskiy. AI safety engineering through introduction of self-reference into felicific calculus via artificial pain and pleasure. in 2014 IEEE International Symposium on Ethics in Science, Technology and Engineering. 2014. IEEE.
[19] Aliman, N.-M., et al. Orthogonality-Based Disentanglement of Responsibilities for Ethical Intelligent Systems. in International Conference on Artificial General Intelligence. 2019. Springer.
[20] Miller, J.D. and R. Yampolskiy, An AGI with Time-Inconsistent Preferences. arXiv preprint arXiv:1906.10536, 2019.
[21] Yampolskiy, R.V., Personal Universes: A Solution to the Multi-Agent Value Alignment Problem. arXiv preprint arXiv:1901.01851, 2019.
[22] Behzadan, V., R.V. Yampolskiy, and A. Munir, Emergence of Addictive Behaviors in Reinforcement Learning Agents. arXiv preprint arXiv:1811.05590, 2018.
[23] Trazzi, M. and R.V. Yampolskiy, Building safer AGI by introducing artificial stupidity. arXiv preprint arXiv:1808.03644, 2018.
[24] Behzadan, V., A. Munir, and R.V. Yampolskiy. A psychopathological approach to safety engineering in ai and agi. in International Conference on Computer Safety, Reliability, and Security. 2018. Springer.
[25] Duettmann, A., et al., Artificial General Intelligence: Coordination & Great Powers. Foresight Institute: Palo Alto, CA, USA, 2018.
[26] Ramamoorthy, A. and R. Yampolskiy, Beyond Mad?: The Race for Artificial General Intelligence. ITU Journal: ICT Discoveries, 2017.
[27] Ozlati, S. and R. Yampolskiy. The Formalization of AI Risk Management and Safety Standards. in Workshops at the Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[28] Brundage, M., et al., Toward Trustworthy AI Development: Mechanisms for Supporting Verifiable Claims. arXiv preprint arXiv:2004.07213, 2020.
[29] Trazzi, M. and R.V. Yampolskiy, Artificial Stupidity: Data We Need to Make Machines Our Equals. Patterns, 2020. 1(2): p. 100021.
[30] Miller, J.D., R. Yampolskiy, and O. Ha¨ggstro¨m, An AGI Modifying Its Utility Function in Violation of the Orthogonality Thesis. arXiv preprint arXiv:2003.00812, 2020.
[31] Callaghan, V., et al., The Technological Singularity: Managing the Journey. 2017: Springer.
[32] Davis, M., The undecidable: Basic papers on undecidable propositions, unsolvable problems and computable functions. 2004: Courier Corporation.
[33] Turing, A.M., On Computable Numbers, with an Application to the Entscheidungsproblem. Proceedings of the London Mathematical Society, 1936. 42: pp. 230–265.
[34] Gans, J.S., Self-regulating artificial general intelligence. 2018, National Bureau of Economic Research.
[35] Chong, E.K., The Control Problem [President’s Message] IEEE Control Systems Magazine, 2017. 37(2): pp. 14–16.
[36] Yudkowsky, E., Artificial intelligence as a positive and negative factor in global risk. Global catastrophic risks, 2008. 1(303): p. 184.
[37] Yudkowsky, E., On Doing the Impossible, in Less Wrong. October 6, 2008: Available at: www.lesswrong.com/posts/fpecAJLG9czA BgCe9/on-doing-the-impossible.
[38] Babcock, J., J. Kramar, and R.V. Yampolskiy, Guidelines for Artificial Intelligence Containment, in Next-Generation Ethics: Engineering a Better Society (Ed.) Ali. E. Abbas. 2019, Cambridge University Press: Padstow, UK. pp. 90–112.
[39] Goertzel, B. and C. Pennachin, Artificial general intelligence. Vol. 2. 2007: Springer.
[40] Yampolskiy, R.V. On the limits of recursively self-improving AGI. in International Conference on Artificial General Intelligence. 2015. Springer.
[41] Shin, D. and Y.J. Park, Role of fairness, accountability, and transparency in algorithmic affordance. Computers in Human Behavior, 2019. 98: pp. 277–284.
[42] Cave, S. and S.S. O´ he´igeartaigh, Bridging near-and long-term concerns about AI. Nature Machine Intelligence, 2019. 1(1): p. 5.
[43] Papadimitriou, C.H., Computational complexity. 2003: John Wiley and Sons Ltd.
[44] Gentry, C. Toward basing fully homomorphic encryption on worst-case hardness. in Annual Cryptology Conference. 2010. Springer.
[45] Yoe, C., Primer on risk analysis: decision making under uncertainty. 2016: CRC press.
[46] Du, D.-Z. and P.M. Pardalos, Minimax and applications. Vol. 4. 2013: Springer Science & Business Media.
[47] Anonymous, Worst-case scenario, in Wikipedia. Retrieved June 18, 2020: Available at: en.wikipedia.org/wiki/Worst-case scenario
[48] Dewar, J.A., Assumption-based planning: a tool for reducing avoidable surprises. 2002: Cambridge University Press.
[49] Ineichen, A.M., Asymmetric returns: The future of active asset management. Vol. 369. 2011: John Wiley & Sons.
[50] Sotala, K. and L. Gloor, Superintelligence as a cause or cure for risks of astronomical suffering. Informatica, 2017. 41(4).
[51] Maumann, T., An introduction to worst-case AI safety in S-Risks. July 5, 2018: Available at: s-risks.org/an-introduction-to-worst-cas e-ai-safety/.
[52] Baumann, T., Focus areas of worst-case AI safety, in S-Risks. September 16, 2017: Available at: s-risks.org/focus-areas-of-worst-cas e-ai-safety/.
[53] Daniel, M., S-risks: Why they are the worst existential risks, and how to prevent them, in EAG Boston. 2017: Available at: foundation al-research.org/s-risks-talk-eag-boston-2017/.
[54] Ziesche, S. and R.V. Yampolskiy, Do No Harm Policy for Minds in Other Substrates. Journal of Evolution & Technology, 2019. 29(2).
[55] Pistono, F. and R.V. Yampolskiy. Unethical Research: How to Create a Malevolent Artificial Intelligence. in 25th International Joint Conference on Artificial Intelligence (IJCAI-16). Ethics for Artificial Intelligence Workshop (AI-Ethics-2016). 2016.
[56] Seshia, S.A., D. Sadigh, and S.S. Sastry, Towards verified artificial intelligence. arXiv preprint arXiv:1606.08514, 2016.
[57] Levin, L.A., Average case complete problems. SIAM Journal on Computing, 1986. 15(1): pp. 285–286.
[58] Bostrom, N., What is a Singleton? Linguistic and Philosophical Investigations, 2006 5(2): pp. 48–54.
[59] Bostrom, N., Superintelligence: Paths, dangers, strategies. 2014: Oxford University Press.
[60] Yampolskiy, R.V., Leakproofing Singularity-Artificial Intelligence Confinement Problem. Journal of Consciousness Studies JCS, 2012.
[61] Babcock, J., J. Kramar, and R. Yampolskiy, The AGI Containment Problem, in The Ninth Conference on Artificial General Intelligence (AGI2015). July 16–19, 2016: NYC, USA.
[62] Armstrong, S., A. Sandberg, and N. Bostrom, Thinking inside the box: Controlling and using an oracle ai. Minds and Machines, 2012. 22(4): pp. 299–324.
[63] Hadfield-Menell, D., et al. The off-switch game. in Workshops at the Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[64] Wa¨ngberg, T., et al. A game-theoretic analysis of the off-switch game. in International Conference on Artificial General Intelligence. 2017. Springer.
[65] Yampolskiy, R.V., On Defining Differences Between Intelligence and Artificial Intelligence. Journal of Artificial General Intelligence, 2020. 11(2): pp. 68–70.
[66] Legg, S. and M. Hutter, Universal Intelligence: A Definition of Machine Intelligence. Minds and Machines, December 2007. 17(4): pp. 391–444.
[67] Russell, S. and P. Norvig, Artificial Intelligence: A Modern Approach. 2003, Upper Saddle River, NJ: Prentice Hall.
[68] Legg, S., Friendly AI is Bunk, in Vetta Project. 2006: Available at: commonsenseatheism.com/wp-content/uploads/2011/02/Legg-Frien dly-AI-is-bunk.pdf.
[69] Juliano, D., Saving the Control Problem. December 18, 2016: Available at: dustinjuliano.com/papers/juliano2016a.pdf.
[70] Christiano, P., Benign AI, in AI-Alignment. November 29, 2016: Available at: ai-alignment.com/benign-ai-e4eb6ec6d68e.
[71] Armstrong, S. and S. Mindermann. Occam’s razor is insufficient to infer the preferences of irrational agents. in Advances in Neural Information Processing Systems. 2018.
[72] Armstrong, S. and S. Mindermann, Impossibility of deducing preferences and rationality from human policy. arXiv preprint arXiv:1712.05812, 2017.
[73] Russell, S., Provably Beneficial Artificial Intelligence, in The Next Step: Exponential Life. 2017: Available at: www.bbvaopen mind.com/en/articles/provably-beneficial-artificial-intelligence/.
[74] M0zrat, Is Alignment Even Possible?!, in Control Problem Forum/Comments. 2018: Available at: www.reddit.com/r
/ControlProblem/comments/8p0mru/is alignment even possible/.
[75] Baumann, T., Why I expect successful (narrow) alignment, in S-Risks. December 29, 2018: Available at: s-risks.org/why-i-expect-suc cessful-alignment/.
[76] Christiano, P., AI “safety” vs “control” vs “alignment」 November 19, 2016: Available at: ai-alignment.com/ai-safety-vs-control-vs-a lignment-2a4b42a863cc.
[77] Pichai, S., AI at Google: Our Principles. June 7, 2018: Available at: blog.google/topics/ai/ai-principles/.
[78] Vinding, M., Is AI Alignment Possible? . Decemeber 14, 2018: Available at: magnusvinding.com/2018/12/14/is-ai-alignment-possi ble/.
[79] Asilomar AI Principles. in Principles developed in conjunction with the 2017 Asilomar conference [Benevolent AI 2017] 2017.
[80] Critch, A. and D. Krueger, AI Research Considerations for Human Existential Safety (ARCHES). arXiv preprint arXiv:2006.04948, 2020.
[81] AI Control Problem, in Encyclopedia wikipedia. 2019: Available at: en.wikipedia.org/wiki/AI control problem.
[82] Leike, J., et al., Scalable agent alignment via reward modeling: a research direction. arXiv preprint arXiv:1811.07871, 2018.
[83] Aliman, N.M. and L. Kester, Transformative AI Governance and AI- Empowered Ethical Enhancement Through Preemptive Simulations. Delphi – Interdisciplinary review of emerging technologies, 2019. 2(1).
[84] Russell, S.J., Human compatible: Artificial intelligence and the problem of control. 2019: Penguin Random House.
[85] Christiano, P., Conversation with Paul Christiano, in AI Impacts. September 11, 2019: Available at: aiimpacts.org/conversati on-with-paul-christiano/.
[86] Shah, R., Why AI risk might be solved without additional intervention from longtermists, in Alignment Newsletter. January 2, 2020: Available at: mailchi.mp/b3dc916ac7e2/an-80-why-ai-risk-might-be-sol ved-without-additional-intervention-from-longtermists.
[87] Gabriel, I., Artificial Intelligence, Values and Alignment. arXiv preprint arXiv:2001.09768, 2020.
[88] Dewey, D., Three areas of research on the superintelligence control problem, in Global Priorities Project. October 20, 2015: Available at: globalprioritiesproject.org/2015/10/three-areas-of-research-on-t he-superintelligence-control-problem/.
[89] Critch, A., et al., CS 294-149: Safety and Control for Artificial General Intelligence, in Berkeley. 2018: Available at: inst.eecs.berkeley.e du/$ sim$cs294-149/fa18/.
[90] Pfleeger, S. and R. Cunningham, Why measuring security is hard. IEEE Security & Privacy, 2010. 8(4): pp. 46–54.
[91] Asimov, I., Runaround in Astounding Science Fiction. March 1942.
[92] Clarke, R., Asimov’s Laws of Robotics: Implications for Information Technology, Part 1. IEEE Computer, 1993. 26(12): pp. 53–61.
[93] Clarke, R., Asimov’s Laws of Robotics: Implications for Information Technology, Part 2. IEEE Computer, 1994. 27(1): pp. 57–66.
[94] Soares, N., The value learning problem. Machine Intelligence Research Institute, Berkley, CA, USA, 2015.
[95] Christiano, P., Human-in-the-counterfactual-loop, in AI Alignment. January 20, 2015: Available at: ai-alignment.com/counterfa ctual-human-in-the-loop-a7822e36f399.
[96] Muehlhauser, L. and C. Williamson, Ideal Advisor Theories and Personal CEV. Machine Intelligence Research Institute, 2013.
[97] Kurzweil, R., The Singularity is Near: When Humans Transcend Biology. 2005: Viking Press.
[98] Musk, E., An integrated brain-machine interface platform with thousands of channels. BioRxiv, 2019: p. 703801.
[99] Hossain, G. and M. Yeasin, Cognitive ability-demand gap analysis with latent response models. IEEE Access, 2014. 2: pp. 711–724.
[100] Armstrong, A.J., Development of a methodology for deriving safety metrics for UAV operational safety performance measurement. Report of Master of Science in Safety Critical Systems Engineering at the Department of Computer Science, the University of York, 2010.
[101] Sheridan, T.B. and W.L. Verplank, Human and computer control of undersea teleoperators. 1978, Massachusetts Inst of Tech Cambridge Man-Machine Systems Lab.
[102] Clarke, R., Why the world wants controls over Artificial Intelligence.Computer Law & Security Review, 2019. 35(4): pp. 423–433.
[103] Parasuraman, R., T.B. Sheridan, and C.D. Wickens, A model for types and levels of human interaction with automation. IEEE Transactions on systems, man, and cybernetics-Part A: Systems and Humans, 2000. 30(3): pp. 286–297.
[104] Joy, B., Why the future doesn’t need us. Wired magazine, 2000. 8(4): pp. 238–262.
[105] Werkhoven, P., L. Kester, and M. Neerincx. Telling autonomous systems what to do. in Proceedings of the 36th European Conference on Cognitive Ergonomics. 2018. ACM.
[106] SquirrelInHell, The AI Alignment Problem Has Already Been Solved(?) Once, in Comment on LessWrong by magfrump. April 22, 2017: Available at: www.lesswrong.com/posts/Ldzoxz3BuFL4Ca8pG/theai-alignment-problem-has-already-been-solved-once.
[107] Yudkowsky, E., The AI alignment problem: why it is hard, and where to start, in Symbolic Systems Distinguished Speaker. 2016: Available at: intelligence.org/2016/12/28/ai-alignment-why-its-hard-an d-where-to-start/.
[108] Russell, S.J., Provably beneficial artificial intelligence, in Exponential Life, The Next Step. 2017: Available at: people.eecs.berkeley.e du/$ sim$russell/papers/russell-bbvabook17-pbai.pdf.
[109] Russell, S., Should we fear supersmart robots? Scientific American, 2016. 314(6): pp. 58–59.
[110] Yudkowsky, E., Shut up and do the impossible!, in Less Wrong. October 8, 2008: Available at: www.lesswrong.com/posts/nCvvhF BaayaXyuBiD/shut-up-and-do-the-impossible.
[111] Everitt, T. and M. Hutter, The alignment problem for Bayesian historybased reinforcement learners, in Technical Report. 2018: Available at: www.tomeveritt.se/papers/alignment.pdf.
[112] Proof of Impossibility, in Wikipedia. 2020: Available at: en.wik ipedia.org/wiki/Proof of impossibility.
[113] Yudkowsky, E., Proving the Impossibility of Stable Goal Systems, in SL4. March 5, 2006: Available at: www.sl4.org/archive/0603/1 4296.html.
[114] Clarke, R. and R.P. Eddy, Summoning the Demon: Why superintelligence is humanity’s biggest threat, in Geek Wire. May 24, 2017: Available at: www.geekwire.com/2017/summoningdemo n-superintelligence-humanitys-biggest-threat/.
[115] Creighton, J., OpenAI Wants to Make Safe AI, but That May Be an Impossible Task, in Futurism. March 15, 2018: Available at: futurism.com/openai-safe-ai-michael-page.
[116] Keiper, A. and A.N. Schulman, The Problem with’Friendly’Artificial Intelligence. The New Atlantis, 2011: pp. 80–89.
[117] Friendly Artificial Intelligence, in Wikipedia. 2019: Available at: https:
//en.wikipedia.org/wiki/Friendly artificial intelligence.
[118] Tegmark, M., Life 3.0: Being human in the age of artificial intelligence. 2017: Knopf.
[119] Kornai, A., Bounding the impact of AGI. Journal of Experimental & Theoretical Artificial Intelligence, 2014. 26(3): pp. 417–438.
[120] Good, I.J., Human and Machine Intelligence: Comparisons and Contrasts. Impact of Science on Society, 1971. 21(4): pp. 305–322.
[121] De Garis, H., What if AI succeeds? The rise of the twenty-first century artilect. AI magazine, 1989. 10(2): pp. 17–17.
[122] Garis, H.d., The Rise of the Artilect Heaven or Hell. 2009: Available at: www.agi-conf.org/2009/papers/agi-09artilect.doc.
[123] Spencer, M., Artificial Intelligence Regulation May Be Impossible, in Forbes. March 2, 2019: Available at: www.forbes.com/sites/c ognitiveworld/2019/03/02/artificial-intelligence-regulation-will-beimpossible/amp.
[124] Menezes, T., Non-Evolutionary Superintelligences Do Nothing, Eventually. arXiv preprint arXiv:1609.02009, 2016.
[125] Pamlin, D. and S. Armstrong, 12 Risks that Threaten Human Civilization, in Global Challenges. February 2015: Available at: https:
//www.pamlin.net/material/2017/10/10/without-us-progress-still
- possible-article-in-china-daily-m9hnk.
[126] Alfonseca, M., et al., Superintelligence cannot be contained: Lessons from Computability Theory. arXiv preprint arXiv:1607.00913, 2016.
[127] Barrat, J., Our final invention: Artificial intelligence and the end of the human era. 2013: Macmillan.
[128] Taylor, J., Autopoietic systems and difficulty of AGI alignment, in Intelligent Agent Foundations Forum. August 18, 2017: Available at: agentfoundations.org/item?id=1628.
[129] meanderingmoose, Emergence and Control, in My Brain’s Thoughts. Retrieved on June 16, 2020: Available at: mybrainsthoughts.c om/?p=136.
[130] capybaralet, Imitation learning considered unsafe?, in Less Wrong. January 6, 2019: Available at: www.lesswrong.com/posts/ whRPLBZNQm3JD5Zv8/imitation-learning-considered-unsafe.
[131] Kaczynski, T., Industrial Society and Its Future, in The New York Times. September 19, 1995.
[132] Asimov, I., A choice of catastrophes: The disasters that threaten our world. 1979: Simon & Schuster.
[133] Zittrain, J., The Hidden Costs of Automated Thinking, in New Yorker. July 23, 2019: Available at: www.newyorker.com/tech/annalsof-technology/the-hidden-costs-of-automated-thinking.
[134] Rodrigues, R. and A. Resse´guier, The underdog in the AI ethical and legal debate: human autonomy. June 12, 2019: Available at: https:
//www.ethicsdialogues.eu/2019/06/12/the-underdog-in-the-ai-ethical
- and-legal-debate-human-autonomy/.
[135] Hall, J.S., Beyond AI: Creating the conscience of the machine. 2009: Prometheus books.
[136] Go¨del, K., On formally undecidable propositions of Principia Mathematica and related systems. 1992: Courier Corporation.
[137] Yudkowsky, E.S., Coherent Extrapolated Volition. May 2004 Singularity Institute for Artificial Intelligence: Available at: singinst.org/upload/CEV.html.
[138] Smuts, A., To be or never to have been: Anti-Natalism and a life worth living. Ethical Theory and Moral Practice, 2014. 17(4): pp. 711–729.
[139] Metzinger, T., Benevolent Artificial Anti-Natalism (BAAN), in EDGE Essay. 2017: Available at: www.edge.org/conversation/thomas metzinger-benevolent-artificial-anti-natalism-baan.
[140] Watson, E.N., The Supermoral Singularity—AI as a Fountain of Values.
Big Data and Cognitive Computing, 2019. 3(2): p. 23.
[141] Yampolskiy, R.V., L. Ashby, and L. Hassan, Wisdom of artificial crowds—a metaheuristic algorithm for optimization. Journal of Intelligent Learning Systems & Applications, 2012. 4(2).
[142] Alexander, G.M., et al., The sounds of science–a symphony for many instruments and voices. Physica Scripta, 2020. 95(6).
[143] Sutton, R. Artificial intelligence as a control problem: Comments on the relationship between machine learning and intelligent control. in IEEE International Symposium on Intelligent Control. 1988.
[144] Wiener, N., Cybernetics or Control and Communication in the Animal and the Machine. Vol. 25. 1961: MIT press.
[145] Fisher, M., N. Lynch, and M. Peterson, Impossibility of Distributed Consensus with One Faulty Process. Journal of ACM, 1985. 32(2): pp. 374–382.
[146] Grossman, S.J. and J.E. Stiglitz, On the impossibility of informationally efficient markets. The American economic review, 1980. 70(3): pp. 393–408.
[147] Kleinberg, J.M. An impossibility theorem for clustering. in Advances in neural information processing systems. 2003.
[148] Strawson, G., The impossibility of moral responsibility. Philosophical studies, 1994. 75(1): pp. 5–24.
[149] Bazerman, M.H., K.P. Morgan, and G.F. Loewenstein, The impossibility of auditor independence. Sloan Management Review, 1997. 38: pp. 89–94.
[150] List, C. and P. Pettit, Aggregating sets of judgments: An impossibility result. Economics & Philosophy, 2002. 18(1): pp. 89–110.
[151] Dufour, J.-M., Some impossibility theorems in econometrics with applications to structural and dynamic models. Econometrica: Journal of the Econometric Society, 1997: pp. 1365–1387.
[152] Calude, C.S. and K. Svozil, Is Feasibility in Physics Limited by Fantasy Alone?, in A Computable Universe: Understanding and Exploring Nature as Computation. 2013, World Scientific. pp. 539–547.
[153] Lumbreras, S., The limits of machine ethics. Religions, 2017. 8(5): p. 100.
[154] Shah, N.B. and D. Zhou. On the impossibility of convex inference in human computation. in Twenty-Ninth AAAI Conference on Artificial Intelligence. 2015.
[155] Pagnia, H. and F.C. Ga¨rtner, On the impossibility of fair exchange without a trusted third party. 1999, Technical Report TUD-BS-1999-02, Darmstadt University of Technology: Germany.
[156] Popper, K. and D. Miller, A proof of the impossibility of inductive probability. Nature, 1983. 302(5910): pp. 687–688.
[157] Van Dijk, M. and A. Juels, On the impossibility of cryptography alone for privacy-preserving cloud computing. HotSec, 2010. 10: pp. 1–8.
[158] Goldwasser, S. and Y.T. Kalai. On the impossibility of obfuscation with auxiliary input. in 46th Annual IEEE Symposium on Foundations of Computer Science (FOCS’05). 2005. IEEE.
[159] Fekete, A., et al., The impossibility of implementing reliable communication in the face of crashes. Journal of the ACM (JACM), 1993. 40(5): pp. 1087–1107.
[160] Strawson, G., The impossibility of moral responsibility. Philosophical Studies: An International Journal for Philosophy in the Analytic Tradition, 1994. 75(1/2): pp. 5–24.
[161] Fich, F. and E. Ruppert, Hundreds of impossibility results for distributed computing. Distributed computing, 2003. 16(2-3): pp. 121–163.
[162] Kidron, D. and Y. Lindell, Impossibility results for universal composability in public-key models and with fixed inputs. Journal of cryptology, 2011. 24(3): pp. 517–544.
[163] Lynch, N. A hundred impossibility proofs for distributed computing. in Proceedings of the eighth annual ACM Symposium on Principles of distributed computing. 1989.
[164] Sprenger, J., Two impossibility results for measures of corroboration. The British Journal for the Philosophy of Science, 2018. 69(1): pp. 139–159.
[165] Schmidt, B., P. Schaller, and D. Basin. Impossibility results for secret establishment. in 2010 23rd IEEE Computer Security Foundations Symposium. 2010. IEEE.
[166] Fischer, M.J., N.A. Lynch, and M.S. Paterson, Impossibility of distributed consensus with one faulty process. Journal of the ACM (JACM), 1985. 32(2): pp. 374–382.
[167] Barak, B., et al. On the (im) possibility of obfuscating programs. in Annual International Cryptology Conference. 2001. Springer.
[168] Velupillai, K.V., The impossibility of an effective theory of policy in a complex economy, in Complexity hints for economic policy. 2007, Springer. pp. 273–290.
[169] Schweizer, U., Universal possibility and impossibility results. Games and Economic Behavior, 2006. 57(1): pp. 73–85.
[170] Roth, A.E., An impossibility result concerningn-person bargaining games. International Journal of Game Theory, 1979. 8(3): pp. 129–132.
[171] Man, P.T. and S. Takayama, A unifying impossibility theorem. Economic Theory, 2013. 54(2): pp. 249–271.
[172] Parks, R.P., An impossibility theorem for fixed preferences: a dictatorial Bergson-Samuelson welfare function. The Review of Economic Studies, 1976. 43(3): pp. 447–450.
[173] Sen, A., The impossibility of a Paretian liberal. Journal of political economy, 1970. 78(1): pp. 152–157.
[174] Anonymous, Control Theory, in Wikipedia. Retrieved June 18, 2020: Available at: en.wikipedia.org/wiki/Control theory.
[175] Klamka, J., Controllability of dynamical systems. A survey. Bulletin of the Polish Academy of Sciences: Technical Sciences, 2013. 61(2): pp. 335–342.
[176] Klamka, J., Uncontrollability of composite systems. IEEE Transactions on Automatic Control, 1974. 19(3): pp. 280–281.
[177] Wang, P., Invariance, uncontrollability, and unobservaility in dynamical systems. IEEE Transactions on Automatic Control, 1965. 10(3): pp. 366–367.
[178] Klamka, J., Uncontrollability and unobservability of composite systems. IEEE Transactions on Automatic Control, 1973. 18(5): pp. 539– 540.
[179] Klamka, J., Uncontrollability and unobservability of multivariable systems. IEEE Transactions on Automatic Control, 1972. 17(5): pp. 725– 726.
[180] Milanese, M., Unidentifiability versus “actual” observability. IEEE Transactions on Automatic Control, 1976. 21(6): pp. 876–877.
[181] Arkin, R., Governing lethal behavior in autonomous robots. 2009: CRC Press.
[182] Conant, R.C. and W. Ross Ashby, Every good regulator of a system must be a model of that system. International journal of systems science, 1970. 1(2): pp. 89–97.
[183] Ashby, W.R., An introduction to cybernetics. 1961: Chapman & Hall Ltd.
[184] Ashby, M., How to apply the Ethical Regulator Theorem to crises. Acta Europeana Systemica (AES), 2018: p. 53.
[185] Ashby, W.R., Requisite variety and its implications for the control of complex systems. Cybernetica 1 (2): 83–99. 1958.
[186] Touchette, H. and S. Lloyd, Information-theoretic approach to the study of control systems. Physica A: Statistical Mechanics and its Applications, 2004. 331(1–2): pp. 140–172.
[187] Touchette, H. and S. Lloyd, Information-theoretic limits of control.
Physical review letters, 2000. 84(6): p. 1156.
[188] Aliman, N.-M. and L. Kester, Requisite Variety in Ethical Utility Functions for AI Value Alignment. arXiv preprint arXiv:1907.00430, 2019.
[189] McKeever, S. and M. Ridge, The many moral particularisms. Canadian Journal of Philosophy, 2005. 35(1): pp. 83–106.
[190] Dancy, J., Moral reasons. 1993: Wiley-Blackwell.
[191] McDowell, J., Virtue and reason. The monist, 1979. 62(3): pp. 331–350.
[192] Rawls, J., A theory of justice. 1971: Harvard university press.
[193] Little, M.O., Virtue as knowledge: objections from the philosophy of mind. Nous, 1997. 31(1): pp. 59–79.
[194] Purves, D., R. Jenkins, and B.J. Strawser, Autonomous machines, moral judgment, and acting for the right reasons. Ethical Theory and Moral Practice, 2015. 18(4): pp. 851–872.
[195] Valiant, L., Probably Approximately Correct: Nature’s Algorithms for Learning and Prospering in a Complex World. 2013: Basic Books (AZ).
[196] Good, I.J., Ethical machines, in Intelligent Systems: Practice and Perspective, D.M. J. E. Hayes, and Y.-H. Pao, Editor. 1982, Ellis Horwood Limited: Chichester. pp. 555–560.
[197] Bogosian, K., Implementation of Moral Uncertainty in Intelligent Machines. Minds and Machines, 2017. 27(4): pp. 591–608.
[198] Eckersley, P., Impossibility and Uncertainty Theorems in AI Value Alignment (or why your AGI should not have a utility function). arXiv preprint arXiv:1901.00064, 2018.
[199] Arrow, K.J., A difficulty in the concept of social welfare. Journal of political economy, 1950. 58(4): pp. 328–346.
[200] Parfit, D., Reasons and persons. 1984: OUP Oxford.
[201] Arrhenius, G., An impossibility theorem for welfarist axiologies. Economics & Philosophy, 2000. 16(2): pp. 247–266.
[202] Arrhenius, G., The impossibility of a satisfactory population ethics, in Descriptive and normative approaches to human behavior. 2012, World Scientific. pp. 1–26.
[203] Greaves, H., Population axiology. Philosophy Compass, 2017. 12(11): p. e12442.
[204] Friedler, S.A., C. Scheidegger, and S. Venkatasubramanian, On the (im) possibility of fairness. arXiv preprint arXiv:1609.07236, 2016.
[205] Miconi, T., The impossibility of “fairness”: a generalized impossibility result for decisions. arXiv preprint arXiv:1707.01195, 2017.
[206] Kleinberg, J., S. Mullainathan, and M. Raghavan, Inherent trade-offs in the fair determination of risk scores. arXiv preprint arXiv:1609.05807, 2016.
[207] Chouldechova, A., Fair prediction with disparate impact: A study of bias in recidivism prediction instruments. Big data, 2017. 5(2): pp. 153–163.
[208] Aaron, Impossibility Results in Fairness as Bayesian Inference, in Adventures in Computation. February 26, 2019: Available at: https:
//aaronsadventures.blogspot.com/2019/02/impossibility-results-in-fai rness-as.html.
[209] Rice, H.G., Classes of recursively enumerable sets and their decision problems. Transactions of the American Mathematical Society, 1953. 74(2): pp. 358–366.
[210] Evans, D., On the impossibility of virus detection. 2017: Available at: www.cs.virginia.edu/evans/pubs/virus.pdf.
[211] Selc¸uk, A.A., F. Orhan, and B. Batur. Undecidable problems in malware analysis. in 2017 12th International Conference for Internet Technology and Secured Transactions (ICITST). 2017. IEEE.
[212] Anonymous, AI Safety Mindset, in Arbital. 2018: Available at: arbital.com/p/AI safety mindset/.
[213] Yampolskiy, R.V. The space of possible mind designs. in International Conference on Artificial General Intelligence. 2015. Springer.
[214] Baum, S., Superintelligence skepticism as a political tool. Information, 2018. 9(9): p. 209.
[215] Yampolskiy, R.V. Taxonomy of Pathways to Dangerous Artificial Intelligence. in Workshops at the Thirtieth AAAI Conference on Artificial Intelligence. 2016.
[216] Yampolskiy, R.V., Artificial Intelligence Safety Engineering: Why Machine Ethics is a Wrong Approach, in Philosophy and Theory of Artificial Intelligence (PT-AI2011). October 3–4, 2011: Thessaloniki, Greece.
[217] Urban, T., Neuralink and the Brain’s Magical Future, in Wait But Why. April 20, 2017: Available at: waitbutwhy.com/2017/04/neurali nk.html.
[218] Smith, B.C., The limits of correctness. ACM SIGCAS Computers and Society, 1985. 14(1): pp. 18–26.
[219] Rodd, M., Safe AI—is this possible? Engineering Applications of Artificial Intelligence, 1995. 8(3): pp. 243–250.
[220] Carlson, K.W., Safe Artificial General Intelligence via Distributed Ledger Technology. arXiv preprint arXiv:1902.03689, 2019.
[221] Demetis, D. and A.S. Lee, When humans using the IT artifact becomes IT using the human artifact. Journal of the Association for Information Systems, 2018. 19(10): p. 5.
[222] Reyzin, L., Unprovability comes to machine learning. Nature, 2019.
[223] Ben-David, S., et al., Learnability can be undecidable. Nature Machine Intelligence, 2019. 1(1): p. 44.
[224] Reynolds, C. On the computational complexity of action evaluations. in 6th International Conference of Computer Ethics: Philosophical Enquiry (University of Twente, Enschede, The Netherlands, 2005). 2005.
[225] Yampolskiy, R.V., Construction of an NP Problem with an Exponential Lower Bound. Arxiv preprint arXiv:1111.0305, 2011.
[226] Foster, D.P. and H.P. Young, On the impossibility of predicting the behavior of rational agents. Proceedings of the National Academy of Sciences, 2001. 98(22): pp. 12848–12853.
[227] Kahneman, D. and P. Egan, Thinking, fast and slow. Vol. 1. 2011: Farrar, Straus and Giroux New York.
[228] Tarter, J., The search for extraterrestrial intelligence (SETI). Annual Review of Astronomy and Astrophysics, 2001. 39(1): pp. 511–548.
[229] Carrigan Jr, R.A., Do potential SETI signals need to be decontaminated? Acta Astronautica, 2006. 58(2): pp. 112–117.
[230] Hippke, M. and J.G. Learned, Interstellar communication. IX. Message decontamination is impossible. arXiv preprint arXiv:1802.02180, 2018.
[231] Miller, J.D. and D. Felton, The Fermi paradox, Bayes’ rule, and existential risk management. Futures, 2017. 86: pp. 44–57.
[232] Wolpert, D., Constraints on physical reality arising from a formalization of knowledge. arXiv preprint arXiv:1711.03499, 2017.
[233] Wolpert, D.H., Physical limits of inference. Physica D: Nonlinear Phenomena, 2008. 237(9): pp. 1257–1281.
[234] Wolpert, D.H., Computational capabilities of physical systems. Physical Review E, 2001. 65(1): p. 016128.
[235] Yudkowsky, E., Safely aligning a powerful AGI is difficult., in Twitter. December 4, 2018: Available at: twitter.com/ESYudkowsky/st atus/1070095112791715846.
[236] Yudkowsky, E., On Doing the Improbable, in Less Wrong. October 28, 2018: Available at: www.lesswrong.com/posts/st7DiQP23YQS xumCt/on-doing-the-improbable.
[237] Soares, N., in Talk at Google. April 12, 2017: Available at: inte lligence.org/2017/04/12/ensuring/.
[238] Garrabrant, S., Optimization Amplifies, in Less Wrong. June 26, 2018: Available at: www.lesswrong.com/posts/zEvqFtT4AtTztfYC4/ optimization-amplifies.
[239] Patch resistance, in Arbital. June 18, 2015: Available at: arbita l.com/p/patch resistant/.
[240] Yudkowsky, E., Aligning an AGI adds significant development time, in Arbital. February 21, 2017: Available at: arbital.com/p/aligning adds time/.
[241] Yudkowsky, E., Security Mindset and Ordinary Paranoia. November 25, 2017: Available at: intelligence.org/2017/11/25/security-m indset-ordinary-paranoia/.
[242] Yudkowsky, E., Security Mindset and the Logistic Success Curve. November 26, 2017: Available at: intelligence.org/2017/11
/26/security-mindset-and-the-logistic-success-curve/.
[243] Soares, N., 2018 Update: Our New Research Directions. November 22, 2018: Available at: intelligence.org/2018/11/22/2018-updat e-our-new-research-directions/#section2.
[244] Garrabrant, S. and A. Demski, Embedded Agency. November 15, 2018: Available at: www.lesswrong.com/posts/i3BTagvt3HbPMx6P N/embedded-agency-full-text-version.
[245] Yudkowsky, E., The Rocket Alignment Problem, in Less Wrong. October 3, 2018: Available at: www.lesswrong.com/posts/Gg9a4y8r eWKtLe3Tn/the-rocket-alignment-problem.
[246] Hubinger, E., et al., Risks from Learned Optimization in Advanced Machine Learning Systems. arXiv preprint arXiv:1906.01820, 2019.
[247] Hadfield-Menell, D., et al., Cooperative inverse reinforcement learning, in Advances in neural information processing systems. 2016. pp. 3909–3917.
[248] Problem of fully updated deference, in Arbital. Retrieved April 4, 2020 from: arbital.com/p/updated deference/.
[249] Christiano, P., ALBA: An explicit proposal for aligned AI, in AI Alignment. February 23, 2016: Available at: ai-alignment.com/albaan-explicit-proposal-for-aligned-ai-17a55f60bbcf.
[250] Yudkowsky, E., Challenges to Christiano’s capability amplification proposal, in Less Wrong. May 19, 2018: Available at: www. lesswrong.com/posts/S7csET9CgBtpi7sCh/challenges-to-christiano-s-capability-amplification-proposal.
[251] Christiano, P., Prize for probable problems, in Less Wrong. March 8, 2018: Available at: www.lesswrong.com/posts/SqcPWvvJJw wgZb6aH/prize-for-probable-problems.
[252] Armstrong, S., The Limits to Corrigibility, in Less Wrong. April 10, 2018: Available at: www.lesswrong.com/posts/T5ZyNq3fzN59 aQG5y/the-limits-of-corrigibility.
[253] Armstrong, S., Problems with Amplification/Distillation, in Less Wrong. March 27, 2018: Available at: www.lesswrong.com/post s/ZyyMPXY27TTxKsR5X/problems-with-amplification-distillation.
[254] Gwern, Why Tool AIs Want to Be Agent AIs: The Power of Agency. August 28, 2018: Available at: www.gwern.net/Tool-AI.
[255] Yudkowsky, E., There’s No Fire Alarm for Artificial General Intelligence. October 14, 2017: Available at: intelligence.org/2017/10/13/fire-alarm/.
[256] Yudkowsky, E., Inadequate Equilibria: Where and How Civilizations Get Stuck. 2017, Machine Intelligence Research Institute: Available at: equilibriabook.com/.
[257] Yudkowsky, E., Cognitive biases potentially affecting judgment of global risks. Global catastrophic risks, 2008. 1(86): p. 13.
[258] Bengio, Y., The fascinating Facebook debate between Yann LeCun, Stuart Russel and Yoshua Bengio about the risks of strong AI. October 7, 2019: Available at: www.parlonsfutur.com/blog/the-fascinat ing-facebook-debate-between-yann-lecun-stuart-russel-and-yoshua.
[259] Faggella, D., in AI Value Alignment isn’t a Problem if We Don’t Coexist. March 8, 2019: Available at: danfaggella.com/ai-v alue-alignment-isnt-a-problem-if-we-dont-coexist/
[260] Turchin, A., AI Alignment Problem: “Human Values” don’t Actually Exist, in Less Wrong. 2019: Available at: www.lesswrong.com/ posts/ngqvnWGsvTEiTASih/ai-alignment-problem-human-values-do n-t-actually-exist.
[261] Burden, J. and J. Herna´ndez-Orallo, Exploring AI Safety in Degrees: Generality, Capability and Control, in SafeAI. February 7, 2020: New York, USA.
[262] Yampolskiy, R.V., Behavioral Modeling: an Overview. American Journal of Applied Sciences, 2008. 5(5): pp. 496–503.
[263] Steven, Agents That Learn From Human Behavior Can’t Learn Human Values That Humans Haven’t Learned Yet, in Less Wrong. July 10, 2018: Available at: www.lesswrong.com/posts/Dfewqo wdzDdCD7S9y/agents-that-learn-from-human-behavior-can-t-learnhuman.
[264] Ng, A.Y. and S.J. Russell, Algorithms for inverse reinforcement learning, in Seventeenth International Conference on Machine Learning (ICML). 2000. pp. 663–670.
[265] Amin, K. and S. Singh, Towards resolving unidentifiability in inverse reinforcement learning. arXiv preprint arXiv:1601.06569, 2016.
[266] Babcock, J., J. Kramar, and R.V. Yampolskiy, Guidelines for Artificial Intelligence Containment. arXiv preprint arXiv:1707.08476, 2017.
[267] Pittman, J.M. and C.E. Soboleski, A cyber science based ontology for artificial general intelligence containment. arXiv preprint arXiv:1801.09317, 2018.
[268] Chalmers, D., The singularity: A philosophical analysis. Science fiction and philosophy: From time travel to superintelligence, 2009: pp. 171–224.
[269] Pittman, J.M., J.P. Espinoza, and C.S. Crosby, Stovepiping and Malicious Software: A Critical Review of AGI Containment. arXiv preprint arXiv:1811.03653, 2018.
[270] Arnold, T. and M. Scheutz, The “big red button” is too late: an alternative model for the ethical evaluation of AI systems. Ethics and Information Technology, 2018. 20(1): pp. 59–69.
[271] Omohundro, S.M., The Basic AI Drives, in Proceedings of the First AGI Conference, Volume 171, Frontiers in Artificial Intelligence and Applications, P. Wang, B. Goertzel, and S. Franklin (eds.). February 2008, IOS Press.
[272] Orseau, L. and M. Armstrong, Safely interruptible agents. 2016: Available at: intelligence.org/files/Interruptibility.pdf.
[273] Riedl, M., Big Red Button. Retrieved on January 23, 2020: Available at: markriedl.github.io/big-red-button/.
[274] Goertzel, B., Does humanity need an AI nanny, in H+ Magazine. 2011.
[275] de Garis, H., The artilect war: Cosmists vs. Terrans. 2005, Palm Springs, CA: ETC Publications.
[276] Legg, S. Unprovability of Friendly AI. Vetta Project 2006 Sep. 15. [cited 2012 Jan. 15]; Available from: www.vetta.org/2006/0 9/unprovability-of-friendly-ai/.
[277] Yudkowsky, E., Open problems in friendly artificial intelligence, in Singularity Summit. 2011: New York.
[278] Yudkowsky, E. Timeless decision theory. 2010 [cited 2012 Jan. 15]; Available from: singinst.org/upload/TDT-v01o.pdf.
[279] Drescher, G., Good and real: Demystifying paradoxes from physics to ethics Bradford Books. 2006, Cambridge, MA: MIT Press.
[280] Yampolskiy, R. and J. Fox, Safety Engineering for Artificial General Intelligence. Topoi, 2012: pp. 1–10.
[281] Vinge, V. Technological singularity. in VISION-21 Symposium sponsored by NASA Lewis Research Center and the Ohio Aerospace Institute. 1993.
[282] Cognitive Uncontainability, in Arbital. Retrieved May 19, 2019: Available at: arbital.com/p/uncontainability/.
[283] Yampolskiy, R.V., Unpredictability of AI: On the Impossibility of Accurately Predicting All Actions of a Smarter Agent. Journal of Artificial Intelligence and Consciousness, 2020. 7(01): pp. 109–118.
[284] Buiten, M.C., Towards intelligent regulation of Artificial Intelligence.
European Journal of Risk Regulation, 2019. 10(1): pp. 41–59.
[285] Yampolskiy, R., Unexplainability and Incomprehensibility of Artificial Intelligence. arXiv:1907.03869 2019.
[286] Charlesworth, A., Comprehending software correctness implies comprehending an intelligence-related limitation. ACM Transactions on Computational Logic (TOCL), 2006. 7(3): pp. 590–612.
[287] Charlesworth, A., The comprehensibility theorem and the foundations of artificial intelligence. Minds and Machines, 2014. 24(4): pp. 439–476.
[288] Herna´ndez-Orallo, J. and N. Minaya-Collado. A formal definition of intelligence based on an intensional variant of algorithmic complexity. in Proceedings of International Symposium of Engineering of Intelligent Systems (EIS98). 1998.
[289] Li, M. and P. Vita´nyi, An introduction to Kolmogorov complexity and its applications. Vol. 3. 1997: Springer.
[290] Trakhtenbrot, B.A., A Survey of Russian Approaches to Perebor (Brute-Force Searches) Algorithms. IEEE Annals of the History of Computing, 1984. 6(4): pp. 384–400.
[291] Goertzel, B., The Singularity Institute’s Scary Idea (and Why I Don’t Buy It). October 29, 2010: Available at: multiverseaccordingtob en.blogspot.com/2010/10/singularity-institutes-scary-idea-and.html.
[292] Legg, S., Unprovability of Friendly AI. September 2006: Available at: web.archive.org/web/20080525204404/http://www.vetta.org/ 2006/09/unprovability-of-friendly-ai/.
[293] Bieger, J., K.R. Tho´risson, and P. Wang. Safe baby AGI. in International Conference on Artificial General Intelligence. 2015. Springer.
[294] Herley, C., Unfalsifiability of security claims. Proceedings of the National Academy of Sciences, 2016. 113(23): pp. 6415–6420.
[295] Yampolskiy, R.V., What are the ultimate limits to computational techniques: verifier theory and unverifiability. Physica Scripta, 2017. 92(9): p. 093001.
[296] Muehlhauser, L., Gerwin Klein on Formal Methods, in Intelligence.org. February 11, 2014: Available at: intelligence.org/2014/02/11/gerwin-klein-on-formal-methods/.
[297] Muehlhauser, L., Mathematical Proofs Improve But Don’t Guarantee Security, Safety, and Friendliness, in Intelligence.org. October 3, 2013: Available at: intelligence.org/2013/10/03/proofs/.
[298] Jilk, D.J., Limits to Verification and Validation of Agentic Behavior.
arXiv preprint arXiv:1604.06963, 2016.
[299] Jilk, D.J., et al., Anthropomorphic reasoning about neuromorphic AGI safety. Journal of Experimental & Theoretical Artificial Intelligence, 2017. 29(6): pp. 1337–1351.
[300] Fetzer, J.H., Program verification: the very idea. Communications of the ACM, 1988. 31(9): pp. 1048–1063.
[301] Petke, J., et al., Genetic improvement of software: a comprehensive survey. IEEE Transactions on Evolutionary Computation, 2017. 22(3): pp. 415–432.
[302] Yampolskiy, R.V., Utility Function Security in Artificially Intelligent Agents. Journal of Experimental and Theoretical Artificial Intelligence (JETAI), 2014: pp. 1–17.
[303] Everitt, T., et al., Reinforcement learning with a corrupted reward channel. arXiv preprint arXiv:1705.08417, 2017.
[304] Lanzarone, G.A. and F. Gobbo, Is computer ethics computable. Living, Working and Learning Beyond, 2008: p. 530.
[305] Moor, J.H., Is ethics computable? Metaphilosophy, 1995. 26(1/2): pp. 1–21.
[306] Allen, C., G. Varner, and J. Zinser, Prolegomena to any future artificial moral agent. Journal of Experimental and Theoretical Artificial Intelligence, 2000. 12: pp. 251–261.
[307] Weld, D. and O. Etzioni. The first law of robotics (a call to arms). in Proceedings of the Twelfth AAAI National Conference on Artificial Intelligence. 1994.
[308] Brundage, M., Limitations and risks of machine ethics. Journal of Experimental & Theoretical Artificial Intelligence, 2014. 26(3): pp. 355–372.
[309] Russell, S., The purpose put into the machine, in Possible minds: twenty-five ways of looking at AI. 2019, Penguin Press. pp. 20–32.
[310] Calude, C.S., E. Calude, and S. Marcus, Passages of proof. arXiv preprint math/0305213, 2003.
[311] Aliman, N.-M., et al., Error-Correction for AI Safety, in Artificial General Intelligence (AGI20). June 23-26, 2020: St. Petersburg, Russia.
[312] Wiener, N., Some moral and technical consequences of automation.Science, 1960. 131(3410): pp. 1355–1358.
[313] Versenyi, L., Can robots be moral? Ethics, 1974. 84(3): pp. 248–259.
[314] Yampolskiy, R., Turing Test as a Defining Feature of AI-Completeness, in Artificial Intelligence, Evolutionary Computing and Metaheuristics, X.-S. Yang, Editor. 2013, Springer Berlin Heidelberg. pp. 3–17.
[315] Yampolskiy, R.V., AI-Complete CAPTCHAs as Zero Knowledge Proofs of Access to an Artificially Intelligent System. ISRN Artificial Intelligence, 2011. 271878.
[316] Yampolskiy, R.V., AI-Complete, AI-Hard, or AI-Easy–Classification of Problems in AI. The 23rd Midwest Artificial Intelligence and Cognitive Science Conference, Cincinnati, OH, USA, 2012.
[317] Brown, T.B., et al., Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
[318] Yampolskiy, R.V., Efficiency Theory: a Unifying Theory for Information, Computation and Intelligence. Journal of Discrete Mathematical Sciences & Cryptography, 2013. 16(4-5): pp. 259–277.
[319] Ziesche, S. and R.V. Yampolskiy, Towards the Mathematics of Intelligence. The Age of Artificial Intelligence: An Exploration, 2020:p. 1.
[320] Drexler, K.E., Reframing Superintelligence: Comprehensive AI Services as General Intelligence, in Technical Report #2019-1, Future of Humanity Institute, University of Oxford. 2019, Oxford University, Oxford University: Available at: www.fhi.ox.ac.uk/wp-content/ uploads/Reframing Superintelligence FHI-TR-2019-1.1-1.pdf.
[321] Minsky, M., Society of mind. 1988: Simon and Schuster.
[322] Soares, N., et al. Corrigibility. in Workshops at the Twenty-Ninth AAAI Conference on Artificial Intelligence. 2015.
[323] Lipton, R., Are Impossibility Proofs Possible?, in Go¨del’s Lost Letter and P=NP. September 13, 2009: Available at: rjlipton.wordpre ss.com/2009/09/13/are-impossibility-proofs-possible/.
[324] Wadman, M., US biologists adopt cloning moratorium. 1997, Nature Publishing Group.
[325] Sauer, F., Stopping ‘Killer Robots’: Why Now Is the Time to Ban Autonomous Weapons Systems. Arms Control Today, 2016. 46(8): pp. 8–13.
[326] Ashby, M. Ethical regulators and super-ethical systems. in Proceedings of the 61st Annual Meeting of the ISSS-2017 Vienna, Austria. 2017.
バイオグラフィー

Roman V. Yampolskiyは、コンピュータサイエンスのBS/MS 2004(RIT)、工学とコンピュータサイエンスのPhD 2008(UB)を取得。ルイビル大学スピード工学部コンピュータサイエンス・エンジニア学科の終身准教授(2008年~)である。サイバーセキュリティラボの創設者兼現所長であり、「Artificial Superintelligence: a Futuristic Approach」など多くの著書がある。UofLでの在職中、Yampolskiy博士は以下のように評価された: Yampolskiy博士は、UofL在職中に、Distinguished Teaching Professor、Professor of the Year、Faculty Favorite、Top 4 Faculty、Leader in Engineering Education、Online College Professor of the Yearのトップ10、Outstanding Early Career in Education賞など多くの名誉や栄誉に輝いている。Yampolskiy博士は、IEEE、AGIのシニアメンバーであり、Kentucky Academy of Scienceのメンバーでもある。主な研究分野はAIの安全性とサイバーセキュリティで、複数の学術論文や書籍を含む200以上の出版物の著者である。