
Contents
How to Assess the External Validity and Model Validity of Therapeutic Trials: A Conceptual Approach to Systematic Review Methodology
www.ncbi.nlm.nih.gov/pmc/articles/PMC3963220/
オンラインで2014年1月19日に公開
Raheleh Khorsan 1 , 2 ,* and Cindy Crawford 3

keydifferences.com/difference-between-internal-and-external-validity.html
概要
背景
エビデンスランキングでは、補完代替医療/統合医療(CAM/IM)研究を含む臨床研究について、内的妥当性(IV)外的妥当性(EV)モデル妥当性(MV)を均等に考慮していない。本論文では、このモデルを説明し、IVに加えてEVとMVに基づいて研究を評価するためのEV評価ツール(EVAT©)を提供する。
方法
EV/MV基準で発表された文献を検索、収集、評価するために、略式のシステマティックレビュー方法を採用した。EV,MV,バイアススコアに関連するキーワードを用いて,標準的なデータベースを開設時から 2013年1月まで検索した。これらの品質基準を評価するための強固なツールを構築するために、特定されたツールと記述された概念をプールした。結果 本研究では、CAM/IM研究に敏感なEV/MV研究の質を評価するために、合理化された客観的なツールを構築した。
結論
EVに関する報告の改善は、政策立案者、公衆衛生研究者、およびその他の科学者が、研究で試された介入の選択、開発、および改善を行う際の指針となる情報を生み出し、提供するのに役立つ。全体として、高いEVを伴う臨床研究は、健康への介入の「リアルワールド」での結果について最も有用な情報を提供する可能性がある。IV、EV、MVを同等に考慮するこの新しいツールが、臨床上の意思決定のより良い指針となることを期待している。
1. はじめに
研究結果の外的妥当性とモデル的妥当性は、臨床的には重要な問題である。しかし、方法論的な観点から見ると、外的妥当性やモデル妥当性の概念は、一見するとはるかに複雑であるように思われる。より多くの情報に基づいたヘルスケアの決定を行うために、より多くのミックスメソッドデザインや比較効果研究が必要とされる時代に突入した今、研究の質を評価する上で、これらの問題に注意を払う必要がある。
ヘルスケア分野のシステマティックレビューでは、一般的に実験的な無作為化臨床対照試験(RCT)の質を評価する。これらのシステマティックレビューは、RCTの報告における方法論的バイアスを特定・評価し、特定の研究課題に関連する研究エビデンスを統合することを目的としている。そのため、システマティックレビューの結果は、医療における政策決定にしばしば適用され、最強の研究エビデンスとみなされることが多く、臨床治療に関する正確な意思決定を行うための重要な要素となっている。しかし、ほとんどの医療システマティックレビューにおける研究の質の評価は、内的妥当性に大きく依存した結果に基づいている。
1995年にMoherらは,無作為化試験のバイアスを評価するために使用された25の尺度と9つのチェックリストを特定した[1, 2]。最近では 2008年にOlivoらが、無作為化試験のバイアス評価に使用された21の尺度を特定している[3]。これらの品質評価尺度・チェックリストの大半は、内的妥当性に主眼を置き、盲検化、無作為化(無作為割付順序として知られる)割付隠蔽、離脱・脱落のみを評価している。なお、これらのツールの大半はスケールであり、システマティックレビューではスコアが集約されるが、コクラン共同計画などの組織は、システマティックレビューではスコアの集約を避けることを推奨している。実際、コクラン共同計画によると、スケールやチェックリストを用いてバイアスを評価する際に難しいのは、研究による不完全な報告と、スケールのカテゴリーに重みを割り当てる際の主観性である。つまり、盲検化と比較して、無作為化の重要性が高いのか低いのかということである。また、バイアス尺度では、研究方法を適切に実施することよりも、報告方法を重要視することがよくある[4]。
このような尺度は、特に医療に関する臨床的な意思決定を行う際に、RCTや非ランダム化研究を含めて、その情報が現実の状況にどのように適用されるのか、大多数のシステマティックレビューの質的分析を制限している可能性がある。
そのため,研究調査やシステマティックレビューのバイアスを評価する際には,Cochrane CollaborationのツールRisk of Bias [4],Consolidated Standards of Reporting Trials (CONSORT) [5],Grading of Recommendation, Assessment, Development, and Evaluation (GRADE) approach [6],Scottish Intercollegiate Guidelines Network (SIGN) [7]などのシステマティックレビューツールを用いることが望ましいとされている。
研究の質は多面的な概念であると考えている。このレビューでは,研究の質の概念と,それが内的妥当性,外的妥当性,モデル妥当性とどのように関連しているかについて述べている。また、質の評価に用いられる方法を概説し、著者らが開発した「外的妥当性評価ツール(EVAT©)」と呼ばれるツールを紹介する。このツールは、この分野の文献に既に見られるものを基に、より強固で合理的なものとなっており、内的妥当性の基準とともに、臨床試験における外的妥当性とモデル的妥当性の評価に用いることができる。
1.1. 試験品質の概念
妥当性とは?妥当性とは、研究から得られた結果が真実である可能性が高く、バイアスがかかっていない度合いのことである[8]。研究から得られた結果の解釈は、内的妥当性と外的妥当性の両方に依存する。一般的に実験的臨床試験では、介入の効果は、その試験に登録された人々に基づいて推定された結果に基づいて測定される。登録された個人は、「試験集団」または「試験サンプル」と呼ばれる。内的妥当性とは、研究結果と結論が研究集団に対して有効であるかどうかを意味する。したがって、以下の3つの基準を用いて因果推論(相互関係とも呼ばれる)が適切に証明されれば、その研究は内的妥当性を有すると結論づけることができる。(1)原因が結果に時間的に先行している(時間的先行性)(2)原因と結果が関連している(共変性)(3)原因以外に結果に対するもっともらしい代替説明がない(非スプリアス性)という3つの基準を用いて、因果推論(相互関係としても知られる)が適切に示されれば、研究は内的妥当性を有すると結論づけることができる[9]。したがって,実験研究は,(1)推定される原因を操作し,その後の結果を観察すること(治療効果),(2)原因の変動が効果の変動に関係しているかどうかを観察すること,(3)最後に,実験中に効果に対する他の説明の妥当性を低下させる方法を用いることによって,上記の基準を達成しようとするものである。したがって、真の実験は因果関係研究の「ゴールドスタンダード」と呼ばれ、システマティックレビューは、それらの真の実験を組み合わせて実験研究の総合的な効果を記述する最高の証拠となるのである。しかし、(A)人や測定変数の変動に対して因果関係が成り立つかどうかの推論(外的妥当性)と、(B)データが収集された特定の治療法や設定(モデル妥当性)を定義しなければ、妥当性の基準を満たすことは困難である。
内的妥当性は外的妥当性の前提条件であり、有効性と効果は連続的に存在すると考えられている[10, 11]。「系統的誤差により真の効果から乖離した研究結果は、一般化可能性の根拠を欠く」[11]とされている。一般化可能性がなければ、臨床試験の真の治療効果を評価することはできない。Dekkersら[11]が述べているように、「臨床医の観点からは、試験結果の一般化可能性が最も重要である。CONSORT声明によれば、無作為化臨床試験(RCT)を報告する際には、外的妥当性に取り組むべきである」と述べている[11, 12]。そうは言っても、ヘルスケア研究の方法論的考察において、外的妥当性が軽視されていることが多いのには驚かされる[11, 13, 14]。また、Dekkersらは、ほとんどの臨床試験が外的妥当性を軽視する理由は2つあるとしている。
- (1)ほとんどの臨床試験は、特定の狭い「理想的な」設定に基づいて結果の評価を行い、一般診療や「日常的な臨床診療」に適用した場合に介入が効果を持つかどうかという疑問を無視していること、
- (2)研究者が外的妥当性の複雑さを過小評価し、外的妥当性を研究に参加していない人々の「欺瞞的なほど単純な記述」として概念化することが多いことである[11]。
したがって、医療従事者、政策立案者、その他の関係者にとって、介入の有効性と効果に関する研究結果を区別することが重要だ。「有効性試験(説明的試験または[RCT])は、理想的な状況下で介入が期待される結果をもたらすかどうかを判断するものである。有効性試験(プラグマティック試験)は、「実世界」の臨床環境下での有益な効果の程度を測定するものである[15]。したがって、有効性試験の仮説と試験デザインは、日常的な臨床実践の条件と、臨床判断に不可欠なアウトカムに基づいて策定される。臨床家や政策立案者は、しばしば「介入の有用性(effectiveness ) と有効性(efficacy )を区別する」 [10]。
※有効性は、理想的な条件での効果、有用性は平均的な診療の条件下での効果(通常有効性より劣る)
2006,Gartlehnerらは、メタアナリシスを含むシステマティックレビューでは、有効性試験のバイアス評価は含まれているものの、有効性試験の評価は無視されていることが多いと報告した。Gartlehnerらは、研究者やシステマティックレビューの作成者、さらには試験結果の一般化に関心のある臨床医が、有効性試験と有用性試験をより容易に、より一貫して区別できるようにするためのツールを提案し、検証した。このツールでは、患者のベースライン特性(性別、年齢、重症度、人種など)地理的環境(都市部と農村部)および医療制度と健康アウトカム、試験期間と臨床的に関連する治療方法、有害事象の評価、患者の視点から最小重要差を評価するのに十分なサンプルサイズ、intention-to-treat分析など、一般化のための主要な要素を検証した。また、「無作為割付、割付隠し、盲検化は、これらの要素を否定することになり、一方では内的妥当性を高め、他方では外的妥当性を低下させる。したがって、「有効性試験」の運用上の定義は、ある程度、内的妥当性との必要なトレードオフを明確にしている。理想的な定義は、満足のいく内的妥当性が高度な一般化可能性を伴う点で、この均衡を保つことである」[10]。
以下の文献レビューでは、特定の症状や集団に対する治療(有効性試験と有効性試験の両方)の有効性を決定する上で、内的妥当性と外的妥当性が等しく重要であり、システマティックレビューの品質評価プロセスから外的妥当性を無視することで、研究者はシステマティックレビューの結果の全体的な質や、エビデンスを実践に移すための解釈を著しく低下させることを論じる。
1.2. 外的妥当性とは?
CookとCampbellによる古典的な研究によると、外的妥当性とは、異なる尺度、人、設定、時間に一般化できる因果関係の推論である[16, 17]。
外的妥当性は、研究の一般化可能性に関係する。つまり、観察された効果が研究以外の場所で発生する可能性がどの程度あるのかということである。この論文では、外的妥当性を2つの別の用語に分けている。(A)当初の研究サンプル(結果を一般化すべき患者集団)以外の人に対する結果としての外的妥当性と、(B)実験者が構築した状況から現実の状況や設定への結果の一般化としてのモデル妥当性(状況や設定、すなわち、施術者、スタッフ、施設、文脈、治療レジメン、アウトカムを越えた一般性)である。モデルの妥当性をサブセットとして含む包括的な用語「外的妥当性」は、従来、内的妥当性の外にあるバケツの中のすべてのものを表すのに使われてた[11]。この論文で定義されている外的妥当性は、母集団妥当性と呼ばれることもあり、モデル妥当性は生態学的妥当性と呼ばれることもある。
しかし、なぜ外的妥当性が重要なのであろうか?そして、なぜそれを測定すべきなのであろうか?患者の治療において、臨床家はしばしば “この患者にはどのような治療計画が最適か?”という問題に直面する。[18]. 医療研究においても同様に,”この患者集団にとって最も効果的な介入は何か?”という質問がしばしばなされる。前述のように、臨床家も研究者も、特定の介入に関する証拠の質を迅速に概算するために、システマティックレビューで分析されたRCTによって提供される証拠に目を向ける。また、「これらのランキングシステムは、主に内的妥当性に基づいて証拠の強さを定義している。外的妥当性の次元は、一般的に、証拠を適用する過程で解決すべき二次的な問題とみなされている」[18]。そのため、ヘルスケアや公衆衛生の研究では、今日では内的妥当性が優先されているようである[19]。しかし、研究がより応用的・実用的になるにつれ、臨床研究において外的妥当性を強調・強化する傾向が見られる[16]。例えば、ある医療介入やプログラムが理想的な条件下で機能すること(すなわち、有効性)だけでなく、日常的な状況で他の集団を対象に現場で展開された場合に、他の環境でも効果を発揮する可能性があること(すなわち、有効性)を知ることが重要であると考えられる。
モデル妥当性は、外的妥当性のサブセットと呼んでいるが、生態学的妥当性としても知られている。患者の適格性基準を超えて、病因、環境、診療の特徴を含む概念モデルに移行する。実際、外的妥当性の定義には、母集団や環境に対する研究の一般化も含まれることが多い。ここでいうモデルの妥当性とは、(1)患者や医療従事者の好みや知識、(2)医療従事者や治療センターの技能、訓練、認定、(3)治療センターや試験地が「現実の」環境を表現する可能性、などを考慮したものである。
モデルの妥当性は、研究の評価において、有効性を検証する場合だけでなく、CAM/IM研究の有効性と組み合わせる場合にも、より重要である。JonasとLinde[20]は、従来型とCAMの違いや、調査対象となる概念体系の違いについて述べている。彼らは、「欧米では、従来の医療における臨床研究は、共通の前提となる病因、診断、病態生理に依存しているため、研究方法がこれらの基本的な前提に違反していないかどうかを評価する必要はない。しかし、補完医療の多くは、このような西洋医学の標準的な前提の外で開発された医学体系に由来している。そのため、研究者は、研究方法と調査対象の概念モデルとの相互作用を考慮することが重要だ。研究者は、研究がCAMシステムの概念モデルをどれだけ調査に組み込んでいるかを判断する必要がある」[20]。この分野では、より多くの混合法を受け入れる方向に向かっているので、システマティックレビューでは、内的妥当性(主に有効性試験で用いられる)だけでなく、外的妥当性によっても質を評価することが重要になる。
本レビューの目的は、外的妥当性とモデル妥当性に関する文献で入手可能な現在のエビデンスベースを評価し、無作為化および非無作為化研究試験における外的妥当性とモデル妥当性を測定するためのこの評価ツールを開発し、適用することである。この評価ツールは、還元主義モデルが適合しない領域(すなわち、より効果試験に焦点を当てたより実践的なRCTおよび比較効果研究(CER)のデザイン)に対してより敏感になるであろう、標準的に受け入れられている内的妥当性ツールとともに使用することができる。
1.3. ツール開発のための文献調査
1.3.1. 一般化可能性。研究対象集団とソース集団の比較
外的妥当性は、ソース集団(ターゲット集団)に依存するため、外的妥当性の評価の最初のステップは、このソース集団を定義することである[11]。ソース集団とは,一般集団の中で,定義された包含領域と排除領域に基づいて,研究の参加者となり得る個人を指す.例えば、米国北東部の病院に入院しているスピロノラクトンによる心不全治療を受けているすべての男性患者が原集団となる。調査対象者(別名:調査サンプルまたは調査対象者)は、より大きなソース集団から無作為に選ばれた個人である。これは単純無作為抽出と呼ばれている。例えば 2011年1月1日から 2012年1月1日の間に、米国北東部の4つの病院に入院している18歳から45歳までの男性で、心臓病の既往歴があり、心不全のためにスピロノラクトンで治療を受けている患者が対象となる。この手法は簡単に見えるかもしれないが、(Dekkers et al 2009)[11]は、非常に複雑であると述べている。
「問題は、臨床現場では、異なる医師が同じ研究結果を異なる対象者に適用したいと考えることである。例えば、45歳から74歳までの拡張機能障害を持つが重度の合併症を持たない患者に対する降圧薬の効果についての研究があるとする。この特定の研究のためのターゲット集団を定義するにはいくつかの可能性がある。ある医師は、厳密に45〜74歳の年齢層に一般化することを望むかもしれない。しかし、別の医師は、この結果を重度の合併症を持たない拡張機能障害を持つすべての成人高血圧患者に適用することを望むかもしれない。つまり、45歳未満と74歳以上の高血圧患者に言及することになる。
実際、74歳以上の患者が研究から除外された場合、その外的妥当性はこの年齢制限以下の患者に制限されるべきであろうか?治療的介入の効果が76歳の患者には一般化できないと信じる理由はあるのであろうか?あるいは、77歳の人にも?同様に、40歳の人にも一般化できないのであろうか?しかし、この一般化可能性の拡張はどこで止めるべきであろうか?次に、併存疾患の重症度の捉え方が異なるかもしれない。内服薬で治療されている合併症のない糖尿病は、重度の併存疾患と考えるべきであろうか。また、インスリンを使用した糖尿病はどうであろうか?このように、ある研究において、共通して定義された対象者は存在しないことが明らかになった。一般化可能性の問題は、様々な対象集団、つまり異なるタイプの患者について熟考し、それぞれについて外的妥当性を評価しなければならない(pp3)[11]」。
言い換えれば、“RCTで研究されるサンプルは、統計的な推論ができるように、理想的には対象となる集団から無作為に抽出されることによって、厳密に代表的であるべきである “ということである。コミュニティベースのプログラム、特に家族ベースの予防プログラムの限界は、参加するモチベーションである。参加率、採用率、定着率は大きく変動する。彼らは、「参加者と非参加者の社会人口統計学的特性の単純な分析は有益であるが、それだけでは非参加の影響を排除するには不十分であると主張する」と述べている[21]。実際、サンプルの減少も一般化の問題として捉えられている。リスク因子や媒介変数において、脱落者と非脱落者の間に何らかの違いがあるかどうかを調べるためには、別途、脱落分析が必要である。
Fernandez-Hermida and colleagues (2012) [21]も、一般化可能性と適用可能性を区別している。彼らは、若年層のアルコール誤用に対する家族ベースの普遍的な予防プログラムの効果を評価した29の無作為化試験について、外的妥当性の特性の3つの領域(一般化可能性、適用可能性、予測可能性(GAP))を評価した。彼らの研究では、適用性を「成果が実証された予防的介入が、異なる環境や異なる集団への関連性を効果的に判断できる程度」と定義している[21]。最後に、彼らは予測可能性を評価に加えている。彼らの予測可能性の定義には、研究結果の測定値が意味のある健康上または社会上の成果(すなわち、傷害、罹患率、死亡率、生活の質、教育的および経済的成果)にどの程度関連しているかが含まれる。
最後に、著者らは外的妥当性を意図的に狭い定義の下で公式化している。しかし、外的妥当性を評価する際、著者らは「外的妥当性の適切な評価に必要な情報は、研究全体であまり報告されていない」と報告している[21]。Fernandez-Hermidaら[21]は次のように指摘している。
「子どもの性別や民族、親の教育水準、家族の所得水準などの変数が繰り返し用いられているが、これらの変数が介入の結果にどのように影響するかについての説明はない。サンプルの募集や、対照群と実験群の両方におけるサンプルの保持に自己選択がある場合、外的妥当性、特に研究結果の一般化の度合いが制限される可能性がある(p1575)[21]。”
したがって、上記の元となる集団の定義によると、特に適格基準で厳密に定義されたRCTにおいては、概念上問題となる可能性がある。なぜならば、適格基準に完全に適合する対象集団は、定義上、地理的、民族的、時間的条件に関して、元の研究集団とは依然として異なるからである。これらの違いは、それぞれの目的の結果に影響を与える可能性がある[11]。外的妥当性を明確に定義することで,その評価が容易になる可能性がある。
これらの問題に対応するために,我々は最近,ヘルスケアRCT,特に補完代替医療/統合ヘルスケア(統合医療とも呼ばれる)の分野における外的妥当性とモデル妥当性の方法論的チェックリストの開発に取り組んでいる。
1.3.2. 選択バイアスと割付バイアス
外的妥当性にはいくつかの脅威があり、研究結果が他のグループにも適用できるかどうかを表明する自信を損なう可能性がある。主要な脅威の一つは選択バイアスであり、無作為に選ばれた場合には起こらないような、実験的治療と相互作用する無傷のグループの何らかの選択要因の影響である。Shadish et al 2002)[9]によると
「この問題は、サンプルが母集団から無作為に選択された場合に最も顕著に現れる。サンプリング統計学者が、よく設計された宇宙を表現するために無作為抽出を促進することに熱心である理由を考えてみてほしい。このようなサンプリングは,サンプリング誤差の範囲内で,測定された変数と測定されていない変数のすべてにおいて,サンプルと母集団の分布が同一であることを保証する。これには、母集団のラベル(より正確であろうとなかろうと)も含まれており、ランダムサンプリングの保証はサンプルにも適用されることに注意してほしい。ランダムサンプリングの有用性の鍵となるのは、サンプリングの対象となる境界のはっきりした母集団を持つことである。これはサンプリング理論の要件であり、実際にはしばしば明白なことである。多くの境界が明確な母集団はラベルも明確であることから、ランダムサンプリングは、有効な母集団のラベルがサンプルにも同様に有効に適用されることを保証する。目的を持ったサンプル選択では,母集団のラベルが分かっていてもいなくても,このエレガントな理論的根拠は使用できない[9]」。
したがって,実験的な臨床研究や社会科学研究でよく用いられる意図的なサンプル選択を行う場合,単純なランダムサンプリングを用いてどのように一般化可能性を実現するかは,考えにくいところである(図1)。つまり、外的妥当性があるとすれば、母集団からの単一の無作為抽出に基づいて、人、環境、治療変数、測定変数のばらつきに対して、因果関係の推論が成り立つのかということである。Shadishら[9]は、外的妥当性とは、実験に参加した人、設定、治療、および結果の変動と、実験に参加しなかった人、設定、治療、および結果の変動であると考えている。彼らは、単一のサンプルから観察されていない事例への因果関係の一般化を、ランダムサンプリングが使用されたか否かに関わらず、外的妥当性の問題として扱っている。我々は、臨床試験(有効性研究と効果研究の両方)における外的妥当性の測定なしには、研究を公衆衛生の実践に移すことができなくなる危険性があると主張する[16]。
ECAM2014-694804.001.jpg
図1 単純無作為抽出を用いた一般化可能性
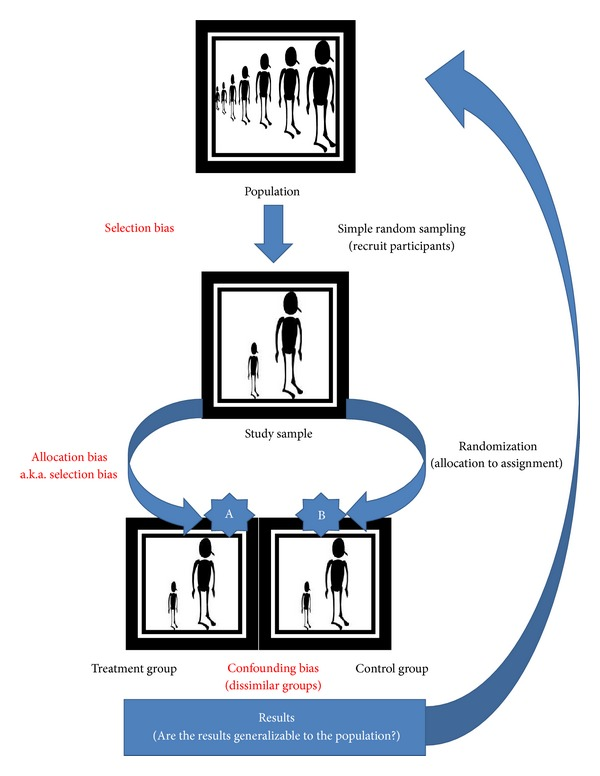
1.3.3. 適格基準による選択。交絡因子と離脱バイアス
交絡因子(交絡変数とも呼ばれる)とは、統計モデルにおいて、従属変数と独立変数の両方と(正または負の)相関関係を持つ外部変数のことである。このような要因には、年齢、性別、教育水準、危険因子、生活様式、環境などがある。これらの要因は、健康状態に影響を与えることが多いため、コントロールする必要がある。萎縮バイアスは選択バイアスの一種である。萎縮バイアスは、あるグループの人々が他のグループよりも頻繁に研究から離脱し(または有害事象や研究プロトコルの遵守不足により離脱し)その結果、サンプルが研究における当初のサンプルとは似ても似つかぬものになってしまう場合に生じる。
除外基準と呼ばれる選択基準は、研究の交絡変数(内的妥当性)と離脱バイアス(外的妥当性)の両方を減らすために重要だ。しかし、システマティックレビューの手法では、内的・外的妥当性のばらつきが効果量の推定値に与える影響を明らかにすることが非常に重要だ[22]。多くの場合、RCTは明確に定義された排除基準を持っている。患者の資格基準を狭めることは、通常、内的妥当性が強くなり、特定の患者集団に対する全体的な効果サイズが大きくなる [22]。しかし、年齢、性別、重症度、危険因子などの患者の特徴は、内的妥当性と外的妥当性の両方のレベルで全体の効果量に影響を与える。内的妥当性は高くても、集団レベルでの外的妥当性が低い研究もある。ここでは、Persaud and Mamdani [18]が心不全におけるスピロノラクトンの使用について示した例を用いて、内部的には妥当だが外部的には妥当ではない特定の選択基準に依存することの危険性を説明する。
「無作為化スピロノラクトン評価試験(RALES)は、「スピロノラクトンによるアルドステロン受容体の遮断は、標準的な治療に加えて、重症心不全患者の罹患率と死亡率の両方のリスクを実質的に減少させる」という結論が明らかになった時点で、早々に終了した[23]。しかし、RALESと比較して、スピロノラクトンを標準療法に併用した場合、高カリウム血症の発生率が有意に高いことを発見したレトロスペクティブ・スタディがある[24]。さらに、集団時系列解析では、RALES後に高齢者のうっ血性心不全(CHF)患者におけるスピロノラクトンの処方が増加したことに伴い、この患者群では高カリウム血症関連の入院および高カリウム血症関連の病院死亡が増加したことが示された[25]。
RCTと非実験的研究の知見の違いは、特定の特徴(高カリウム血症のリスクが低い)を持つ患者群で得られた知見を実際の患者群に適用したことによると考えられる。RALESでは、スピロノラクトンは、慎重な観察の下で選ばれた患者に使用すれば、標準治療との併用でCHF患者の死亡率を低下させることが示唆されたが、非実験的研究では、実際の臨床現場では、スピロノラクトンは集団レベルで死亡率を低下させないことが示唆された。つまり、「レベル1」のエビデンスを臨床に適用するには、非実験的研究から得られた、いわゆる「劣ったエビデンス」に照らして再解釈する必要があったのである[18]。”
前述の例は、特定の適格性基準が、選択された患者においては強力なプラスの効果をもたらすが、集団レベルではそれらの効果をもたらすことができず、かつ/または有害事象を生み出すことを示している。したがって、システマティックレビューでは、(1)組み入れ基準と除外基準、(2)脱落と離脱、(3)有害事象、(4)治療プロトコルの遵守不足のために研究に残った患者の代表性を考慮する必要がある。RCTでは存在感の薄かったサブグループ(高齢者、女性、黒人など)や、試験が最も頻繁に終了する専門センター以外の一般患者のベースライン予後を取り上げることが重要だ[18]。
最後に、内的妥当性を高めるために、多くのRCTでは併存疾患のある患者の参加を除外している。しかし、これらの同じ研究(患者のサブサンプルを除外したもの)は、すべての患者(除外された患者のサブサンプルを含む)に対する介入または治療に関する使用の証拠を正当化するものである。RCTから併存疾患のある患者を除外することは、外的妥当性のバイアスにつながり、潜在的に不十分で危険な治療方法になる可能性がある[26]。
2. 方法
PubMed(MEDLINEを含む),EBM(Evidence-Based Medicine) Reviews-Cochrane Central Register of Controlled Trials(CCTR),Cochrane Libraryを対象に,英語で出版され,医療研究におけるRCTの方法論的な質を評価するための外的妥当性またはモデル妥当性のツールやチェックリストを記述または使用している関連論文を,データベースの開始から 2013年1月2日までにコンピュータによるデータベース検索を行った。検索戦略で使用したキーワードは,”external validity”, “model validity”, “bias-scoring” plus “scale”, “checklist”, “critical appraisal”, “critical appraisal review”, “appraisal of methodology”, “research design review”, “quality assessment”, “randomized controlled trial” であった。
MeSH戦略に基づいて使用した検索語を図2にまとめた。
ECAM2014-694804.002.jpg
図2 MeSH戦略にしたがって使用した検索語。

尺度の開発または外的妥当性とモデル妥当性の尺度の心理学的評価,チェックリスト[27],またはコクラン共同計画のバイアスリスク評価ツール[4]のようなドメインベースの評価について報告している出版された研究が,収録の対象となった。
3. 結果
最初の電子データベースによる文献検索の結果、合計1131件の論文要旨が得られた。このうち33件がタイトルと要旨に基づいて研究候補として選ばれた。Moherら[1, 2]とOlivoら[3]の調査結果に加えて、RCTの外的妥当性および/またはモデル妥当性評価を含む8つの尺度、チェックリスト、または領域ベースの評価を確認した。これらのツールには、(1) Effective Public Health Practice Project Quality Assessment Tool (EPHPP) [28]、(2) Berhoft er al)。 checklist for model validity and external validity qualitative evaluation of clinical studies [29]、(3) Mathie er al)。 checklist for model validity and external validity qualitative evaluation of clinical studies [30]、(4) the Dekkers er al)。 strategy to assess the external validity and applicability of clinical trials [11]、(5) GAP (assessment of generalizability, applicability and predictability) for evaluation of external validity checklist [21]、(6) Downs and Black checklist for validity [31]、(7) LOVE [20]、(8) Singh Scale [32]がある。
3.1. ツールの開発
我々は、医療介入におけるRCTと非ランダム化研究の両方の外的妥当性を評価するためのツールを開発した。このツールは、研究結果の外的妥当性を判断するために最も必要な基準を持つツールから照合された文献プールを使用し、Cochrane Collaboration Risk of Bias assessment approach [8]およびScottish Intercollegiate Guidelines Network approach for guideline methodology [7]の提案に従って適応した。さらに,外的妥当性評価ツール(EVAT)を作成する際には,外的妥当性とモデル妥当性の次元を洗練させるために,特にプールされたツールの中から2つのチェックリスト(GAPチェックリスト[21]とDowns and Black checklist for measuring study quality)[31]を使用した。
我々は,コンセンサス・アプローチを用いてEVATの実現性を評価した。2人以上の査読者(RK,CC,JS)が,個別に独立して,著者らが作成したルールブックを用いて,EVATを用いてRCTおよび有効性研究の外的妥当性およびモデル妥当性の次元の方法論的質を評価し,コンセンサスが得られるまで,それぞれの評価に基づいてツールの基準と客観性を改良した。レビューアのバイアスを最小限に抑えつつ、客観的な測定を可能にしたこのルールブックは、Samueli研究所の内部コアシステマティックレビューチームにEVATの使用法をトレーニングするために使用され、今後行われるすべてのシステマティックレビューにおいてツールの有効性と信頼性をさらに検証する予定である。
3.2. EVAT:外的妥当性とモデル妥当性をバイアス尺度で定式化したもの
外的妥当性評価ツール(EVAT)の方法論は、各臨床医療研究において、その外的妥当性とモデル妥当性を評価する際に、システマティックレビューが外的妥当性とモデル妥当性の強さを評価できるように、著者がこれらの基準を報告することを保証するために、有用であることが推奨されている。方法論の評価は、研究デザインの外的・モデル的妥当性の側面に焦点を当てた3つの中核領域に基づいている。我々が行ったエビデンスの文献調査では、研究結果と結論のバイアスのリスクに大きな影響を与える研究デザインの特定の側面が見つかった。我々は、前述の文献レビューで得た知識と、すでに文書化されているツール(特にGAP [21]とDowns and Black [31]のチェックリスト)を通じて包括的な普及テーマを用いて、この客観的で合理的なツールを考案した。
EVATは、実用性に加えて、方法論的な厳密さを追求している(表1参照)。EVATの詳細および使用上の注意点については、Samueli Institute(http://www.samueliinstitute.org/)にお問い合わせほしい。このツールとその適用性を理解することは、臨床試験担当者にとって、すべての報告書でこれらの基準を報告していることを確認するのに役立ち、その後、システマティックレビューの方法論者によって品質基準として評価されることになる。
表1 医療介入におけるRCTおよび非ランダム化研究の外的妥当性を評価するためのEVAT*。
よくカバーされている (++) 十分に対処されている (+) 不十分に対処されている (-)
(1)募集
本研究では、参加者のソース集団を特定し、そのソース集団からどのように参加者をリクルートしたかを記述したか。
(2)参加
研究に参加した被験者は、募集された母集団全体を代表していたか?
(3)モデルの妥当性
患者が治療を受けたスタッフ、場所、施設は、大多数の患者が通常受けるであろう治療を代表するものであったか。
*EVATは、GAPチェックリストとDowns and Blackチェックリストをベースに改良した、研究の質を測定するためのツールである。
**この質問は、質問番号1が十分にカバーされている、または適切に対処されていると回答された場合にのみ適用される。回答が不十分とされた場合、レビューアは報告書に記載されているソース集団を理解していないため、この質問も不十分とされなければならない。
EVATの手法は、3つのコア・ドメインに基づいている。それぞれの領域は、個々の研究の報告に基づいて評価される。査読者は、研究デザインの側面に基づいて各ドメインを検討し、個々の研究がそのドメイン基準をどの程度満たしているかを判断することになる。各領域について、各研究で取り上げられた質を示すために、以下のいずれかを選択する。(1)よくカバーされている(++)(2)適切に対処されている(+)(3)不十分に対処されている(-)(4)該当しない(0)。
3.3. 領域1:研究は研究募集に対応している
第1の領域は、RCTおよび非ランダム化研究の両方を含む臨床試験で報告された参加者のソース集団の特定に関するものである。つまり、参加者はそのソース集団からリクルートされたのか(すなわち、参加者のソース集団を特定し、参加者がどのように選択されたかを記述する)。
3.4. 領域2:研究は参加を扱っている
研究サンプルの明確な記述が、ソース集団全体の代表者に基づいて特定されていなければ、関連するリスク因子や媒介変数、交絡変数の分布が研究の結論に影響を与えることを研究がどの程度実証しているかを評価することは困難であろう。この領域の質問は、領域1が十分にカバーされているか、または適切に対処されている場合にのみ適用されることに注意することが重要である。取り組みが不十分とされた場合、査読者は報告書に記載された原集団を理解していないため、この質問にも取り組みが不十分とされなければならない。
3.5. 領域3:モデルの妥当性に関する研究
この領域では、モデルの妥当性の概念を取り上げている。大多数の患者が受ける治療を代表する他の設定との関連性を判断できるように、スタッフ、設定、および介入の特徴が明確かつ詳細に記述されていることが重要である。
システマティックレビューの方法論における評価プロセスには、必然的に個々のレビュアーによるある程度の主観が含まれる。つまり、個々のレビュアーは、研究/臨床の文脈と個人的な判断を評価プロセスに持ち込むことになる。したがって、EVATの方法論では、個人的なバイアスや主観的なエラーを減らし、最小化するために、フルレビューの検討対象として選択された各研究は、少なくとも2人以上の査読者によって評価される必要がある。2人以上のレビュアーの間でEVATドメインに関する意見の相違があった場合、第3のレビュアー(治験責任医師、プログラムマネージャーなど)が仲裁者となり、システマティックレビューのエビデンスベースに研究が含まれる前にコンセンサスが得られなければならない。Samueli研究所では、より客観的なツールを作成し、評価をより合理的なものにするために、基準に答えるさまざまなカテゴリーの選択方法についてルールブックを作成するという試みを行っている。
4. 考察
4.1. 臨床意思決定における外的妥当性とモデル妥当性およびその適用性
臨床的意思決定における外的妥当性には、実際の患者集団に対する介入の一般化可能性が含まれる。2009,Jonasら[33]は、プライマリ・ケアの4つの雑誌に掲載されたRCTの外的妥当性を評価するために、プライマリ・ケアの人々からの試験参加者の選択プロセスを定量化する研究を行い、プライマリ・ケアに基づくRCTへの参加者募集の報告は一貫性がなく、しばしば不完全であることを発見した。彼らはこう述べている。
「発表された148件のRCTのうち、103件(70%)が適格性を審査した人数を報告し、発表されたRCTの80%が適格性を満たした人数を報告していた。採用プロセスを報告したRCTでは、採用された個人の割合に著しいばらつきがあるようである。これらの知見は、RCTの報告を改善すべきであり、RCTの中には、適格な参加者の低い割合のみがうまくリクルートされるため、外的妥当性が制限されるものがあることを示唆している[33]。”
したがって、募集データがないRCTは、適格な集団の特定や報告が不十分である可能性があるため、慎重に取り扱う必要がある。今後、システマティックレビューでは、外的妥当性を評価する際に募集データを考慮する必要がある。
前述のように、病因、診断、および病態生理学の概念体系に対する見解の違いは、それ自体が異なるタイプの研究デザインにつながる[20]。CAMの全体システム(WSCAM)のための非線形動的システムモデルの方法論的意味についてのBellらによる最近の研究[34]では、次のように述べられている。
「研究用語では、「良い」無作為化臨床試験(RCT)デザインは、有効性を検証するための強い内的妥当性を持っている。つまり、独立変数のみ(すなわち、特定の介入)が観察された効果を生み出したという確実性を最適化するために、十分に制御された実験条件が選択される。一方、外的妥当性は、研究参加者が抽出されたより大きな集団に対する観察された効果の一般化可能性を扱い、モデル妥当性は、研究デザインと理想的な設定との間の一致に関連する(詳細は[29, 35]を参照)。研究における外的妥当性とモデル的妥当性のためには、WS-CAMの実践者は、
(a)標準化された個別の要素ではなく、不可分で相互依存的な反復的ケアパッケージを使用すること、
(b)研究に参加する実践者が十分な訓練を受け、高度な経験を積んでいることを保証すること、
(c)混同している併存疾患、心理社会的要因、その他の治療を伴うリアルワールドの患者を治療すること、
(d)単純な臓器や疾患固有の効果ではなく、複雑で出現する患者全体の結果をそれぞれのケースで評価することが必要である。
WSCAMの主な特徴は、協調的、適応的、不可分なケアパッケージと、グローバルな機能(例:QOL)と複数のローカルなサブシステム(例:元々の主訴だけでなく、多くの症状における「非特異的」な変化)の両方において、患者全体にポジティブな結果が現れることである。これらを総合すると、これらの臨床的複雑性は、特定のアウトカムを評価するために標準化された介入を行う従来の生物医学的有効性研究の研究デザインの前提とは根本的に相容れない[34]。”
還元主義的な生物医学モデルとCAM/IMのホリスティックな概念モデルとの世界観の根本的な違いが、複雑な方法論的問題を生み出している。これらの方法論的問題には、RCTSを含む従来の研究方法で用いられている一般的な線形モデルの仮定の問題が含まれる。線形・還元論的な理論の仮定には次のようなものがある。(1) 比例的な原因と結果の関係 (2) 原因は独立している (3) 残留誤差は独立同分布のサンプルである [34] 。上述のように,CAM/IM研究は線形研究モデルにうまく適合せず,複雑な非線形モデルを必要とする場合がある。したがって、CAM/IMのRCT統計の結論、またはその欠如は、慎重に解釈されるべきである。CAM/IMの介入や治療には、実用的な準実験計画の方が適しているかもしれない。システマティックレビューの質の評価と同様に、臨床試験の報告にEVATを含めることで、今後の研究でより一般化できる結果を解釈し、医療に関するより良い情報に基づいた意思決定を行うことができる。
2012,Fernandez-Hermidaら[21]は、彼らの研究に含まれる29のRCTのうち、大多数(69%)がサンプルから研究集団への一般化可能性を判断するための十分な情報を報告しておらず、35%が他の集団や環境への適用性を判断するための十分な情報を報告しておらず、その後の死亡率、罹患率、生活の質、その他の経済的・社会的なアウトカムに対する試験のエンドポイント測定の妥当性の評価に基づく予測可能性を提供した研究はなかったと報告している。また、代替エンドポイントを評価するための確立された基準を用いて、代替エンドポイントの有効性を報告した研究は一つもなかった。したがって、若年層のアルコール誤用に対する家族ベースの予防の効果を評価した研究では、健康や社会的なアウトカムに対する知見の一般化に関連する情報の報告が全体的に不十分であると結論づけている。実際、RCTの多くは、細心の注意を払って実施されていても、特に有用性や関連性、注目すべき点がない場合があると議論されているが、それはRCTが「介入が最も効果を示す可能性が高い理想的な状況下」で介入の影響を推定するようにデザインされていることが一因である[36]。そのため、これらの試験はしばしば「説明試験」または「有効性試験」と呼ばれ、理想的な状況下で介入が機能するかどうかについての疑問に答えるためにのみ有用であるが、その結果は現実的または通常の状況下で介入が機能するかどうかについての疑問に答えるためには関連性が限られており、したがって臨床医、管理者、および政策立案者にとってはあまり有用ではない[36]。また、現代の生物医学研究の多くが、真の発見のための研究前および研究後の確率が非常に低い領域で行われていることを論じている人もいる。Ioannidisは,「新しい発見のほとんどは,研究前の確率が低いか非常に低い仮説生成研究から生まれ続けるだろう」と述べている.そして,単一の研究の報告書における統計的有意差検定は,報告書の外や関連する分野全体でどれだけの検定が行われたかを知らずに,部分的な情報しか与えないことを認識すべきである」 [37]。
すべての研究において、どのようなタイプの研究デザインを実施しようとしているかにかかわらず、何よりもまず、知見の一般化に関連する十分な情報を伴う明確な研究課題を問う必要がある。ある試験では有効性に重点が置かれ、他の試験では介入の有効性を検証することが主な目的となる。有効性とは、特定の介入が理想的な条件下でどの程度有益であるかを示すものであり、一方、有用性とは、特定の介入が現場で日常的に展開されたときに、ある集団に対して意図したとおりの効果を発揮する程度を示すものである。どちらのタイプの研究も、RCT研究デザインを用いて実施することができる。しかし、有効性研究と効果研究は、研究課題に対するアプローチが大きく異なり、有効性の異なる側面に焦点を当てている。想像できるように、有効性研究は内的妥当性の構成要素で高いスコアを得ることができ、一方、有用性研究は外的妥当性の構成要素に関連して評価され、内的妥当性では低いスコア、外的妥当性の構成要素では高いスコアを得ることができる。明確なリサーチクエスチョンと研究の目的に応じて、内的妥当性と外的妥当性の評価基準を導入することで、振り子のような状態になる。有効性の高いRCT研究デザインは、システマティックレビューの方法論において、評価対象となるリサーチクエスチョンの純粋な性質から、現在のところほとんどが内的妥当性の基準で評価されているため、苦戦を強いられている。内的妥当性と外的妥当性の両方を評価するツールを提供することで、査読者はこの振り子の揺れを確認し、研究者が特定の研究課題に答えるための最も重要な基準に包括的かつ厳密に取り組んでいることを確認することができる。研究の目的は、変化を生み出すことを意図した対象者に奉仕することである。研究対象者には、患者、医療従事者、地域社会、政策決定者などがいます。これらの聴衆は、共通の核となる情報に関心があるが、優先順位は異なる。我々研究者は、これらの人々が医療に関する意思決定を始めるために必要な、重複する情報のバランスと合意を見つける必要がある。Patient-Centered Outcomes Research Institute(PCORI)は、患者とその医療従事者がより多くの情報に基づいた意思決定を行えるよう、入手可能な最善のエビデンスに関する情報を提供するための研究を行うために設立された。このイニシアチブの目的は、患者とそのケアをする人たちに、利用可能な予防、治療、ケアの選択肢と、それらの選択肢を支える科学について、よりよく理解してもらうことである。
CAM/IMプラクティスに関する質の高い研究は、従来の医療と比較して、まだ非常に少ないものである。従来の医療の多くでは、有効性の研究は、薬物研究のための標準的なRCTで答えることができる、非常に正確な研究課題がある場合に、最も意味があるように思われる。しかし、CAM/IMについては、これらのシステムの中には非常に複雑なものがあり、これらの試験の報告に必要な要件がなければ、結果を一般化することは困難になる。例えば、鍼灸のような施術は、適切に行われるためにはかなりの訓練と技術を必要とする。米国および海外にはさまざまなライセンス構造があり、報告書にトレーニングや資格取得の経験のレベルを完全に開示しなければ、結果を他の集団に一般化することは困難である。このような分野に配慮した、より複雑な評価ツールが必要である。
EVATは、Samueli Institute Rapid Evidence Assessment of the Literature(REAL©)[38]手法の外的妥当性とモデル妥当性を評価するためのギャップを埋めるために作成された。EVATは、Samueli研究所で計画されている今後の研究において、今後のシステマティックレビューを通じて追加される予定の迅速な評価ツールである。これらの質問に答えるための独自のルールブックは、社内のレビュアーチームを訓練するために開発され、今後のシステマティックレビューで使用される予定である。EVATの心理測定法は今後のシステマティックレビューで検証され、これらの実際の適用基準を報告していないことについてのギャップが明らかになるであろう。
5. おわりに
結論として、外的妥当性とモデル妥当性が測定されていないために、実務家は、ある研究結果が自分の地域の環境、人口配置、資源に当てはまるかどうかを判断できないことが多い。外的妥当性とモデル妥当性に関する情報が不足していると、研究を公衆衛生の実践に結びつけることができない原因となる。
そのため、政策や行政の意思決定者は、研究結果の一般化可能性や適用範囲の広さを判断することができない。最後に、外的妥当性のデータが報告されない場合、システマティックレビューやメタアナリシスは、引き出せる結論に制限がある。EVATは、研究者が研究を評価する際にこれらの複雑さを考慮する方法を提供し、実社会での実用性に適用するための研究の妥当性を示する。この評価ツールを使用するための適切なトレーニングを受ければ、臨床試験をより強固で厳格に評価することができ、患者や地域社会のために臨床的な意思決定を行う人々により良いサービスを提供することができる。