
Contents
Challenging issues in randomised controlled trials
pubmed.ncbi.nlm.nih.gov/20413119/
2010年7月
概要
このトピックの目的は?無作為化比較試験(RCT)は、治療と結果の間に因果関係が存在するかどうかを判断する最も厳密な方法であり、現在の臨床実践を導く証拠の階層に不可欠な要素である。RCTを成功させるためにも、医学文献を解釈するためにも、RCTの質を評価するためのRCTデザインの重要な要素を理解し、その結果をどの程度重視すべきかを理解することが重要だ。この記事では、モナシュ大学のオーストラリア・ニュージーランド集中治療研究センターが共同で行っている進行中の外傷研究を例に、これらの重要な要素の一部を紹介する。
共通の問題と課題 多くのRCTの質は、以下のような一般的な落とし穴を避けることで向上する可能性がある。
- (i) 不明瞭な仮説と複数の目的
- (ii) エンドポイントの選択不良。
- (iii) 不適切な被験者選択基準
- (iv) 臨床的に適切でない、または実行可能でない治療/介入レジメン
- (v) 不適切な無作為化、層別化、盲検化
- (vi) 小規模RCTにおける層別化の欠如
- (vii) 試験の不十分な盲検化
- (viii) 不十分なサンプルサイズ/パワー
- (ix) intention to treat分析の不使用
- (x) RCTの実施中に遭遇する一般的な実用的問題の予測の失敗、
などである。
研究者へのアドバイス 研究者へのアドバイス:資金提供を受ける可能性が高く、質の高いRCTは、常にこれらの問題に対処している。
はじめに
このトピックは何についてのものか
無作為化比較試験(RCT)は、治療法や介入の有効性や効果を検証するために一般的に用いられる研究の一種である。比較的最近のパラダイムシフトにより、今日の医学文献では無作為化比較試験が重要視されているが、そのきっかけとなったのは、発表された無作為化比較試験と観察デザインを用いた試験を比較した研究でした14。この研究では、患者選択のバイアスにより、過去の比較試験の結果が新しい治療法に有利になることが示されたが、これは質の高いRCTには見られない欠点である。さらに、RCTには、その方法論的な堅牢性を高め、世界中の臨床試験担当者に採用されているいくつかの側面がある。重要なのは、RCTの「無作為化」とは、患者を治療群と対照群(治療を受けないプラセボ群)のいずれかに確実に無作為に割り当てるプロセスを意味することである。このプロセスは、治療群と対照群の間に、既知および未知の、研究された介入以外の結果にバイアスをかける可能性のある要因において、系統的なベースラインの違いが生じないようにすることを目的としている。
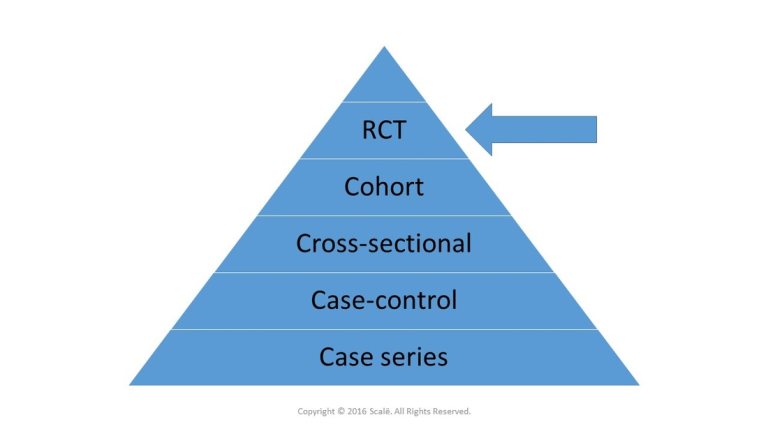
エビデンスに基づく医療では、研究をそのデザインに基づいてエビデンスの「グレード」に分類している。8 RCTはエビデンスのグレードが最も高く(グレードの高いRCTのメタアナリシスには最高のグレードが確保されている)最も低いグレードは記述的研究や専門家の意見に適用される。介入試験は一般的に、第I相(介入の安全性を証明する試験で、通常、健康なボランティアを対象に実施される)第II相(治療/介入を少人数の患者に行い、エンドポイントは酸素化、サイトカイン濃度など、臨床転帰を改善するための代替マーカーが多い)第III相(死亡率など、臨床的に関連性のあるエンドポイントを検出するための検出力を持つ、より大規模な患者グループを対象とした有効性試験)第IV相(有害事象をモニタリングしたり、治療法の適応を拡大したりするための市販後試験)のいずれかに分類される。ほとんどの場合、第II相および第III相試験は無作為化比較試験である。
無作為化比較試験は多くの場面で有用であるが、すべての治療法や介入策の評価に最適な試験デザインではないことに留意する必要がある。特に、まれな結果をもたらすものや、効果の発現に非常に長い時間を要するものなどである。このような場合には、症例対照研究やコホート研究などの他の研究デザインがより適切であるかもしれない。しかし、RCTは依然として最も堅牢な効果の推定値を提供するが、(堅牢性ではなく)実現可能性に基づいて、これらの他のデザインが選択されることが多いことに留意する必要がある。
将来のRCTをデザインする際にも、医学文献を解釈する際にも、RCTの質を評価し、その結果に与えられるべき重みを評価するために、RCTの重要な要素を理解することが重要だ。この記事では、メルボルンのモナシュ大学にあるオーストラリア・ニュージーランド集中治療研究センター(ANZIC-RC)が現在実施している外傷性脳損傷(TBI)研究を例に、これらの重要な要素を紹介する。特に、POLAR (The Prophylactic Hypothermia Trial to Lessen Traumatic Brain Injury, NCT00987688) と EPO-TBI (Erythro-poietin in Traumatic Brain Injury, NCT00987454) のRCTを参照する。このレビューでは、RCTの主要な構成要素を簡単に紹介するが、RCTの報告と批評のための網羅的で質の高いガイドラインが数多く発表されていることにも留意する必要がある1,11,2。
「よくある問題と課題」と「研究者のためのヒント」について
RCTでよく遭遇する問題や課題は以下の通り
仮説の不明確さと複数の目的
厳密な検証が可能な明確な目的を持つことが重要である。単一の主目的を持つ明確な仮説は、適切な統計計画と検出力分析を可能にするだけでなく、試験の臨床目的を前もって述べ、その臨床的妥当性を明確にする。例えば、POLAR試験の目的は、「早期の予防的低体温療法が正常体温療法と比較して、重度外傷性脳損傷後6カ月の早期神経学的転帰を改善するかどうか」を明らかにすることであり、EPO-TBI試験の目的は、「エリスロポエチン40,000Uを毎週3週間プラセボと比較して、中等度または重度のTBI後6カ月の神経学的転帰を改善するかどうか」を明らかにすることである。これらの研究から得られる答えは、「改善する」か「改善しない」のいずれかであり、その結果は、重要で関連性のある臨床上の疑問を解決し、これらの分野における実践を導くのに役立つであろう。
注:目的が多すぎると試験が混乱するので、シンプルで明確なものにしよう。目的が多すぎると試験が混乱する。単一の仮説と少数の副次的な仮説があれば十分である。
試験のエンドポイントの選択不良
エンドポイントは臨床的に適切である必要がある。臨床家が特定の治療を患者に施すべきか否かを決定するのに役立たない臨床エンドポイントを報告または試験する意味はない。第2相試験では、生理学的、生化学的、または炎症学的な代替マーカーを使用することが多いであるが、第3相試験では、一般的に死亡率などの「より困難な」転帰のマーカーを試験する。患者や社会の観点からは、単に生きているか死んでいるかではなく、もっと重要なことがあるという認識が高まっている。そのため、TBIの多くの第3相試験では、神経機能(Glasgow Outcomes Scale, Extended (GOSE)など)および生活の質(EQ-5Dなど)を評価するために、国際的に認知され、検証されたツールを使用している。そのため、ぽらりすとEPO-TBIの両試験では、主要評価項目として受傷後6カ月間の神経機能(GOSE)を、副次評価項目としてQOL(EQ-5D)を評価することにした。
注:最も重要で、関連性が高く、実用的な関心事である結果を適切に測定する1つの主要変数を選ぶこと。
不適切な被験者選択基準
RCTにおける患者の組み入れ基準は、研究集団を記述するものであり、したがって、明確で客観的かつ臨床的に適切である必要がある。例えば、ポーラとEPOは、それぞれ重度のTBI(グラスゴー・コーマ・スコア(GCS)<9)または重度および中等度のTBI(GCS<13)の患者を組み入れる。治療や介入によって被害を受ける可能性のある患者の登録を防ぐため、また、治療が無駄な患者の登録を防ぐために、除外基準を設けることは全く妥当なことである(例:TBI研究で瞳孔が固定されて拡張し、GCS=3の患者)。しかし、これらの除外基準は過度に複雑ではなく、最終的な研究結果の一般性を著しく低下させないことが重要である。これらの除外基準は、一般的なもの(例:妊娠)でも、特定のもの(例:誘発性低体温は凝固障害と関連する可能性があるため、出血のリスクが高い外傷患者をPOLAR試験への登録から除外するのが賢明である)でもよい。
注:非常に均質な患者群を選択すること(効果を検出しやすいかもしれないが、被験者の登録が困難で、結果が一般化しにくい)と、異種の患者選択基準(被験者の登録が容易で、結果が一般化しやすいが、治療効果が希釈される可能性がある)との間で、利益とリスクのバランスをとること。
臨床的に適切でない、または実行可能な治療/介入レジメン
常識的に考えて、最も有用なRCTは有効性を決定するだけでなく、試験の治療/介入がほとんどの臨床現場で研究対象者に容易に実施できるものでなければならない。非常に複雑で手間のかかる治療法や介入法は、有益である可能性はあるものの、物流や資源の問題から実施できないことがある。このような理由から、EPO-TBI試験とPOLAR試験では、有効であればオーストラリアのすべての外傷センターがこれらの介入を採用することがほとんど困難ではない程度に、試験介入を簡略化した。
注:原則として、最も関連性の高い臨床現場で実用化されるであろう試験治療・介入方法を選択すること。
不適切な無作為化、層別化、盲検化
無作為割付とは、参加者が試験群または対照群のいずれかに無作為に割り当てられることを意味する。したがって、サンプルサイズが十分であれば、試験開始時に参加者の特性は各群間で類似している可能性が高い。無作為化が適切に実施され、大規模な患者コホートで行われれば、評価されるエンドポイントに誤って影響を与える可能性のある既知および未知の要因の深刻な不均衡のリスクを低減することができる。無作為化は、無作為化対照試験にバイアスを減らす重要な能力を与えるため、無作為化が正しく実施され、文書化されることが非常に重要だ。無作為化には様々な方法があるが、共通しているのは、ある患者さんがどのグループに割り振られるかを誰も事前に決定できないようにすることである。これはRCTの中心的な要素であるにもかかわらず、無作為化の方法はあまり報告されていない15,17,10。
理想的な無作為化の記述は、(i)無作為化スケジュールの設計(例:ブロックサイズが記載されたコンピュータベースのスケジュール)(ii)層別化の有無、(iii)誰がどのように患者を無作為化するか(例:ベッドサイドナースとウェブプロトコル)(iv)すべての無作為化試行の記録とログ、および無作為化後に治療群または対照群のいずれかに正しく割り付けられたかどうかを確認するプロセスの記述である。
小規模RCTにおける層別化の欠如
層別とは、治療群間で不均衡になる可能性のある重要な予後因子をコントロールすることを目的とした方法である。例えば、EPO-TBI試験では、脳損傷の重症度(中等度または重度)によって層別化し、両群に同程度の損傷を受けた患者が同数含まれるようにする。対象となる層に対してグループのバランスをとることで、知見の解釈性が高まり、ベースラインの不均衡が偶然に生じた場合に多変量解析による調整を行う必要がなくなることが多い。層化の使用は、200人以下の小規模試験では特に重要であり、層化を行わないと、平均的なサブグループ分析に必要な数が不足する可能性がある。
注:特に試験が小規模であったり、予後因子が非常に強力である場合には、グループ間の重要な予後因子の不均衡を防ぐために層別化を行う。
試験の盲検化が不十分な場合
盲検化が不十分な場合、治療法の割り付けがわかっていると、単に治療法の違いだけではなく、広い意味での異なる治療、すなわち、異なるフォローアップ、異なる調査が行われ、試験結果に影響を及ぼす可能性があるため、バイアスが生じる可能性がある。盲検化を維持し、結果を客観的に評価するためには、プラセボや偽薬を使用するなど、さまざまな手法を用いることができる。例えば、当グループのEPO-TBI試験は、二重盲検プラセボ対照RCTであり、治療を担当する医師も、6ヵ月間の神経学的転帰を評価する研究者も、治療の割り当てを知ることはできない(EPOとプラセボの同一の注射器を準備する研究薬剤師のみ)。治療割り付けの盲検化は必ずしも可能ではないが(ぽらりす研究の患者は、ICUで少なくとも3日間、低体温(33℃)または正常体温(37℃)のいずれかに維持される)結果評価の盲検化は可能であることに留意する必要がある(ぽらりすでは、訓練を受けた結果評価者が割り付けを盲検化する)。この盲検化は、エンドポイントが主観的なもの(痛み、機能など)である研究において最も重要だ。
注:最低でも、結果評価者には必ず治療割り付けを盲検化する。
サンプルサイズ/パワーの不足
大きな差が予想される場合、2群間の統計的に有意な差を得ることは比較的容易である。しかし、多くの無作為化比較試験では、研究対象となる治療法の効果が比較的小さいことが予想されるため、大きなサンプルサイズが必要となる。16 残念ながら、RCTに対する比較的一般的な批判は、試験群間の臨床的に妥当な差を検出するにはサンプルサイズが不十分だったというものである。このことは、71件の無作為化比較試験を対象とした最近の研究で、これらの試験のほとんどが重要な臨床的差異を検出するには小さすぎる(すなわち検出力が不十分である)ことが明らかになった。さらに、統合失調症とTBIの研究に登録された患者を対象とした最近の研究では、実施された試験のうち、十分な検出力を有していたのはごく少数であったことがわかった17,7。
例えば、POLAR研究では、最近の前向き研究13,12を利用して、オーストラリアとニュージーランドの重度TBI患者における現在の良好な神経学的転帰の加重平均率が50%であることを決定した。さらに、重症TBIにおける予防的低体温療法の有益な効果として、受傷後6カ月の神経学的転帰が50%から65%への30%の相対的リスク増加(RI)(15%の絶対的リスク増加(ARI))は、臨床的に意義のある重要な効果であると考えられる。これは、以下の根拠に基づき、妥当で保守的な推定値であると判断された。
重度の外傷性脳損傷において、予防的低体温療法と正常体温療法を比較した最近のメタ解析3では、好ましい転帰が46%改善された(相対リスク(RR)1.46,95%(CI)1.12~1.92,p=0.006)。
到着時に低体温であった45歳未満の重度外傷性脳損傷患者のサブグループを対象に、低体温療法と正常体温療法に無作為に割り付けた結果、良好な転帰が50%増加した(p=0.02)という結果が出ている4。
もし予防的低体温療法が有益であることが証明された場合、そのような神経学的転帰の差は臨床的に非常に有意であり(NNT = 7)オーストラリアおよび国際的に重度TBI患者の管理を広く変更することにつながるであろう。
注:治療効果の大きさは保守的に保つこと。試験デザインのこの面でのエラーは、資金調達が失敗する一般的な理由である。
intention to treat分析の失敗
意図した介入を行ったかどうかにかかわらず、割り付けられたグループの患者を対象に主要な結果分析を行うことが重要である。このintention to treat分析(ITT)は、起こりうる様々な誤解を招くバイアスを回避することを目的としており、現実の生活と同様に、当初の意図にもかかわらず、患者全員が最適な治療を受けられないことがあるという仮定に基づいている。ITTは、特定の治療の潜在的な効果(すなわち、計画通りに治療を受けた群に対する効果)ではなく、治療方針(すなわち、全員を治療するという決定)の潜在的な効果に関する情報を提供する。ITT試験における交差や脱落は、介入の真の効果について偏った推定値を与えることになるが、重要なのは、これが常に帰無仮説に偏り、保守的な結果を与えるということである。
ITT分析を行う主な理由は、クロスオーバーや脱落によって生じる可能性のあるバイアスを回避し、無作為化の原則を維持することにある。POLAR試験を例にとると、より重度のTBIを受け、その後死亡する可能性が高くなった患者が、3日間の低体温誘導に耐えられず、合併症を発症して再加温されたとする。試験終了時に、フル経過の冷却を受けた患者のみを対照群と比較するper-protocol解析を行った場合、低体温群の重症患者を解析から系統的に除外していたため、低体温が転帰を改善したように見えるかもしれない。ITT解析では、これらの患者を考慮する。したがって、治療を開始した全員が試験に参加していると考えられる。
注:intention to treat分析を必ず使用すること
RCTの実施中に遭遇する現実的な問題
多くの問題は、一度開始された試験の成功を妨げる可能性がある。そのため、積極的な研究者はこれらの問題を予測しようとする。
採用率の低さ。これはすべてのRCTにおける永遠の問題であり、過度に選択的な組み入れ基準、あまりにも多くの不適切な除外基準、研究に参加可能な患者数の不適切な評価、潜在的に組み入れ可能な患者の不適切な検出(スクリーニング)および同意の拒否を考慮していないことから生じる可能性がある。症例数を決定し(組み入れ基準と除外基準を考慮した上で)これらの潜在的に適格な患者のうち、せいぜい50%未満しか採用できないことを想定すること。EPOとPOLARの両試験では、以前の多施設共同観察研究で決定されたように、潜在的な患者の50%以下の採用率を見込んでいる13。
注:保守的に、潜在的に適格な患者の50%未満を採用することのみを想定する。
クロスオーバー、離脱、追跡調査不能
医師の選択(プロトコル違反ではあるが)合併症の発症、同意の撤回などにより、すべての患者が割り当てられた治療群に留まるとは限らない。このような事態を想定しておくことが重要だ。さらに、一次エンドポイントを評価できない患者が常に存在する。これは、エンドポイントの測定が、最初の病気からかなりの時間が経過した後や、患者が退院した後に行われる場合に多く見られる。
例えば、POLAR試験では、試験終了時に必要な評価可能な患者数を確保するために、(i)追跡調査、(ii)低体温療法の中止、(iii)禁忌による損失を考慮してサンプルサイズを増加させた。長期追跡調査での損失が全体の5%であることを考慮して、サンプルサイズを384名に拡大した。さらに、パイロットデータに基づいて、低体温療法に無作為に割り付けられた患者の低体温療法の中止率を12%(出血8%、代理/医師の同意撤回2%、不適切な登録(TBIではなく心血管事故など)2%と見積もって、サンプルサイズを496人に拡大した。
注:試験力を十分に維持するためには、クロスオーバーやフォローアップの喪失を常に想定しておく必要がある。