Contents
Beautiful small: Misleading large randomized controlled trials? The example of colloids for volume resuscitation
クリスチャン・J・ヴィーデルマン、ヴォルフガング・ヴィーデルマン1,2
要旨
麻酔および集中治療では、小規模または中程度の規模の試験に基づいて主張された治療効果は、大規模ランダム化比較試験では何度も確認されていない。イベント発生率の高い同種の患者集団を対象としたよく計画された小規模試験であれば、決定的な結果が得られる可能性がある;しかしながら、麻酔および集中治療の患者集団は、併存疾患のために典型的には不均質である。
治療的介入の予想される効果の大きさは、関連するエンドポイントとの関係では一般的に低い。規制目的のためには、臨床的に重要なエンドポイントで有効性を実証することが求められており、死亡、敗血症、肺炎などの臨床的に重要な試験のエンドポイントは二分化しており、まれにしか発生しないため、試験の規模を大きくしなければならない。
エンドポイントイベントが試験集団で発生する頻度が低いほど、ランダムイベントが過度に強調されないようにするためには、S/N比(信号対雑音比)が低いほど大規模な試験でなければならない。
試験デザインに加えて、イベント率、臨床的に意味のあるリスク比の低下、実際の患者数に基づいたサンプルサイズの決定は、試験結果を解釈する際に最も重要な特徴の一つである。試験の規模は、より大きな患者集団または一般的な患者集団への試験結果の一般化可能性を決定する重要な要素である。
小規模な単施設研究の典型的な特徴として、サロゲートパラメータの転帰指標の変動性が低いこと、選択的な発表と報告があることが知られている。麻酔科や集中治療医学では、コロイドの静脈内注入に関する緊急輸液療法研究の結果がこの例である。
アルブミン注入の安全性と人工コロイドであるヒドロキシエチルデンプンの副作用の両方が大規模試験でしか確認されていないためである。
キーワード
バイアス、一貫性、デザイン、メタアナリシス、無作為化比較試験、サンプルサイズ決定
序論
エビデンスに基づいた医療とは、最良の研究エビデンスと臨床の専門知識や患者の価値観を統合したものである[1]。しかし、多くの臨床医は医学文献を批判的に評価する資格がないと感じている[2] 。臨床医は、ガイドラインの推奨が製薬、診断薬、医療機器業界の激しいマーケティング戦略の影響を受けることを承知の上で、多かれ少なかれ推奨に従っている[3]。
大規模無作為化比較試験(RCT)では複数の試験施設が必要となるため、各施設のケア基準の違いによる不均一性が生じてしまう。簡略化された組み入れ基準を用いた実用的な試験デザインは典型的な結果であり、試験結果を日常の臨床現場で実施する際には、潜在的な限界があることが判明した。緊急輸液療法の分野では、大規模RCTの結果の一般化可能性が疑問視されており、小規模RCTへの依存度が高いことが魅力的に映る場合もある。このナラティブレビュー論文は、RCTの結果の意味や、評価される研究のデザインや規模の役割を医師がよりよく理解することを目的としている。
ランダム化対照試験と研究の階層性
ガイドラインは一般向けに作成されているが、個々の患者に合わせたものでなければならない。これを成功させるためには、日常臨床での実践者の個人的な経験に加えて、最善の研究エビデンスから得られた結果の独立した有能な評価から得られる医学的知識も重要である。このように、臨床医学、そしてすべての開業医にとって、臨床試験の結果を批判的に評価し、最良の研究エビデンスと臨床の専門性や患者の価値観を統合できるようにするためには、臨床試験の方法論を理解することが必要となってきている。
まず、試験の種類を理解することが必要である[1] が、一般的には実験的試験と観察的試験の 2 つに分類されるが、これは治験責任医師が曝露を割り当てるか否かによる。実験的試験は無作為化試験と非無作為化試験に細分化される。エビデンスを質によって層別化するシステムが開発されている[5] 。少なくとも1つの適切に設計されたRCTから得られたエビデンスは、治療および予防研究において最高レベルにある。RCTは臨床研究においてユビキタスであり、今日では科学的なルーチンとなっている。無作為化の概念は初期の統計学者Fisher[6,7]の著作にまで遡ることができるが(歴史的発展の議論については、例えばref. 約60年前に、この種の研究の最初のものが近代的な基準に従って実施されたばかりである[9]。
サンプルサイズとトライアルデザイン
イベント発生率の高い同種の患者集団を対象としたよく計画された試験は、たとえ小規模であっても決定的な結果を得ることができる[11] 。 実際、最近では10年前までは、集中治療や麻酔科の設定では、数百人の患者を対象とした試験が大規模と考えられていた。今日、これらの分野における現代の研究では、数千人の患者を対象とした試験を実施しなければ意味のある規模とは言えない。その理由は明らかである。治療的介入、特に麻酔や集中治療における薬物の効果は、一般的に関連するエンドポイントとの関連性が低いからである。成功した試験で測定された相対リスクやリスク比(RR)の減少などの効果の大きさは、ほとんどが20~25%の範囲である。これは、試験が通常、多因子性の疾患合併症に対する介入を調査しているからである。さらに、例示とは対照的に、遺伝性疾患またはよく特徴づけられた疾患実体は、患者集団が特に異質である。現代の介入は通常、疾患合併症の発生における単一の病態生理学的ステップに影響を与えることを強く目標としており、多因子性の病態生理学を通常約20〜25%のRR低下をもたらすものよりも強力に修正することは期待できない。
一方で、大規模試験は必ずしもより信頼性が高いとは限らない。試験デザインも考慮に入れる必要がある。緊急輸液療法のためのコロイドに関する現在の論争は、厳密な流体プロトコルを強制しない「実用的」な大規模試験に関するものである[12,13] 。 異種介入、交絡のある併用療法、ベースラインのリスクアンバランスなど、特定の大規模試験の設計上の弱点を考慮に入れる必要がある[14] 。コロイドの最近のいくつかのメタアナリシスでは、追跡期間の短さが大きな問題となっていた[15,16]。
無作為化対照試験のメタアナリシス
物流上、財政上、管理上の理由から、「大規模」試験の実施が困難であることは周知の通りである。したがって、集中治療や麻酔における多くの介入のエビデンスベースは、大部分が「小規模な」研究で構成されており、臨床的な行動に統計学を利用する必要がある。メタアナリシスは、通常システマティックレビューで与えられる分析力を高めるために、個々の研究の結果を組み合わせることを目的としている。類似の研究の結果を統計的に組み合わせることで、治療効果の推定値をより正確にすることができ、類似の状況で治療効果が類似しているかどうかを評価することができる。変動性は、多施設RCTにおける母集団の違いにつながる患者に内在する要因から生じ、患者に外在する要因には、患者の募集方法や管理方法などがある。個々の研究の結果がメタアナリシスで結合されるほど類似しているかどうかの判断は、結果の妥当性に影響を与える[17]。
コロイド論争
コロイド輸液研究では、Van Der Lindenらによるメタアナリシス[15]は、あまりにも異なると考えられる研究を組み合わせていると批判されてきた[18] 。 小規模な研究に基づくメタアナリシスから、麻酔学およびクリティカルケア医学におけるより意味のある大規模な研究の結果へと進化し、更新されたメタアナリシスへの影響は、次の例で最もよく説明できる。重症患者を対象とした緊急輸液療法法と拡張法の研究に関するコクラングループのメタアナリシスに対応して、アルブミン溶液の使用に関するガイドラインが劇的に変更された。この変更と、その後の優先的に小規模な研究のメタアナリシスにより、矛盾した推奨事項がもたらされた[19,20]。
もともと低カリウム血症および低アルブミン血症の治療において、天然コロイドアルブミンの使用は、重症の集中治療室(ICU)患者に推奨されていた。1998年、集中治療患者におけるアルブミン投与に関するコクラン解析がBritish Medical Journalに発表された[21] 。このシステマティックレビューおよび24の小規模RCTを対象としたメタアナリシスでは、患者を他の輸液ではなくアルブミンで治療した場合、患者の死亡率が有意に増加するという結論が導かれた[21]。総和効果では、アルブミンを投与された患者では死亡率が70%近くも有意に増加することが示された。このメタアナリシスの結果により、コロイダル緊急輸液療法法におけるアルブミン溶液の一般的使用が劇的に減少した。ヨーロッパでは、アルブミンはほぼ完全に人工コロイド、特にヒドロキシエチルデンプン(HES)溶液に置き換えられた[22]。
そのわずか数年後、アルブミン治療を受けた重症患者の死亡率の増加を示唆するコクランのメタアナリシスは、更新されたメタアナリシスによって反証された。 このメタアナリシスでは、3504人の患者にランダムに割り付けられた55の試験が含まれており、525人が死亡した[23] 。観察された小試験バイアスは、大規模試験では小試験に比べてRRが実質的に低かったため、対照群に有利であった[23] 。 コクランアルブミンメタアナリシスは、小試験バイアスが寄与因子であっただけでなく、関連するランダム化試験の少数の偏ったサブセットが組み合わされていたため、再現不可能であることが証明された[24] 。 その後、大規模試験からの新たな証拠に基づいて、この更新されたメタアナリシスの結果が確認された[25] 。
重症患者へのアルブミン投与が死亡率やその他の有害事象を増加させるかどうかは、約7000人の患者を対象とした大規模RCTである「The Saline versus Albumin Fluid Evaluation」試験でようやく明らかになった[25] 。 この十分に大規模なRCTの結果から、小規模RCTの結果からの仮説は棄却され、現在では緊急輸液療法や低アルブミン血症の修正のためのアルブミン投与は安全であると考えられている。これは、メタアナリシスが疑問を投げかけ、”決定的な証明 “を目指して臨床試験を開始した例である。
さらに最近では、大規模RCTからの追加証拠により、アルブミン輸液の安全性がさらに確認された[26,27] 。重度の敗血症を有する成人におけるアルブミンの使用を評価した3つの大規模RCT[25,26,27]において、死亡率はアルブミン投与群の方がクリスタロイド投与群よりも低く、3つの試験すべてのプールされた死亡率の減少は統計学的に有意であった(プールされたRR:0.92;95%信頼区間[CI]:(0.84-1.0;P = 0.046)[28]。
最近の大規模RCTもまた、HES溶液の安全性について長年議論されてきた疑問を解決するのに役立っている。798人の患者を対象としたScandinavian Starch for Severe Sepsis/Septic Shock(6S)試験では、HES 130/0.42により死亡率と腎代替療法の必要性が増加した[12] 。 13] ICU患者2857人を対象としたCRISTAL(Colloids Versus Crystalloids for the Resuscitation of the Critically Ill)ランダム化試験では、28日目の死亡率または腎代替療法の必要性に対するコロイド(主にHES)の効果は観察されなかった[14]。 CRISTALのデータの探索的分析では、90日目の死亡率はコロイド群の方が低かった。
これらの試験はまた、規模や統計的検出力以外にも潜在的に重要な方法論の問題を例示している。HESの安全性を実証しようとする研究に対する根強い批判の一つは、フォローアップ期間の短さである。最近のコロイドのメタアナリシスでは、追跡期間の短さが大きな問題となっていた[15,16] 。この批判を裏付けるものとして、死亡率に対する有意な効果が90日後には示されたが、28日後には示されなかった6S試験がある。さらに、6S、CHESTおよびCRISTALはすべて、体液管理戦略が厳格なプロトコルに従うのではなく、出席した臨床医の裁量に委ねられた実用的な試験であった。特定のプロトコルを実施することで転帰が変更される可能性はあるが、これは実証される必要がある。
最後に、大規模な試験であっても、バイアスを最小化するような方法で実施されなければならない。例えば、CRISTAL試験では、主治医は治療の割り付けを盲検化していなかった。さらに、この試験では、ICU入院前の12時間にクリスタロイドを投与された患者では、コロイドに割り付けられる可能性が33%高く(P = 10-7)それ以前にコロイドを投与された患者ではクリスタロイドに割り付けられる可能性が15%高く(P = 0.001)無作為化に欠陥があることが顕著に示された。このような不均衡が偶然に生じた可能性は極めて低い。
重症敗血症/敗血症性ショックのためのスカンジナビアのスターチとCHESTは、特に規制措置を促す上で決定的な役割を果たしている。欧州医薬品庁(www.ema.europa.eu/docs/en_GB/document_ library/Referrals_document/Solutions_for_infusion_containing_hydroxyethyl_starch/European_Commission_final_decision/WC500162361.pdf; accessed 8 July 2014)と米国食品医薬品局(www.fda.gov/BiologicsBloodVaccines/SafetyAvailability/ucm358271.htm; accessed 8 July 2014)の両方が、敗血症を含む重症患者にHES溶液を使用すべきではないと決定した。欧州では、急性失血による低カリウム血症の治療にHESを使用することは引き続き認められるが、HES輸液後90日間の腎機能のモニタリングなど、新たなリスク最小化の手順が求められることになる。
イベント率 試験の規模が十分かどうかを判断する
死亡、敗血症、肺炎などの臨床的に重要な試験のエンドポイントは二項対立であり、発生頻度が低いため、大規模なRCTで研究するのが最善である。麻酔や集中治療医学では、これらのエンドポイントは一般的に患者に合併症や多臓器不全がある場合に発生し、個々の治療の臨床的に重要な転帰への影響を判断することは困難であることが多い。RCTの包含基準にもよるが、このようなイベントの頻度は2~10%の範囲内であると推定されている。対照的に、バイタルパラメータ、血行動態パラメータ、または臨床検査パラメータの有意な変化など、臨床的に重要性の低いエンドポイントは、多くの場合、これらの代替パラメータが検証されていないにもかかわらず、より頻繁に発生する。エンドポイントイベントの発生頻度が低いほど、研究集団内でのエンドポイントイベントの発生頻度が高くなる;つまり、SN比が低いほど、ランダムイベントが過度に強調されるのを防ぎ、統計的に意味のある研究結果を得るためには、RCTの規模が大きくならなければならない。したがって、RCTのエビデンスに基づいた医療への影響を解釈する際には、サンプルサイズのイベント率は、関心のある仮説を検証するための適切な力を研究に与えるために十分に高くなければならない。イベント率、臨床的に意味のあるRR短縮率、実際の患者数に基づいてサンプルサイズを決定することは、研究結果を解釈する際にRCTの最も重要な特徴の一つである[29]。
麻酔と集中治療における臨床研究のほとんどの質問の目標は、試験した介入で、20-25%のRR削減に達することができることを証明することである。例えば、定義された観察期間中の対照群の死亡率が8%であった場合、RRを25%減少させると、100人中8人の死亡が6人に減少し、2人が死亡することになる。統計的検出力とは、効果がゼロであるという帰無仮説を正しく棄却する確率のことである。したがって、統計的検出力が高いほど、帰無仮説を正しく棄却する確率が高くなる。図1の左側のパネルは、ベースライン率を8%と仮定した場合のRR低減と3つの一般的に認められている検出力の値(80%、90%、95%)の関数として、研究に必要な総標本サイズを示している。サンプルサイズは、Agresti (p. 242)に記載されている方法を用いて算出した[30] 。 全体的に、被験者数は所望の検出力に応じて増加し、RR低減の大きさに応じて減少する。例えば、RCTの検出力が80%(すなわち、効果が本当に存在することを考えると、100回の研究の繰り返しで80回有意な結果が確認されることになる)とすると、ベースラインのイベント率が8%の場合、RRが20%減少することを証明するためには6450人の患者が必要となる。
図1 5%の有意水準を仮定した場合の効果量と検出力の関数として必要とされる研究被験者数(左図)
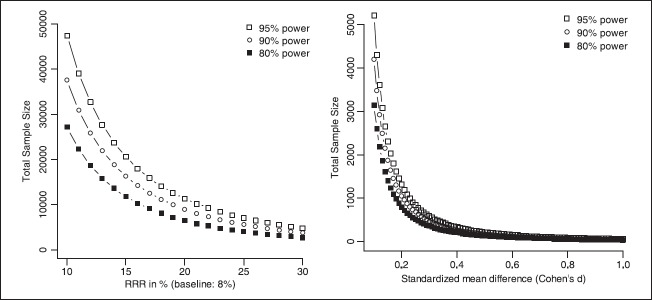
ベースラインイベント率8%を仮定した二項対立変数、右パネル。右側のパネル:均質分散を仮定した連続変数)
意味のあるサンプルサイズの計算を行わず、予測される患者数を含めていない研究は、パワー過剰またはパワー不足のリスクがある。過剰な力のある試験とは、非常に大きなサンプル数を用いた場合に、極端に小さな差があっても統計的に有意な結果が得られるようなデータの状況を意味する。パワー不足試験とは、サンプルサイズが小さすぎるために、(実際に存在する)効果を検出できない試験のことである。どちらの場合も、有効な結論を導き出すことはできない。RCTで統計的に有意な効果が検出されない場合、これは真の効果がないか、研究集団が少なすぎたことが原因である可能性がある。真の効果がないことは、その試験が十分なパワーを持っている場合にのみ結論を出すことができる。
麻酔・集中治療医学における小規模試験の脆弱性
統計的に有意な結果が得られた小規模なRCTは、特にICUや手術室のように研究集団が異質な場合には、しばしば不正確であることが証明される。繰り返し行われた場合、結果が統計的有意性に達しないことがよくある。その理由の一つは、イベント頻度のわずかな変化でさえ、P値が有意(P < 0.05)から無有意(P > 0.05)に大きく変化することがあるからである。例えば、400人の患者を対象とした研究(介入群200人、プラセボ群200人)では、対照群で10件のイベントがあり、治療群で2件のイベントがあった場合、1自由度(df)で4.21の2×2分割表のχ²値が得られる。したがって、この差はP = 0.04で統計的に有意であるであろう。イベント率の減少が10から 2ではなく10から3になった場合、χ² = 2.86 (df = 1)となり、有意ではないP = 0.09が得られる。試験のイベント率の最小の変化の統計解析結果への有意な影響は、イベント率が低い場合に見られ、したがって、小規模RCTの脆弱性に寄与している。結果として、統計的に有意なP < 0.05は必ずしも臨床的関連性があるとは限らない。形式的には、P < 0.05とは、真の差がゼロであると仮定しながら、少なくとも実際に観察されたものと同じくらい極端な研究群の差が得られる確率が5%よりも小さいことを意味する。明らかに、この確率は、観察された差の臨床的関連性について何の記述もしない。類推では、例えば、RRが45%で95%CIが4〜90%というのは、研究の100回の繰り返しのうち95回で、信頼範囲が真のRRと重なることを意味する。したがって、信頼度(例えば、95%)は、(未)確実性の程度を決定する。このような研究結果から臨床的に適切な結論を導き出すためには、信頼区間が非常に重要である。CIが広すぎる場合は、RCTのサイズが小さすぎた可能性が高い[29]。
メタアナリシスにおけるサンプルサイズ
「小規模試験効果」という用語は、同じメタアナリシスにおいて、小規模試験の方が大規模試験よりも治療効果が高いと報告する傾向を示す。サンプルサイズは、同じ問題を調査しているメタアナリシス内であっても試験によって大きく異なる[31] 。遺伝性疾患や特定の肝疾患のように、疾患の特徴によって不均一性の少ない患者集団を同定できる場合には、S/N比が確実に高くなり、小規模であっても研究の脆弱性が低くなる可能性がある。十分な試験サイズと不十分な試験サイズの区別は、CIの大きさによってよりよく反映されるかもしれない[29]。
さまざまな病状および介入の大規模なメタアナリシスのコレクションにおいて、治療効果推定値に対する試験サンプルサイズの影響を評価する際、治療効果推定値は試験サンプルサイズのみに基づいてメタアナリシス内で異なり、小規模な研究ではより強い効果が認められた[31]。 したがって、メタアナリシスの結論の頑健性は、メタアナリシス全体の結果が最大の研究の4分の1の結果と一致するかどうかを確認することによって評価されるべきである。プールされた結果は、そうでない場合には慎重な解釈が必要である。
結合された治療効果は、真の治療効果の最良の推定値ではないかもしれない。したがって、「小規模研究効果」の概念は、一見有益な結果につながる可能性があるため、利用可能なすべての証拠をメタアナリシスに含めるべきかどうかという問題を提起する。個々の研究、特にそれらが小規模である場合には、メタアナリシスで結合されるのに十分に類似しているだけでなく、試験の仮説も同様の病態生理学的合理性と生物学的妥当性に基づいているべきである。「小規模試験効果」の最も重要な理由の中には、重要でない結果よりも有意な結果を得た研究の報告を公表する傾向があるため、小規模な研究ほど公表バイアスがかかりやすいということがある[32]。
経験的に、メタアナリシスは通常、大規模RCTと一致している[33] 。 メタアナリシスでまとめられた小規模研究間の治療効果の一貫性は、大規模RCTで確認される可能性の高い信頼できる結果をもたらす可能性がある[34] 。 実際、大規模試験における治療効果の一貫性は、個々の大規模試験では実証できない結論をメタアナリシスで導き出すことを可能にしている[25,26,27] 。
極端な均質性 – メタアナリシスに関するその他の洞察
研究間の極端な同質性は、メタアナリシスとその構成研究に有用な洞察を与える。小規模試験は真の治療効果を過大評価する可能性が高いだけでなく、報告の偏りや不正が起こりやすい[35,36,37] 最近、麻酔科と集中治療医学の分野では、Boldtらによる小規模単施設臨床試験の発表が合計90件[38]撤回されたが、そのうち88件は2011年に倫理委員会の関与を怠ったことと不正が原因であり[39]、さらに2014年にはデータの捏造が確認されたため、さらに2件が撤回された。 [40,41] 後者の2件については 2006年に不正の可能性を示唆する報告で治療効果の極端な同質性がすでに観察されていた[42]が、アルブミンまたは血漿タンパク質画分とヒドロキシエチルデンプンの輸液による療法による死亡率に差があるかどうかを検討したメタアナリシス[43]では、全体的に研究間での同質性が極端に高かった。しかし、追跡期間中にイベントが発生した10件の研究(メタ解析の全20件の研究のうち)のうち5件は、明らかにBoldtらによって実施されたものであった。 これらの5件の研究は、ほぼ同一のデザインであり、メタ解析におけるイベントの総数の70%を占めており、これらの研究はすべて、同一の層別化と同一の割り付けスケジュールを使用して、同一の施設から行われたものであった[42]。 偏った詐欺的な研究発表は、著者が1つの診療科のみの単一施設のものであることが多いが、患者集団はケアに複数の診療科の関与を必要とするような特徴を持っていた。さらに、募集期間に関する情報が提供されていないことが多い。
サロゲートエンドポイント試験
サロゲートマーカーは、一次エンドポイントの数が非常に少なく、統計的に有意な数のエンドポイントを収集するための臨床試験を実施することが非現実的な場合に使用される。パラメータは多くの場合、臨床的に意味のあるエンドポイントの代わりになることを目的とした連続的なアウトカム指標であるバイオマーカーや生理学的指標である。臨床的な意思決定に有益な情報を提供するためには、重要な臨床転帰を有するRCTを含む広範な研究を必要とするサロゲートエンドポイントのバリデーションが重要である。
連続的なアウトカム指標では、試験に参加している各人が情報を提供することになる。このような研究における標本サイズの計算は、我々が確実に検出したいCohenのdのような標準化された平均差に基づいている。Cohen[44]は、d = 0.2,0.5,および0.8がそれぞれ小、中、および大の効果を示すことを示唆している。例えば、最小差が d = 0.5 の場合、2 × 64 人の被験者のサンプルサイズで十分であり、名目上の有意水準を 5%とし、所望の検出力を 80%とすると、十分である。対照的に、最小差 d = 0.2(効果が小さいと考えられる)の場合、80%の検出力を得るためには、2 × 394 人の被験者が必要となる(ここでも名目上の有意水準を 5%と仮定している)。図1の右側のパネルは、Cohenのd、所望の検出力、および5%の有意水準の関数として必要な総被験者数を示している。ここでも、総標本サイズは、検出力とともに増加し、効果の大きさとともに減少する。この種の近似計算は、研究が確固とした結論を支持するのに十分な「十分な大きさ」であるかどうかを判断するのに役立つ。より詳細な標本サイズの計算は、無料でできるソフトウェアツールを使用して行うことができる。
結論
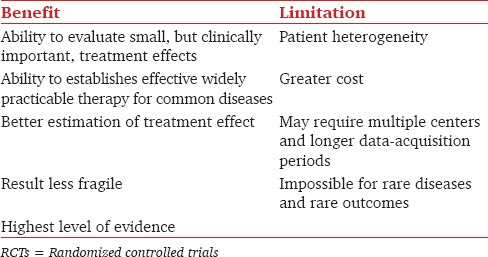
過去10年の間に、麻酔および集中治療医学の臨床研究は、ほとんどが小規模な研究から大規模なRCTへと変化してきた。緊急輸液療法に関する研究の経験から、メタアナリシスを含むパワー不足の研究で見られる治療効果の過大な解釈から生じる問題が明らかになっている。小規模試験は、重要なエンドポイントに対するパワーが不足していることが多く、脆弱で、バイアスがかかりやすいため、誤解を招く。小規模試験のメタアナリシスは、大規模試験の結果と一致している場合には有益である。大規模試験は、小規模ではあるが臨床的に重要な治療効果を評価することができ、真の治療効果をよりよく推定することができる[表1]。小規模試験に比べて、大規模試験は脆弱性が少ない。しかし、大規模試験はコストが高く、データ収集期間が長く、複数の施設で実施する必要があるため、管理が論理的に複雑である。
表1 RCTにおける大規模サンプルサイズの利点と限界