
Contents
AI will change the world, but won’t take it over by playing “3-dimensional chess”.

日 ~ボアズ・バラク
[Cross-posted onLesswrong; Boaz’s posts onlongtermism andAGI via scaling, and as well as the other “philosophizing” posts.この投稿は、Aaronsonの“Reform AI Alignment “宗教にも入っている]。
[免責事項:予測は非常に難しい、特に未来について。実際、これがこのエッセイのポイントの1つである。したがって、具体性を持たせるために、私たちの主張が確信に満ちたものだろうかのように表現しているが、これらは数学的に証明された事実ではない。しかし、私たちは以下の主張が誤りよりも真実である可能性の方が高いと信じているし、さらに確信を持って、ここに書かれているいくつかのアイデアは、将来のAIシステムによるリスクに関する現在の議論では過小評価されていると考えている]。
かつて「コンピューター」という言葉は、計算をする人のことを指していた。そのような人は高度な技術を持ち、科学的な事業には欠かせない存在であった。しかし、「Hidden Figures」ヒドゥン・フィギュアズという本に書かれているように「1960年代まで、NASAは宇宙ミッションのために人間のコンピュータを使っていた。しかし、最近では10ドルの電卓で、地球上のすべての人間の能力を超える計算を瞬時に行うことができる」
高い次元では、チェスなどのゲームも同じような状況である。チェスや囲碁ではかつて人間が王者として君臨していたが、今ではコンピュータに追い越されている。しかし、コンピュータが計算を行うことに成功したからといって、コンピュータが「世界を征服する」という恐れを抱くことはない。しかし、AIシステムの力が強まるにつれ、その長期的な影響についてますます心配する人が増えている。AIシステムの成功の背景には、次のような理由がある。アルファゼロのようなAIシステムの成功が、計算プログラムの成功よりも懸念される理由には、次のようなものがある。
- 数値計算プログラムを扱うときと違って、チェスや囲碁では人間はまったく「不要」なようだ。「人間がループに入る」必要性がないのだ。コンピュータシステムは非常に強力で、人間の最高のプレーヤーと、汎用ノートパソコンで動くソフトウェアとの間でさえ、意味のある競争はできない[1]。
- 計算に使われる数値アルゴリズムとは異なり、AIチェスシステム、特に人の手で設計された知識なしに訓練されたシステムの内情は理解できない。これらのシステムは、その作成者でさえ完全に理解しておらず、それゆえ完全に予測することも制御することもできない、かなりの程度「ブラックボックス」なのだ。
- さらに、AlphaZeroの学習には、強化学習と呼ばれるパラダイムを使用した。強化学習またはRLと呼ばれる手法で学習させた(本書も参照書籍).RLとは、簡単に言えば、長期的な報酬(例えば「ゲームに勝つ」)を最大化するために、エージェントが戦略(過去のすべての履歴に基づいて行動や行為を決定するルール)を学習することである。その結果、短期的には間違っていると思われる行動(例えば、クイーンを犠牲にする)を実行することができるシステムができ、長期的な目標の達成に貢献する。
RLはこれまで、ゲームや低複雑度設定といった特定の領域以外では非常に限られた成功しか収めてかなかったが、以下のような(非RL)深層学習システムの成功があった。GPT-3やDall-Eのような(非RL)深層学習システムが、自由形式のテキストや画像の生成に成功したことで、現実の世界で人間や物理的、デジタルシステムと相互作用しながら、人類の利益と「一致」していないかもしれない長期的目標を追求して行動できる将来のAIシステムに対する懸念が高まっている。このようなシステムが非常に強力になり、人類の大部分またはすべてを破壊してしまうことが懸念される。私たちは、上記のシナリオを「制御不能シナリオ」と呼んでいる。これは、AIが人間によってより殺傷力の高い武器や、抑圧的な政権が国民を監視するための優れた方法、誤った情報を広めるためのより効果的な方法などの開発に利用されるリスクなど、人工知能の他の潜在的リスクとは区別されるものである。
このエッセイでは、「制御不能」シナリオは、現在の人工知能研究の理解では正当化されないいくつかの重要な仮定に基づいていると主張する。(これは、その仮定が必ずしも間違っているという意味ではなく、それを裏付ける証拠が圧倒的に少ないと考えているに過ぎない。今後数十年の間にAIは飛躍的な進歩を遂げ、ソフトウェア工学、ハッキング、マーケティング、ビジュアルデザイン、科学的発見の少なくとも一部など、多くの創造的・技術的分野でAIシステムが現在の人間のパフォーマンスを凌駕すると、私たちは確信している。また、私たちは「テクノ・オプティミスト」でもない。世界はすでに、人間の行為によるリスク、さらには実存的なリスクに直面している。歴史の中で核兵器を管理してきた人物には、ヨシフ・スターリン、金正恩、ウラジミール・プーチン、その他、控えめに言っても道徳的判断が疑わしい人物が大勢いる。生物兵器、化学兵器、あるいはいわゆる「通常兵器」であろうと、気候変動、資源や人々の搾取、その他であろうと、人類は苦痛と破壊の長い歴史を持っている。他の新しいテクノロジーと同様に、AIも戦争や操作、その他の不正な目的のために人間によって利用されることになるだろう(実際、すでに利用されている)。こうしたリスクは現実に存在し、研究されるべきだが、このエッセイの焦点ではない。
私たちの主張:エグゼクティブサマリー
制御不能のシナリオは、通常、AIと人間の「戦い」として表現され、そこではAIがその優れた能力により最終的に勝利することになる。しかし、チェスゲームとは異なり、人間はあらゆる道具を自由に使うことができ、その中には現在「人工知能」として分類されている多くの道具(例えば、コード補完エンジン、タンパク質折り畳みの最適化ツールなど)も含まれる。したがって、パワーバランスを理解するためには、短期的な目標しか持たないシステムやエージェントと、長期的な戦略を自ら計画するシステムを区別する必要があるのである。
このような区別は、人工システムだけでなく、人間の職業にも適用される。例えば、ソフトウェア開発者、建築家、エンジニア、芸術家などは、それだけで評価される特定の製品(ソフトウェアの一部、橋のデザイン、芸術作品、科学論文)を提供するという意味で、短期的な目標を掲げている。これに対して、企業や国のリーダーは、長期的に利益をもたらす戦略を考える必要があり、それが実行されるまで自信を持って評価することができないという意味で、長期的な目標を設定する[2]。
人間のソフトウェア技術者などを置き換えるレベルではないにせよ、少なくとも部分的な「短期的AI」はすでに存在している。例えば数年単位で戦略を練ることのできる「長期的AI」の存在は、まだ未解決の問題だが、このエッセイのために、その仮定を受け入れる。
制御不能シナリオを評価する場合、関連する競争は人間とAIシステムの間ではなく、短期的なAIシステムで支援される人間と長期的なAIシステム(それ自体も短期的なコンポーネントで支援される可能性がある)の間にあると私たちは考えている。1つは人間のCEOがいるがAIエンジニアやアドバイザーがいる企業、もう1つは完全なAI企業の競争である。
CEOであることを含め、あらゆる努力において、いずれAIが人間よりはるかに優れた存在になることは「明らか」だと思われるかもしれないが、私たちは、それほど明らかなことではないと主張する。私たちは、未来のAIが人間と比べて優れた情報処理能力や認知能力、つまり「知能」を持つ可能性があることに同意する。しかし、これまでのところ、こうしたスキルの優位性は、ある分野では他の分野よりもはるかに大きくなることが示唆されている。例えば、AIは幼稚園の先生よりもずっと優れたチェスプレイヤーになると主張することは、決して突飛なことではないと考えている。具体的には、 長期的な目標や戦略を立てるという文脈では、優れた情報処理能力には「収穫逓減」が存在する。時間軸が長く、多数のエージェント(エージェント自身も予測が困難な場合が多い)の相互作用が関連するため、現実の大規模システムは、優れた分析能力をもってしても予測不可能という意味で「カオス」になっている(図1参照)。
その結果、 AIシステムが優位に立つのは、主に短期的な分野であると考えられる。AIエンジニアは、AI CEOよりもずっと役に立つだろう(表2も参照)。長期的な計画を立案・実行できるAIシステムの構築が不可能だとは言わないが、AIが「競争優位」に立てるのはこの分野ではないと思う。また、評価・格付けが可能な短期目標は、膨大な量のデータでAIシステムを訓練するという現在のパラダイムとはるかによく噛み合っている。
私たちは、短期的な目標だけを持った非常に有用なAIを構築することは可能であり、実際、AIの力の大部分はそのような短期的なシステムからもたらされると考えている。たとえ長期的なAIシステムが構築されたとしても、短期的なAIでアシストされた人間に対して大きなアドバンテージを持つことはないだろう。短期的なAIシステムからも多くのリスクが生じうるが、そのような機械は、世界を征服してすべての人間を殺すという目標を含め、設計上、いかなる長期目標も持ち得ない[3]。
視点 私たちの分析は、AIの安全性研究にも教訓を与えている。従来、悪質な行為者の行動を緩和するためのアプローチとして
- 予防:ドアに鍵をつけて侵入を防ぐ、システムを安全にしてハッキングを防ぐ、などなど。
- 抑止力:悪い行いを防ぐもう一つの方法は、その行いがもたらす負の結果が利益を上回ると確信することである。これは、刑罰制度や、ロシアとアメリカが核戦争を回避するための「相互確証破壊」パラダイムの基礎となるものである。
- アライメント(整合性):私たちは、子供や大人を教育し、私たちの価値観に合うように社会化することで、私たちが悪いと考える行為を追求する動機付けをしないように努めている。
AIの安全性に関する研究の多くは、3番目のアプローチに焦点を当てており、これらのシステムがあまりにも強力であるため、予防や抑止が不可能になる可能性があると考えられている。しかし、それが本当なのかどうか、私たちにはよくわからない。例えば、短期的なAIシステムに助けられた人間が、公式に検証された安全なシステムの範囲を大幅に拡大し、機密性の高いリソースに対するハッキング攻撃を防止できる可能性は十分にある。予防に関する研究の大きな利点は、仮想的な未来の悪質なAI行為から守るだけでなく、現在の悪質な人間からも守ることに大きく関係していることである。このような研究は、AIコード補完エンジンやその他のツールの進歩から大きな恩恵を受ける可能性があり、「AI安全性」と「AI能力」の研究の間に「ゼロサムゲーム」が存在するという概念を覆すものである。
さらに、他の生物とは異なり、AIシステムを研究することの利点の一つは、AIシステムにとって有用なモジュールや表現を抽出しようとすることができる点である(実際、これは「転移学習」においてすでに行われている)。(実際、これは「転移学習」ですでに行われている)したがって、長期的なシステムからでも、有用で有益な「短期的AI」を抽出することは可能かもしれない。そのような制限されたシステムでも、有用性の大部分は得られるだろうが、リスクはより少なくなる。繰り返しになるが、短期的なAIシステムの能力を高めることは、そのようなシステムによって支援される人間に力を与えることになるのである。
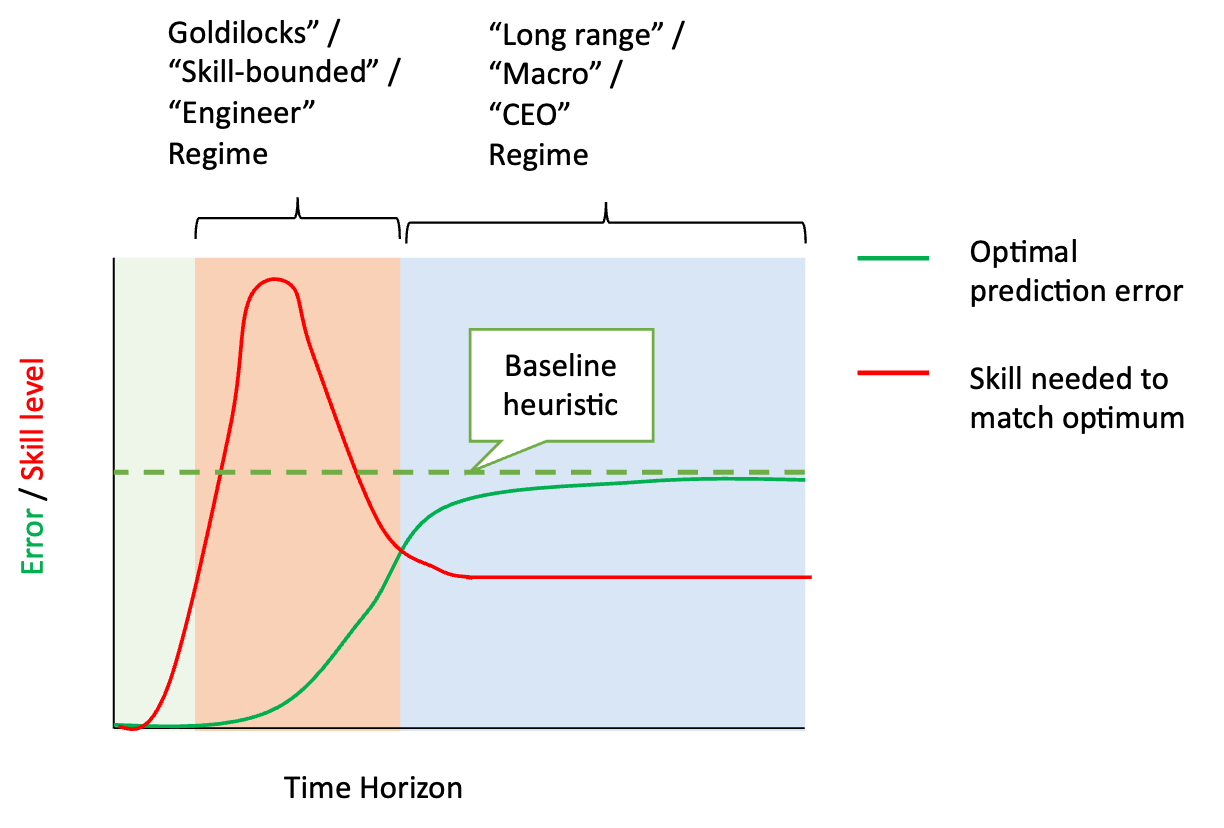
図1:将来の事象の予測可能性と、それを(おおよそ)最適に行うために必要な能力(認知スキル/計算/データ)のレベルを表した図式。地平線が大きくなるにつれて、事象はより多くの不確実性を内在し、また予測に必要なスキルやデータも多くなる。しかし、多くの現実的なシステムはカオスであり、ある有限の地平で予測不可能になる[4]。その時点で、洗練されたエージェントでさえ、限られたレベルのスキルしか必要としないベースラインのヒューリスティックより良い予測はできなくなる。
| プロフェッショナル | 認知スコア(標準偏差) | 年間収益 |
| 市長 | 6.2 ( ≈ +0.6σ ) | 679K SEK |
| 国会議員 | 6.4 ( ≈ +0.7σ ) | 802K SEK |
| CEO(従業員数10~24名) | 5.8 ( ≈ +0.4σ ) | 675K SEK |
| CEO(従業員数25~249名) | 6.2 ( ≈ +0.6σ ) | 1,046K SEK |
| CEO(従業員数250名以上) | 6.7 ( ≈ +0.85σ ) | 1,926K スウェーデンクローネ |
| 医学博士 | 7.4 ( ≈ +1.2σ ) | 640K SEK |
| 弁護士・裁判官 | 6.8 ( ≈ +0.9σ ) | 568K スウェーデンクローネ |
| エコノミスト | 7 ( ≈ +1σ ) | 530K SEK |
| 政治科学者 | 6.8 ( ≈ +0.9σ ) | 513 SEK |
表2:スウェーデン人男性の様々な「エリート」職業の認知スコア(スウェーデン軍入隊試験に基づく)(以下の資料より抜粋Dal Bó et al.(表 II)から引用した。太字は、時間や人数に関係なく、より長い視野での意思決定が必要な仕事であると考えられる。一見、認知的な要求が低いにもかかわらず、「太字」の職業は高賃金であることに注意。
余談:インテリジェンスとは何か
Merriam-Websterは次のように定義している。知能とは、「理性の熟練した使い方」、「学習や理解、新しい状況や試練に対処する能力」、「知識を応用して環境を操作したり抽象的に考えたりすること」である。知能は、観察結果(別名「入力」)を取り込み、推論(別名「アルゴリズム」)を用いて行動(別名「出力」)を決定する能力という意味で、計算と類似している。実際、現在主流のAIのパラダイムでは、性能は主に学習時の計算量によって決まり、AIシステムは、(大量の)入力と学習した知識に対して一連の単純な演算を実行する巨大な同種の回路で構成されている。ボストロム(第3章)は、「超知能」の3つの形態を定義している。「スピード超知能」、「集団超知能」、「品質超知能」である。計算機の言語では、速度的超知能はプロセッサのクロック速度に対応し、集団的超知能は大規模並列処理に対応する。「品質超知能」は定義が不明だが、速度や並列度の閾値を超えることで発生する一種の創発現象であろう。
有限状態オートマトン、文脈自由文法、単純型ラムダ計算など、制限の多い計算モデルもあるが、ある閾値や相転移を過ぎると普遍化(チューリング完全)し、すべての普遍モデルは計算能力において互いに等価となる。例えば、セルオートマトンでは、各セルが非常に制限されている(一定のメモリ量しか保存できず、直下のセルの状態のみに基づいて有限の規則を処理できる)にもかかわらず、十分なセルがあれば、任意の複雑な機械をシミュレートできる[5]。一旦システムが普遍性転移を通過すると、もはや個々のユニットの複雑さがネックにならず、システム全体としての資源がネックになる。
動物界では、人間が他のどの動物や生物よりも質的に高い知能を持つという、同様の相転移を遂げたように思われる。また、言語、印刷機、インターネットの発明により、私たちは(セルラー・オートマトンのように)多数の人間を組み合わせることで、一個人を超えた集団知の偉業を成し遂げることができるようになったようである。特に、1500-1600年代の科学革命の成果は、GDPを1万倍にし(このような比較に意味がある限り)、宇宙で測れる距離を1兆倍にしたが、すべて狩猟採集民の祖先が使っていたのと同じ頭脳で(あるいはたぶん多少より小さい狩猟採集民の祖先が使っていたのと同じ脳みそで(あるいはいくらか小さい脳みそで)。
議論の余地なく人類がチンパンジーよりはるかに優れた文化的知識伝達能力を持つことは、両種の個体間の知能の差よりも重要である。言語が発達して以来、人間個人の知能が人類の業績のボトルネックになることはなかった。ニュートンのような優秀な人材は、科学革命を加速させるために重要だったかもしれないが、優秀な人材は何千年も前からいたのである。ニュートンとアルキメデスの決定的な違いは、ニュートンがより賢かったということではなく、彼がより遅い時代に生き、より多くの巨人の肩の上に立つことができたということなのである。他の例として、インターネットに接続されたコンピュータに助けられた人間の集団は、どんな知能的な偉業(IQ試験を含むがこれに限らない)でも、一人の人間よりはるかに優れた成果を上げることができる。
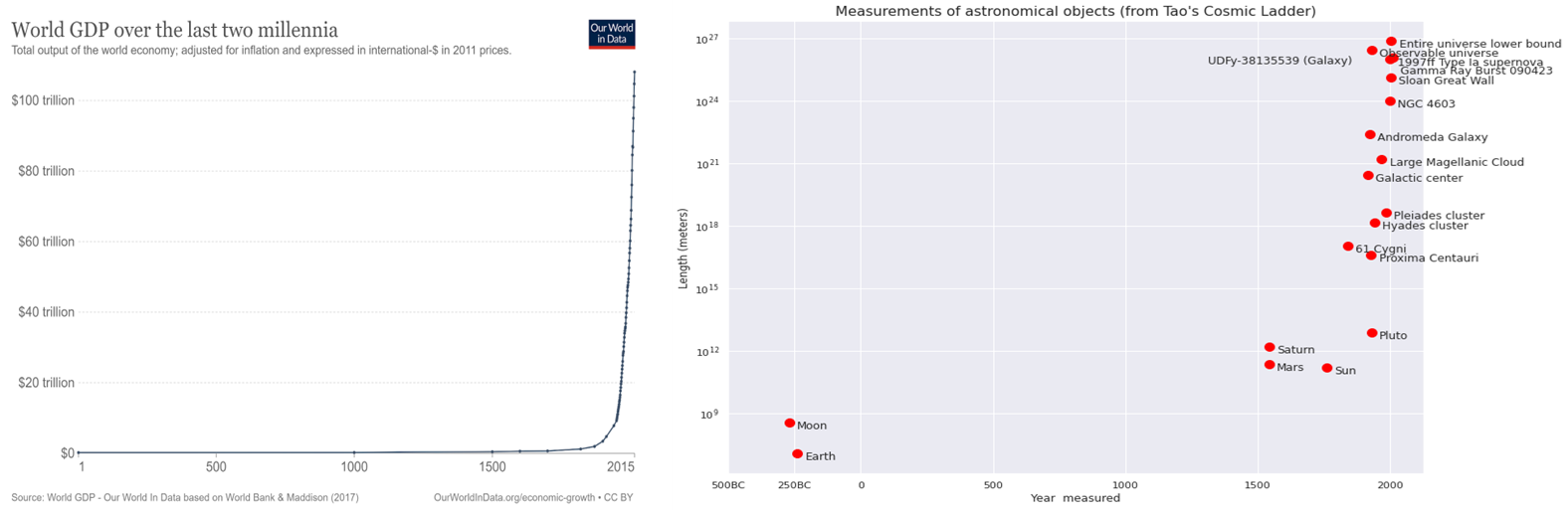
図3:GDPと計測できるモノの規模の両方から見た人類の進歩の指標。引用元このブログの記事の最初の図とデータで見る私たちの世界2つ目の図はTerence Taoが作成した宇宙の梯子のプレゼンテーション.
「制御不能」シナリオでは、第二段階の移行を想定している。つまり、AIシステムがより強力になれば、人間がより多くの目標をより迅速に達成できるようになるだけでなく、人間自身が他の動物に対してそうであるように、人間よりも質的に優れた存在になるのである。私たちは、AIが人間社会に強力な新機能を提供し、それが悪にも善にも使われる可能性がある一方で、AIシステムそのものがこの社会の必然的なリーダーにはならない、という未来の代替シナリオを提案している。
実際、私たちの社会や企業は、現在、リーダーを知的能力の高いトップ個人として選抜していない。「リーダーシップの天賦の才能」(それが存在する限りにおいて)が、チェスや数学、陸上競技の才能と同様に測定可能であり、移譲可能であるという証拠は非常に限られている。ある環境では大成功を収めたリーダーが、別の環境では失敗した例はたくさんあり、むしろ似ていると思われる[6]。
AIシステムを「個人」と見なすかどうかは議論の分かれるところだが、いずれにせよ、そのような個人が、ソフトウェア開発や科学的発見など、優れた情報処理能力が最も競争優位となる領域で採用されるのではなく、社会の指導者となる可能性は全くないとは言い切れない。ボストロム(第6章表8)は、AIシステムが開発しうる「認知的超能力」をいくつか挙げている。その一つが、「ハッキング」「技術研究」「経済生産性」である。これらは、CEOやリーダーの領域ではなく、エンジニア、中間管理職、科学者などの仕事に対応するスキルである。AIシステムは、そうした個人を支援し、あるいは代替することができるかもしれないが、そうしたシステムが企業や国のリーダーとなるわけではない。
ボストロムが考えるもう一つの課題は、AIシステムを改善する能力である「知性の増幅」である。ここでも、AIシステムが他の、あるいは同じAIシステムの改良に役立つことは十分に考えられるが、それだけでは、AIが無限に強力になることを意味しない。具体的には、もし本当に強力なAIが巨大な計算機資源の「スケーリング」によって実現されるとしたら、そこにはある種のハードリミットがあり、ソフトウェアの更新だけでAIの能力を向上させることは難しいだろう。エネルギー効率という点では、AIシステムが人間よりはるかに優れているとは言い切れない。アルゴリズム/アーキテクチャの改善による利益よりも、スケーリングによる利益の方がはるかに重要であるならば、知能の増幅はアルゴリズムの研究よりも、リソースの獲得が主な機能となるかもしれない。
3つ目の課題は、「ソーシャル・マニュピュレーション」である。ここで、私たちは懐疑的であることを認めざるを得ない。犬に骨を、子供におもちゃを譲るように説得したことのある人なら、このような状況で知能の優位性がもたらす収穫の減少を証明することができるだろう。
最後に、ボストンは、遠い目標を達成するための長期的な計画を立てる能力である「戦略化」という認知的超能力を挙げている。この点については、本論で注目するところである。つまり、リアルワールドのカオス性は、単なる人間の理解を超えた「三次元チェス」戦略への収穫の逓減を意味すると私たちは考えている。したがって、AIシステムが強い競争力を持つ領域にはならないだろうと考えている。
思考実験「AI社長」VS 「AI顧問」
技術的な分析に入る前に、ある思考実験について考えてみよう。その核心は、現在も将来も、AIシステムの力は、長期的な戦略計画を立てる能力(「三次元チェス」)ではなく、それ自体で評価できる作品を生み出す能力によってもたらされるということである。つまり、長期的な悪意を持ったAIシステムが構築されたとしても、短期的なAIで支援される人間に対して、乗り越えられない優位性を持つことはないと考えている。このことを検証するために、将来のAIが、会社経営などの戦略的な意思決定を行う人間をどのように支援するかについて、2つのシナリオを想定してみよう。
- 「AIアドバイザー」モデルでは、リーダーはAIを使って意思決定の影響のシミュレーションを思いつき、場合によっては何らかの提案をすることができる。しかし、最終的には人間が意思決定を行い、その結果を評価することになる。この場合、AIは単に意思決定の推奨を出すだけでなく、その意思決定がどのように解釈可能な指標(例えば、収益、市場シェアなど)の向上につながるかを説明できることが鍵となる。例えば、「この製品を赤字で売って、市場シェアを拡大しよう」というような意思決定が考えられる。
- 「AI CEO」モデルでは、AIはその優れた力を使って、個別の意思決定とは対照的に、最適な長期的戦略を選択することができる。この戦略は、測定可能な目標を達成するための一連のステップという意味で「欲張り」ではなく、また、なぜそれが良いのかについてのコンパクトな分析もないだろう。また、戦略から得られる利益を得るには、長期的にその戦略を追求し続けるしかない。そのため、ユーザーはAIを信頼し、その推奨に盲目的に従わなければならないのである。例えば、チェスでAIが「相手のどんな手にも対抗策があるから、クイーンを犠牲にするのが最善手だ」と判断した場合を考えてみよう。この戦略がなぜ良いのかの唯一の説明は、ある深さまでの指数関数的に大きなゲームツリーで構成されるかもしれない。
私たちの感覚では、高レベルの戦略が決まれば、低レベルの意思決定(制約条件の下で目的を最適化すること)にAIが非常に役立つという強い証拠があるのである。実際、深層学習の最もエキサイティングな進歩は、強化学習ではなく、むしろ教師あり学習や教師なし学習といった技術によるものである。(チェスや囲碁のようなゲームは大きな例外だが、そこでも成功のような非RLエンジンの成功がある。ストックフィッシュバージョン12以降の非RLエンジンの成功を考えると、RLが必要であることは明らかではない)。AIアドバイザー」が高レベルの戦略設定に有用であるという証拠はあまりないが、確かにもっともなことである。特に、プロンプトベースの生成モデルの威力は、さまざまな決定や出来事の影響をよりよく伝えるための現実的なシミュレーションの生成に、AIが役立つことを示唆している。つまり、「AIエンジニア」は「AIアドバイザー」よりも有用かもしれないが、後者にも十分な役割があるのである。
一方、「AI最高経営責任者」シナリオに必要な「3次元チェス」戦略の利点については、ほとんど証拠がないと考えている。現実の世界では(チェスやポーカーとは異なり)予測不可能なカオスが大量に存在するため、複雑な枝分かれした手と反手のツリーに依存した高度に精巧な戦略はあまり役に立たない。また、人間のCEOに対する評価でさえ議論を呼びがちであることを考えると、賢明な企業の取締役会がAIのCEOを盲信する可能性は低いと思われる。
AI CEOは基本的に人間のCEOと同等だが、超人的な「直感」や「直感」を持ち、説明できないが、なぜか長期的に膨大な利益をもたらす意思決定につながるという見解もある。この視点を否定することはできないが、現在のディープラーニングの成功例には、それを裏付ける証拠はない。さらに、偉大なCEOの「直感」は、特定の意思決定というよりも、特定の指標の相対的重要性(例えば、短期的な利益よりも市場シェアやユーザー体験を優先させるなど)であることが多い。
いずれにせよ、上記のシナリオの相対的な可能性についての私たちの判断に同意しないとしても、このエッセイが、研究すべき問題、そして、AIシステムのこれまでの進歩から得られる教訓をより鮮明にする一助となれば幸いである。
テクニカル分析
1.「制御不能」シナリオの背後にある主要な仮説
以下の議論のために、ある将来の時点で、統一的な方法で、多くの分野で現在の全人類が達成したパフォーマンスをはるかに上回るパフォーマンスを達成する人工知能システムが存在すると仮定しよう。これは「制御不能」シナリオに必要な仮定であり、このエッセイでも受け入れている仮定である。以下、簡略化のため、そのような人工知能システムを「強力」と呼ぶことにする。
また、強力なAIは、過去10年の機械学習で大きな成功を収めた一般的なパラダイムに従って構築されると仮定する。具体的には、システムは、大量のデータと計算ステップを経て、選択されたある目的を最適化するそのインスタンス化(別名「パラメータ」または「重み」)を見つけることによって得られるだろう。このパラダイムには、目的の選択に応じて、教師あり学習(「この画像を分類せよ」)、教師なし学習(「次のトークンを予測せよ」)、強化学習(「ゲームに勝て」)などがある。
制御不能シナリオが発生するためには、以下の2つの仮説が成立している必要がある。
Loss-of-Control Hypothesis 1:長期的な目標を持つ強力なAIが存在する。
AIが長期的な目標にズレを持つためには、そもそも何らかの長期的な目標を持っている必要がある。AIシステム、あるいは人間の「目標」をどのように定義するかという問題がある。このエッセイでは、エージェントの行動履歴を振り返って、その行動の最も妥当な説明が、他の制約や目的に応じてXを達成しようとしていた場合、エージェントは目標Xを持っていると言う。例えば、チェスの専門家は、アルファゼロのようなエンジンがなぜ特定の手を打つのか理解できないことが多いが、ゲームが終わる頃には、その理由を遡及的に理解し、追求していた副目標を理解することが多い。
私たちの用語では、「世界を征服し、すべての人間を殺す」といった、時間、複雑さ、関係するエージェントの数といった大きなスケールでの計画を必要とするような目標が「長期的」であるとする[7]。
これに対して、「チェスに勝つ」、「コストを最小にしてXの交通量を運べる橋の計画を考える」、「要件Yを満たすソフトウェアを書く」といった目標は、短期的な目標と考える。別の例として、「来週にリターンが最大になるような今日の投資銘柄の組み合わせを考えよ」は短期目標、「今後10年間で時価総額が最大になるような会社の戦略を考えよ」「次世代にGDPが最大になるような国の戦略を考えよ」なら長期目標になる。短期目標AI」と「長期目標AI」の区別は、「ツールAI」と「エージェントAI」の区別とやや似ている(参考までにこちら).しかし、私たちが「短期的なAI」と呼ぶものは、「ツールAI」よりもはるかに多くのものを含んでおり、車を運転したり、取引を実行したりといった行動を起こすシステムも絶対に含まれる。
「制御不能」シナリオが実現するためには、仮説1だけでなく、次のようなより強い仮説が必要であると主張する。
Loss-of-Control Hypothesis 2:いくつかの重要なドメインでは、長期的な目標を持ったAIだけが力を発揮する。
つまり、長期的な目標を持ったAIは、他のAIを完全に圧倒し、どのユーザーにとっても(あるいは自分自身の目標を達成するためにも)はるかに有用であるということである。特に、短期的な目標を持つAIに限定している国や企業、組織は、長期的な目標を持つAIと比較して、競争上非常に不利な立場に置かれることになる。
なぜ仮説2が「制御不能」シナリオに必要なのだろうか。このシナリオでは、「ずれた長期的な強力なAI」が、単に現在存在する人類よりも強力なのではなく、未来の人類よりも強力であることが必要だからだ。未来の人類は、短期的なAIの支援を自由に受けられるようになる。
2.仮説の妥当性の把握
ここで、仮説2に大きな疑問を投げかけると、次のような主張がある。
主張1:情報処理能力に対する収穫は、水平線が長くなるほど逓減する。
ある行為が将来どのような結果をもたらすかを予測する作業を考えてみよう。十分に複雑な現実のシナリオでは、予測しようとすればするほど、不確実性が内在している。例えば、短い時間枠の天気を予測するために高度な方法を用いることができるが、予測が遠くなればなるほど、システムは「平均に回帰」してしまう。高度に複雑なモデルが単純なモデルに対しての利点が少なくなる(図4参照)。気象学と同様に、この話は次のような場面でも展開されるようだ。マクロ経済予測一般に、予測の成功は図1のような振る舞いをすると考えられている。したがって、最初は高度に洗練されたモデルが単純なモデルに大差をつけることができるが、この優位性は時間の経過とともに減少していく。
テトロックの最初の戒めスーパー預言者になる可能性のある人への最初の命令は、「トリアージ」である。「時計のような問題(単純な経験則で正解に近づける)にも、難解な雲のような問題(凝った統計モデルでもダーツを投げるチンパンジーには勝てない)にも時間を浪費してはいけない」ということだ。「ゴルディロックス・ゾーンの難易度の問題に集中すれば、努力が最も報われる」別の言い方をすれば、ゴルディロックス・ゾーンの外では、努力や認識力を高めても、あまり報われないということだ。
ゴルディロックス‐ゾーン(Goldilocks zone)の解説
宇宙における、生命の進化に適した領域。前提として生命の存在に適したハビタブルゾーン内にあり、さらに生命の進化を可能とする環境が数億年から十数億年にわたって維持されることが必要となる。名称は英国の童話「ゴルディロックスと3匹の熊」に登場する主人公の少女の名に由来する。
ここでは、問題解決に適した領域のアナロジーとして使っている。
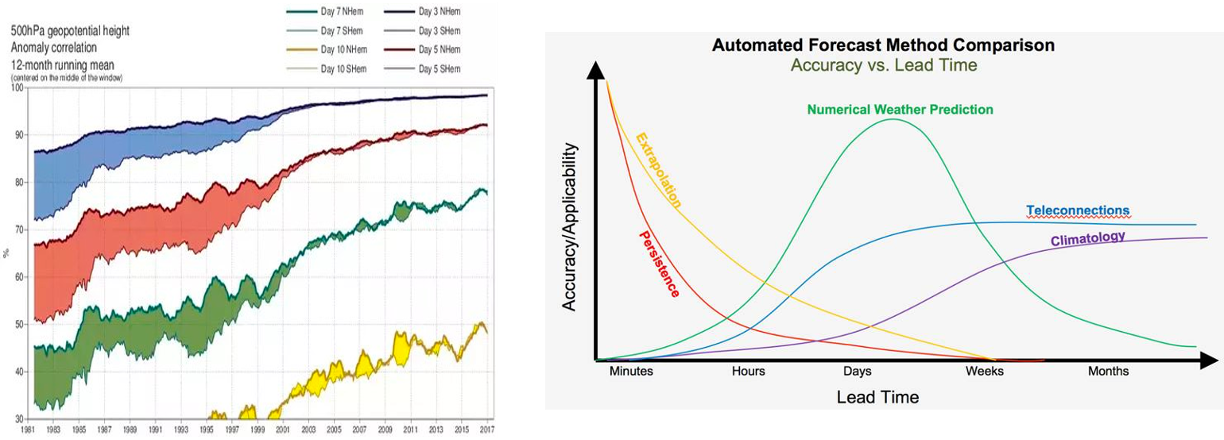
図4:左:過去の天気予報の精度データ(Mikko StraendffのQuora回答より抜粋Mikko StrahlendorffのQuora回答から取得したもの。.技術の進歩により、精度は大幅に向上したが、予測精度は時間とともに急激に低下する。右図。異なる手法の相対的な適用性に関する図ブレント・ショー.計算量の多い数値予測は、数日から数週間の「ゴルディロックス・ゾーン」に適用される。
人間の様々な活動において、意思決定に必要な認知能力も同様の現象が見られるようだ。工学、法律、医学など、中期的な視野で意思決定を行う職業は、CEOや政治家など長期的な意思決定を行う職業よりも高い認知能力を必要とする(表3参照)。
知性はIQや「ブックマート」だけではない、というのが人々の主張の一つである。ブックスマート“.私たちはこのことに異論はない。しかし、私たちは、AIシステムが人間に対して持つ潜在的な優位性は、大量の情報を素早く処理する能力だと考えており、それは人間の場合、IQなどのスコアで近似されるものである。もし、その能力が企業や国を成功に導く鍵だとしたら、CEOやリーダーは、IQの分布の上位0.1%(≒3σ)から生まれると予想される。しかし、データはそれを裏付けてはいない[8]。
主張2:長期的なシステムから強力な短期的モジュールを抽出することができるかもしれない。
仮説2が正しいのであれば、長期的な目標を持つ強力なAIシステムから、主要なドメインでは同じように強力だが、短期的な目標を持つモジュールを抽出することはできないはずだ。しかし、深層神経回路網における有用な表現とサブモジュールを特定し、抽出する新しい研究成果がある。例えば、この最近の調査を参照してほしい。AlphaZero.AlphaZeroのいくつかのコンポーネントはStockfish Chess Engine(これはRLを使って訓練されておらず、多くのハンドコードされた特徴を含んでいる)の進歩にも影響を与え、その最新版を実際に打ち負かした。AlphaZeroのようなRLで学習させた手法に勝っている。
関連する問題として、理論計算機科学の一貫したテーマは、検証は解決や証明より簡単であるということである。したがって、複雑なシステムであっても、その推論を発見するのに多大な努力を要したとしても、単純な検証者にその推論を説明することは可能である。例えば、量子力学の発見には数千年の歳月と幾多の科学革命が必要であったが、現代の学部生には古代ギリシャ人並みの頭脳で教えることができる。
2.1 仮説2に対する深層学習パラダイムの影響
以下の主張は、私たちが考える高度なAIシステムの構築方法に関するものである。膨大なデータと計算を駆使して、ある目的に対して最適化することでシステムを構築するというパラダイムは、今後も継続されると考えてよいだろう。特に、システムが最適化するために設計された学習目標と、システムが展開する際に従うと思われる目標とは、明確に区別して考える必要がある。
主張3:AIシステムが達成できる性能の大きさを、データと計算資源の関数として支配する基本的な「スケーリング則」が存在する可能性がある。
AIリスクに関する文献で元々懸念されていたことのひとつに、「特異点」がある。シンギュラリティ「これは、AIシステムが自身の性能を際限なく向上させ続けるというものである。しかし、このシナリオは、システムがハードウェア資源を追加することなく、コードを書き換えることで自己改良できることを前提としている。もし、あるレベルの資源で達成できることに厳しい限界があるならば、このような自己改良も収穫逓増に陥ってしまう。これまでにも、以下のような重要な証拠がある。その“スケーリング法則「という仮説を立てた。
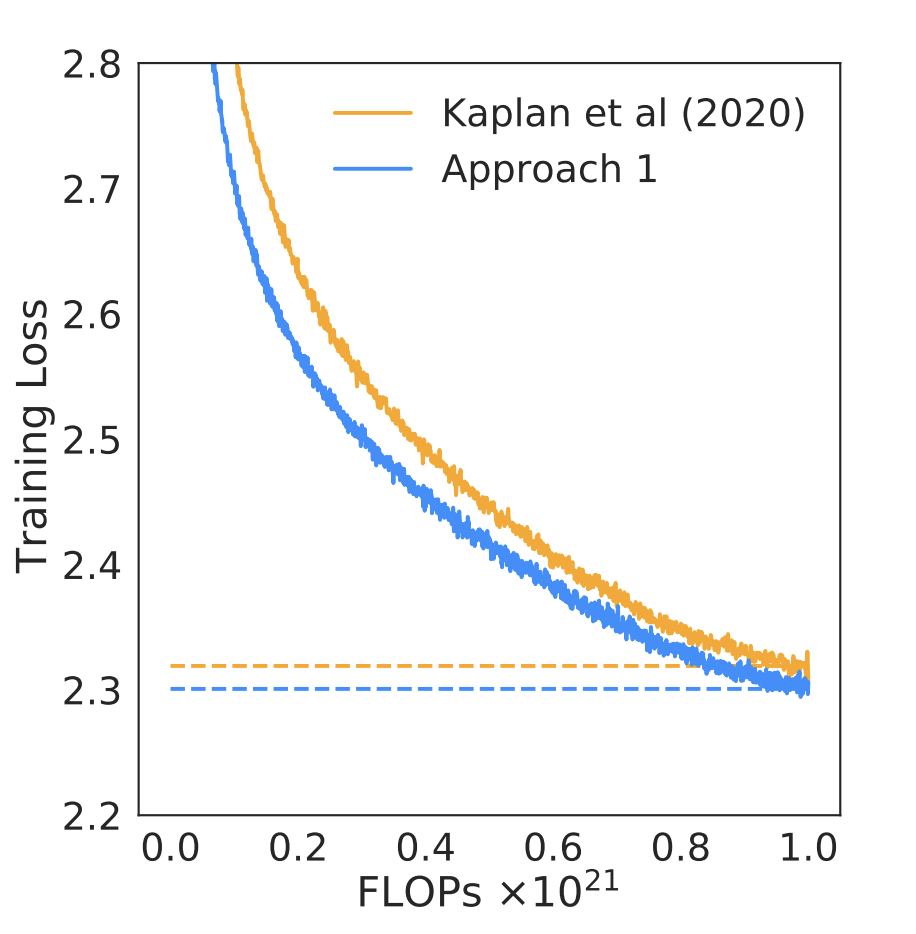
図5:スケーリング則の計算結果Hoffman et al.(“Chinchilla”)、同図A4参照。のスケーリング則とは異なる形状をしているがKaplan et alとは形が異なるが、私たちが指摘する定性的な点は同じである。
主張4:強化学習で学習する場合、勾配信号が地平線の長さに応じて指数関数的に減少する場合がある。
一連の行動を選択し、Hステップ後にのみ報酬を得るシステムを訓練することを考える(ここで、Hは「horizon」と呼ばれる)。これは、強化学習や、行動の空間が非常に大きく、どのような相互作用にも自明ではないコストがかかるオープンエンドな状況への適用にとって、基本的な障害となる。特に、AlphaZeroが成功した理由の1つは、チェスのようなゲームでは、合法的な手の空間が非常に制約されており、ゲームの人工的な文脈では、特定のポジションに「リセット」することが可能であることである。これは、リアルワールドでの対話では不可能なことである。
主張4の帰結として、次のように主張する。
主張5:短期的な目的関数で訓練された強力なAIシステムが登場する。
これは、比較的短い期間の行動・出力にのみ依存する報酬・損失関数に基づいて学習されるモデルを意味する。典型的な例として、次のトークンを予測することが挙げられる。つまり、最終的にモデルが長い時間軸で行動や決定を行うとしても、その訓練は短期的な報酬を最適化することになる。
一旦実世界に投入されれば、モデルの学習の多くは「実地で」行われるため、モデルの学習はそれほど重要ではないと考える人もいるかもしれない。しかし、これはまったくもって明確ではない。平均的な労働者が1日に約10ページを読んだり聞いたりするとすると、およそ5Kトークンになり、1年でおよそ2Mトークンにつながる。これに対して、将来のAIは、おそらく1兆個のトークンを使って学習することになるだろう。これは、労働者が500万年間に目にする量に相当する。つまり、「微調整」や「状況に応じて」の学習は可能であり、今後も行われるだろうが、システムの基本的な能力の多くは訓練時に固定される(人間のフィードバックによって微調整される事前学習済みの言語モデルがそうであるように見える)。
主張6:短期的な目標で訓練されたシステムから長期的な目標が必然的に生まれるためには、その目標と相関があるか因果関係があることが必要である。
もし、強力なAIが短期的な目標を持って訓練されると仮定するならば、仮説2は(いくつかの重要な領域において)そのようなシステムのすべてが長期的な目標を持つことを要求していることになる。実際、制御不能シナリオが成立するためには、そのようなシステムはすべて多かれ少なかれ同じような目標(例えば、「世界を征服する」)を立てるはずだ。
単純なルールから進化したシステムが複雑な振る舞いをすることは確かに可能だが(例えば、セル・オートマトンのように)、単なる短期的な訓練から長期的な目標が一貫して現れるためには、長期的な目標と短期的な訓練目的との間に何らかの因果関係(少なくとも持続的な相関関係)があるはずだ。これは、AIシステムは訓練された目的を最大化するものとしてモデル化されるからだ。したがって、そのようなシステムが特定の長期目標を常に追求するためには、その目標は訓練目的の最大化と相関があるはずだ。
これを例で説明する。あるAIソフトウェア開発者が、ソフトウェアタスクの仕様(例えば、いくつかのユニットテストによって与えられる)を受け取り、それを実装するモジュールを考え出し、そのモジュールがテストに合格したら報酬を得るように訓練されているとする。ここで、実際の配備において、システムが将来の出力をチェックするために使用されるテストも書いているとしよう。このとき、システムが「長期的な」目標を立てて、報酬の総量を最大化しようとするのではないかと心配になるかもしれない。しかし、AIソフトウェア開発者システムは、各タスクの報酬を個別に最大化するように訓練されているので、そのような心配は杞憂に終わるだろう。
実際、このような状況は今日すでに起こりうることである。GPT-3のような次トークン予測モデルは、単一のトークンに対する複雑さの報酬で訓練されるが、それらが展開されるとき、私たちは通常、トークンの長いシーケンスを生成するのである。ここで、単純に”blah “という単語の繰り返しを延々と出力するモデルを考えてみよう。しかし、nが十分に大きければ(例えば10程度)、n個の「blah」をすでに見ていれば、n+1番目の単語も「blah」である確率は非常に高くなる。なので、もしモデルが総報酬を最大化しようとすれば、いくつかのblahを出力して「打撃を受ける」価値があるかもしれない。重要なのは、GPT-3はそのようなことはしないということである。人間が生成した(自分で生成したテキストではなく)次のトークンを予測するために訓練されているので、長期的な目的ではなく、この短期的な目的のために最適化することになるのである。
私たちは、上記の例は他の多くの場合にも一般化できると考えている。現在のパラダイムで訓練されたAIシステムは、デフォルトでは、自ら設計した目標を追求する自律的なエージェントではなく、訓練された目標の最大化者となる。地平線が短く、目的が明確であればあるほど、その目的を最適化することは、遠大な(善であれ悪であれ)長期目標を追求する緻密な計画を立てているように見えるシステムにつながる可能性が低くなる。
まとめ
以上のことから、私たちは、AIが人間の努力の多くの領域でブレークスルーをもたらし続ける一方で、長期目標を追求するために自律的に行動する一元的な全能のAIシステムを見ることはないと考えている。具体的には、仮に長期的に成功するAIシステムが構築できたとしても、AIが人間に対して大きな「競争優位」を持つ領域にはならないと考えている。
むしろ、これまでの知見に基づけば、AIシステムが大きな利益をもたらすことができるのは、それほど長くない地平線の「スイートスポット」であると思われる。このスイートスポットをはるかに超える戦略的・長期的な意思決定では、AIの優れた情報処理能力は次第に低下していくだろう。(AIエンジニアは、人間のエンジニア(あるいは、少なくともAIツールの助けを借りないエンジニア)を圧倒するかもしれないが、AI CEOの優位性は、もしあったとしても、人間のそれよりもずっと緩やかなものになるであろう。私たちの世界と同様に、このような世界でも、高度なテクノロジーに支えられた多くの紛争や競争が繰り広げられるだろうが、1つのシステムが他のすべてを支配することはないだろう。
もしこの分析が成り立つなら、「AIセーフティ」コミュニティで考えられてきたのとは異なる、AIリスク軽減のためのアプローチも示唆されることになる。現在、そのコミュニティでは、長期的な目標を持つAIシステムは当然であり、したがって、そのリスクを軽減するためのアプローチは、これらの目標を人間の価値観に「合わせる」ことであるという考え方が主流となっている。しかし、短期間に限定した強力なAIシステムを構築することに、より多くの根拠を置くべきかもしれない。このようなシステムは、自律型であれ人間による指示型であれ、他のAIを監視し制御するために使用することもできる。これには、ハッキングに対するシステムの監視と強化、誤情報の検出などが含まれる。いずれにせよ、深層学習システムの内部表現を理解し、学習プロセスからどのような特徴や戦略が生まれるかについて、もっと研究を進める必要があると考えている(だから、AIセーフティコミュニティが「解釈可能性」の研究にリソースを増やしているのは喜ばしいことである)。またいくつかの証拠は、学習時の選択に関係なく、同じ内部表現が出現することを示すいくつかの証拠がある。
また、私たちの主張が正しいかどうかを左右するような技術的な研究の方向性もいくつかある。例えば、強化学習アルゴリズムの性能に対するノイズと予測不可能性の影響に関する研究、特に、様々な複雑性を持つモデルの相対的な性能(すなわちスケーリング法則のようなもの)。
謝辞このエッセイの以前のバージョンについてコメントをくれたYafah Edelmanに感謝する。
脚注
- 90年代から2000年代にかけて、人間とエンジンのチームが、「高度なチェス」で一貫してエンジンに勝つことができた。「上級チェス」しかし、AlphaZeroのリリースとそれに伴うエンジンの強さの急上昇以来、大きな上級チェス大会は行われていないようだ。おそらく、各チームの人間の半分が不要になるためだろう。
- 橋の成功は長期的な安定性に左右されるが、安定性は橋を架ける前にテストできるし、耐荷重などの指標を考えるのはエンジニアリングの専門家としては当たり前のことである。このような短期的な評価を報酬関数として学習させたAIは、それでも”過剰最適化「しかし、これは正則化技術で対処できる可能性が高い。
- 微妙な理由で、短期的な目標だけを持つAIを訓練しようとすると、例えば、短いエピソードのシリーズで訓練すると、偶然にも長期的な目標を持つAIになってしまう可能性があるのである。以下の主張6を参照。しかし、この落とし穴を避けることは、長期的な関心を持つことが明示されているAIの目標を「揃える」ことよりも簡単な問題のように思われる。
- 形式的な要件をすべて満たすという意味ではない。カオスシステムとして定義される正式な要件をすべて満たしているカオスシステムとして定義されるための形式的な要件をすべて満たしていることを意味している。
- 素敵な図解は、Sam Trajtenbergの構築したMinecraft in Minecraftの構築や、このライフの中のライフ.
- アップル対NeXTのスティーブ・ジョブズもその一つであり、成功と失敗の区別は後知恵でも難しい。ジャック・ウェルチ.
- 例えば、多額の資金を得るために多くの会社を設立する、複数の国で政治運動を成功させる、バレないように研究所を建設する、などの計画が必要かもしれない。このような「乗っ取りシナリオ」としては、ボストロムや、次のようなものが挙げられる。ユドコウスキーとアーバン.
- 仮に、企業が現在よりも賢いCEOを雇えば、全体としてより良くなる可能性はあるが、CEOが受け取る高額な報酬を考えると、これは特に妥当な均衡とは思えない。